Spark a vu le jour en 2009 en tant que projet au sein de l'AMPLab de l'Université de Californie à Berkeley. Plus précisément, il est né de la nécessité de prouver le concept de Mesos, également créé au sein de l'AMPLab. Spark a été abordé pour la première fois dans le livre blanc de Mesos intitulé Mesos :une plate-forme pour le partage de ressources à grain fin dans le centre de données, rédigé notamment par Benjamin Hindman et Matei Zaharia.
Il est apparu comme une solution rapide et pratique pour effectuer une analyse complexe de données à grande échelle. Spark a évolué en tant que nouveau cadre de traitement pour le Big Data qui résout de nombreuses lacunes du modèle MapReduce. Il prend en charge l'analyse de données à grande échelle, et les données peuvent provenir de différentes sources comme le temps réel, le traitement par lots dans divers formats comme les images, les textes, les graphiques et bien d'autres. En plus de son cœur Apache Spark, il fournit également un ensemble de bibliothèques utiles pour l'analyse de données volumineuses.
Présentation des composants Spark
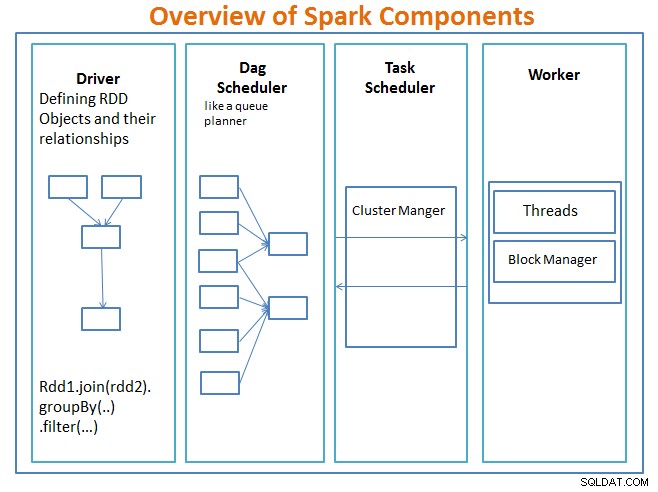
Le conducteur est le code qui inclut la fonction principale et définit les ensembles de données distribués résilients (RDD) et leurs transformations. Les RDD sont les principales structures de données qui seront utilisées dans nos programmes Spark.
Les opérations parallèles sur les RDD sont envoyées au planificateur DAG , qui optimisera le code et arrivera à un DAG efficace qui représente les étapes de traitement des données dans l'application.
Le DAG résultant est envoyé au gestionnaire de cluster et le gestionnaire de cluster dispose d'informations sur les travailleurs, les threads affectés et l'emplacement des blocs de données et est responsable de l'attribution de tâches de traitement spécifiques aux travailleurs. Il gère également le paly en cas de défaillance du travailleur. Le gestionnaire de cluster peut être YARN, Mesos, le gestionnaire de cluster de Spark.
Le travailleur reçoit des unités de travail et des données à gérer et le travailleur exécute sa tâche spécifique sans connaître l'ensemble du DAG et ses résultats sont renvoyés aux applications pilotes.
Spark, comme d'autres outils de Big Data, est puissant, capable et bien adapté pour relever un éventail de défis liés aux données. Spark, comme d'autres technologies de Big Data, n'est pas nécessairement le meilleur choix pour chaque tâche de traitement de données.
Dans la partie 2, nous discuterons des concepts de base de Spark tels que les ensembles de données distribués résilients, les variables partagées, SparkContext, les transformations, l'action , et Avantages de l'utilisation de Spark avec des exemples et quand utiliser Spark.
Référence :
Apprenez Spark en un jour avec les architectures d'applications Acodemy et Hadoop.