Il existe plusieurs méthodes pour examiner les requêtes peu performantes dans SQL Server, notamment le magasin de requêtes, les événements étendus et les vues de gestion dynamiques (DMV). Chaque option a des avantages et des inconvénients. Les événements étendus fournissent des données sur l'exécution individuelle des requêtes, tandis que le magasin de requêtes et les DMV agrègent les données de performances. Pour utiliser le magasin de requêtes et les événements étendus, vous devez les configurer à l'avance, soit en activant le magasin de requêtes pour votre ou vos bases de données, soit en configurant une session XE et en la démarrant. Les données DMV sont toujours disponibles, c'est donc très souvent la méthode la plus simple pour obtenir un premier aperçu rapide des performances des requêtes. C'est là que les requêtes DMV de Glenn sont utiles - dans son script, il a plusieurs requêtes que vous pouvez utiliser pour trouver les principales requêtes pour l'instance en fonction du processeur, des E/S logiques et de la durée. Cibler les requêtes les plus consommatrices de ressources est souvent un bon début lors du dépannage, mais nous ne pouvons pas oublier le scénario "mort par mille coupes" - la requête ou l'ensemble de requêtes qui s'exécutent TRÈS fréquemment - peut-être des centaines ou des milliers de fois par minute. Glenn a une requête dans son ensemble qui répertorie les principales requêtes pour une base de données en fonction du nombre d'exécutions, mais d'après mon expérience, cela ne vous donne pas une image complète de votre charge de travail.
Le principal DMV utilisé pour examiner les mesures de performances des requêtes est sys.dm_exec_query_stats. Des données supplémentaires spécifiques aux procédures stockées (sys.dm_exec_procedure_stats), aux fonctions (sys.dm_exec_function_stats) et aux déclencheurs (sys.dm_exec_trigger_stats) sont également disponibles, mais considérez une charge de travail qui n'est pas purement des procédures stockées, des fonctions et des déclencheurs. Considérez une charge de travail mixte qui comporte des requêtes ad hoc, ou qui est peut-être entièrement ad hoc.
Exemple de scénario
En empruntant et en adaptant le code d'un article précédent, Examen de l'impact sur les performances d'une charge de travail ad hoc, nous allons d'abord créer deux procédures stockées. Le premier, dbo.RandomSelects, génère et exécute une instruction ad hoc, et le second, dbo.SPRandomSelects, génère et exécute une requête paramétrée.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Nous allons maintenant exécuter les deux procédures stockées 1 000 fois, en utilisant la même méthode décrite dans mon article précédent avec des fichiers .cmd appelant des fichiers .sql avec les instructions suivantes :
Contenu du fichier Adhoc.sql :
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Contenu du fichier.sql paramétré :
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Exemple de syntaxe dans le fichier .cmd qui appelle le fichier .sql :
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Si nous utilisons une variante de la requête Top Worker Time de Glenn pour examiner les principales requêtes basées sur le temps de travail (CPU) :
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
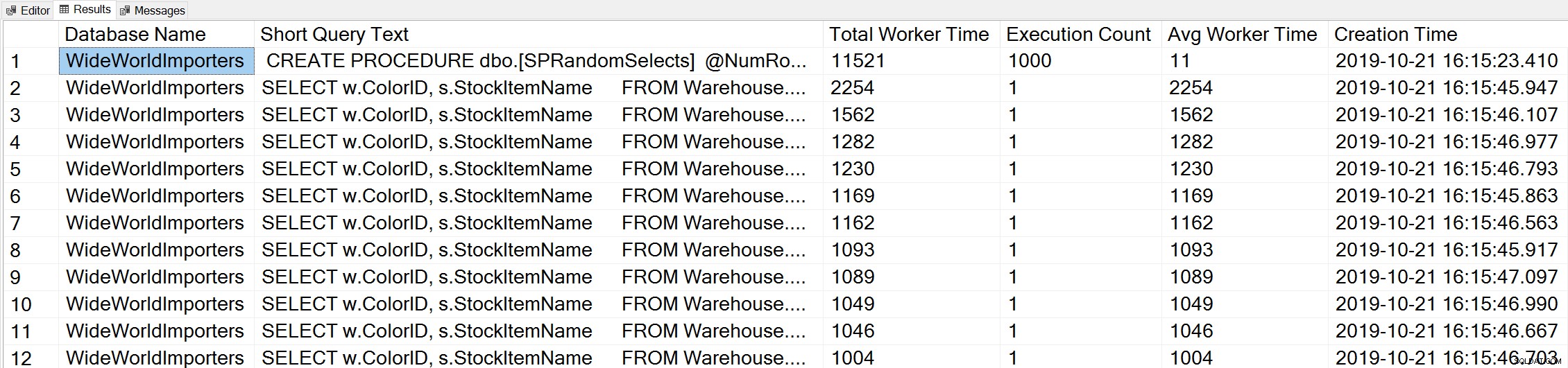
Nous voyons l'instruction de notre procédure stockée comme la requête qui s'exécute avec la plus grande quantité de CPU cumulée.
Si nous exécutons une variante de la requête Query Execution Counts de Glenn sur la base de données WideWorldImporters :
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
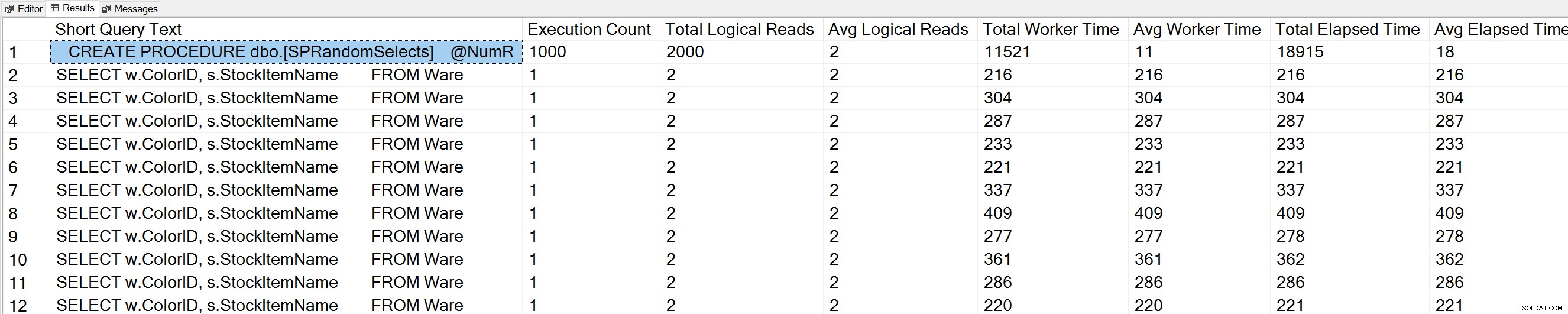
Nous voyons également notre déclaration de procédure stockée en haut de la liste.
Mais la requête ad hoc que nous avons exécutée, même si elle a des valeurs littérales différentes, était essentiellement la même instruction exécutée à plusieurs reprises, comme nous pouvons le voir en regardant le query_hash :
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
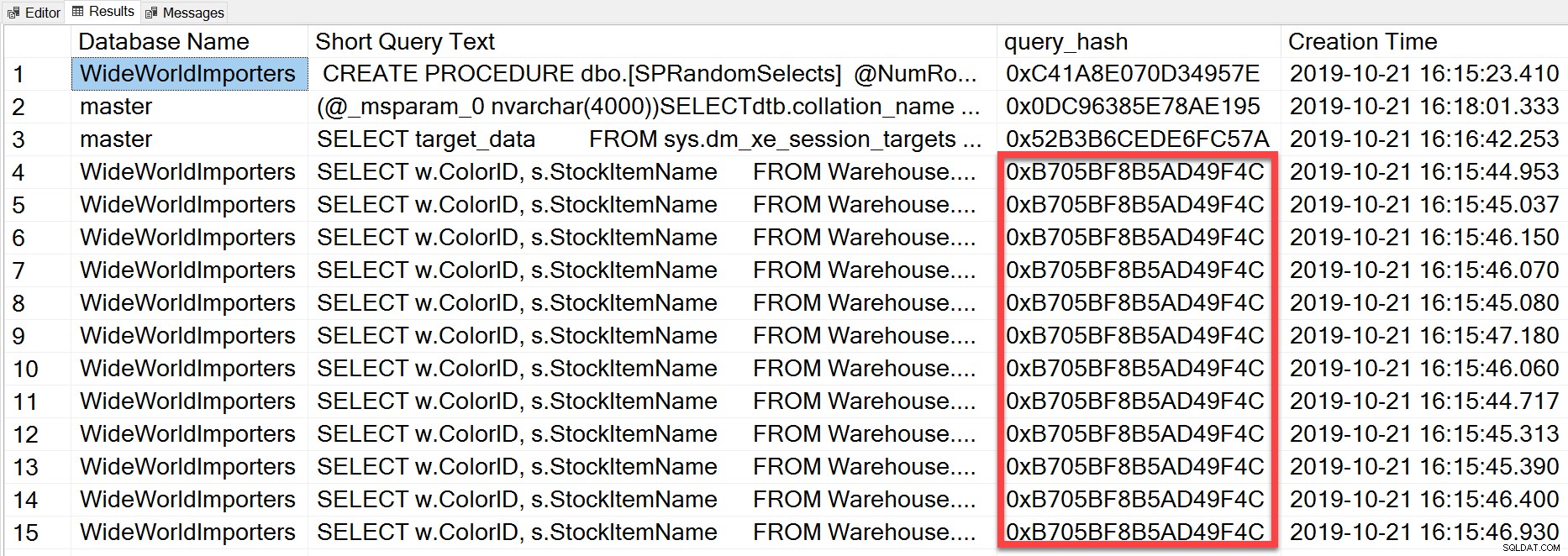
Le query_hash a été ajouté dans SQL Server 2008 et est basé sur l'arborescence des opérateurs logiques générés par l'optimiseur de requête pour le texte de l'instruction. Les requêtes qui ont un texte d'instruction similaire qui génère le même arbre d'opérateurs logiques auront le même query_hash, même si les valeurs littérales du prédicat de requête sont différentes. Bien que les valeurs littérales puissent être différentes, les objets et leurs alias doivent être identiques, ainsi que les indicateurs de requête et éventuellement les options SET. La procédure stockée RandomSelects génère des requêtes avec différentes valeurs littérales :
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Mais chaque exécution a exactement la même valeur pour le query_hash, 0xB705BF8B5AD49F4C. Afin de comprendre à quelle fréquence une requête ad hoc - et celles qui sont identiques en termes de query_hash - s'exécute, nous devons regrouper par l'ordre query_hash sur ce nombre, plutôt que de regarder execution_count dans sys.dm_exec_query_stats (qui montre souvent un valeur de 1).
Si nous changeons de contexte pour la base de données WideWorldImporters et recherchons les principales requêtes basées sur le nombre d'exécutions, où nous regroupons sur query_hash, nous pouvons maintenant voir à la fois la procédure stockée et notre requête ad hoc :
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Remarque :La DMV sys.dm_exec_function_stats a été ajoutée dans SQL Server 2016. L'exécution de cette requête sur SQL Server 2014 et versions antérieures nécessite la suppression de la référence à cette DMV.
Cette sortie fournit une compréhension beaucoup plus complète des requêtes réellement exécutées le plus fréquemment, car elle s'agrège en fonction du query_hash, et non en regardant simplement le execution_count dans sys.dm_exec_query_stats, qui peut avoir plusieurs entrées pour le même query_hash lorsque différentes valeurs littérales sont utilisé. La sortie de la requête inclut également query_plan_hash, qui peut être différente pour les requêtes avec le même query_hash. Ces informations supplémentaires sont utiles lors de l'évaluation des performances du plan pour une requête. Dans l'exemple ci-dessus, chaque requête a le même query_plan_hash, 0x299275DD475C4B17, démontrant que même avec des valeurs d'entrée différentes, l'optimiseur de requête génère le même plan - c'est stable. Lorsque plusieurs valeurs query_plan_hash existent pour le même query_hash, la variabilité du plan existe. Dans un scénario où la même requête, basée sur query_hash, s'exécute des milliers de fois, une recommandation générale consiste à paramétrer la requête. Si vous pouvez vérifier qu'aucune variabilité de plan n'existe, le paramétrage de la requête supprime le temps d'optimisation et de compilation pour chaque exécution, et peut réduire le CPU global. Dans certains scénarios, le paramétrage de cinq à dix requêtes ad hoc peut améliorer les performances du système dans son ensemble.
Résumé
Quel que soit l'environnement, il est important de comprendre quelles requêtes sont les plus coûteuses en termes d'utilisation des ressources et quelles requêtes s'exécutent le plus fréquemment. Le même ensemble de requêtes peut apparaître pour les deux types d'analyse lors de l'utilisation du script DMV de Glenn, ce qui peut être trompeur. En tant que tel, il est important d'établir si la charge de travail est principalement procédurale, principalement ad hoc ou mixte. Bien qu'il y ait beaucoup de documentation sur les avantages des procédures stockées, je trouve que les charges de travail mixtes ou hautement ad hoc sont très courantes, en particulier avec les solutions qui utilisent des mappeurs objet-relationnel (ORM) tels que Entity Framework, NHibernate et LINQ to SQL. Si vous n'êtes pas sûr du type de charge de travail d'un serveur, exécuter la requête ci-dessus pour examiner les requêtes les plus exécutées basées sur un query_hash est un bon début. Au fur et à mesure que vous commencez à comprendre la charge de travail et ce qui existe à la fois pour les gros frappeurs et les requêtes mortelles par milliers, vous pouvez passer à une véritable compréhension de l'utilisation des ressources et de l'impact de ces requêtes sur les performances du système, et cibler vos efforts de réglage.



