Cet article est la cinquième partie d'une série sur les expressions de table. Dans la partie 1, j'ai fourni le contexte des expressions de table. Dans les parties 2, 3 et 4, j'ai couvert à la fois les aspects logiques et d'optimisation des tables dérivées. Ce mois-ci, je commence la couverture des expressions de table communes (CTE). Comme pour les tables dérivées, je vais d'abord aborder le traitement logique des CTE, et à l'avenir, j'aborderai les considérations d'optimisation.
Dans mes exemples, j'utiliserai un exemple de base de données appelé TSQLV5. Vous pouvez trouver le script qui le crée et le remplit ici, et son diagramme ER ici.
CTE
Commençons par le terme expression de table commune . Ni ce terme, ni son acronyme CTE, n'apparaissent dans les spécifications de la norme ISO/IEC SQL. Il se peut donc que le terme soit originaire de l'un des produits de base de données et adopté plus tard par certains des autres fournisseurs de bases de données. Vous pouvez le trouver dans la documentation de Microsoft SQL Server et Azure SQL Database. T-SQL le prend en charge à partir de SQL Server 2005. La norme utilise le terme expression de requête pour représenter une expression qui définit un ou plusieurs CTE, y compris la requête externe. Il utilise le terme avec élément de liste pour représenter ce que T-SQL appelle un CTE. Je fournirai la syntaxe d'une expression de requête sous peu.
Mis à part la source du terme, expression de table commune , ou CTE , est le terme couramment utilisé par les praticiens T-SQL pour désigner la structure qui fait l'objet de cet article. Alors d'abord, voyons si c'est un terme approprié. Nous avons déjà conclu que le terme expression de table est approprié pour une expression qui renvoie conceptuellement une table. Les tables dérivées, les CTE, les vues et les fonctions de table en ligne sont tous des types d'expressions de table nommées que T-SQL prend en charge. Ainsi, l'expression de table partie de l'expression de table commune semble certainement approprié. Quant au commun partie du terme, cela a probablement à voir avec l'un des avantages de conception des CTE par rapport aux tables dérivées. N'oubliez pas que vous ne pouvez pas réutiliser le nom de la table dérivée (ou plus précisément le nom de la variable de plage) plus d'une fois dans la requête externe. Inversement, le nom CTE peut être utilisé plusieurs fois dans la requête externe. En d'autres termes, le nom CTE est courant à la requête externe. Bien sûr, je vais démontrer cet aspect du design dans cet article.
Les CTE vous offrent des avantages similaires aux tables dérivées, notamment en permettant le développement de solutions modulaires, en réutilisant les alias de colonne, en interagissant indirectement avec les fonctions de fenêtre dans des clauses qui ne les autorisent normalement pas, en prenant en charge les modifications qui reposent indirectement sur TOP ou OFFSET FETCH avec la spécification de commande, et d'autres. Mais il existe certains avantages de conception par rapport aux tables dérivées, que je couvrirai en détail après avoir fourni la syntaxe de la structure.
Syntaxe
Voici la syntaxe standard pour une expression de requête :
7.17
Fonction
Spécifiez une table.
Le terme standard expression de requête représente une expression impliquant une clause WITH, une liste with , qui est composé d'un ou plusieurs avec des éléments de liste , et une requête externe. T-SQL fait référence au standard avec élément de liste en tant que CTE.
T-SQL ne prend pas en charge tous les éléments de syntaxe standard. Par exemple, il ne prend pas en charge certains des éléments de requête récursifs les plus avancés qui vous permettent de contrôler la direction de la recherche et de gérer les cycles dans une structure de graphique. Les requêtes récursives sont au centre de l'article du mois prochain.
Voici la syntaxe T-SQL pour une requête simplifiée sur un CTE :
Voici un exemple de requête simple sur un CTE représentant des clients américains :
Vous trouverez les trois mêmes parties dans une déclaration contre un CTE comme vous le feriez avec une déclaration contre une table dérivée :
Ce qui est différent dans la conception des CTE par rapport aux tables dérivées, c'est l'endroit où se trouvent ces trois éléments dans le code. Avec les tables dérivées, la requête interne est imbriquée dans la clause FROM de la requête externe et le nom de l'expression de table est attribué après l'expression de table elle-même. Les éléments sont en quelque sorte entrelacés. Inversement, avec les CTE, le code sépare les trois éléments :d'abord vous attribuez le nom de l'expression de table; deuxièmement, vous spécifiez l'expression de table, du début à la fin sans interruption ; troisièmement, vous spécifiez la requête externe, du début à la fin sans interruption. Plus tard, sous "Considérations de conception", j'expliquerai les implications de ces différences de conception.
Un mot sur les CTE et l'utilisation d'un point-virgule comme terminateur d'instruction. Malheureusement, contrairement au SQL standard, T-SQL ne vous oblige pas à terminer toutes les instructions par un point-virgule. Cependant, il existe très peu de cas dans T-SQL où, sans terminateur, le code est ambigu. Dans ces cas, la résiliation est obligatoire. Un de ces cas concerne le fait que la clause WITH est utilisée à des fins multiples. L'une consiste à définir un CTE, une autre à définir un indicateur de table pour une requête, et il existe quelques cas d'utilisation supplémentaires. Par exemple, dans l'instruction suivante, la clause WITH est utilisée pour forcer le niveau d'isolement sérialisable avec un indicateur de table :
Le potentiel d'ambiguïté est lorsque vous avez une instruction non terminée précédant une définition CTE, auquel cas l'analyseur peut ne pas être en mesure de dire si la clause WITH appartient à la première ou à la deuxième instruction. Voici un exemple démontrant ceci :
Ici, l'analyseur ne peut pas dire si la clause WITH est censée être utilisée pour définir un indicateur de table pour la table Customers dans la première instruction, ou pour démarrer une définition CTE. Vous obtenez l'erreur suivante :
La solution consiste bien sûr à terminer l'instruction précédant la définition CTE, mais en tant que meilleure pratique, vous devriez vraiment terminer toutes vos instructions :
Vous avez peut-être remarqué que certaines personnes commencent leurs définitions CTE par un point-virgule comme pratique, comme ceci :
Le but de cette pratique est de réduire le risque d'erreurs futures. Que se passe-t-il si, plus tard, quelqu'un ajoute une instruction non terminée juste avant votre définition CTE dans le script, et ne prend pas la peine de vérifier le script complet, mais uniquement sa déclaration ? Votre point-virgule juste avant la clause WITH devient effectivement leur terminateur d'instruction. Vous pouvez certainement voir le caractère pratique de cette pratique, mais c'est un peu contre nature. Ce qui est recommandé, bien que plus difficile à réaliser, est d'inculquer de bonnes pratiques de programmation dans l'organisation, y compris la fin de toutes les déclarations.
En termes de règles de syntaxe qui s'appliquent à l'expression de table utilisée comme requête interne dans la définition CTE, elles sont identiques à celles qui s'appliquent à l'expression de table utilisée comme requête interne dans une définition de table dérivée. Ce sont :
Pour plus de détails, consultez la section "Une expression de table est une table" dans la partie 2 de la série.
Si vous demandez à des développeurs T-SQL expérimentés s'ils préfèrent utiliser des tables dérivées ou des CTE, tout le monde ne sera pas d'accord sur ce qui est le mieux. Naturellement, différentes personnes ont des préférences de style différentes. J'utilise parfois des tables dérivées et parfois des CTE. Il est bon de pouvoir identifier consciemment les différences de conception de langage spécifiques entre les deux outils et de choisir en fonction de vos priorités dans une solution donnée. Avec le temps et l'expérience, vous faites vos choix de manière plus intuitive.
De plus, il est important de ne pas confondre l'utilisation des expressions de table et des tables temporaires, mais c'est une discussion liée aux performances que j'aborderai dans un prochain article.
Les CTE ont des capacités d'interrogation récursives et les tables dérivées n'en ont pas. Donc, si vous devez compter sur ceux-ci, vous opterez naturellement pour les CTE. Les requêtes récursives sont au centre de l'article du mois prochain.
Dans la partie 2, j'ai expliqué que je considère l'imbrication des tables dérivées comme ajoutant de la complexité au code, car il est difficile de suivre la logique. J'ai fourni l'exemple suivant, identifiant les années de commande au cours desquelles plus de 70 clients ont passé des commandes :
Les CTE ne prennent pas en charge l'imbrication. Ainsi, lorsque vous examinez ou dépannez une solution basée sur les CTE, vous ne vous perdez pas dans la logique imbriquée. Au lieu d'imbriquer, vous créez des solutions plus modulaires en définissant plusieurs CTE sous la même instruction WITH, séparés par des virgules. Chacun des CTE est basé sur une requête écrite du début à la fin sans interruption. Je le vois comme une bonne chose du point de vue de la clarté du code et de la maintenabilité.
Voici une solution à la tâche susmentionnée à l'aide de CTE :
J'aime mieux la solution basée sur CTE. Mais encore une fois, demandez aux développeurs expérimentés laquelle des deux solutions ci-dessus ils préfèrent, et ils ne seront pas tous d'accord. Certains préfèrent en fait la logique imbriquée et la possibilité de tout voir au même endroit.
Un avantage très clair des CTE par rapport aux tables dérivées est lorsque vous devez interagir avec plusieurs instances de la même expression de table dans votre solution. Souvenez-vous de l'exemple suivant basé sur les tables dérivées de la partie 2 de la série :
Cette solution renvoie les années de commande, le nombre de commandes par an et la différence entre les nombres de l'année en cours et de l'année précédente. Oui, vous pourriez le faire plus facilement avec la fonction LAG, mais mon objectif ici n'est pas de trouver le meilleur moyen d'accomplir cette tâche très spécifique. J'utilise cet exemple pour illustrer certains aspects de la conception du langage des expressions de table nommées.
Le problème avec cette solution est que vous ne pouvez pas attribuer un nom à une expression de table et la réutiliser dans la même étape de traitement de requête logique. Vous nommez une table dérivée d'après l'expression de table elle-même dans la clause FROM. Si vous définissez et nommez une table dérivée comme première entrée d'une jointure, vous ne pouvez pas également réutiliser ce nom de table dérivée comme deuxième entrée de la même jointure. Si vous avez besoin d'auto-joindre deux instances de la même expression de table, avec des tables dérivées, vous n'avez pas d'autre choix que de dupliquer le code. C'est ce que vous avez fait dans l'exemple ci-dessus. A l'inverse, le nom CTE est attribué comme premier élément du code parmi les trois précités (nom CTE, requête interne, requête externe). En termes de traitement logique des requêtes, au moment où vous arrivez à la requête externe, le nom CTE est déjà défini et disponible. Cela signifie que vous pouvez interagir avec plusieurs instances du nom CTE dans la requête externe, comme suit :
Cette solution présente un net avantage de programmabilité par rapport à celle basée sur des tables dérivées dans la mesure où vous n'avez pas besoin de conserver deux copies de la même expression de table. Il y a plus à dire à ce sujet du point de vue du traitement physique et à comparer avec l'utilisation de tables temporaires, mais je le ferai dans un prochain article qui se concentrera sur les performances.
L'un des avantages du code basé sur des tables dérivées par rapport au code basé sur des CTE est lié à la propriété de fermeture qu'une expression de table est censée posséder. Rappelez-vous que la propriété de fermeture d'une expression relationnelle indique que les entrées et la sortie sont des relations, et qu'une expression relationnelle peut donc être utilisée là où une relation est attendue, comme entrée d'encore une autre expression relationnelle. De même, une expression de table renvoie une table et est censée être disponible en tant que table d'entrée pour une autre expression de table. Cela est vrai pour une requête basée sur des tables dérivées :vous pouvez l'utiliser là où une table est attendue. Par exemple, vous pouvez utiliser une requête basée sur des tables dérivées comme requête interne d'une définition CTE, comme dans l'exemple suivant :
Cependant, il n'en va pas de même pour une requête basée sur les CTE. Même si elle est conceptuellement censée être considérée comme une expression de table, vous ne pouvez pas l'utiliser comme requête interne dans les définitions de table dérivées, les sous-requêtes et les CTE eux-mêmes. Par exemple, le code suivant n'est pas valide dans T-SQL :
La bonne nouvelle est que vous pouvez utiliser une requête basée sur les CTE comme requête interne dans les vues et les fonctions table en ligne, que je couvrirai dans de futurs articles.
N'oubliez pas non plus que vous pouvez toujours définir un autre CTE en fonction de la dernière requête, puis faire interagir la requête la plus externe avec ce CTE :
Du point de vue du dépannage, comme mentionné, je trouve généralement plus facile de suivre la logique du code basé sur les CTE, par rapport au code basé sur des tables dérivées. Cependant, les solutions basées sur des tables dérivées ont l'avantage de pouvoir mettre en surbrillance n'importe quel niveau d'imbrication et de l'exécuter indépendamment, comme illustré à la figure 1.
Avec les CTE, les choses sont plus délicates. Pour que le code impliquant des CTE soit exécutable, il doit commencer par une clause WITH, suivie d'une ou plusieurs expressions de table entre parenthèses nommées séparées par des virgules, suivies d'une requête sans parenthèses sans virgule précédente. Vous pouvez mettre en évidence et exécuter n'importe laquelle des requêtes internes véritablement autonomes, ainsi que le code complet de la solution ; cependant, vous ne pouvez pas mettre en surbrillance et exécuter avec succès toute autre partie intermédiaire de la solution. Par exemple, la figure 2 montre une tentative infructueuse d'exécution du code représentant C2.
Ainsi avec les CTE, il faut recourir à des moyens un peu maladroits pour pouvoir dépanner une étape intermédiaire de la solution. Par exemple, une solution courante consiste à injecter temporairement une requête SELECT * FROM your_cte juste en dessous du CTE concerné. Vous mettez ensuite en surbrillance et exécutez le code, y compris la requête injectée, et lorsque vous avez terminé, vous supprimez la requête injectée. La figure 3 illustre cette technique.
Le problème est que chaque fois que vous apportez des modifications au code, même des modifications mineures temporaires comme ci-dessus, il est possible que lorsque vous essayez de revenir au code d'origine, vous finissiez par introduire un nouveau bogue.
Une autre option consiste à styliser votre code un peu différemment, de sorte que chaque définition CTE qui n'est pas la première commence par une ligne de code distincte qui ressemble à ceci :
Ensuite, chaque fois que vous souhaitez exécuter une partie intermédiaire du code jusqu'à un CTE donné, vous pouvez le faire avec des modifications minimes de votre code. En utilisant un commentaire de ligne, vous commentez uniquement la ligne de code qui correspond à ce CTE. Vous mettez ensuite en surbrillance et exécutez le code jusqu'à et y compris la requête interne de ce CTE, qui est maintenant considérée comme la requête la plus externe, comme illustré à la figure 4.
Si vous n'êtes pas satisfait de ce style, vous avez encore une autre option. Vous pouvez utiliser un commentaire de bloc qui commence juste avant la virgule qui précède le CTE d'intérêt et se termine après la parenthèse ouvrante, comme illustré à la figure 5.
Cela se résume à des préférences personnelles. J'utilise généralement la technique de requête SELECT * injectée temporairement.
Il existe une certaine limitation dans la prise en charge par T-SQL des constructeurs de valeurs de table par rapport à la norme. Si vous n'êtes pas familier avec la construction, assurez-vous de consulter d'abord la partie 2 de la série, où je la décris en détail. Alors que T-SQL vous permet de définir une table dérivée basée sur un constructeur de valeur de table, il ne vous permet pas de définir un CTE basé sur un constructeur de valeur de table.
Voici un exemple pris en charge qui utilise une table dérivée :
Malheureusement, un code similaire qui utilise un CTE n'est pas pris en charge :
Ce code génère l'erreur suivante :
Il existe cependant quelques solutions de contournement. L'une consiste à utiliser une requête sur une table dérivée, qui à son tour est basée sur un constructeur de valeur de table, en tant que requête interne du CTE, comme ceci :
Une autre consiste à recourir à la technique que les gens utilisaient avant l'introduction des constructeurs de valeurs de table dans T-SQL, en utilisant une série de requêtes FROMless séparées par des opérateurs UNION ALL, comme ceci :
Notez que les alias de colonne sont attribués juste après le nom CTE.
Les deux méthodes sont algébrisées et optimisées de la même manière, alors utilisez celle avec laquelle vous êtes le plus à l'aise.
Un outil que j'utilise assez souvent dans mes solutions est une table auxiliaire de nombres. Une option consiste à créer une table de nombres réels dans votre base de données et à la remplir avec une séquence de taille raisonnable. Une autre consiste à développer une solution qui produit une séquence de nombres à la volée. Pour cette dernière option, vous voulez que les entrées soient les délimiteurs de la plage souhaitée (nous les appellerons
Ce code génère la sortie suivante :
Le premier CTE appelé L0 est basé sur un constructeur de valeurs de table à deux lignes. Les valeurs réelles y sont insignifiantes; ce qui est important, c'est qu'il a deux rangées. Ensuite, il y a une séquence de cinq CTE supplémentaires nommés L1 à L5, chacun appliquant une jointure croisée entre deux instances du CTE précédent. Le code suivant calcule le nombre de lignes potentiellement générées par chacun des CTE, où @L est le numéro de niveau CTE :
Voici les chiffres que vous obtenez pour chaque CTE :
Monter au niveau 5 vous donne plus de quatre milliards de lignes. Cela devrait être suffisant pour tout cas d'utilisation pratique auquel je peux penser. La prochaine étape a lieu dans le CTE appelé Nums. Vous utilisez une fonction ROW_NUMBER pour générer une séquence d'entiers commençant par 1 sans ordre défini (ORDER BY (SELECT NULL)) et nommez la colonne de résultat rownum. Enfin, la requête externe utilise un filtre TOP basé sur l'ordre rownum pour filtrer autant de nombres que la cardinalité de séquence souhaitée (@high – @low + 1), et calcule le résultat n comme @low + rownum – 1.
Ici, vous pouvez vraiment apprécier la beauté de la conception CTE et les économies qu'elle permet lorsque vous construisez des solutions de manière modulaire. En fin de compte, le processus de désimbrication décompresse 32 tables, chacune composée de deux lignes basées sur des constantes. Cela peut être clairement vu dans le plan d'exécution de ce code, comme illustré à la figure 6 à l'aide de SentryOne Plan Explorer.
Chaque opérateur Constant Scan représente un tableau de constantes à deux lignes. Le fait est que l'opérateur Top est celui qui demande ces lignes, et il court-circuite après avoir obtenu le nombre souhaité. Remarquez les 10 lignes indiquées au-dessus de la flèche entrant dans l'opérateur supérieur.
Je sais que cet article se concentre sur le traitement conceptuel des CTE et non sur des considérations physiques/de performance, mais en regardant le plan, vous pouvez vraiment apprécier la brièveté du code par rapport à la profusion de ce qu'il se traduit dans les coulisses.
À l'aide de tables dérivées, vous pouvez en fait écrire une solution qui remplace chaque référence CTE par la requête sous-jacente qu'elle représente. Ce que vous obtenez est assez effrayant :
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formater
[
[
AS [
|
[
|
[
|
[
|
[
::=TABLE
CORRESPONDING [ BY
FETCH { FIRST | NEXT } [
|
7.18
Fonction
Spécifiez la génération d'informations de tri et de détection de cycle dans le résultat des expressions de requête récursives.
Formater
SEARCH
DEPTH FIRST BY
CYCLE
DEFAULT
7.3
Fonction
Spécifiez un ensemble de
Formater
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Syntaxe incorrecte près de 'UC'. S'il s'agit d'une expression de table commune, vous devez explicitement terminer l'instruction précédente par un point-virgule. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Considérations de conception
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figure 1 :peut mettre en surbrillance et exécuter une partie du code avec des tables dérivées
Figure 1 :peut mettre en surbrillance et exécuter une partie du code avec des tables dérivées  Figure 2 :Impossible de mettre en surbrillance et d'exécuter une partie du code avec les CTE
Figure 2 :Impossible de mettre en surbrillance et d'exécuter une partie du code avec les CTE  Figure 3 :Injecter SELECT * sous le CTE pertinent
Figure 3 :Injecter SELECT * sous le CTE pertinent , cte_name AS (
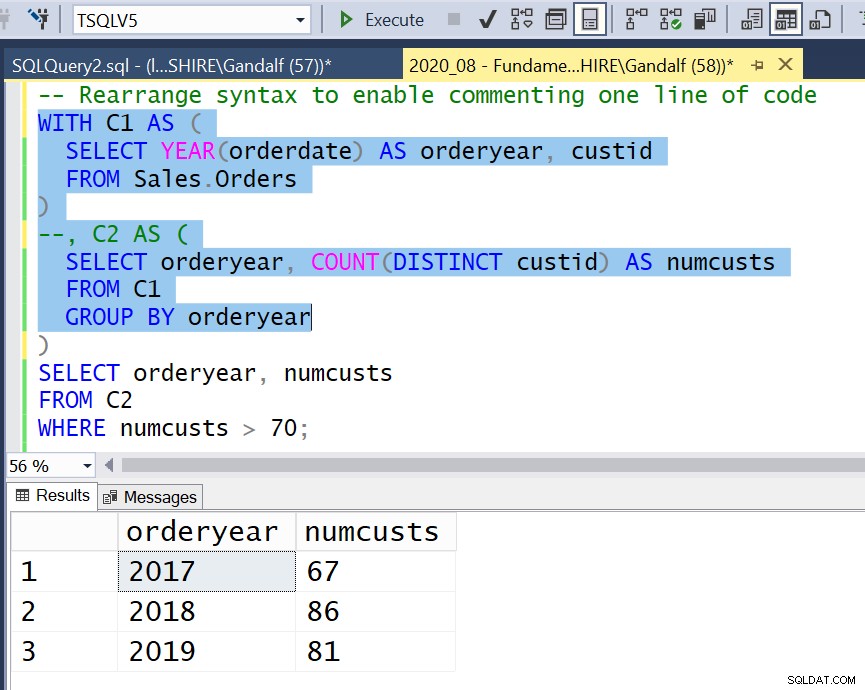 Figure 4 :réorganiser la syntaxe pour permettre de commenter une ligne de code
Figure 4 :réorganiser la syntaxe pour permettre de commenter une ligne de code  Figure 5 :Utiliser le commentaire de bloc
Figure 5 :Utiliser le commentaire de bloc Constructeur de valeur de table
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Syntaxe incorrecte près du mot-clé 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Produire une suite de nombres
@low et @high ). Vous souhaitez que votre solution prenne en charge des plages potentiellement étendues. Voici ma solution à cet effet, en utilisant des CTE, avec une demande pour la plage 1001 à 1010 dans cet exemple spécifique :DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Cardinalité L0 2 L1 4 L2 16 L3 256 L4 65 536 L5 4 294 967 296  Figure 6 :Plan de requête générant une séquence de nombres
Figure 6 :Plan de requête générant une séquence de nombres DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Résumé
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes