Un engagement de réglage des performances peut finir par prendre plusieurs tournants au fur et à mesure que vous y travaillez - tout dépend de ce qui apparaît comme le problème et de ce que les données vous disent. Certains jours, il atterrit sur une requête spécifique, ou un ensemble de requêtes, qui peuvent être améliorées avec des index - soit de nouveaux index, soit des modifications d'index existants. L'une de mes parties préférées du réglage est de travailler avec des index et, alors que je réfléchissais à cet article, j'ai été tenté de qualifier le réglage d'index de tâche "plus facile"... mais ce n'est vraiment pas le cas.
Je considère le réglage d'index comme un art et une science. Vous devez essayer de penser comme l'optimiseur, et vous devez comprendre le schéma de table et la requête (ou les requêtes) que vous essayez de régler. Ces deux éléments sont axés sur les données et relèvent donc de la catégorie de la science. La composante artistique entre en jeu lorsque vous pensez à l'autre index sur la table, et tous l'autre les requêtes qui impliquent la table qui pourrait être affectée par les changements d'index.
Étape 1 :Identifiez la requête et examinez le plan
Lorsque j'identifie une requête qui pourrait bénéficier d'un index, j'obtiens immédiatement son plan. J'obtiens souvent le plan d'exécution à partir du cache de plan ou du magasin de requêtes, puis j'utilise SSMS pour obtenir le plan d'exécution plus les statistiques d'exécution (également appelées plan d'exécution réel). Plusieurs fois, la forme de ces deux plans est la même; mais ce n'est pas une garantie, c'est pourquoi j'aime voir les deux.
Le plan peut avoir une recommandation d'index manquante, il peut avoir une analyse d'index clusterisé (ou une analyse de tas s'il n'y a pas d'index clusterisé), il peut utiliser un index non clusterisé mais avoir ensuite une recherche pour récupérer des colonnes supplémentaires. Résoudre chacun de ces problèmes individuellement semble assez facile. Ajoutez simplement l'index manquant, n'est-ce pas ? S'il y a une analyse d'un index ou d'un tas clusterisé, créer l'index dont j'ai besoin pour la requête et c'est terminé ? Ou si un index est utilisé mais qu'il va à la table pour obtenir les colonnes supplémentaires, ajoutez simplement les colonnes à cet index ?
Ce n'est généralement pas si facile, et même quand c'est le cas, je passe toujours par le processus que je décris ici.
Étape 2 :Déterminez le(s) tableau(x) à examiner
Maintenant que j'ai ma requête, je dois déterminer quelles tables ne sont pas correctement indexées. En plus d'examiner le plan, j'active également les statistiques IO et TIME dans SSMS. C'est probablement de la vieille école de ma part, car les plans d'exécution contiennent de plus en plus d'informations - y compris la durée et les numéros d'E/S par opérateur - à chaque version, mais j'aime les statistiques d'E/S car je peux voir rapidement les lectures pour chaque table. Pour les requêtes complexes avec plusieurs jointures, ou sous-requêtes, ou CTE, ou vues imbriquées, comprendre où l'IO et/ou le temps est passé dans les lecteurs de requête où je passe mon temps. Dans la mesure du possible à partir de ce point, je prends la requête la plus grande et la plus complexe et je la réduis à la partie qui cause le plus gros problème.
Par exemple, s'il y a une requête qui se joint à 10 tables et a deux sous-requêtes, le plan (ainsi que les informations d'E/S et de durée) m'aide à identifier où le problème existe. Ensuite, je vais extraire cette partie de la requête - la table problématique et peut-être quelques autres auxquelles elle se joint - et me concentrer sur cela. Parfois, c'est juste la sous-requête, alors je commence par là.
Étape 3 :Examinez les index existants
Avec la requête (ou une partie de la requête) définie, je me concentre sur les index existants pour les tables impliquées. Pour cette étape, je m'appuie sur la version de sp_helpindex de Kimberly. Je préfère de loin sa version au sp_helpindex standard car il répertorie également les colonnes INCLUDEd et la définition du filtre (le cas échéant). En fonction du nombre d'index qui s'affichent pour une table, je vais souvent le copier et le coller dans Excel, puis commander en fonction de la clé d'index, puis des colonnes incluses. Cela me permet de trouver rapidement les redondances.
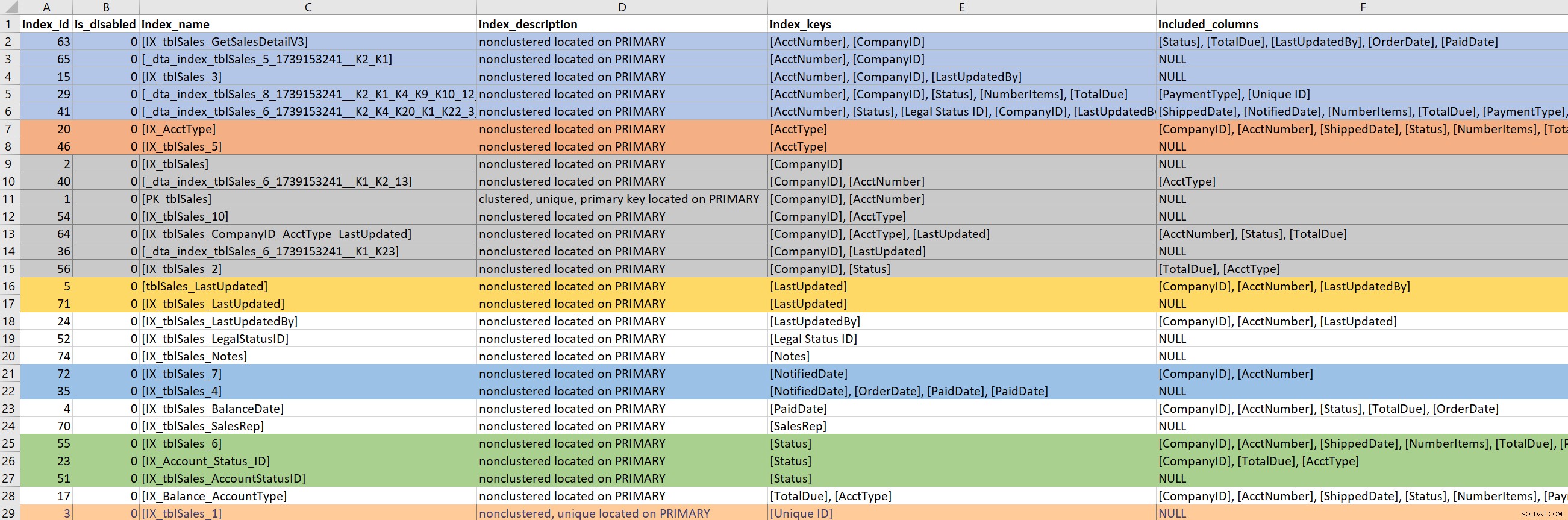
Sur la base de l'exemple de sortie ci-dessus, il existe sept index qui commencent par CompanyID, cinq qui commencent par AcctNumber et quelques autres redondances potentielles. Bien qu'il semble idéal de n'en avoir qu'un index qui mène sur une colonne particulière (par exemple CompanyID), pour certains modèles de requête, cela ne suffit pas.
Quand je regarde les index existants, il est très facile de descendre dans un terrier de lapin. Je regarde la sortie ci-dessus et commence immédiatement à demander pourquoi il y a sept index qui commencent par CompanyID, et je veux savoir qui les a créés, pourquoi et pour quelle requête. Mais… si ma requête problématique n'utilise pas CompanyID, dois-je m'en soucier ? Oui… parce qu'en général, je suis là pour améliorer les performances, et si cela signifie regarder d'autres index sur la table en cours de route, alors tant pis. Mais c'est là qu'il est facile de perdre la notion du temps (et de son véritable objectif).
Si ma requête problématique a besoin d'un index qui mène à PaidDate, je n'ai qu'à traiter avec un index existant. Si ma requête problématique a besoin d'un index qui mène à AcctNumber, cela devient délicat. Lorsque les index existants couvrent en quelque sorte une requête et que je cherche à développer un index (ajouter plus de colonnes) ou à consolider (fusionner deux ou peut-être trois index en un seul), alors je dois creuser.
Étape 4 :Statistiques d'utilisation de l'index
Je trouve que beaucoup de gens ne saisissent pas régulièrement les statistiques d'utilisation de l'index. C'est malheureux, car je trouve les données utiles pour décider quels index conserver et lesquels supprimer ou fusionner. Dans le cas où je n'ai pas de statistiques d'utilisation historiques, je vérifie au moins à quoi ressemble l'utilisation actuelle (depuis le dernier redémarrage du service) :
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
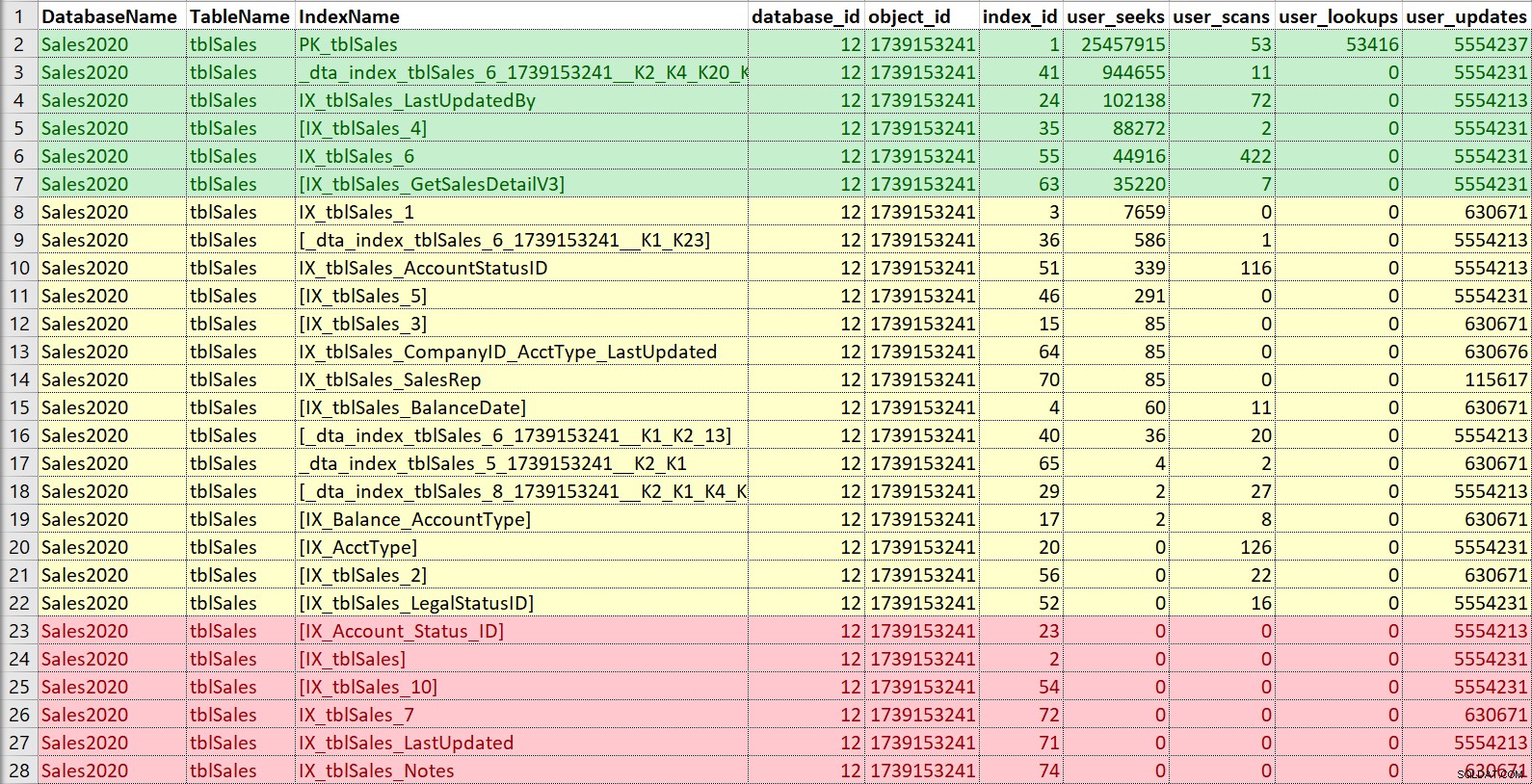
Encore une fois, j'aime mettre cela dans Excel, trier par recherches puis par analyses, et également prendre note des mises à jour. Pour cet exemple, les index en rouge sont ceux sans recherches, analyses ou recherches… uniquement des mises à jour. Ce sont des candidats pour être désactivés et potentiellement abandonnés, s'ils ne sont vraiment pas utilisés (encore une fois, avoir un historique d'utilisation aiderait ici). Les index en vert sont définitivement utilisés, je veux les conserver (bien que dans certains cas, ils pourraient peut-être être modifiés). Ceux en jaune… certains sont en quelque sorte utilisés, d'autres sont à peine utilisés. Encore une fois, l'historique serait utile ici, ou le contexte des autres - parfois, un index peut être crucial pour un rapport ou un processus qui ne s'exécute pas tout le temps.
Si je cherche simplement à modifier ou à ajouter un nouvel index, par opposition à un véritable nettoyage et à une consolidation, je suis principalement préoccupé par les index similaires à ce que je veux ajouter ou modifier. Cependant, je m'assurerai de signaler les informations d'utilisation au client et, si le temps le permet, d'aider à la stratégie d'indexation globale de la table.
Quelle est la prochaine ?
Nous n'avons pas fini ! C'est la partie 1 de mon approche du réglage de l'index, et mon prochain épisode énumérera le reste de mes étapes. En attendant, si vous ne capturez pas les statistiques d'utilisation de l'index, c'est quelque chose que vous pouvez mettre en place en utilisant la requête ci-dessus, ou une autre variante. Je recommanderais de capturer les statistiques d'utilisation pour toutes les bases de données utilisateur, pas seulement une table et une base de données spécifiques comme je l'ai fait ci-dessus, donc modifiez le prédicat si nécessaire. Et enfin, dans le cadre de cette tâche planifiée pour créer un instantané de ces informations dans une table, n'oubliez pas une autre étape pour nettoyer la table après que les données s'y trouvent depuis un certain temps (je les conserve pendant au moins six mois ; certains pourraient dire qu'un année est nécessaire).