Cet article est la quatrième partie d'une série sur les expressions de table. Dans les parties 1 et 2, j'ai couvert le traitement conceptuel des tables dérivées. Dans la partie 3, j'ai commencé à couvrir les considérations d'optimisation des tables dérivées. Ce mois-ci, je couvre d'autres aspects de l'optimisation des tables dérivées ; plus précisément, je me concentre sur la substitution/désimbrication des tables dérivées.
Dans mes exemples, j'utiliserai des exemples de bases de données appelées TSQLV5 et PerformanceV5. Vous pouvez trouver le script qui crée et remplit TSQLV5 ici, et son diagramme ER ici. Vous pouvez trouver le script qui crée et remplit PerformanceV5 ici.
Désimbrication/substitution
La désimbrication/substitution d'expressions de table est un processus consistant à prendre une requête qui implique l'imbrication d'expressions de table, et comme si elle la substituait par une requête où la logique imbriquée est éliminée. Je dois souligner qu'en pratique, il n'y a pas de processus réel dans lequel SQL Server convertit la chaîne de requête d'origine avec la logique imbriquée en une nouvelle chaîne de requête sans imbrication. Ce qui se passe réellement, c'est que le processus d'analyse de la requête produit une arborescence initiale d'opérateurs logiques reflétant étroitement la requête d'origine. Ensuite, SQL Server applique des transformations à cette arborescence de requêtes, en éliminant certaines des étapes inutiles, en réduisant plusieurs étapes en moins d'étapes et en déplaçant les opérateurs. Dans ses transformations, tant que certaines conditions sont remplies, SQL Server peut déplacer les éléments à travers ce qui était à l'origine des limites d'expression de table, parfois comme s'il éliminait les unités imbriquées. Tout cela dans le but de trouver un plan optimal.
Dans cet article, je couvre les deux cas où une telle désimbrication a lieu, ainsi que les inhibiteurs de désimbrication. Autrement dit, lorsque vous utilisez certains éléments de requête, cela empêche SQL Server de pouvoir déplacer des opérateurs logiques dans l'arborescence de requête, l'obligeant à traiter les opérateurs en fonction des limites des expressions de table utilisées dans la requête d'origine.
Je vais commencer par montrer un exemple simple où les tables dérivées ne sont pas imbriquées. Je vais également montrer un exemple pour un inhibiteur de désimbrication. Je parlerai ensuite de cas inhabituels où la désimbrication peut être indésirable, entraînant soit des erreurs, soit une dégradation des performances, et je montrerai comment empêcher la désimbrication dans ces cas en utilisant un inhibiteur de désimbrication.
La requête suivante (nous l'appellerons Requête 1) utilise plusieurs couches imbriquées de tables dérivées, où chacune des expressions de table applique une logique de filtrage de base basée sur des constantes :
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE date de commande>='20180401';
Comme vous pouvez le voir, chacune des expressions de table filtre une plage de dates de commande commençant par une date différente. SQL Server démêle cette logique d'interrogation multicouche, ce qui lui permet ensuite de fusionner les quatre prédicats de filtrage en un seul représentant l'intersection des quatre prédicats.
Examinez le plan de la requête 1 illustré à la figure 1.
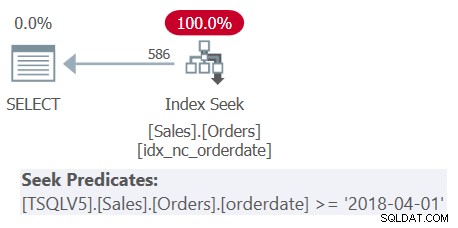 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
Observez que les quatre prédicats de filtrage ont été fusionnés en un seul prédicat représentant l'intersection des quatre. Le plan applique une recherche dans l'index idx_nc_orderdate en fonction du prédicat fusionné unique en tant que prédicat de recherche. Cet index est défini sur orderdate (explicitement), orderid (implicitement en raison de la présence d'un index clusterisé sur orderid) comme clés d'index.
Notez également que même si toutes les expressions de table utilisent SELECT * et que seule la requête la plus externe projette les deux colonnes d'intérêt :date de commande et ID de commande, l'index susmentionné est considéré comme couvrant. Comme je l'ai expliqué dans la partie 3, à des fins d'optimisation telles que la sélection d'index, SQL Server ignore les colonnes des expressions de table qui ne sont finalement pas pertinentes. N'oubliez pas cependant que vous devez disposer des autorisations pour interroger ces colonnes.
Comme mentionné, SQL Server tentera de désimbriquer les expressions de table, mais évitera la désimbrication s'il tombe sur un inhibiteur de désimbrication. Avec une certaine exception que je décrirai plus tard, l'utilisation de TOP ou OFFSET FETCH empêchera la désimbrication. La raison en est que tenter de désimbriquer une expression de table avec TOP ou OFFSET FETCH peut entraîner une modification de la signification de la requête d'origine.
À titre d'exemple, considérons la requête suivante (nous l'appellerons requête 2) :
SELECT orderid, orderdateFROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='202 ' ) AS D2 WHERE date_commande>='20180301' ) AS D3WHERE date_commande>='20180401';
Le nombre de lignes d'entrée dans le filtre TOP est une valeur de type BIGINT. Dans cet exemple, j'utilise la valeur BIGINT maximale (2^63 - 1, calcule en T-SQL en utilisant SELECT POWER(2., 63) - 1). Même si vous et moi savons que notre table Orders n'aura jamais autant de lignes, et donc le filtre TOP n'a vraiment aucun sens, SQL Server doit prendre en compte la possibilité théorique que le filtre soit significatif. Par conséquent, SQL Server ne désimbrique pas les expressions de table dans cette requête. Le plan pour la requête 2 est illustré à la figure 2.
 Figure 2 :Planifier la requête 2
Figure 2 :Planifier la requête 2
Les inhibiteurs de désimbrication empêchaient SQL Server de fusionner les prédicats de filtrage, ce qui rapprochait la forme du plan de la requête conceptuelle. Cependant, il est intéressant d'observer que SQL Server ignorait toujours les colonnes qui n'étaient finalement pas pertinentes pour la requête la plus externe, et pouvait donc utiliser l'index de couverture sur orderdate, orderid.
Pour illustrer pourquoi TOP et OFFSET-FETCH sont des inhibiteurs de désimbrication, prenons une simple technique d'optimisation de refoulement de prédicat. Le refoulement de prédicat signifie que l'optimiseur pousse un prédicat de filtre à un point antérieur par rapport au point d'origine qu'il apparaît dans le traitement logique de la requête. Par exemple, supposons que vous ayez une requête avec à la fois une jointure interne et un filtre WHERE basé sur une colonne de l'un des côtés de la jointure. En termes de traitement logique des requêtes, le filtre WHERE est censé être évalué après la jointure. Mais souvent, l'optimiseur pousse le prédicat de filtre à une étape avant la jointure, car cela laisse la jointure avec moins de lignes à utiliser, ce qui se traduit généralement par un plan plus optimal. Rappelez-vous cependant que de telles transformations ne sont autorisées que dans les cas où la signification de la requête d'origine est préservée, dans le sens où vous êtes assuré d'obtenir le bon ensemble de résultats.
Considérez le code suivant, qui a une requête externe avec un filtre WHERE sur une table dérivée, qui à son tour est basée sur une expression de table avec un filtre TOP :
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ) AS DWHERE orderdate>='20180101';
Cette requête est bien sûr non déterministe en raison de l'absence de clause ORDER BY dans l'expression de la table. Lorsque je l'ai exécuté, SQL Server a accédé aux trois premières lignes avec des dates de commande antérieures à 2018, j'ai donc obtenu un ensemble vide en sortie :
orderid orderdate----------- ----------(0 lignes concernées)
Comme mentionné, l'utilisation de TOP dans l'expression de table a empêché la désimbrication/substitution de l'expression de table ici. Si SQL Server avait désimbriqué l'expression de table, le processus de substitution aurait abouti à l'équivalent de la requête suivante :
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101';
Cette requête est également non déterministe en raison de l'absence de clause ORDER BY, mais il est clair qu'elle a une signification différente de la requête d'origine. Si la table Sales.Orders contient au moins trois commandes passées en 2018 ou plus tard, et c'est le cas, cette requête renverra nécessairement trois lignes, contrairement à la requête d'origine. Voici le résultat que j'ai obtenu lorsque j'ai exécuté cette requête :
orderid orderdate----------- ----------10400 2018-01-0110401 2018-01-0110402 2018-01-02(3 lignes concernées)
Au cas où la nature non déterministe des deux requêtes ci-dessus vous confondrait, voici un exemple avec une requête déterministe :
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderid ) AS DWHERE orderdate>='20170708'ORDER BY orderid;
L'expression de table filtre les trois commandes avec les ID de commande les plus bas. La requête externe filtre ensuite à partir de ces trois commandes uniquement celles qui ont été passées le 8 juillet 2017 ou après. Il s'avère qu'il n'y a qu'une seule commande éligible. Cette requête génère la sortie suivante :
orderid orderdate----------- ----------10250 2017-07-08(1 ligne affectée)
Supposons que SQL Server désimbrique l'expression de table dans la requête d'origine, le processus de substitution aboutissant à l'équivalent de requête suivant :
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20170708'ORDER BY orderid;
La signification de cette requête est différente de la requête d'origine. Cette requête filtre d'abord les commandes passées le 8 juillet 2017 ou après cette date, puis filtre les trois premières parmi celles dont l'ID de commande est le plus bas. Cette requête génère la sortie suivante :
orderid orderdate----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09(3 lignes concernées)
Pour éviter de modifier la signification de la requête d'origine, SQL Server n'applique pas ici la désimbrication/substitution.
Les deux derniers exemples impliquaient un simple mélange de filtrage WHERE et TOP, mais il pourrait y avoir des éléments conflictuels supplémentaires résultant de la désimbrication. Par exemple, que se passe-t-il si vous avez des spécifications de tri différentes dans l'expression de table et la requête externe, comme dans l'exemple suivant :
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC ) AS DORDER BY orderid ;
Vous vous rendez compte que si SQL Server avait désimbriqué l'expression de table, en regroupant les deux spécifications de classement différentes en une seule, la requête résultante aurait eu une signification différente de la requête d'origine. Il aurait soit filtré les mauvaises lignes, soit présenté les lignes de résultats dans le mauvais ordre de présentation. En bref, vous réalisez pourquoi la chose la plus sûre à faire pour SQL Server est d'éviter la désimbrication/substitution des expressions de table basées sur les requêtes TOP et OFFSET-FETCH.
J'ai mentionné plus tôt qu'il existe une exception à la règle selon laquelle l'utilisation de TOP et OFFSET-FETCH empêche la désimbrication. C'est lorsque vous utilisez TOP (100) PERCENT dans une expression de table imbriquée, avec ou sans clause ORDER BY. SQL Server se rend compte qu'il n'y a pas de véritable filtrage en cours et optimise l'option. Voici un exemple démontrant ceci :
SELECT orderid, orderdateFROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate> ='20180201' ) AS D2 WHERE date de commande>='20180301' ) AS D3WHERE date de commande>='20180401';
Le filtre TOP est ignoré, la désimbrication a lieu et vous obtenez le même plan que celui présenté précédemment pour la requête 1 dans la figure 1.
Lorsque vous utilisez OFFSET 0 ROWS sans clause FETCH dans une expression de table imbriquée, il n'y a pas non plus de véritable filtrage en cours. Donc, théoriquement, SQL Server aurait également pu optimiser cette option et activer la désimbrication, mais à la date de rédaction de cet article, ce n'est pas le cas. Voici un exemple démontrant ceci :
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1 WHERE orderdate>='20180201' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2 WHERE orderdate>='20180301' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3WHERE orderdate>='20180401';
Vous obtenez le même plan que celui présenté précédemment pour la requête 2 dans la figure 2, montrant qu'aucune désimbrication n'a eu lieu.
Plus tôt, j'ai expliqué que le processus de désimbrication/substitution ne génère pas vraiment une nouvelle chaîne de requête qui est ensuite optimisée, mais a plutôt à voir avec les transformations que SQL Server applique à l'arborescence des opérateurs logiques. Il existe une différence entre la façon dont SQL Server optimise une requête avec des expressions de table imbriquées par rapport à une requête logiquement équivalente réelle sans l'imbrication. L'utilisation d'expressions de table telles que des tables dérivées, ainsi que des sous-requêtes empêche un paramétrage simple. Rappel de la requête 1 présentée plus haut dans l'article :
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE date de commande>='20180401';
Étant donné que la requête utilise des tables dérivées, un paramétrage simple n'a pas lieu. Autrement dit, SQL Server ne remplace pas les constantes par des paramètres, puis optimise la requête, optimise plutôt la requête avec les constantes. Avec des prédicats basés sur des constantes, SQL Server peut fusionner les périodes qui se croisent, ce qui, dans notre cas, a abouti à un seul prédicat dans le plan, comme illustré précédemment dans la figure 1.
Considérons ensuite la requête suivante (nous l'appellerons la requête 3), qui est un équivalent logique de la requête 1, mais où vous appliquez vous-même la désimbrication :
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401';
Le plan de cette requête est illustré à la figure 3.
 Figure 3 :Plan pour la requête 3
Figure 3 :Plan pour la requête 3
Ce plan est considéré comme sûr pour un paramétrage simple, de sorte que les constantes sont remplacées par des paramètres et, par conséquent, les prédicats ne sont pas fusionnés. La motivation du paramétrage est bien sûr d'augmenter la probabilité de réutilisation du plan lors de l'exécution de requêtes similaires qui ne diffèrent que par les constantes qu'elles utilisent.
Comme mentionné, l'utilisation de tables dérivées dans la requête 1 a empêché un paramétrage simple. De même, l'utilisation de sous-requêtes empêcherait un paramétrage simple. Par exemple, voici notre précédente requête 3 avec un prédicat sans signification basé sur une sous-requête ajoutée à la clause WHERE :
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401' AND (SELECT 42) =42;
Cette fois, le paramétrage simple n'a pas lieu, permettant à SQL Server de fusionner les périodes d'intersection représentées par les prédicats avec les constantes, ce qui donne le même plan que celui illustré précédemment à la figure 1.
Si vous avez des requêtes avec des expressions de table qui utilisent des constantes et qu'il est important pour vous que SQL Server ait paramétré le code et que, pour une raison quelconque, vous ne pouvez pas le paramétrer vous-même, n'oubliez pas que vous avez la possibilité d'utiliser le paramétrage forcé avec un guide de plan. Par exemple, le code suivant crée un tel repère de plan pour la requête 3 :
DECLARER @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>=''20180101'' ) AS D1 WHERE orderdate>=''20180201'' ) AS D2 WHERE orderdate>=''20180301'' ) AS D3WHERE orderdate>=''20180401'';', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'OPTION(PARAMETERIZATION FORCED)';Exécutez à nouveau la requête 3 après avoir créé le repère de plan :
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE date de commande>='20180401';Vous obtenez le même plan que celui présenté précédemment dans la figure 3 avec les prédicats paramétrés.
Lorsque vous avez terminé, exécutez le code suivant pour supprimer le guide du plan :
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Empêcher l'annulation de l'imbrication
N'oubliez pas que SQL Server désimbrique les expressions de table pour des raisons d'optimisation. L'objectif est d'augmenter la probabilité de trouver un plan avec un coût inférieur à celui sans désimbrication. C'est vrai pour la plupart des règles de transformation appliquées par l'optimiseur. Cependant, il pourrait y avoir des cas inhabituels où vous voudriez empêcher la désimbrication. Cela peut être soit pour éviter les erreurs (oui, dans certains cas inhabituels, la désimbrication peut entraîner des erreurs) ou pour des raisons de performances pour forcer une certaine forme de plan, similaire à l'utilisation d'autres conseils de performances. N'oubliez pas que vous disposez d'un moyen simple d'empêcher la désimbrication en utilisant TOP avec un très grand nombre.
Exemple pour éviter les erreurs
Je vais commencer par un cas où la désimbrication des expressions de table peut entraîner des erreurs.
Considérez la requête suivante (nous l'appellerons la requête 4) :
SELECT orderid, productid, discountFROM Sales.OrderDetailsWHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount> 10.0 ;Cet exemple est un peu artificiel dans le sens où il est facile de réécrire le deuxième prédicat de filtre afin qu'il n'entraîne jamais d'erreur (remise <0,1), mais c'est un exemple pratique pour illustrer mon propos. Les remises sont non négatives. Ainsi, même s'il existe des lignes de commande avec une remise nulle, la requête est censée les filtrer (le premier prédicat de filtre indique que la remise doit être supérieure à la remise minimale dans la table). Cependant, rien ne garantit que SQL Server évaluera les prédicats dans l'ordre écrit, vous ne pouvez donc pas compter sur un court-circuit.
Examinez le plan de la requête 4 illustré à la figure 4.
Figure 4 :Plan pour la requête 4
Observez que dans le plan, le prédicat 1.0 / discount> 10.0 (deuxième dans la clause WHERE) est évalué avant le prédicat discount>
(premier dans la clause WHERE). Par conséquent, cette requête génère une erreur de division par zéro : Msg 8134, Niveau 16, État 1Diviser par zéro erreur rencontrée.Vous pensez peut-être que vous pouvez éviter l'erreur en utilisant une table dérivée, en séparant les tâches de filtrage en une interne et une externe, comme ceci :
SELECT orderid, productid, discountFROM ( SELECT * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / discount> 10.0 ;Cependant, SQL Server applique l'annulation de l'imbrication de la table dérivée, ce qui entraîne le même plan que celui illustré précédemment dans la figure 4, et par conséquent, ce code échoue également avec une erreur de division par zéro :
Msg 8134, Niveau 16, État 1Diviser par zéro erreur rencontrée.Une solution simple ici consiste à introduire un inhibiteur de désimbrication, comme ceci (nous appellerons cette solution Requête 5) :
SELECT orderid, productid, discountFROM ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE discount> (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / discount> 10.0;Le plan de la requête 5 est illustré à la figure 5.
Figure 5 :Plan pour la requête 5
Ne soyez pas confus par le fait que l'expression 1.0 / discount apparaît dans la partie interne de l'opérateur Nested Loops, comme si elle était évaluée en premier. Ceci est juste la définition du membre Expr1006. L'évaluation réelle du prédicat Expr1006> 10.0 est appliquée par l'opérateur Filtre comme dernière étape du plan après que les lignes avec la remise minimale ont été filtrées par l'opérateur Boucles imbriquées plus tôt. Cette solution s'exécute correctement sans erreur.
Exemple pour des raisons de performances
Je vais continuer avec un cas où la désimbrication des expressions de table peut nuire aux performances.
Commencez par exécuter le code suivant pour basculer le contexte vers la base de données PerformanceV5 et activer STATISTICS IO et TIME :
UTILISER PerformanceV5 ; SET STATISTICS IO, TIME ON ;Considérez la requête suivante (nous l'appellerons la requête 6) :
SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid ;L'optimiseur identifie un index de couverture de support avec shipperid et orderdate comme clés principales. Il crée donc un plan avec une analyse ordonnée de l'index suivie d'un opérateur Stream Aggregate basé sur l'ordre, comme illustré dans le plan de la requête 6 de la figure 6.
Figure 6 :Plan pour la requête 6
La table Commandes comporte 1 000 000 de lignes et la colonne de regroupement shipperid est très dense :il n'y a que 5 ID d'expéditeur distincts, ce qui donne une densité de 20 % (pourcentage moyen par valeur distincte). L'application d'une analyse complète de la feuille d'index implique la lecture de quelques milliers de pages, ce qui entraîne un temps d'exécution d'environ un tiers de seconde sur mon système. Voici les statistiques de performances que j'ai obtenues pour l'exécution de cette requête :
Temps CPU =344 ms, temps écoulé =346 ms, lectures logiques =3854L'arborescence de l'index comporte actuellement trois niveaux.
Faisons évoluer le nombre de commandes par un facteur de 1 000 à 1 000 000 000, mais toujours avec seulement 5 expéditeurs distincts. Le nombre de pages dans la feuille d'index augmenterait d'un facteur de 1 000 et l'arborescence d'index entraînerait probablement un niveau supplémentaire (quatre niveaux de profondeur). Ce plan a une échelle linéaire. Vous vous retrouveriez avec près de 4 000 000 lectures logiques et une durée d'exécution de quelques minutes.
Lorsque vous devez calculer un agrégat MIN ou MAX par rapport à une grande table, avec une densité très élevée dans la colonne de regroupement (important !), Et un index B-tree de support indexé sur la colonne de regroupement et la colonne d'agrégation, il y a beaucoup plus optimal forme de plan que celle de la figure 6. Imaginez une forme de plan qui analyse le petit ensemble d'ID d'expéditeur à partir d'un index de la table des expéditeurs et, dans une boucle, applique à chaque expéditeur une recherche par rapport à l'index de prise en charge sur les commandes pour obtenir l'agrégat. Avec 1 000 000 de lignes dans le tableau, 5 recherches impliqueraient 15 lectures. Avec 1 000 000 000 de lignes, 5 recherches impliqueraient 20 lectures. Avec un billion de lignes, 25 lectures au total. Clairement, un plan beaucoup plus optimal. Vous pouvez réellement réaliser un tel plan en interrogeant la table des expéditeurs et en obtenant l'agrégat à l'aide d'une sous-requête d'agrégat scalaire sur les commandes, comme ceci (nous appellerons cette solution Requête 7) :
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S ;Le plan de cette requête est illustré à la figure 7.
Figure 7 :Plan pour la requête 7
La forme de plan souhaitée est atteinte, et les chiffres de performance pour l'exécution de cette requête sont négligeables comme prévu :
Temps CPU =0 ms, temps écoulé =0 ms, lectures logiques =15Tant que la colonne de regroupement est très dense, la taille de la table Orders devient pratiquement insignifiante.
Mais attendez un instant avant d'aller célébrer. Il est obligatoire de ne conserver que les expéditeurs dont la date de commande maximale associée dans le tableau des commandes est en 2018 ou après. Cela ressemble à un ajout assez simple. Définissez une table dérivée basée sur la requête 7 et appliquez le filtre dans la requête externe, comme ceci (nous appellerons cette solution la requête 8) :
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Hélas, SQL Server désimbrique la requête de table dérivée, ainsi que la sous-requête, convertissant la logique d'agrégation en l'équivalent de la logique de requête groupée, avec shipperid comme colonne de regroupement. Et la façon dont SQL Server sait optimiser une requête groupée est basée sur un seul passage sur les données d'entrée, ce qui donne un plan très similaire à celui présenté précédemment dans la figure 6, uniquement avec le filtre supplémentaire. Le plan pour la requête 8 est illustré à la figure 8.
Figure 8 :Plan pour la requête 8
Par conséquent, la mise à l'échelle est linéaire et les chiffres de performance sont similaires à ceux de la requête 6 :
Temps CPU =328 ms, temps écoulé =325 ms, lectures logiques =3854La solution consiste à introduire un inhibiteur de désimbrication. Cela peut être fait en ajoutant un filtre TOP à l'expression de table sur laquelle la table dérivée est basée, comme ceci (nous appellerons cette solution Requête 9) :
SELECT shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Le plan de cette requête est illustré à la figure 9 et a la forme de plan souhaitée avec les recherches :
Figure 9 :Plan pour la requête 9
Les chiffres de performance pour cette exécution sont alors bien sûr négligeables :
Temps CPU =0 ms, temps écoulé =0 ms, lectures logiques =15Une autre option encore consiste à empêcher le désimbrication de la sous-requête, en remplaçant l'agrégat MAX par un filtre TOP (1) équivalent, comme ceci (nous appellerons cette solution Requête 10) :
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';Le plan de cette requête est illustré à la figure 10 et, encore une fois, a la forme souhaitée avec les recherches.
Figure 10 :Plan pour la requête 10
J'ai obtenu les chiffres de performance négligeables familiers pour cette exécution :
Temps CPU =0 ms, temps écoulé =0 ms, lectures logiques =15Lorsque vous avez terminé, exécutez le code suivant pour arrêter de générer des rapports sur les statistiques de performances :
SET STATISTICS IO, TIME OFF ;Résumé
Dans cet article, j'ai poursuivi la discussion que j'ai commencée le mois dernier sur l'optimisation des tables dérivées. Ce mois-ci, je me suis concentré sur la désimbrication des tables dérivées. J'ai expliqué que la désimbrication entraîne généralement un plan plus optimal que sans désimbrication, mais j'ai également couvert des exemples où cela n'est pas souhaitable. J'ai montré un exemple où la désimbrication a entraîné une erreur ainsi qu'un exemple entraînant une dégradation des performances. J'ai montré comment empêcher la désimbrication en appliquant un inhibiteur de désimbrication comme TOP.
Le mois prochain, je poursuivrai l'exploration des expressions de table nommées, en mettant l'accent sur les CTE.