Dans un conseil récent, j'ai décrit un scénario dans lequel une instance de SQL Server 2016 semblait avoir du mal avec les heures de point de contrôle. Le journal des erreurs a été rempli avec un nombre alarmant d'entrées FlushCache comme celle-ci :
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 J'étais un peu perplexe face à ce problème, car le système n'était certainement pas en reste - beaucoup de cœurs, 3 To de mémoire et un stockage XtremIO. Et aucun de ces messages FlushCache n'a jamais été associé aux avertissements d'E/S révélateurs de 15 secondes dans le journal des erreurs. Pourtant, si vous y empilez un tas de bases de données à transactions élevées, le traitement des points de contrôle peut devenir assez lent. Pas tant à cause des E/S directes, mais plus de réconciliation qui doit être faite avec un nombre massif de pages sales (pas seulement de committed transactions) dispersées sur une si grande quantité de mémoire, et potentiellement en attente du lazywriter (puisqu'il n'y en a qu'un pour toute l'instance).
J'ai fait quelques lectures rapides de "rafraîchissement" de certains messages très précieux :
- Comment fonctionnent les points de contrôle et ce qui est consigné
- Points de contrôle de la base de données (SQL Server)
- Que fait le point de contrôle pour tempdb ?
- Un mythe quotidien pour l'administrateur de bases de données SQL Server :(15/30) le point de contrôle n'écrit que les pages des transactions validées
- Les messages FlushCache peuvent ne pas être un véritable blocage d'E/S
- Point de contrôle indirect et tempdb :le bon, le mauvais et le planificateur sans rendement
- Modifier le temps de récupération cible d'une base de données
- Comment ça marche :quand le message FlushCache est-il ajouté au journal des erreurs SQL Server ?
- Modifications du comportement des points de contrôle de SQL Server 2016
- Intervalle de récupération cible et point de contrôle indirect :nouvelle valeur par défaut de 60 secondes dans SQL Server 2016
- SQL 2016 – Il s'exécute simplement plus rapidement :point de contrôle indirect par défaut
- SQL Server :grande RAM et points de contrôle de la base de données
J'ai rapidement décidé que je voulais suivre les durées des points de contrôle pour quelques-unes de ces bases de données les plus gênantes, avant et après avoir changé leur intervalle de récupération cible de 0 (l'ancienne méthode) à 60 secondes (la nouvelle méthode). En janvier, j'ai emprunté une session Extended Events à une amie et compatriote canadienne Hannah Vernon :
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; J'ai marqué l'heure à laquelle j'ai modifié chaque base de données, puis j'ai analysé les résultats des données d'événements étendus à l'aide d'une requête publiée dans l'astuce d'origine. Les résultats ont montré qu'après être passé aux points de contrôle indirects, chaque base de données est passée de points de contrôle d'une durée moyenne de 30 secondes à des points de contrôle d'une durée moyenne de moins d'un dixième de seconde (et beaucoup moins de points de contrôle dans la plupart des cas également). Il y a beaucoup à déballer de ce graphique, mais voici les données brutes que j'ai utilisées pour présenter mon argument (cliquez pour agrandir) :
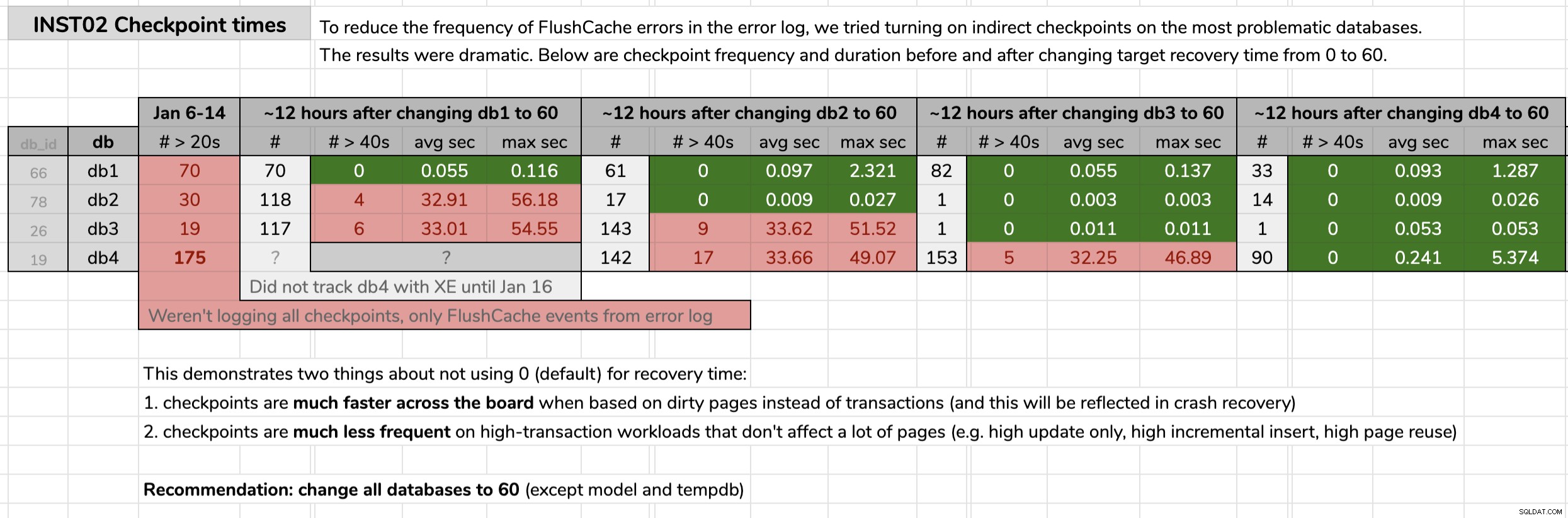 Mes preuves
Mes preuves
Une fois que j'ai prouvé mon cas dans ces bases de données problématiques, j'ai obtenu le feu vert pour l'implémenter dans toutes nos bases de données d'utilisateurs dans notre environnement. En développement d'abord, puis en production, j'ai exécuté ce qui suit via une requête CMS pour obtenir une jauge du nombre de bases de données dont nous parlions :
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Quelques notes sur la requête :
database_id > 4
Je ne voulais pas toucher aumasterdu tout, et je ne voulais pas changertempdbpourtant parce que nous ne sommes pas sur la dernière CU de SQL Server 2017 (voir KB #4497928 pour une raison pour laquelle ce détail est important). Ce dernier exclutmodel, également, car le changement de modèle affecteraittempdbau prochain basculement/redémarrage. J'aurais pu changermsdb, et j'y reviendrai peut-être à un moment donné, mais je me suis concentré ici sur les bases de données d'utilisateurs.
[state] / is_read_only / is_in_standby
Nous devons nous assurer que les bases de données que nous essayons de modifier sont en ligne et non en lecture seule (j'en ai sélectionné une qui était actuellement en lecture seule et je devrai y revenir plus tard).
OUTER APPLY (...)
Nous voulons limiter nos actions aux bases de données qui sont soit primaires dans un AG, soit pas du tout dans un AG (et doivent également tenir compte des AG distribués, où nous pouvons être primaires et locaux mais toujours pas accessibles en écriture) . S'il vous arrive d'exécuter la vérification sur un secondaire, vous ne pouvez pas résoudre le problème, mais vous devriez quand même recevoir un avertissement à ce sujet. Merci à Erik Darling pour son aide dans cette logique, et à Taylor Martell pour avoir motivé les améliorations.
- Si vous avez des instances exécutant des versions plus anciennes comme SQL Server 2008 R2 (j'en ai trouvé une !), vous devrez modifier un peu cela, car le
target_recovery_time_in_secondsla colonne n'existe pas ici. J'ai dû utiliser SQL dynamique pour contourner ce problème dans un cas, mais vous pouvez également déplacer ou supprimer temporairement l'emplacement de ces instances dans votre hiérarchie CMS. Vous ne pouvez pas non plus être paresseux comme moi et exécuter le code dans Powershell au lieu d'une fenêtre de requête CMS, où vous pouvez facilement filtrer les bases de données en fonction du nombre de propriétés avant de rencontrer des problèmes de compilation.
En production, il y avait 102 instances (environ la moitié) et 1 590 bases de données au total utilisant l'ancien paramètre. Tout était sur SQL Server 2017, alors pourquoi ce paramètre était-il si répandu ? Parce qu'ils ont été créés avant que les points de contrôle indirects ne deviennent la valeur par défaut dans SQL Server 2016. Voici un exemple des résultats :
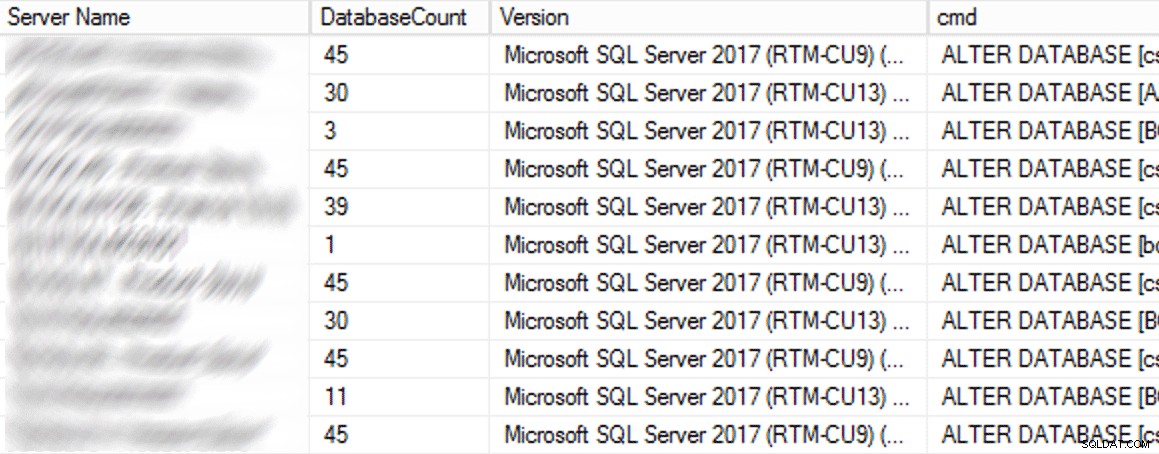 Résultats partiels de la requête CMS.
Résultats partiels de la requête CMS.
Ensuite, j'ai exécuté à nouveau la requête CMS, cette fois avec sys.sp_executesql non commenté. Il a fallu environ 12 minutes pour exécuter cela sur les 1 590 bases de données. En moins d'une heure, je recevais déjà des rapports de personnes observant une baisse significative du processeur sur certaines des instances les plus occupées.
J'ai encore plus à faire. Par exemple, je dois tester l'impact potentiel sur tempdb , et s'il y a un poids dans notre cas d'utilisation pour les histoires d'horreur que j'ai entendues. Et nous devons nous assurer que le paramètre de 60 secondes fait partie de notre automatisation et de toutes les demandes de création de base de données, en particulier celles qui sont scriptées ou restaurées à partir de sauvegardes.



