Ceci est la deuxième partie d'une série sur les solutions au défi du générateur de séries de nombres. Le mois dernier, j'ai couvert les solutions qui génèrent les lignes à la volée à l'aide d'un constructeur de valeurs de table avec des lignes basées sur des constantes. Aucune opération d'E/S n'était impliquée dans ces solutions. Ce mois-ci, je me concentre sur les solutions qui interrogent une table de base physique que vous pré-remplissez avec des lignes. Pour cette raison, en plus de rapporter le profil temporel des solutions comme je l'ai fait le mois dernier, je rapporterai également le profil d'E/S des nouvelles solutions. Merci encore à Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 et Ed Wagner pour avoir partagé vos idées et commentaires.
La solution la plus rapide à ce jour
Tout d'abord, pour rappel rapide, passons en revue la solution la plus rapide de l'article du mois dernier, implémentée sous la forme d'un TVF en ligne appelé dbo.GetNumsAlanCharlieItzikBatch.
Je vais faire mes tests dans tempdb, en activant les statistiques IO et TIME :
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
La solution la plus rapide du mois dernier applique une jointure avec une table factice qui a un index columnstore pour obtenir un traitement par lots. Voici le code pour créer la table factice :
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Et voici le code avec la définition de la fonction dbo.GetNumsAlanCharlieItzikBatch :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Le mois dernier, j'ai utilisé le code suivant pour tester les performances de la fonction avec 100 millions de lignes, après avoir activé les résultats de suppression après exécution dans SSMS pour supprimer le retour des lignes de sortie :
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =16031 ms, temps écoulé =17172 ms.Joe Obbish a correctement noté que ce test pouvait ne pas refléter certains scénarios réels dans le sens où une grande partie du temps d'exécution est due aux attentes d'E/S réseau asynchrones (type d'attente ASYNC_NETWORK_IO). Vous pouvez observer les temps d'attente les plus élevés en consultant la page de propriétés du nœud racine du plan de requête réel ou exécuter une session d'événements étendus avec des informations d'attente. Le fait que vous activiez Ignorer les résultats après exécution dans SSMS n'empêche pas SQL Server d'envoyer les lignes de résultats à SSMS; cela empêche simplement SSMS de les imprimer. La question est la suivante :quelle est la probabilité que vous renvoyiez de grands ensembles de résultats au client dans des scénarios réels, même lorsque vous utilisez la fonction pour produire une série de grands nombres ? Le plus souvent, vous écrivez peut-être les résultats de la requête dans une table ou utilisez le résultat de la fonction dans le cadre d'une requête qui produit finalement un petit ensemble de résultats. Vous devez comprendre cela. Vous pouvez écrire le jeu de résultats dans une table temporaire à l'aide de l'instruction SELECT INTO, ou vous pouvez utiliser l'astuce d'Alan Burstein avec une instruction SELECT d'affectation, qui affecte la valeur de la colonne de résultat à une variable.
Voici comment modifier le dernier test pour utiliser l'option d'affectation de variables :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de temps que j'ai obtenues pour ce test :
Temps CPU =8641 ms, temps écoulé =8645 ms.Cette fois, les informations d'attente n'ont pas d'attentes d'E/S réseau asynchrones, et vous pouvez voir la baisse significative du temps d'exécution.
Testez à nouveau la fonction, cette fois en ajoutant l'ordre :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
J'ai obtenu les statistiques de performances suivantes pour cette exécution :
Temps CPU =9360 ms, temps écoulé =9551 ms.Rappelez-vous qu'il n'y a pas besoin d'un opérateur de tri dans le plan pour cette requête puisque la colonne n est basée sur une expression qui préserve l'ordre par rapport à la colonne rownum. C'est grâce au truc de pliage constant de Charli, que j'ai couvert le mois dernier. Les plans pour les deux requêtes (celle sans tri et celle avec tri) sont les mêmes, donc les performances ont tendance à être similaires.
La figure 1 résume les chiffres de performance que j'ai obtenus pour les solutions du mois dernier, mais cette fois en utilisant l'affectation de variables dans les tests au lieu de rejeter les résultats après l'exécution.
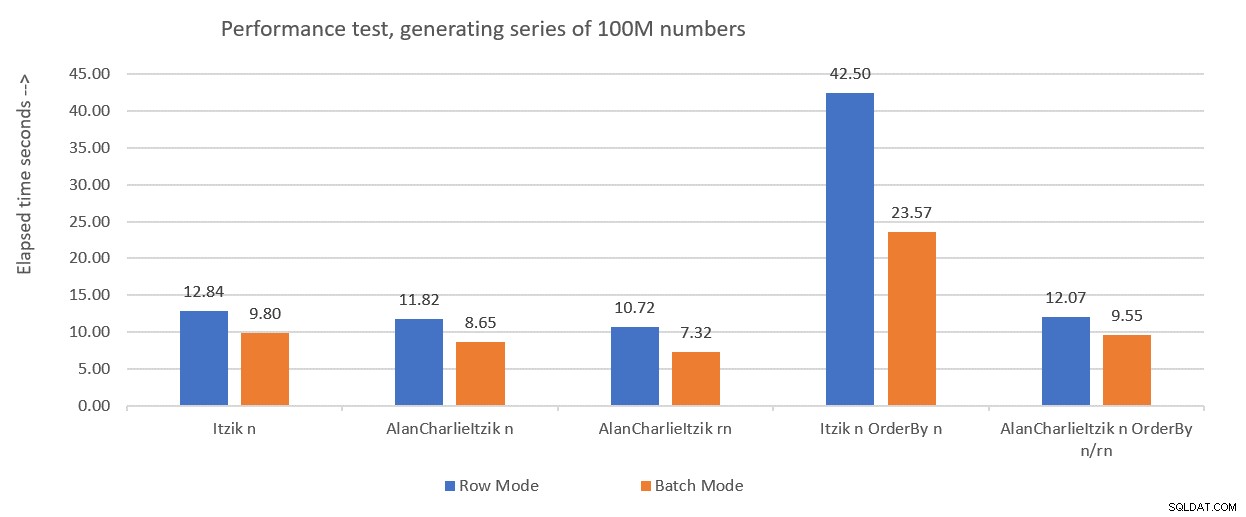 Figure 1 :Résumé des performances jusqu'à présent avec affectation de variables
Figure 1 :Résumé des performances jusqu'à présent avec affectation de variables
Je vais utiliser la technique d'affectation de variables pour tester le reste des solutions que je vais présenter dans cet article. Assurez-vous d'ajuster vos tests pour refléter au mieux votre situation réelle, en utilisant l'affectation de variables, SELECT INTO, Discard results after execution ou toute autre technique.
Astuce pour forcer les plans en série sans MAXDOP 1
Avant de présenter de nouvelles solutions, je voulais juste couvrir une petite astuce. Rappelez-vous que certaines des solutions fonctionnent mieux lors de l'utilisation d'un plan en série. Le moyen évident de forcer cela est d'utiliser un indicateur de requête MAXDOP 1. Et c'est la bonne voie à suivre si parfois vous souhaitez activer le parallélisme et parfois non. Cependant, que se passe-t-il si vous voulez toujours forcer un plan en série lors de l'utilisation de la fonction, bien que ce soit un scénario moins probable ?
Il y a une astuce pour y parvenir. L'utilisation d'une UDF scalaire non inlineable dans la requête est un inhibiteur de parallélisme. L'un des inhibiteurs d'inlining UDF scalaires invoque une fonction intrinsèque qui dépend du temps, telle que SYSDATETIME. Voici donc un exemple pour une UDF scalaire non inlineable :
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Une autre option consiste à définir une UDF avec juste une constante comme valeur renvoyée et à utiliser l'option INLINE =OFF dans son en-tête. Mais cette option n'est disponible qu'à partir de SQL Server 2019, qui a introduit l'intégration UDF scalaire. Avec la fonction suggérée ci-dessus, vous pouvez la créer telle quelle avec les anciennes versions de SQL Server.
Ensuite, modifiez la définition de la fonction dbo.GetNumsAlanCharlieItzikBatch pour avoir un appel factice à dbo.MySYSDATETIME (définissez une colonne basée sur celle-ci mais ne faites pas référence à la colonne dans la requête renvoyée), comme ceci :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Vous pouvez maintenant relancer le test de performances sans spécifier MAXDOP 1, et toujours obtenir un plan série :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Il est important de souligner cependant que toute requête utilisant cette fonction obtiendra désormais un plan de série. S'il y a une chance que la fonction soit utilisée dans des requêtes qui bénéficieront de plans parallèles, mieux vaut ne pas utiliser cette astuce, et lorsque vous avez besoin d'un plan en série, utilisez simplement MAXDOP 1.
Solution par Joe Obbish
La solution de Joe est assez créative. Voici sa propre description de la solution :
"J'ai opté pour la création d'un index columnstore clusterisé (CCI) avec 134 217 728 lignes d'entiers séquentiels. La fonction référence la table jusqu'à 32 fois pour obtenir toutes les lignes nécessaires au jeu de résultats. J'ai choisi un CCI parce que les données se compriment bien (moins de 3 octets par ligne), vous obtenez le mode batch "gratuitement", et l'expérience précédente suggère que la lecture de nombres séquentiels à partir d'un CCI sera plus rapide que de les générer par une autre méthode. ”Comme mentionné précédemment, Joe a également noté que mes tests de performances d'origine étaient considérablement faussés en raison des attentes d'E/S du réseau asynchrone générées par la transmission des lignes à SSMS. Donc, tous les tests que je vais effectuer ici utiliseront l'idée d'Alan avec l'affectation de variable. Assurez-vous d'ajuster vos tests en fonction de ce qui correspond le mieux à votre situation réelle.
Voici le code que Joe a utilisé pour créer la table dbo.GetNumsObbishTable et la remplir avec 134 217 728 lignes :
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Il a fallu 1:04 minutes pour terminer ce code sur ma machine.
Vous pouvez vérifier l'utilisation de l'espace de cette table en exécutant le code suivant :
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
J'ai utilisé environ 350 Mo d'espace. Par rapport aux autres solutions que je vais présenter dans cet article, celle-ci utilise beaucoup plus d'espace.
Dans l'architecture columnstore de SQL Server, un groupe de lignes est limité à 2^20 =1 048 576 lignes. Vous pouvez vérifier combien de groupes de lignes ont été créés pour ce tableau à l'aide du code suivant :
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); J'ai 128 groupes de lignes.
Voici le code avec la définition de la fonction dbo.GetNumsObbish :
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
Les 32 requêtes individuelles génèrent les sous-plages disjointes de 134 217 728 entiers qui, une fois unifiées, produisent la plage ininterrompue complète de 1 à 4 294 967 296. Ce qui est vraiment intelligent dans cette solution, ce sont les prédicats de filtre WHERE utilisés par les requêtes individuelles. Rappelez-vous que lorsque SQL Server traite un TVF en ligne, il applique d'abord l'incorporation de paramètres, en remplaçant les paramètres par les constantes d'entrée. SQL Server peut alors optimiser les requêtes qui produisent des sous-plages qui ne se croisent pas avec la plage d'entrée. Par exemple, lorsque vous demandez la plage d'entrée de 1 à 100 000 000, seule la première requête est pertinente et tout le reste est optimisé. Dans ce cas, le plan impliquera alors une référence à une seule instance de la table. C'est plutôt génial !
Testons les performances de la fonction avec la plage de 1 à 100 000 000 :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Le plan de cette requête est illustré à la figure 2.
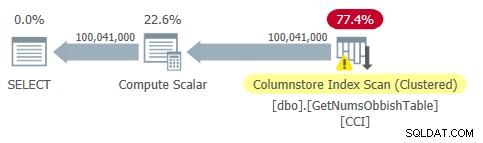 Figure 2 :Plan pour dbo.GetNumsObbish, 100 millions de lignes, non ordonnées
Figure 2 :Plan pour dbo.GetNumsObbish, 100 millions de lignes, non ordonnées
Observez qu'en effet une seule référence au CCI de la table est nécessaire dans ce plan.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
C'est assez impressionnant et de loin plus rapide que tout ce que j'ai pu tester.
Voici les statistiques d'E/S que j'ai obtenues pour cette exécution :
Tableau 'GetNumsObbishTable'. Nombre d'analyses 1, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob logical reads 32928 , lob physique lit 0, lob page serveur lit 0, lob lecture anticipée lit 0, lob page serveur lecture anticipée lit 0.Tableau 'GetNumsObbishTable'. Le segment lit 96 , segment sauté 32.
Le profil d'E/S de cette solution est l'un de ses inconvénients par rapport aux autres, entraînant plus de 30 000 lectures logiques lob pour cette exécution.
Pour voir que lorsque vous traversez plusieurs sous-plages de 134 217 728 entiers, le plan implique plusieurs références à la table, interrogez la fonction avec la plage de 1 à 400 000 000, par exemple :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Le plan de cette exécution est illustré à la figure 3.
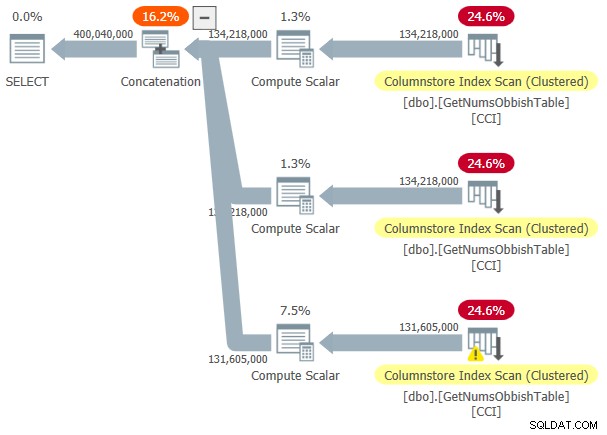 Figure 3 :Plan pour dbo.GetNumsObbish, 400 millions de lignes, non ordonnées
Figure 3 :Plan pour dbo.GetNumsObbish, 400 millions de lignes, non ordonnées
La plage demandée traversait trois sous-plages de 134 217 728 nombres entiers. Le plan montre donc trois références au CCI de la table.
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =20610 ms, temps écoulé =20628 ms.Et voici ses statistiques d'E/S :
Tableau 'GetNumsObbishTable'. Nombre d'analyses 3, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob logical reads 131026 , lob physique lit 0, lob page serveur lit 0, lob lecture anticipée lit 0, lob page serveur lecture anticipée lit 0.Tableau 'GetNumsObbishTable'. Le segment lit 382 , segment sauté 2.
Cette fois, l'exécution de la requête a généré plus de 130 000 lectures logiques lob.
Si vous pouvez supporter les coûts d'E/S et que vous n'avez pas besoin de traiter les séries de nombres de manière ordonnée, c'est une excellente solution. Toutefois, si vous devez traiter les séries dans l'ordre, cette solution entraînera un opérateur de tri dans le plan. Voici un test demandant le résultat commandé :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Le plan de cette exécution est illustré à la figure 4.
 Figure 4 :Plan pour dbo.GetNumsObbish, 100 millions de lignes, commandé
Figure 4 :Plan pour dbo.GetNumsObbish, 100 millions de lignes, commandé
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =44516 ms, temps écoulé =34836 ms.Comme vous pouvez le constater, les performances se sont considérablement dégradées, le temps d'exécution augmentant d'un ordre de grandeur en raison du tri explicite.
Voici les statistiques d'E/S que j'ai obtenues pour cette exécution :
Tableau 'GetNumsObbishTable'. Nombre d'analyses 4, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob logical reads 32928 , lob physique lit 0, lob page serveur lit 0, lob lecture anticipée lit 0, lob page serveur lecture anticipée lit 0.Tableau 'GetNumsObbishTable'. Le segment lit 96 , segment ignoré 32.
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lectures logiques lob 0, lectures physiques lob 0, lectures du serveur de pages lob 0, lectures lob- l'avance lit 0, la lecture anticipée du serveur de pages lob lit 0.
Observez qu'une table de travail est apparue dans la sortie de STATISTICS IO. En effet, un tri peut potentiellement déborder sur tempdb, auquel cas il utiliserait une table de travail. Cette exécution n'a pas renversé, donc les nombres sont tous des zéros dans cette entrée.
Solution par John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson # 2 a publié une solution qui est tout simplement magnifique dans sa simplicité. De plus, il comprend des idées et des suggestions des autres solutions de Dave, Joe, Alan, Charlie et moi-même.
Comme avec la solution de Joe, John a décidé d'utiliser un CCI pour obtenir un haut niveau de compression et un traitement par lots "gratuit". Seul John a décidé de remplir la table avec des lignes 4B avec un marqueur factice NULL dans une colonne de bits et de faire en sorte que la fonction ROW_NUMBER génère les nombres. Étant donné que les valeurs stockées sont toutes les mêmes, avec la compression des valeurs répétitives, vous avez besoin de beaucoup moins d'espace, ce qui entraîne beaucoup moins d'E/S par rapport à la solution de Joe. La compression Columnstore gère très bien les valeurs répétitives car elle ne peut représenter chacune de ces sections consécutives dans le segment de colonne d'un groupe de lignes qu'une seule fois avec le nombre d'occurrences répétées consécutivement. Étant donné que toutes les lignes ont la même valeur (le marqueur NULL), vous n'avez théoriquement besoin que d'une seule occurrence par groupe de lignes. Avec des lignes 4B, vous devriez vous retrouver avec 4 096 groupes de lignes. Chacun doit avoir un seul segment de colonnes, avec très peu d'espace requis.
Voici le code pour créer et remplir la table, implémenté en tant que CCI avec compression d'archivage :
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Le principal inconvénient de cette solution est le temps nécessaire pour remplir cette table. Il a fallu 12:32 minutes à ce code pour terminer sur ma machine en autorisant le parallélisme, et 15:17 minutes en forçant un plan série.
Notez que vous pourriez travailler sur l'optimisation du chargement des données. Par exemple, John a testé une solution qui chargeait les lignes à l'aide de 32 connexions simultanées avec OSTRESS.EXE, chacune exécutant 128 séries d'insertions de 2^20 lignes (taille maximale du groupe de lignes). Cette solution a réduit le temps de chargement de John à un tiers. Voici le code utilisé par John :
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"WITH L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) D(b)), L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B), L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B), nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Pourtant, le temps de chargement est en minutes. La bonne nouvelle est que vous n'avez besoin d'effectuer ce chargement de données qu'une seule fois.
La bonne nouvelle est le peu d'espace nécessaire à la table. Utilisez le code suivant pour vérifier l'utilisation de l'espace :
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
J'ai 1,64 Mo. C'est incroyable compte tenu du fait que le tableau comporte 4 milliards de lignes !
Utilisez le code suivant pour vérifier combien de groupes de lignes ont été créés :
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Comme prévu, le nombre de groupes de lignes est de 4 096.
La définition de la fonction dbo.GetNumsJohn2DaveObbishAlanCharlieItzik devient alors assez simple :
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Comme vous pouvez le voir, une requête simple sur la table utilise la fonction ROW_NUMBER pour calculer les numéros de ligne de base (colonne rownum), puis la requête externe utilise les mêmes expressions que dans dbo.GetNumsAlanCharlieItzikBatch pour calculer rn, op et n. Ici aussi, rn et n préservent l'ordre par rapport à rownum.
Testons les performances de la fonction :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
J'ai obtenu le plan illustré à la figure 5 pour cette exécution.
 Figure 5 :Plan pour dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figure 5 :Plan pour dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Voici les statistiques de temps que j'ai obtenues pour ce test :
Temps CPU =7593 ms, temps écoulé =7590 ms.
Comme vous pouvez le voir, le temps d'exécution n'est pas aussi rapide qu'avec la solution de Joe, mais il est toujours plus rapide que toutes les autres solutions que j'ai testées.
Voici les statistiques d'E/S que j'ai obtenues pour ce test :
Tableau 'NullBits4B'. Le segment lit 96 , segment ignoré 0
Notez que les exigences d'E/S sont nettement inférieures à celles de la solution de Joe.
L'autre avantage de cette solution est que lorsque vous avez besoin de traiter la série de numéros commandée, vous ne payez aucun supplément. En effet, cela n'entraînera pas d'opération de tri explicite dans le plan, que vous classiez le résultat par rn ou n.
Voici un test pour le démontrer :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Vous obtenez le même plan que celui illustré précédemment dans la figure 5.
Voici les statistiques de temps que j'ai obtenues pour ce test ;
Temps CPU =7578 ms, temps écoulé =7582 ms.Et voici les statistiques d'E/S :
Tableau 'NullBits4B'. Nombre d'analyses 1, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob lectures logiques 194 , lob physique lit 0, lob page serveur lit 0, lob lecture anticipée lit 0, lob page serveur lecture anticipée lit 0.Tableau 'NullBits4B'. Le segment lit 96 , segment ignoré 0.
Ils sont fondamentalement les mêmes que dans le test sans la commande.
Solution 2 par John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
La solution de John est simple et rapide. C'est fantastique. Le seul bémol est le temps de chargement. Parfois, ce ne sera pas un problème puisque le chargement ne se produit qu'une seule fois. Mais si c'est un problème, vous pouvez remplir la table avec 102 400 lignes au lieu de 4B lignes, et utiliser une jointure croisée entre deux instances de la table et un filtre TOP pour générer le maximum souhaité de 4B lignes. Notez que pour obtenir des lignes 4B, il suffirait de remplir la table avec 65 536 lignes, puis d'appliquer une jointure croisée ; cependant, pour que les données soient compressées immédiatement, au lieu d'être chargées dans un magasin delta basé sur un rowstore, vous devez charger la table avec un minimum de 102 400 lignes.
Voici le code pour créer et remplir le tableau :
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Le temps de chargement est négligeable — 43 ms sur ma machine.
Vérifiez la taille de la table sur le disque :
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
J'ai 56 Ko d'espace nécessaire pour les données.
Vérifiez le nombre de rowgroups, leur état (compressé ou ouvert) et leur taille :
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); J'ai obtenu le résultat suivant :
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Un seul groupe de lignes est nécessaire ici ; il est compressé et sa taille est négligeable, 293 octets.
Si vous remplissez la table avec une ligne de moins (102 399), vous obtenez un magasin delta ouvert non compressé basé sur un magasin de lignes. Dans un tel cas, sp_spaceused signale une taille de données sur le disque supérieure à 1 Mo, et sys.column_store_row_groups signale les informations suivantes :
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Assurez-vous donc de remplir le tableau avec 102 400 lignes !
Voici la définition de la fonction dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 :
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
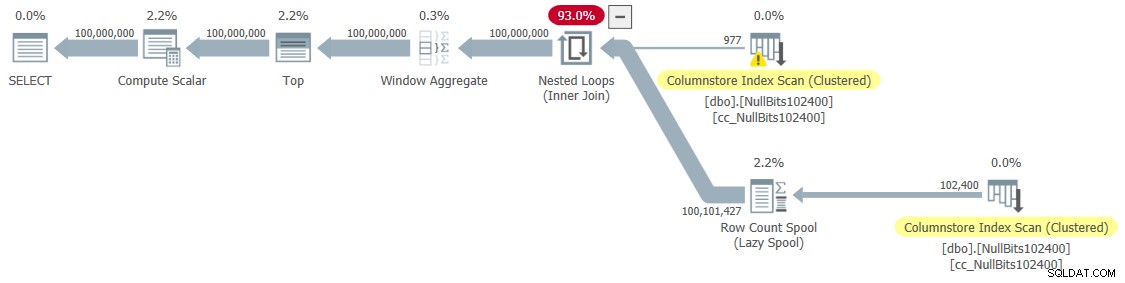 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
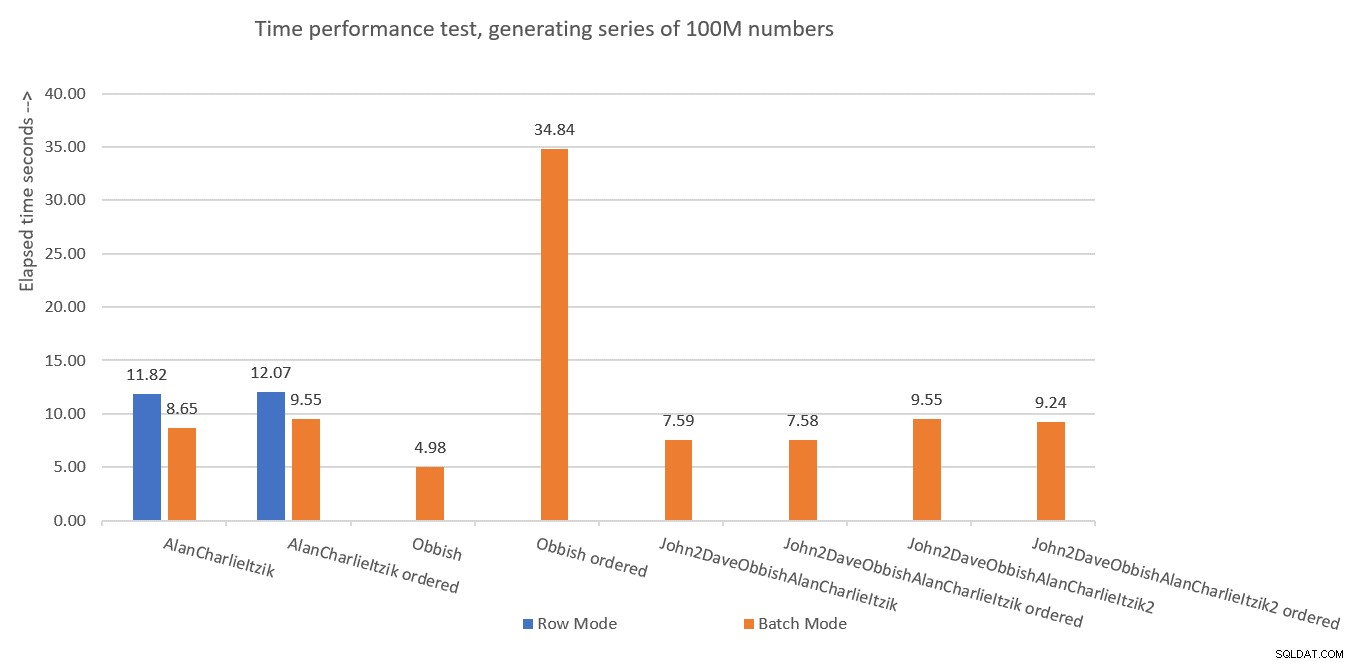 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
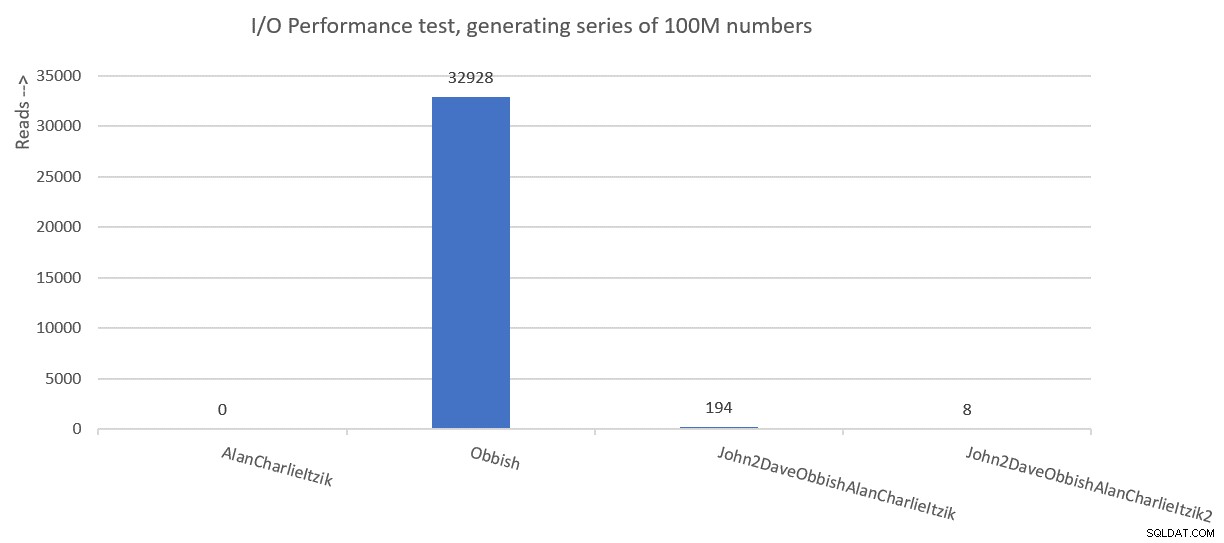 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.