Dans un fil de discussion récent sur StackExchange, un utilisateur a rencontré le problème suivant :
Je veux une requête qui renvoie la première personne dans la table avec un GroupID =2. Si personne avec un GroupID =2 n'existe, je veux la première personne avec un RoleID =2.
Écartons, pour l'instant, le fait que "premier" est terriblement défini. En réalité, l'utilisateur ne se souciait pas de la personne qu'il avait, qu'elle soit venue au hasard, arbitrairement ou par une logique explicite en plus de ses critères principaux. En ignorant cela, disons que vous avez une table de base :
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
Dans le monde réel, il existe probablement d'autres colonnes, des contraintes supplémentaires, peut-être des clés étrangères vers d'autres tables, et certainement d'autres index. Mais restons simples et proposons une requête.
Solutions probables
Avec cette conception de table, résoudre le problème semble simple, n'est-ce pas ? La première tentative que vous feriez probablement serait :
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Cela utilise TOP et un ORDER BY conditionnel pour traiter les utilisateurs avec un GroupID =2 comme une priorité plus élevée. Le plan de cette requête est assez simple, la plupart des coûts se produisant dans une opération de tri. Voici les métriques d'exécution par rapport à une table vide :
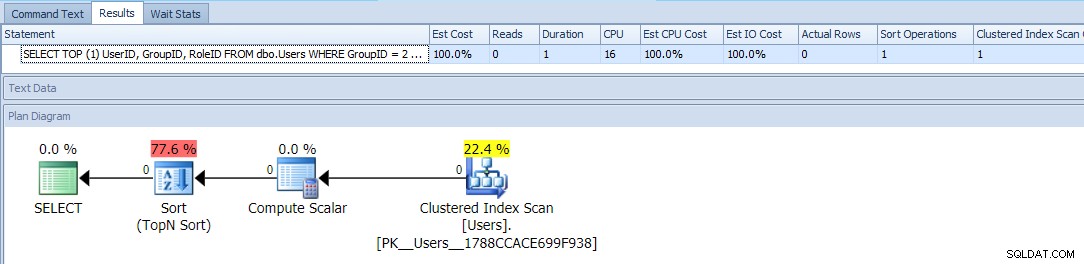
Cela semble être à peu près aussi bon que vous pouvez le faire - un plan simple qui ne scanne la table qu'une seule fois, et autre qu'un genre embêtant avec lequel vous devriez pouvoir vivre, pas de problème, n'est-ce pas ?
Eh bien, une autre réponse dans le fil proposait cette variation plus complexe :
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
À première vue, vous penseriez probablement que cette requête est extrêmement moins efficace, car elle nécessite deux parcours d'index clusterisés. Vous auriez certainement raison à ce sujet; voici les métriques de plan et d'exécution par rapport à une table vide :
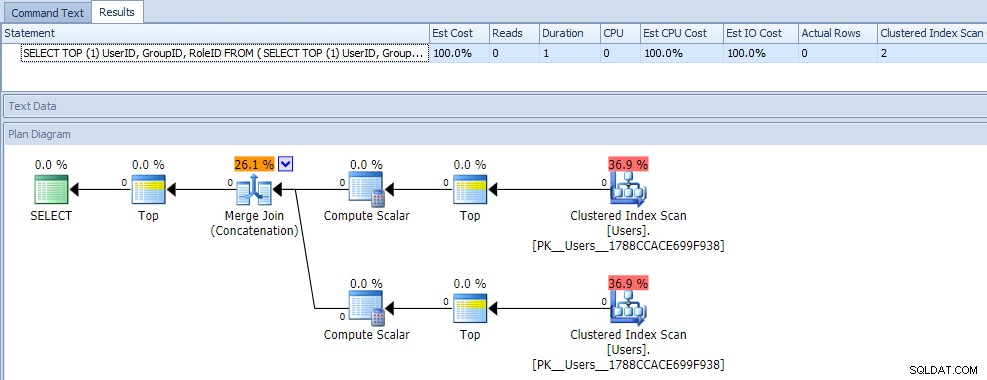
Mais maintenant, ajoutons des données
Afin de tester ces requêtes, je voulais utiliser des données réalistes. Donc, j'ai d'abord rempli 1 000 lignes à partir de sys.all_objects, avec des opérations modulo sur object_id pour obtenir une distribution décente :
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Maintenant, lorsque j'exécute les deux requêtes, voici les métriques d'exécution :

La version UNION ALL propose un peu moins d'E/S (4 lectures contre 5), une durée plus courte et un coût global estimé inférieur, tandis que la version conditionnelle ORDER BY a un coût CPU estimé inférieur. Les données ici sont assez petites pour tirer des conclusions; Je le voulais juste comme un pieu dans le sol. Modifions maintenant la distribution afin que la plupart des lignes répondent à au moins un des critères (et parfois aux deux) :
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Cette fois, l'ordre conditionnel par présente les coûts estimés les plus élevés en CPU et en E/S :

Mais encore une fois, à cette taille de données, il y a un impact relativement sans conséquence sur la durée et les lectures, et mis à part les coûts estimés (qui sont en grande partie inventés de toute façon), il est difficile de déclarer un gagnant ici.
Donc, ajoutons beaucoup plus de données
Bien que j'aime plutôt créer des exemples de données à partir des vues de catalogue, puisque tout le monde en a, cette fois, je vais dessiner sur la table Sales.SalesOrderHeaderEnlarged de AdventureWorks2012, développée à l'aide de ce script de Jonathan Kehayias. Sur mon système, cette table a 1 258 600 lignes. Le script suivant insérera un million de ces lignes dans notre table dbo.Users :
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
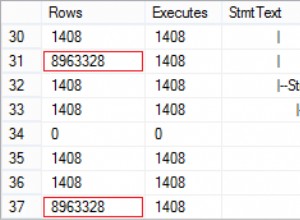
Bon, maintenant, lorsque nous exécutons les requêtes, nous voyons un problème :la variation ORDER BY est devenue parallèle et a effacé à la fois les lectures et le processeur, ce qui donne une différence de durée de près de 120 X :
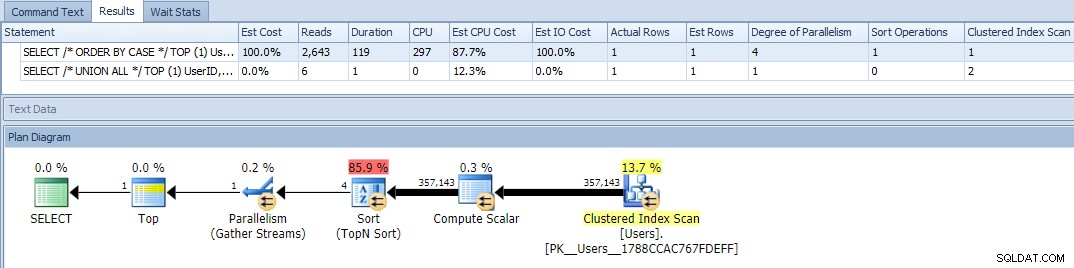
L'élimination du parallélisme (à l'aide de MAXDOP) n'a pas aidé :
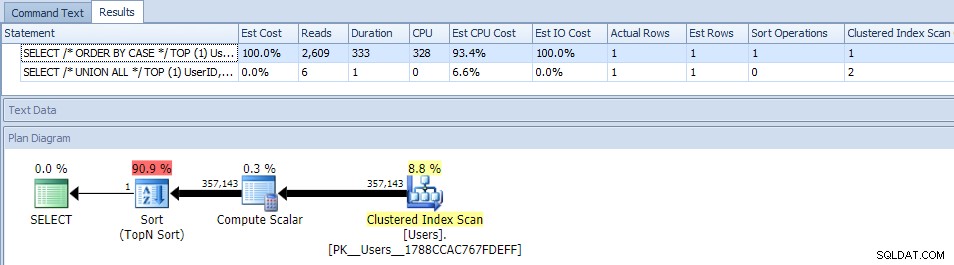
(Le plan UNION ALL a toujours le même aspect.)
Et si nous modifions l'inclinaison pour qu'elle soit paire, où 95 % des lignes répondent à au moins un critère :
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Les requêtes montrent toujours que le tri est d'un coût prohibitif :

Et avec MAXDOP =1, c'était bien pire (il suffit de regarder la durée) :

Enfin, qu'en est-il de l'inclinaison d'environ 95 % dans les deux sens (par exemple, la plupart des lignes satisfont aux critères GroupID ou la plupart des lignes satisfont aux critères RoleID) ? Ce script garantira qu'au moins 95 % des données ont GroupID =2 :
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Les résultats sont assez similaires (je vais juste arrêter d'essayer le truc MAXDOP à partir de maintenant):

Et puis si nous biaisons dans l'autre sens, où au moins 95 % des données ont RoleID =2 :
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Résultats :

Conclusion
Dans pas un seul cas que j'ai pu fabriquer, la requête ORDER BY "plus simple" - même avec un balayage d'index clusterisé de moins - n'a surpassé la requête UNION ALL plus complexe. Parfois, vous devez être très prudent quant à ce que SQL Server doit faire lorsque vous introduisez des opérations telles que des tris dans la sémantique de vos requêtes, et ne pas compter uniquement sur la simplicité du plan (peu importe les biais que vous pourriez avoir en fonction des scénarios précédents).
Votre premier instinct peut souvent être correct, mais je parie qu'il y a des moments où il y a une meilleure option qui semble, à première vue, comme si elle ne pouvait pas mieux fonctionner. Comme dans cet exemple. Je m'améliore un peu pour remettre en question les hypothèses que j'ai faites à partir d'observations et ne pas faire de déclarations générales comme "les analyses ne fonctionnent jamais bien" et "les requêtes plus simples s'exécutent toujours plus rapidement". Si vous éliminez les mots jamais et toujours de votre vocabulaire, vous risquez de vous retrouver à mettre davantage de ces hypothèses et déclarations générales à l'épreuve, et de vous retrouver beaucoup mieux loti.