Cet article est la huitième partie d'une série sur les expressions de table. Jusqu'à présent, j'ai fourni un aperçu des expressions de table, couvert à la fois les aspects logiques et d'optimisation des tables dérivées, les aspects logiques des CTE et certains des aspects d'optimisation des CTE. Ce mois-ci, je continue la couverture des aspects d'optimisation des CTE, en abordant spécifiquement la manière dont plusieurs références CTE sont gérées.
Cet article est la huitième partie d'une série sur les expressions de table. Jusqu'à présent, j'ai fourni un aperçu des expressions de table, couvert à la fois les aspects logiques et d'optimisation des tables dérivées, les aspects logiques des CTE et certains des aspects d'optimisation des CTE. Ce mois-ci, je continue la couverture des aspects d'optimisation des CTE, en abordant spécifiquement la manière dont plusieurs références CTE sont gérées.
Dans mes exemples, je vais continuer à utiliser l'exemple de base de données TSQLV5. Vous pouvez trouver le script qui crée et remplit TSQLV5 ici, et son diagramme ER ici.
Références multiples et non-déterminisme
Le mois dernier, j'ai expliqué et démontré que les CTE sont désimbriquées, alors que les tables temporaires et les variables de table conservent en fait les données. J'ai fourni des recommandations sur le moment où il est logique d'utiliser les CTE par rapport au moment où il est logique d'utiliser des objets temporaires du point de vue des performances des requêtes. Mais il y a un autre aspect important de l'optimisation CTE, ou du traitement physique, à prendre en compte au-delà des performances de la solution :la façon dont plusieurs références au CTE à partir d'une requête externe sont gérées. Il est important de réaliser que si vous avez une requête externe avec plusieurs références au même CTE, chacune est désimbriquée séparément. Si vous avez des calculs non déterministes dans la requête interne du CTE, ces calculs peuvent avoir des résultats différents dans les différentes références.
Supposons, par exemple, que vous invoquiez la fonction SYSDATETIME dans la requête interne d'un CTE, en créant une colonne de résultat appelée dt. Généralement, en supposant qu'il n'y a aucun changement dans les entrées, une fonction intégrée est évaluée une fois par requête et référence, quel que soit le nombre de lignes impliquées. Si vous faites référence au CTE une seule fois à partir d'une requête externe, mais que vous interagissez plusieurs fois avec la colonne dt, toutes les références sont censées représenter la même évaluation de fonction et renvoyer les mêmes valeurs. Cependant, si vous faites référence au CTE plusieurs fois dans la requête externe, que ce soit avec plusieurs sous-requêtes faisant référence au CTE ou une jointure entre plusieurs instances du même CTE (par exemple, alias C1 et C2), les références à C1.dt et C2.dt représente différentes évaluations de l'expression sous-jacente et peut entraîner des valeurs différentes.
Pour le démontrer, considérez les trois lots suivants :
-- Lot 1 DECLARE @i AS INT =1 ; WHILE @@ROWCOUNT =1 SELECT @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Lot 2 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 FROM C WHERE dt =dt; PRINT @i;GO -- Lot 3 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 WHERE (SELECT dt FROM C) =(SELECT dt FROM C); IMPRIMER @i;GO
Sur la base de ce que je viens d'expliquer, pouvez-vous identifier lequel des lots a une boucle infinie et lequel s'arrêtera à un moment donné en raison des deux comparands du prédicat évalués à des valeurs différentes ?
N'oubliez pas que j'ai dit qu'un appel à une fonction intégrée non déterministe comme SYSDATETIME est évalué une fois par requête et référence. Cela signifie que dans le lot 1, vous avez deux évaluations différentes et après suffisamment d'itérations de la boucle, elles donneront des valeurs différentes. Essayez-le. Combien d'itérations le code a-t-il rapporté ?
Comme pour le lot 2, le code a deux références à la colonne dt de la même instance CTE, ce qui signifie que les deux représentent la même évaluation de fonction et doivent représenter la même valeur. Par conséquent, le lot 2 a une boucle infinie. Exécutez-le pendant la durée de votre choix, mais vous devrez éventuellement arrêter l'exécution du code.
Comme pour le lot 3, la requête externe a deux sous-requêtes différentes interagissant avec le CTE C, chacune représentant une instance différente qui passe par un processus de désimbrication séparément. Le code n'attribue pas explicitement des alias différents aux différentes instances du CTE car les deux sous-requêtes apparaissent dans des étendues indépendantes, mais pour faciliter la compréhension, vous pouvez considérer les deux comme utilisant des alias différents tels que C1 dans une sous-requête et C2 dans l'autre. C'est donc comme si une sous-requête interagissait avec C1.dt et l'autre avec C2.dt. Les différentes références représentent différentes évaluations de l'expression sous-jacente et peuvent donc donner des valeurs différentes. Essayez d'exécuter le code et voyez qu'il s'arrête à un moment donné. Combien d'itérations a-t-il fallu jusqu'à ce qu'il s'arrête ?
Il est intéressant d'essayer d'identifier les cas où vous avez une ou plusieurs évaluations de l'expression sous-jacente dans le plan d'exécution de la requête. La figure 1 présente les plans d'exécution graphiques pour les trois lots (cliquez pour agrandir).
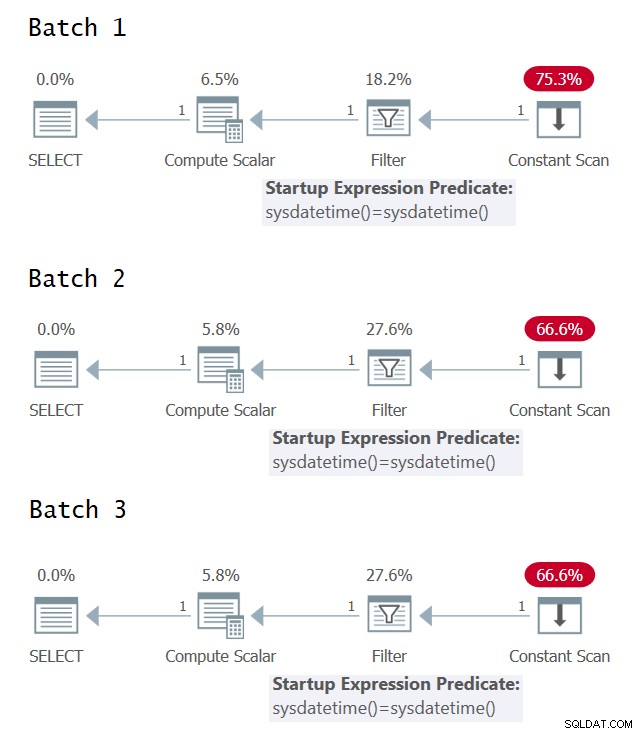 Figure 1 :Plans d'exécution graphiques pour les lots 1, 2 et 3
Figure 1 :Plans d'exécution graphiques pour les lots 1, 2 et 3
Malheureusement, aucune joie des plans d'exécution graphiques; ils semblent tous identiques même si, sémantiquement, les trois lots n'ont pas des significations identiques. Grâce à @CodeRecce et Forrest (@tsqladdict), en tant que communauté, nous avons réussi à aller au fond des choses avec d'autres moyens.
Comme @CodeRecce l'a découvert, les plans XML contiennent la réponse. Voici les parties pertinentes du XML pour les trois lots :
−− Lot 1
…
…
−− Lot 2
…
…
−− Lot 3
…
…
Vous pouvez clairement voir dans le plan XML du lot 1 que le prédicat de filtre compare les résultats de deux invocations directes distinctes de la fonction intrinsèque SYSDATETIME.
Dans le plan XML du lot 2, le prédicat de filtre compare l'expression constante ConstExpr1002 représentant un appel de la fonction SYSDATETIME avec elle-même.
Dans le plan XML du lot 3, le prédicat de filtre compare deux expressions constantes différentes appelées ConstExpr1005 et ConstExpr1006, chacune représentant un appel distinct de la fonction SYSDATETIME.
Comme autre option, Forrest (@tsqladdict) a suggéré d'utiliser l'indicateur de trace 8605, qui montre la représentation initiale de l'arbre de requête créée par SQL Server, après avoir activé l'indicateur de trace 3604 qui fait que la sortie de TF 8605 est dirigée vers le client SSMS. Utilisez le code suivant pour activer les deux indicateurs de trace :
DBCC TRACEON(3604); -- sortie directe vers clientGO DBCC TRACEON(8605); -- afficher l'arborescence initiale de la requêteGO
Ensuite, vous exécutez le code pour lequel vous souhaitez obtenir l'arbre de requête. Voici les parties pertinentes de la sortie que j'ai obtenue de TF 8605 pour les trois lots :
−− Lot 1
LogOp_Project COL :Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [vide]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_ListePrj
AncOp_PrjEl COL :Expr1000
ScaOp_Arithmétique x_aopAdd
ScaOp_Identifier COL :@i
ScaOp_Const TI(entier,ML=4) XVAR(entier,Non possédé,Valeur=1)
−− Lot 2
LogOp_Project COL :Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Projet
LogOp_ConstTableGet (1) [vide]
AncOp_ListePrj
AncOp_PrjEl COL :Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL :Expr1000
ScaOp_Identifier COL :Expr1000
AncOp_ListePrj
AncOp_PrjEl COL :Expr1001
ScaOp_Arithmétique x_aopAdd
ScaOp_Identifier COL :@i
ScaOp_Const TI(entier,ML=4) XVAR(entier,Non possédé,Valeur=1)
−− Lot 3
LogOp_Project COL :Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [vide]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL :Expr1001
LogOp_Projet
LogOp_ViewAnchor
LogOp_Projet
LogOp_ConstTableGet (1) [vide]
AncOp_ListePrj
AncOp_PrjEl COL :Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_ListePrj
AncOp_PrjEl COL :Expr1001
ScaOp_Identifier COL :Expr1000
ScaOp_Subquery COL :Expr1003
LogOp_Projet
LogOp_ViewAnchor
LogOp_Projet
LogOp_ConstTableGet (1) [vide]
AncOp_ListePrj
AncOp_PrjEl COL :Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_ListePrj
AncOp_PrjEl COL :Expr1003
ScaOp_Identifier COL :Expr1002
AncOp_ListePrj
AncOp_PrjEl COL :Expr1004
ScaOp_Arithmétique x_aopAdd
ScaOp_Identifier COL :@i
ScaOp_Const TI(entier,ML=4) XVAR(entier,Non possédé,Valeur=1)
Dans le lot 1, vous pouvez voir une comparaison entre les résultats de deux évaluations distinctes de la fonction intrinsèque SYSDATETIME.
Dans le lot 2, vous voyez une évaluation de la fonction résultant en une colonne appelée Expr1000, puis une comparaison entre cette colonne et elle-même.
Dans le lot 3, vous voyez deux évaluations distinctes de la fonction. Un dans la colonne appelée Expr1000 (plus tard projeté par la colonne de sous-requête appelée Expr1001). Une autre dans la colonne appelée Expr1002 (plus tard projetée par la colonne de sous-requête appelée Expr1003). Vous avez alors une comparaison entre Expr1001 et Expr1003.
Ainsi, en creusant un peu plus au-delà de ce que le plan d'exécution graphique expose, vous pouvez réellement déterminer quand une expression sous-jacente n'est évaluée qu'une seule fois par rapport à plusieurs fois. Maintenant que vous comprenez les différents cas, vous pouvez développer vos solutions en fonction du comportement souhaité que vous recherchez.
Fonctions de fenêtre avec ordre non déterministe
Il existe une autre classe de calculs qui peuvent vous causer des problèmes lorsqu'ils sont utilisés dans des solutions avec plusieurs références au même CTE. Ce sont des fonctions de fenêtre qui reposent sur un ordre non déterministe. Prenez la fonction de fenêtre ROW_NUMBER comme exemple. Lorsqu'il est utilisé avec la commande partielle (classement par éléments qui n'identifient pas de manière unique la ligne), chaque évaluation de la requête sous-jacente peut entraîner une affectation différente des numéros de ligne même si les données sous-jacentes n'ont pas changé. Avec plusieurs références CTE, n'oubliez pas que chacune est désimbriquée séparément et que vous pouvez obtenir différents ensembles de résultats. En fonction de ce que la requête externe fait avec chaque référence, par ex. avec quelles colonnes de chaque référence il interagit et comment, l'optimiseur peut décider d'accéder aux données pour chacune des instances en utilisant différents index avec différentes exigences de commande.
Considérez le code suivant comme exemple :
UTILISER TSQLV5 ; WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Cette requête peut-elle jamais renvoyer un jeu de résultats non vide ? Peut-être que votre première réaction est que ce n'est pas possible. Mais réfléchissez à ce que je viens d'expliquer un peu plus attentivement et vous vous rendrez compte que, du moins en théorie, en raison des deux processus de désimbrication CTE distincts qui auront lieu ici - l'un de C1 et l'autre de C2 - c'est possible. Cependant, c'est une chose de théoriser que quelque chose peut arriver, et une autre de le démontrer. Par exemple, lorsque j'ai exécuté ce code sans créer de nouveaux index, j'ai continué à obtenir un jeu de résultats vide :
orderid shipcountry orderid----------- ---------- -----------(0 lignes affectées)J'ai obtenu le plan illustré à la figure 23 pour cette requête.
Figure 2 :Premier plan de requête avec deux références CTE
Ce qui est intéressant à noter ici, c'est que l'optimiseur a choisi d'utiliser différents index pour gérer les différentes références CTE car c'est ce qu'il a jugé optimal. Après tout, chaque référence dans la requête externe concerne un sous-ensemble différent des colonnes CTE. Une référence a donné lieu à un parcours ordonné vers l'avant de l'index idx_nc_orderedate, et l'autre à un parcours non ordonné de l'index clusterisé suivi d'une opération de tri par date de commande croissante. Même si l'index idx_nc_orderedate est explicitement défini uniquement sur la colonne orderdate comme clé, en pratique, il est défini sur (orderdate, orderid) comme ses clés puisque orderid est la clé d'index cluster et est inclus comme dernière clé dans tous les index non cluster. Ainsi, une analyse ordonnée de l'index émet en fait les lignes ordonnées par orderdate, orderid. Comme pour l'analyse non ordonnée de l'index clusterisé, au niveau du moteur de stockage, les données sont analysées dans l'ordre des clés d'index (basé sur l'ID de commande) pour répondre aux attentes de cohérence minimales du niveau d'isolement par défaut en lecture validée. L'opérateur Sort ingère donc les données triées par orderid, trie les lignes par orderdate, et finit en pratique par émettre les lignes triées par orderdate, orderid.
Encore une fois, en théorie, rien ne garantit que les deux références représenteront toujours le même ensemble de résultats, même si les données sous-jacentes ne changent pas. Un moyen simple de le démontrer consiste à organiser deux index optimaux différents pour les deux références, mais en ayant l'un pour ordonner les données par date de commande ASC, id de commande ASC, et l'autre pour ordonner les données par date de commande DESC, id de commande ASC (ou exactement l'inverse). L'ancien index est déjà en place. Voici le code pour créer ce dernier :
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);Exécutez le code une deuxième fois après avoir créé l'index :
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;J'ai obtenu le résultat suivant lors de l'exécution de ce code après la création du nouvel index :
orderid shipcountry orderid----------- --------------- -----------10251 France 1025010250 Brésil 1025110261 Brésil 1026010260 Allemagne 1026110271 USA 10270...11070 Allemagne 1107311077 USA 1107411076 France 1107511075 Suisse 1107611074 Danemark 11077(546 lignes concernées)Oups.
Examinez le plan de requête pour cette exécution, comme illustré à la figure 3 :
Figure 3 :Deuxième plan de requête avec deux références CTE
Notez que la branche supérieure du plan analyse l'index idx_nc_orderdate de manière ordonnée vers l'avant, obligeant l'opérateur Sequence Project qui calcule les numéros de ligne à ingérer les données en pratique classées par orderdate ASC, orderid ASC. La branche inférieure du plan parcourt le nouvel index idx_nc_odD_oid_I_sc de manière ordonnée vers l'arrière, ce qui amène l'opérateur Sequence Project à ingérer les données en pratique classées par orderdate ASC, orderid DESC. Cela se traduit par une disposition différente des numéros de ligne pour les deux références CTE chaque fois qu'il y a plus d'une occurrence de la même valeur de date de commande. Par conséquent, la requête génère un jeu de résultats non vide.
Si vous voulez éviter de tels bogues, une option évidente consiste à conserver le résultat de la requête interne dans un objet temporaire comme une table temporaire ou une variable de table. Cependant, si vous avez une situation où vous préférez vous en tenir à l'utilisation des CTE, une solution simple consiste à utiliser l'ordre total dans la fonction de fenêtre en ajoutant un bris d'égalité. En d'autres termes, assurez-vous que vous triez par une combinaison d'expressions qui identifie de manière unique une ligne. Dans notre cas, vous pouvez simplement ajouter orderid explicitement comme condition de départage, comme ceci :
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Vous obtenez un jeu de résultats vide comme prévu :
orderid shipcountry orderid----------- ---------- -----------(0 lignes affectées)Sans ajouter d'autres index, vous obtenez le plan illustré à la figure 4 :
Figure 4 :Troisième plan de requête avec deux références CTE
La branche supérieure du plan est la même que pour le plan précédent illustré à la figure 3. La branche inférieure est cependant un peu différente. Le nouvel index créé précédemment n'est pas vraiment idéal pour la nouvelle requête dans le sens où il n'a pas les données ordonnées comme les besoins de la fonction ROW_NUMBER (orderdate, orderid). C'est toujours l'indice de couverture le plus étroit que l'optimiseur puisse trouver pour sa référence CTE respective, il est donc sélectionné ; cependant, il est scanné de manière Ordonné :Faux. Un opérateur de tri explicite trie ensuite les données par date de commande, ID de commande comme le calcul ROW_NUMBER a besoin. Bien sûr, vous pouvez modifier la définition de l'index pour que orderdate et orderid utilisent la même direction et ainsi le tri explicite sera éliminé du plan. Le point principal cependant est qu'en utilisant la commande totale, vous évitez d'avoir des ennuis à cause de ce bogue spécifique.
Lorsque vous avez terminé, exécutez le code suivant pour le nettoyage :
SUPPRIMER L'INDEX SI EXISTE idx_nc_odD_oid_I_sc ON Sales.Orders ;Conclusion
Il est important de comprendre que plusieurs références au même CTE à partir d'une requête externe entraînent des évaluations distinctes de la requête interne du CTE. Soyez particulièrement prudent avec les calculs non déterministes, car les différentes évaluations peuvent entraîner des valeurs différentes.
Lorsque vous utilisez des fonctions de fenêtre telles que ROW_NUMBER et des agrégats avec un cadre, assurez-vous d'utiliser l'ordre total pour éviter d'obtenir des résultats différents pour la même ligne dans les différentes références CTE.