Dans mon article précédent sur les bases de données système SQL Server, nous avons découvert chaque base de données système qui fait partie de l'installation de SQL Server. L'article actuel se concentrera sur les problèmes fréquemment rencontrés autour de la base de données tempdb et sur la façon de les résoudre correctement.
SQL Server TempDB
Comme le nom de cette base de données système l'indique, tempdb contient des objets temporaires créé par SQL Server. Ils concernent plusieurs opérations et agissent comme une zone de travail globale pour tous les utilisateurs se connectant aux instances SQL Server.
La base de données Tempdb contiendra les types d'objets ci-dessous pendant que les utilisateurs effectuent leurs opérations :
- Les objets temporaires sont créés explicitement par les utilisateurs. Il peut s'agir de tables et d'index temporaires locaux ou globaux, de variables de table, de tables utilisées dans les fonctions table et de curseurs.
- Objets internes créés par le moteur de base de données comme
- Tables de travail stockant les résultats intermédiaires pour les spools, les curseurs, les tris et les objets volumineux temporaires (LOB).
- Traitez des fichiers tout en effectuant des opérations de jointure par hachage ou d'agrégation par hachage.
- Trier les résultats intermédiaires lors de la création ou de la reconstruction d'index si SORT_IN_TEMPDB est défini sur ON, et d'autres opérations telles que les requêtes GROUP BY, ORDER BY ou SQL UNION.
- Les magasins de versions qui prennent en charge la fonctionnalité de gestion des versions de ligne, que ce soit le magasin de versions commun ou le magasin de versions de construction d'index en ligne, utilisent les fichiers de base de données tempdb.
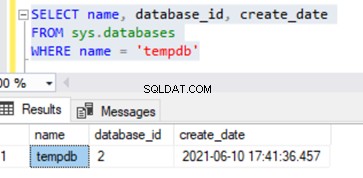
La base de données Tempdb est créée à chaque démarrage du service SQL Server. Par conséquent, l'heure de création de la base de données tempdb peut être considérée comme une heure de démarrage approximative du service SQL Server. Nous pouvons l'identifier à partir de sys.databases DMV en utilisant la requête ci-dessous :
SELECT name, database_id, create_date
FROM sys.databases
WHERE name = 'tempdb'
Cependant, le démarrage réel de SQL Server Service implique le démarrage de toutes les bases de données système dans un ordre spécifique. Cela peut arriver un peu plus tôt que l'heure de création de tempdb. Nous pouvons obtenir la valeur en utilisant sys.databases DMV en exécutant la requête ci-dessous sur sys.dm_os_sys_info DMV .
SELECT ms_ticks, sqlserver_start_time_ms_ticks, sqlserver_start_time
FROM sys.dm_os_sys_info
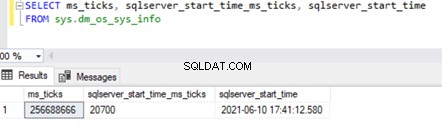
Les ms_ticks La colonne indique le nombre de millisecondes écoulées depuis le démarrage de l'ordinateur ou du serveur. Les sqlserver_start_time_ms_ticks la colonne spécifie le nombre de millisecondes depuis le ms_ticks numéro lorsque le service SQL Server a démarré.
Nous pouvons trouver plus d'informations sur l'ordre des bases de données qui ont démarré lors du démarrage des services SQL Server dans le journal des erreurs SQL Server.
Dans SSMS, développez Gestion > Journaux d'erreurs SQL Server > ouvrir le courant journal des erreurs. Appliquer le démarrage base de données filtrez et cliquez sur Date pour le trier par ordre croissant :
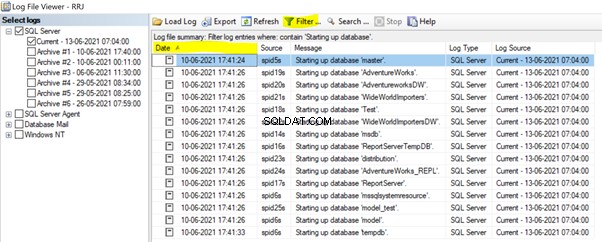
Nous pouvons voir que la base de données master a démarré en premier lors du démarrage du service SQL Server. Ensuite, toutes les bases de données utilisateur et toutes les autres bases de données système ont suivi. Enfin, le tempdb a démarré. Vous pouvez également récupérer ces informations par programmation en exécutant le xp_readerrorlog procédure système :
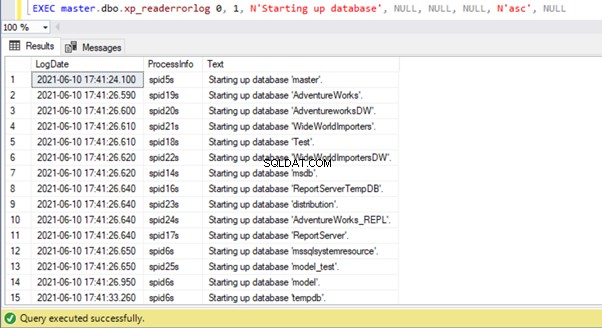
Remarque :Les deux approches ci-dessus peuvent ne pas afficher les informations nécessaires si le service SQL Server n'a pas été redémarré récemment et que le journal des erreurs SQL Server a été recyclé, ce qui aurait pu pousser les journaux d'erreurs plus anciens vers des fichiers plus anciens. Dans ce cas, nous devrons peut-être analyser les données dans les fichiers journaux d'erreurs SQL Server archivés.
Problèmes fréquemment rencontrés dans la base de données SQL TempDB
Étant donné que tempdb fournit une zone de travail globale pour toutes les sessions ou activités des utilisateurs, il peut devenir un goulot d'étranglement des performances pour les opérations des utilisateurs s'il n'est pas soigneusement configuré. Dans mon article précédent, nous avons discuté des meilleures pratiques recommandées à mettre en œuvre dans la base de données tempdb. Cependant, même après leur mise en œuvre, nous pouvons rencontrer fréquemment des problèmes :
- Croissance inégale des fichiers dans les fichiers de données tempdb
- Les fichiers de données Tempdb atteignent une valeur énorme et doivent réduire Tempdb.
Croissance inégale des fichiers dans les fichiers de données TempDB
À partir de SQL Server 2000, la recommandation par défaut est d'avoir plusieurs fichiers de données en fonction du nombre de cœurs logiques disponibles sur le serveur.
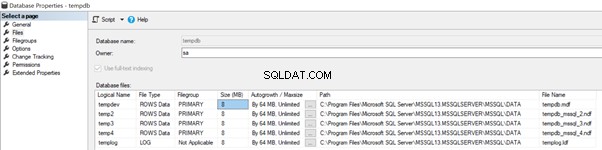
Lorsque nous avons plusieurs fichiers de données, par exemple, 4 fichiers de données tempdb comme dans l'image ci-dessous, la croissance automatique des fichiers de données tempdb se produira de 64 Mo de manière circulaire à partir de tempdev> temp2> temp3> temp4> tempdev> et ainsi de suite.
Si l'une des tailles de fichier ne peut pas croître automatiquement pour une raison quelconque, cela entraînera la taille énorme de certains fichiers par rapport à d'autres fichiers. Cela entraîne une surcharge supplémentaire placée sur des fichiers volumineux et un impact négatif sur les performances de la base de données tempdb.
Nous devons nous assurer manuellement que tous les fichiers de données tempdb sont de taille uniforme à tout moment manuellement pour éviter les problèmes de contention ou de performances jusqu'à SQL Server 2014. Microsoft a modifié ce comportement à partir de SQL Server 2016 et des versions ultérieures en implémentant quelques fonctionnalités qui seront discuté plus loin dans cet article.
Pour surmonter les problèmes de performances ci-dessus, SQL Server a introduit 2 indicateurs de trace nommé 1117 et 1118 pour éviter les problèmes de contention autour de tempdb.
- Indicateur de suivi 1117 – permet la croissance automatique de tous les fichiers au sein d'un seul groupe de fichiers
- Indicateur de suivi 1118 – active UNIFORM FULL EXTENTS pour tempdb
Indicateur de suivi 1117
Sans Trace Flag 1117 activé, chaque fois que tempdb est configuré avec plusieurs fichiers de données de taille égale et que les fichiers de données doivent croître automatiquement, SQL Server essaiera par défaut d'augmenter la taille des fichiers de manière circulaire si tous les fichiers. Si les fichiers de données ne sont pas dimensionnés de manière uniforme, SQL Server essaiera d'augmenter la taille du fichier de données le plus volumineux de tempdb et utilisera ce fichier plus volumineux pour la plupart des opérations utilisateur, ce qui entraînera des problèmes de conflit tempdb.
Pour résoudre ce problème, SQL Server a introduit l'indicateur de trace 1117. Une fois activé, si un fichier d'un groupe de fichiers doit se développer automatiquement, il développera automatiquement tous les fichiers de ce groupe de fichiers. Il résout les problèmes de contention tempdb. Cependant, le problème est qu'une fois l'indicateur de trace 1117 activé, la croissance automatique est également configurée pour toutes les bases de données utilisateur.
Indicateur de suivi 1118
L'indicateur de trace 1118 est utilisé pour activer UNIFORM FULL EXTENTS. Revenons un peu en arrière pour comprendre comment SQL Server stocke les données de base.
Page est l'unité de stockage fondamentale de SQL Server avec une taille de 8 kilo-octets (Ko).
Étendue est un ensemble de 8 pages physiquement contiguës d'une taille de 64 Ko (8*8 Ko). En fonction du nombre d'objets ou de propriétaires stockant les données dans une étendue, l'étendue peut être classée en :
- Étendues uniformes sont 8 pages contiguës utilisées ou consultées par un seul objet ou propriétaire ;
- Mixte Étendues – sont 8 pages contiguës utilisées ou consultées par un minimum de 2 et un maximum de 8 objets ou propriétaires
L'activation de Trace Flag 1118 permettra à tempdb d'avoir des étendues uniformes, ce qui se traduira par de meilleures performances.
Comment activer les indicateurs de trace 1117 et 1118
Les indicateurs de trace peuvent être activés via plusieurs approches. Vous pouvez définir le chemin approprié à partir des options ci-dessous :
Paramètres de démarrage du service SQL Server
Disponible en permanence même après le redémarrage du service SQL. La méthode recommandée consiste à activer les indicateurs de trace 1117 et 1118 via les paramètres de démarrage du service SQL Server .
Ouvrez Gestionnaire de configuration SQL Server et cliquez sur Services SQL Server pour répertorier les services disponibles sur ce serveur :

- Cliquez avec le bouton droit sur SQL Server (MSSQLSERVER) > Propriétés > Paramètres de démarrage .
- Type -T dans le champ vide pour indiquer le indicateur de suivi .
- Fournir des valeurs 1117 et 1118 comme indiqué ci-dessous.
- Cliquez sur Ajouter pour que les indicateurs de suivi soient ajoutés en tant que paramètres de démarrage.
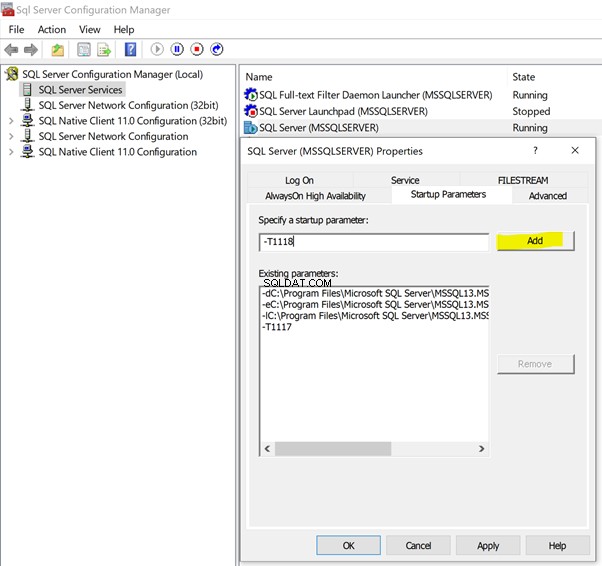
Cliquez ensuite sur OK pour que les indicateurs de trace soient ajoutés de façon permanente pour cette instance de SQL Server. Redémarrez le service SQL Server pour que les modifications soient prises en compte.
DBCC TRACEON (, -1)
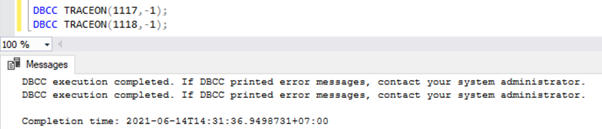
Activez un indicateur de trace globalement. Le service SQL Server perdra les indicateurs de trace lors du redémarrage du service. Pour activer un indicateur de trace globalement, exécutez le script ci-dessous dans une nouvelle fenêtre de requête :
DBCC TRACEON(1117,-1);
DBCC TRACEON(1118,-1);
DBCC TRACEON ()
Activez l'indicateur de trace au niveau de la session. Il s'applique uniquement à la session en cours créée par l'utilisateur. Pour activer un indicateur de trace au niveau de la session, exécutez le script ci-dessous dans une nouvelle fenêtre de requête :
DBCC TRACEON(1117);
DBCC TRACEON(1118);
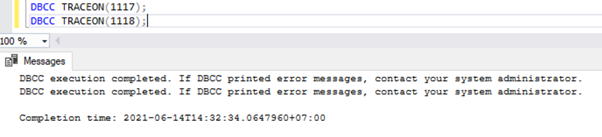
Pour afficher la liste des indicateurs de trace activés dans une instance de SQL Server, nous pouvons utiliser le DBCC TRACESTATUS commande :
DBCC TRACESTATUS();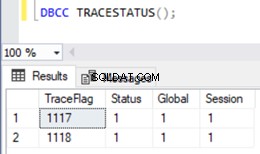
Comme nous pouvons le voir, Les drapeaux de trace 1117 et 1118 sont activés globalement dans mon instance avec la session .
Pour désactiver un indicateur de trace, nous pouvons utiliser la commande DBCC TRACEOFF comme :
DBCC TRACEOFF(1117,-1);
DBCC TRACEOFF(1118,-1);
Améliorations de SQL Server 2016 TempDB
Dans les versions de SQL Server SQL Server 2000 à SQL Server 2014, nous devons activer les indicateurs de trace 1117 et 1118 ainsi qu'une surveillance complète de tempdb pour éviter les problèmes de conflit tempdb. À partir de SQL Server 2016 et des versions ultérieures, les indicateurs de trace 1117 et 1118 sont implémentés par défaut.
Cependant, sur la base de mon expérience personnelle, il est préférable de pré-développer tempdb à une taille énorme pour éviter le besoin de croissance automatique plusieurs fois et pour éliminer les tailles de fichiers inégales ou les fichiers uniques largement utilisés par SQL Server .
Nous pouvons vérifier comment Trace Flag 1117 et 1118 sont implémentés dans SQL Server 2016 :
Indicateur de suivi 1117 qui définit la croissance automatique de tous les fichiers d'un groupe de fichiers est désormais une propriété du groupe de fichiers . Nous pouvons le configurer lors de la création d'un nouveau groupe de fichiers ou de la modification d'un groupe existant.
Pour vérifier la propriété de croissance automatique du groupe de fichiers , exécutez le script ci-dessous à partir de sys.filegroups DMV :
SELECT name Filegroup_Name, is_autogrow_all_files
FROM sys.filegroups
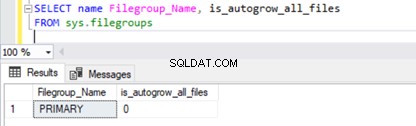
Pour modifier la propriété de croissance automatique du groupe de fichiers principal de la base de données AdventureWorks , nous exécutons le script ci-dessous avec AUTOGROW_ALL_FILES pour faire croître automatiquement tous les fichiers de manière égale ou AUTOGROW_SINGLE_FILE pour permettre la croissance automatique d'un seul fichier de données.
ALTER DATABASE Adventureworks MODIFY FILEGROUP [PRIMARY]
AUTOGROW_SINGLE_FILE
-- AUTOGROW_ALL_FILES is the default behavior
GO
Indicateur de suivi 1118 qui définit la propriété Uniform Extent des fichiers de données est activé par défaut pour tempdb et toutes les bases de données utilisateur à partir de SQL Server 2016 . Nous ne pouvons pas modifier les propriétés de tempdb, car il ne prend désormais en charge que l'option Étendue uniforme.
Pour les bases de données utilisateur, nous pouvons modifier ce paramètre. Les bases de données système master, model et msdb prennent en charge les étendues mixtes par défaut et ne peuvent pas non plus être modifiées.
Pour modifier les valeurs des propriétés d'allocation de pages mixtes pour les bases de données utilisateur, utilisez le script ci-dessous :
ALTER DATABASE Adventureworks SET MIXED_PAGE_ALLOCATION ON
-- OFF is the default behavior
GO
Pour vérifier la propriété d'allocation de pages mixtes, nous pouvons interroger le is_mixed_page_allocation_on colonne de sys.databases DMV avec la valeur 0, indiquant l'allocation de page d'étendue uniforme, et 1 pour indiquer l'allocation de page d'étendue mixte.
SELECT name, is_mixed_page_allocation_on
FROM sys.databases
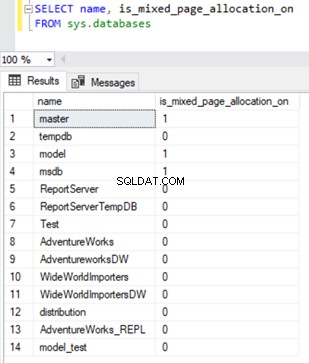
Les fichiers de données TempDB atteignent une valeur énorme nécessitant une réduction TempDB
Dans SQL Server 2014 ou les versions antérieures, si les indicateurs de trace 1117 et 1118 ne sont pas configurés correctement avec plusieurs fichiers de données créés pour la base de données tempdb, certains de ces fichiers deviendront inévitablement énormes. Si cela se produit, un DBA essaie généralement de réduire les fichiers de données tempdb. Mais c'est un inapproprié approche pour gérer ce scénario.
Il existe d'autres options disponibles pour réduire la tempdb.
Considérons les commandes DBCC disponibles pour Shrink tempdb et les impacts de ces opérations.
DBCC SHRINKDATABASE
La DBCC SHRINKDATABASE La commande console fonctionne en rétrécissant la fin des fichiers Data\Log .
Pour réussir à réduire une base de données, la commande a besoin d'espace libre à la fin du fichier. S'il y a des transactions actives à la fin du fichier, les fichiers de la base de données ne peuvent pas être réduits.
L'impact de l'exécution de DBCC SHRINKDATABASE est qu'il essaiera de libérer de l'espace libre disponible à la fin de chaque fichier de données ou fichier journal qui aurait pu être réservé pour une croissance future des données de la table. Par conséquent, l'exécution de cette commande peut entraîner des tailles de fichier inégales entraînant des problèmes de conflit tempdb.
La syntaxe pour réduire une base de données d'utilisateurs, par exemple la base de données Adventureworks, serait
DBCC SHRINKDATABASE (AdventureWorks, TRUNCATEONLY);DBCC SHRINKFILE
Le DBCC SHRINKFILE La commande console fonctionne de la même manière que DBCC SHRINKDATABASE, mais elle réduit les données de base de données ou les fichiers journaux spécifiés .
Si vous identifiez qu'un fichier de données tempdb particulier est volumineux, nous pouvons essayer de réduire cet élément particulier à l'aide de DBCC SHRINKFILE, comme indiqué ci-dessous.
Soyez prudent lorsque vous utilisez cette commande sur tempdb car si un fichier est réduit à une valeur inférieure ou supérieure à celle des autres fichiers de données, ce fichier de données particulier ne sera pas utilisé efficacement. Ou, il sera utilisé plus fréquemment, ce qui entraînera des problèmes de conflit tempdb.
La syntaxe pour exécuter l'opération DBCC SHRINKFILE sur le fichier de données AdventureWorks jusqu'à 1 Go (1 024 Mo) serait :
DBCC SHRINKFILE (AdventureWorks, 1024);
GO
TAMPONS DBCC DROPCLEAN
Les DBCC DROPCLEANBUFFERS La commande console est utilisée pour effacer tous les tampons propres du pool de tampons et les objets columnstore du pool d'objets columnstore .
Exécutez simplement la commande ci-dessous :
DBCC DROPCLEANBUFFERSDBCC FREEPROCCACHE
Le DBCC FREEPROCCACHE la commande efface tout le cache du plan d'exécution des procédures stockées .
Le cache du plan d'exécution de procédure est utilisé par SQL Server pour exécuter plus rapidement les mêmes appels de procédure. Après l'exécution de DBCC FREEPROCCACHE, le cache du plan est effacé. Ainsi, SQL Server doit recréer ce cache lorsque la procédure stockée est exécutée dans l'instance. Cela laisse un impact négatif sérieux lorsqu'il est exécuté dans les instances de base de données de production.
Il n'est pas recommandé d'exécuter DBCC FREEPROCCACHE sur l'instance de base de données de production !
La syntaxe pour exécuter DBCC FREEPROCCACHE est ci-dessous :
DBCC FREEPROCCACHEDBCC FREESESSIONCACHE
Le DBCC FREESESSIONCACHE la commande efface le cache de connexion de la requête de distribution de l'instance SQL Server . Cela sera utile lorsque de nombreuses requêtes distribuées s'exécutent sur une instance SQL Server particulière.
La syntaxe pour exécuter DBCC FREESESSIONCACHE serait :
DBCC FREESESSIONCACHEDBCC FREESYSTEMCACHE
Le DBCC FREESYSTEMCACHE la commande efface toutes les entrées de cache inutilisées de tout le cache . SQL Server le fait par défaut pour libérer plus de mémoire pour les nouvelles opérations. Cependant, nous pouvons l'exécuter manuellement en utilisant la commande ci-dessous :
DBCC FREESYSTEMCACHEComme nous le savons, tempdb stocke tous les objets utilisateur temporaires ou les objets internes, y compris le cache du plan d'exécution, les données du pool de tampons, les caches de session et les caches système. Par conséquent, l'exécution des 6 commandes DBCC ci-dessus aidera à effacer les fichiers de données tempdb qui empêchent le processus de réduction normal.
Même si nous avons suivi les étapes sur la façon de réduire tempdb via différentes approches, les meilleures pratiques recommandées pour gérer la base de données tempdb sont répertoriées ci-dessous :
a. Redémarrez les services SQL Server si possible pour recréer uniformément les fichiers de données tempdb. L'impact potentiel serait que nous perdrions tous les plans d'exécution et autres informations de cache discutés ci-dessus.
b. Pré-développez les fichiers de données tempdb à une taille de fichier énorme disponible dans le lecteur contenant les fichiers de données tempdb. Cela empêchera SQL Server d'augmenter la taille des fichiers de manière inégale dans les versions 2014 et antérieures de SQL Server.
c. Si les services SQL Server ne peuvent pas être redémarrés en raison d'un RTO ou d'un RPO, essayez les commandes DBCC ci-dessus après avoir bien compris les impacts.
d. Réduire la base de données tempdb ou les fichiers de données n'est pas une approche recommandée et ne le faites donc jamais dans votre environnement de production, sauf s'il n'y a pas d'autres options.
Conclusion
Nous en avons appris davantage sur le fonctionnement interne de tempdb afin de pouvoir configurer tempdb pour de meilleures performances en évitant les problèmes de contention sur tempdb. Nous avons également passé en revue les problèmes fréquemment rencontrés dans tempdb, les mesures disponibles dans SQL Server sur différentes versions et comment les gérer efficacement. En plus de cela, nous avons examiné pourquoi la réduction de la base de données tempdb ou des fichiers de données n'est pas une approche recommandée lors de la gestion de la base de données tempdb.