Dans cet article, nous nous concentrerons sur l'analyse opérationnelle en temps réel et sur la manière d'appliquer cette approche à une base de données OLTP. Lorsque nous examinons le modèle analytique traditionnel, nous pouvons voir que l'OLTP et les environnements analytiques sont des structures distinctes. Tout d'abord, les environnements de modèles analytiques traditionnels doivent créer des tâches ETL (Extraire, Transformer et Charger). Parce que nous devons transférer des données transactionnelles vers l'entrepôt de données. Ces types d'architecture présentent certains inconvénients. Ce sont le coût, la complexité et la latence des données. Afin d'éliminer ces inconvénients, nous avons besoin d'une approche différente.
Analyse opérationnelle en temps réel
Microsoft a annoncé l'analyse opérationnelle en temps réel dans SQL Server 2016. La capacité de cette fonctionnalité est de combiner la base de données transactionnelle et la charge de travail des requêtes analytiques sans aucun problème de performances. L'analyse opérationnelle en temps réel fournit :
- structure hybride
- les requêtes transactionnelles et analytiques peuvent être exécutées en même temps
- ne cause aucun problème de performances et de latence.
- une mise en œuvre simple.
Cette fonctionnalité peut surmonter les inconvénients de l'environnement analytique traditionnel. Le thème principal de cette fonctionnalité est que l'index du magasin de colonnes conserve une copie des données sans affecter les performances du système transactionnel. Ce thème permet aux requêtes analytiques de s'exécuter sans affecter les performances. Cela minimise donc l'impact sur les performances. La principale limitation de cette fonctionnalité est que nous ne pouvons pas collecter de données à partir de différentes sources de données.
Index de magasin de colonnes non clusterisées
SQL Server 2016 introduit un « index de magasin de colonnes non clusterisé » pouvant être mis à jour. L'index de magasin de colonnes non clusterisé est un index basé sur des colonnes qui offre des avantages en termes de performances pour les requêtes analytiques. Cette fonctionnalité nous permet de créer le cadre d'analyse opérationnelle en temps réel. Cela signifie que nous pouvons exécuter des transactions et des requêtes analytiques en même temps. Considérez que nous avons besoin des ventes totales mensuelles. Dans un modèle traditionnel, nous devons développer des tâches ETL, un magasin de données et un entrepôt de données. Mais dans l'analyse opérationnelle en temps réel, nous pouvons le faire sans nécessiter d'entrepôt de données ni de modification de la structure OLTP. Nous avons seulement besoin de créer un index de magasin de colonnes non clusterisé approprié.
Architecture de l'index de magasin de colonnes non clusterisé
Examinons brièvement l'architecture de l'index de magasin de colonnes non clusterisé et du mécanisme d'exécution. L'index de magasin de colonnes non clusterisé contient une copie d'une partie ou de toutes les lignes et colonnes de la table sous-jacente. Le thème principal de l'index de magasin de colonnes non clusterisé est de conserver une copie des données et d'utiliser cette copie des données. Ainsi, ce mécanisme minimise l'impact sur les performances de la base de données transactionnelle. L'index de magasin de colonnes non clusterisé peut créer une ou plusieurs colonnes et peut appliquer un filtre aux colonnes.
Lorsque nous insérons une nouvelle ligne dans une table qui a un index de magasin de colonnes non clusterisé, tout d'abord, SQL Server crée un "rowgroup". Rowgroup est une structure logique qui représente un ensemble de lignes. Ensuite, SQL Server stocke ces lignes dans un stockage temporaire. Le nom de ce stockage temporaire est "deltastore". SQL Server utilise cette zone de stockage temporaire car ce mécanisme améliore le taux de compression et réduit la fragmentation de l'index. Lorsque le nombre de lignes atteint 1 048 577, SQL Server ferme l'état du groupe de lignes. SQL Server compresse ce groupe de lignes et change l'état en "compressé".
Maintenant, nous allons créer une table et ajouter l'index du magasin de colonnes non clusterisé.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
Dans cette étape, nous allons insérer plusieurs lignes et examiner les propriétés de l'index de magasin de colonnes non clusterisé.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Cette requête affichera les états des groupes de lignes, le nombre total de tailles de lignes et d'autres valeurs.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

L'image ci-dessus nous montre l'état du deltastore et le nombre total de lignes non compressées. Maintenant, nous allons remplir plus de données dans la table et lorsque le nombre de lignes atteindra 1 048 577, SQL Server fermera le premier groupe de lignes et ouvrira un nouveau groupe de lignes.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server va compresser ce groupe de lignes et créer un nouveau groupe de lignes. L'option "COMPRESSION_DELAY" nous permet de contrôler combien de temps le rowgroup attend dans le statut fermé.

Lorsque nous exécutons les commandes de maintenance de l'index (réorganiser, reconstruire), les lignes supprimées sont physiquement supprimées et l'index est défragmenté.

Lorsque nous mettons à jour (supprimer + insérer) certaines lignes de ce tableau, les lignes supprimées sont marquées comme "supprimées" et les nouvelles lignes mises à jour sont insérées dans le deltastore.
Besoin de performance des requêtes analytiques
Dans cet en-tête, nous remplirons les données de la table Analysis_TableTest. J'ai inséré 4 millions d'enregistrements. (Vous devez tester cette étape et les étapes suivantes dans votre environnement de test. Des problèmes de performances peuvent survenir et la commande DBCC DROPCLEANBUFFERS peut nuire aux performances. Cette commande supprimera toutes les données de tampon sur le pool de tampons.)
Nous allons maintenant exécuter la requête analytique suivante et examiner les valeurs de performances.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

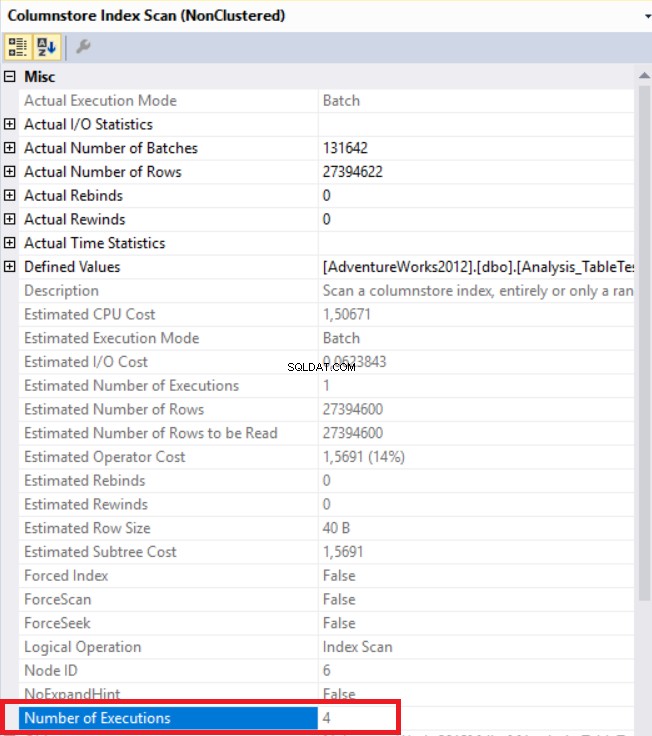
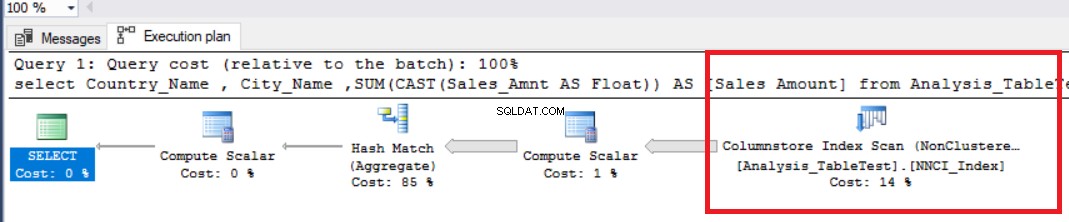
Dans l'image ci-dessus, nous pouvons voir l'opérateur d'analyse d'index de magasin de colonnes non clusterisé. Le tableau ci-dessous montre les temps CPU et d'exécution. Cette requête consomme 1,765 millisecondes en CPU et se termine en 0,791 millisecondes. Le temps CPU est supérieur au temps écoulé car le plan d'exécution utilise des processeurs parallèles et répartit les tâches sur 4 processeurs. Nous pouvons le voir dans les propriétés de l'opérateur "Columnstore Index Scan". La valeur "Nombre d'exécutions" l'indique.

Nous allons maintenant ajouter un indice à la requête pour réduire le nombre de processeurs. Nous ne verrons aucun opérateur de parallélisme.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

Le tableau ci-dessous définit les temps d'exécution. Dans ce graphique, nous pouvons voir que le temps écoulé est supérieur au temps CPU car SQL Server n'a utilisé qu'un seul processeur.
Nous allons maintenant désactiver l'index du magasin de colonnes non clusterisé et exécuter la même requête.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

Le tableau ci-dessus nous montre que l'index de magasin de colonnes non clusterisé offre des performances incroyables dans les requêtes analytiques. Approximativement, la requête indexée du magasin de colonnes est cinq fois meilleure que l'autre.
Conclusion
L'analyse opérationnelle en temps réel offre une flexibilité incroyable car nous pouvons exécuter des requêtes analytiques dans les systèmes OLTP sans aucune latence de données. Dans le même temps, ces requêtes analytiques n'affectent pas les performances de la base de données OLTP. Cette fonctionnalité nous permet de gérer les données transactionnelles et les requêtes analytiques dans le même environnement.
Références
Index de magasin de colonnes – Guide de chargement des données
Démarrez avec Column Store pour des analyses opérationnelles en temps réel
Analyse opérationnelle en temps réel
Autres lectures :
Analyse en arrière de l'index SQL Server :compréhension, réglage
Utilisation des index dans les tables optimisées en mémoire SQL Server



