ProxySQL est un équilibreur de charge dédié pour MySQL qui comprend une variété de fonctionnalités, y compris, mais sans s'y limiter, la redirection des requêtes, la mise en cache des requêtes ou la mise en forme du trafic. Il peut être utilisé pour configurer facilement une séparation en lecture-écriture et rediriger les requêtes vers des nœuds principaux distincts. En conséquence, il fournit de nombreuses raisons impérieuses d'utilisation. D'autre part, HAProxy est un excellent équilibreur de charge, mais il n'est pas dédié aux bases de données et bien qu'il puisse être utilisé, il ne peut pas vraiment être comparé en termes de fonctionnalités avec ProxySQL. Cela peut être la raison pour laquelle les environnements qui s'appuient toujours sur HAProxy tentent de migrer vers ProxySQL.
Dans ce court article de blog, nous partagerons quelques suggestions concernant le processus de migration.
Planification de votre mise à niveau
C'est assez évident et cela devrait aller sans aucun doute, mais nous aimerions quand même l'avoir par écrit. Planifiez votre mise à niveau. Assurez-vous que vous êtes familiarisé avec le processus, que vous avez tout testé de manière approfondie. Configurez un environnement de test dans lequel vous pouvez vérifier différentes approches de la mise à niveau et décider de celle qui vous convient le mieux.
Tester la division lecture/écriture dans ProxySQL si vous envisagez de l'utiliser
En fonction de vos besoins, vous pouvez envisager d'utiliser le fractionnement lecture/écriture dans ProxySQL. C'est probablement l'une des raisons les plus convaincantes pour la mise à niveau. Au lieu de l'implémenter du côté de l'application (ou de ne pas l'implémenter du tout si vous ne pouvez pas l'accomplir dans l'application), vous pouvez compter sur ProxySQL pour effectuer la séparation lecture/écriture pour vous. La configuration est très simple, surtout si vous déployez ProxySQL à l'aide de ClusterControl - cela se fait presque automatiquement.
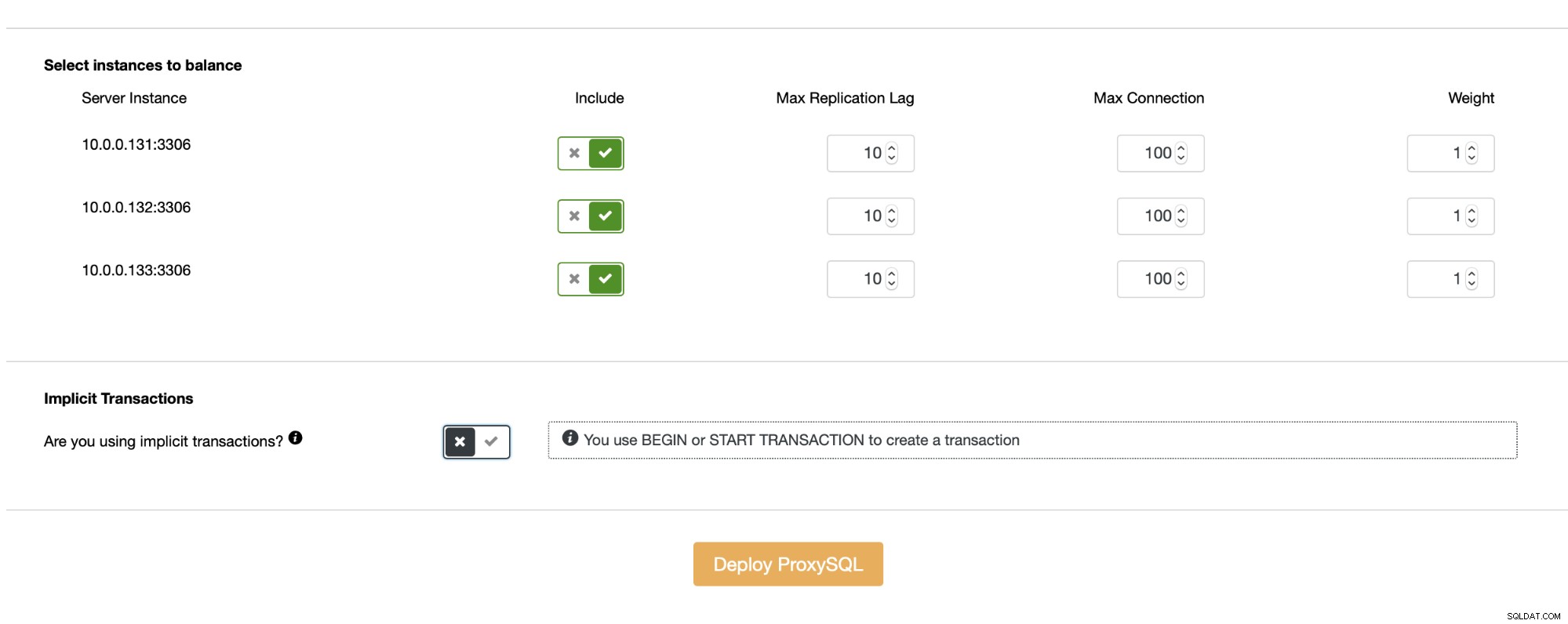
Tant que vous n'utilisez pas de transactions implicites, ClusterControl configurera le fractionnement lecture/écriture pour vous à l'aide d'un ensemble de règles de requête :
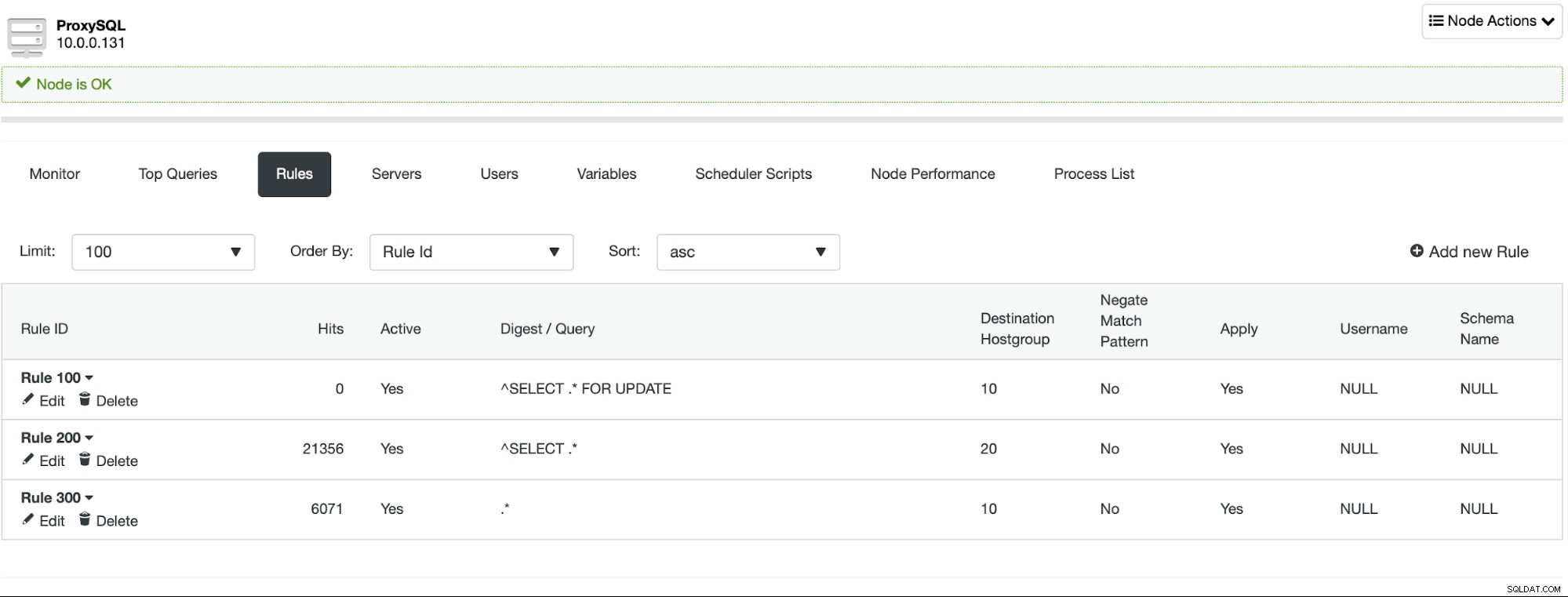
Même s'il est très simple d'implémenter le fractionnement lecture/écriture, vous devriez faites preuve de prudence lorsque vous envisagez de le faire. Les applications peuvent s'appuyer sur certaines fonctionnalités qui ne fonctionnent pas vraiment prêtes à l'emploi dans ProxySQL. Dans la plupart des cas, une configuration supplémentaire vous permettra de bénéficier de cette fonctionnalité, mais il est très important pendant la phase de test d'identifier si votre application fonctionnera ou si vous devez ajouter une configuration personnalisée. Les parties particulièrement délicates sont les problèmes de lecture après écriture - dans ce cas, vous devrez peut-être reconfigurer ProxySQL pour désactiver le multiplexage de connexion pour certaines requêtes.
Oubliez le fichier de configuration dans ProxySQL
C'est l'une des choses qui surprend les nouveaux utilisateurs de ProxySQL. Il n'utilise pas vraiment de fichiers de configuration. Il y en a un, oui, mais il agit à peu près comme un moyen de démarrer ProxySQL lors du premier démarrage. ProxySQL utilise une base de données SQLite qui contient sa configuration et la manière appropriée d'apporter des modifications à la configuration consiste à utiliser un client MySQL connecté au port administratif de ProxySQL. À partir de là, vous pouvez effectuer les modifications de configuration en cours d'exécution, pratiquement sans avoir à redémarrer ProxySQL.
Bien sûr, l'interface utilisateur de ClusterControl vous permet également de reconfigurer le ProxySQL :
Modèles de déploiement ProxySQL
Il existe deux manières principales de déployer ProxySQL. Vous pouvez soit utiliser un serveur dédié pour déployer ProxySQL sur :
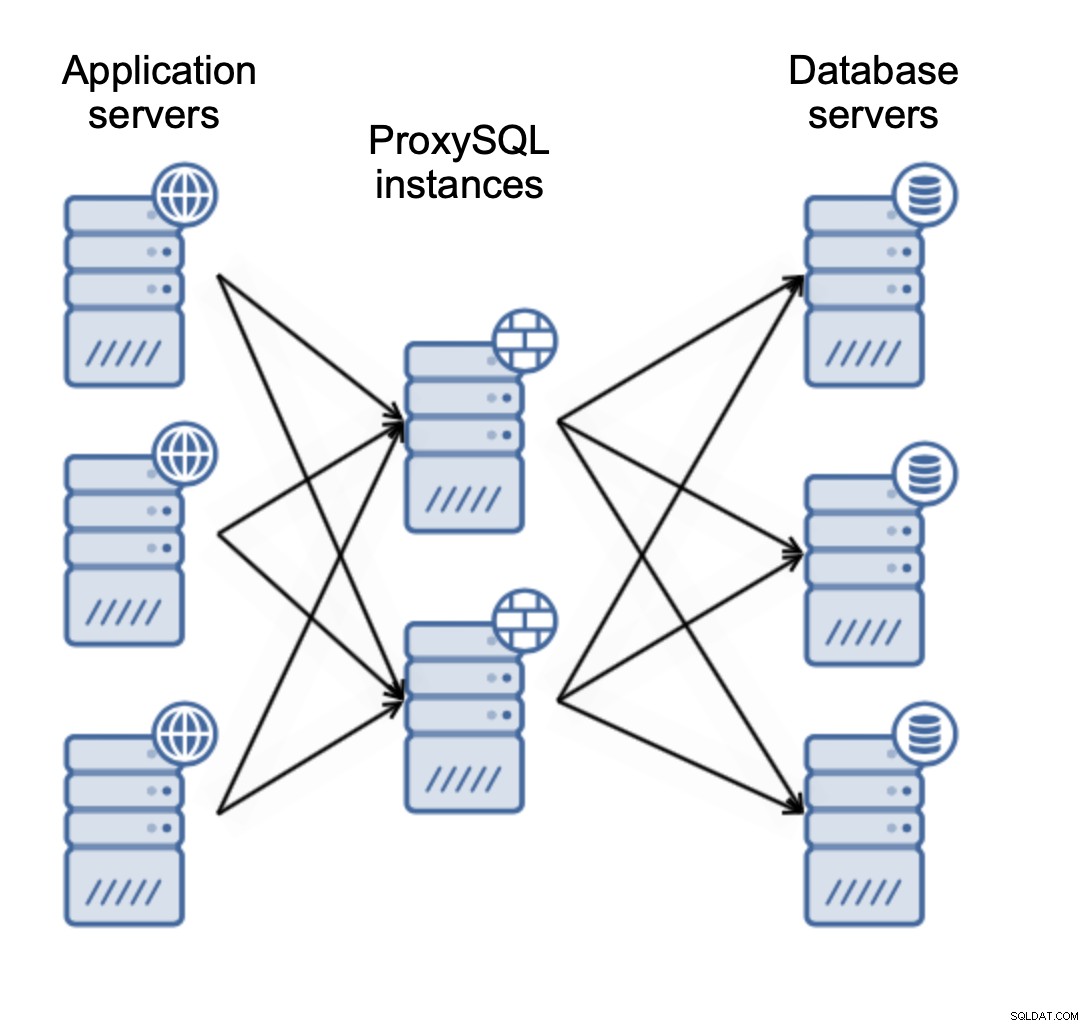
Ou vous pouvez colocaliser ProxySQL avec des serveurs d'application :
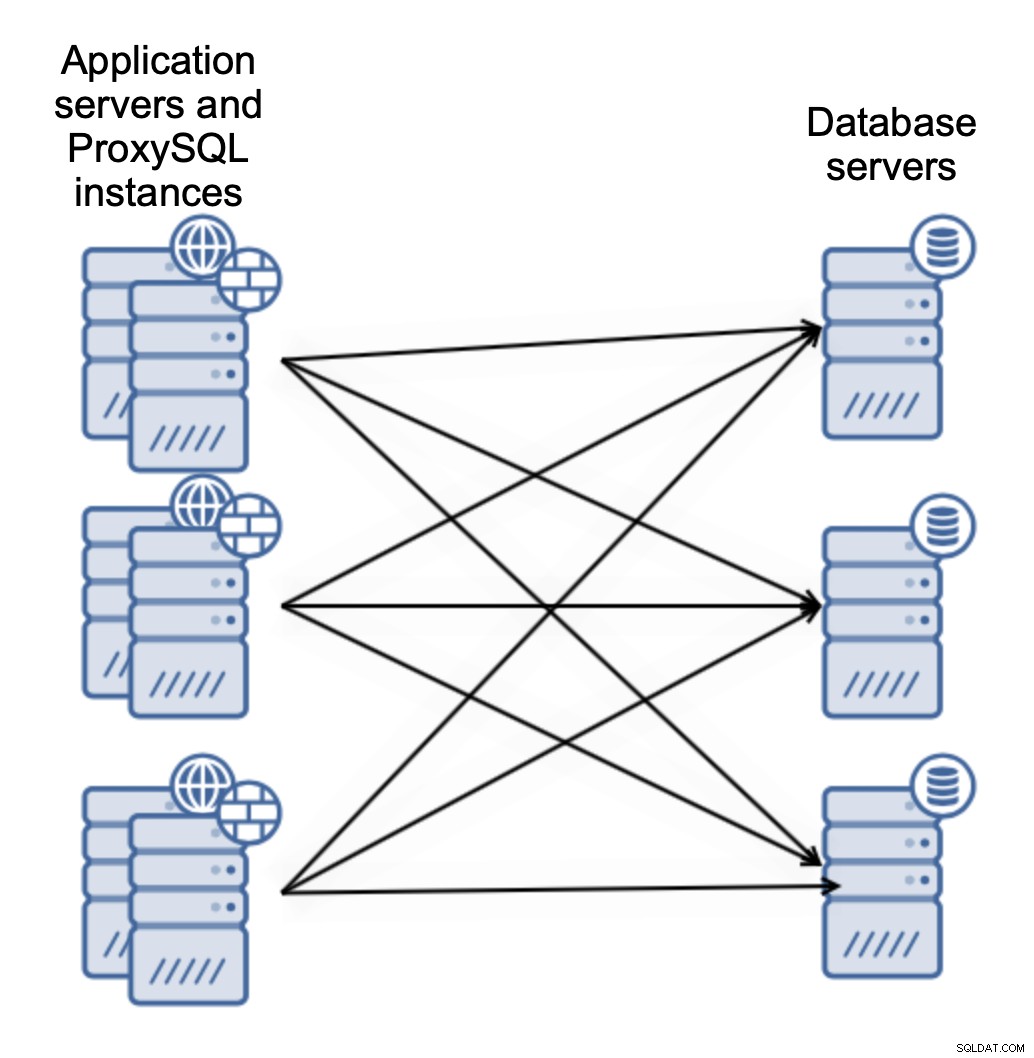
Cela permet à votre application de se connecter à l'instance ProxySQL locale à l'aide du socket Unix, qui est plus performant que d'utiliser une connexion TCP distante. Cela simplifie également la configuration - il n'est pas nécessaire d'implémenter Keepalived ou un autre fournisseur d'adresse IP virtuelle pour équilibrer la charge sur les instances ProxySQL. L'application se connecte uniquement au ProxySQL local et c'est à peu près tout.
Utiliser des clusters ProxySQL pour des déploiements plus importants
S'assurer que vos instances ProxySQL contiennent tout le temps la même configuration peut être difficile, surtout si leur nombre est important. Il existe de nombreuses façons de relever de tels défis - Ansible/Chef/Puppet, scripts shell, etc. Nous vous suggérons de vous fier à la solution intégrée - ProxySQL Cluster. Avec seulement quelques changements de configuration, vous pouvez configurer les nœuds ProxySQL pour former un cluster où un changement de configuration sur l'un des nœuds sera propagé à tous les membres du cluster.
Tinker avec SO_REUSEPORT pour un changement d'équilibreur de charge gracieux
L'une des parties les plus difficiles peut être de vous assurer que vous basculerez le trafic de HAProxy vers ProxySQL de manière à minimiser l'impact sur l'application. En règle générale, vous devrez modifier au moins un paramètre - le nom d'hôte ou le port auquel l'application doit se connecter. Selon votre environnement, cela peut ne pas être idéal, en particulier si la configuration de la connectivité de la base de données est intégrée à l'application. Cela nécessiterait à peu près de modifier la base de code et de pousser un nouveau code en production. Ce n'est pas la plus grosse affaire, mais vous pouvez faire mieux que ça.
La partie intéressante est que ProxySQL et les versions récentes de HAProxy (à partir de 1.8) sont capables d'utiliser SO_REUSEPORT. Cette option de socket est disponible sous Linux à partir du noyau 3.9 et permet à plusieurs processus de partager le même port. ProxySQL peut l'utiliser pour des mises à niveau gracieuses entre les versions de ProxySQL, HAProxy l'utilise pour recharger la configuration sans aucun impact sur l'application. Ce qui est intéressant, c'est qu'il est possible de configurer ProxySQL pour partager le port avec HAProxy pour une migration transparente entre ces deux load balancers.
Il y a quelques éléments que vous devez prendre en compte lorsque vous essayez de le faire - premièrement, ProxySQL n'utilise pas cette option par défaut, vous devez ajouter l'indicateur -r à ProxySQL au démarrage. Vous pouvez le faire en éditant le fichier d'unité systemd ProxySQL :
example@sqldat.com:~# systemctl edit proxysql --fullet en changeant la directive ExecStart en :
ExecStart=/usr/bin/proxysql -c /etc/proxysql.cnf -rUne autre limitation que vous devez connaître sous Linux est que seuls les processus démarrés par le même ID utilisateur peuvent partager le port. Cela signifie que vous devrez reconfigurer ProxySQL pour qu'il soit exécuté en tant qu'utilisateur "haproxy".
Comme d'habitude, vous souhaiterez peut-être exécuter des tests avant de tenter d'effectuer cette opération dans un environnement de production. Il est tout à fait possible d'accomplir cet exploit, mais vous devez faire preuve de prudence et vérifier que cela n'aura pas d'impact sur votre production en raison d'une sorte de configuration non standard liée à votre environnement.
Nous espérons que ce court blog vous donnera un aperçu du processus de migration de HAProxy vers ProxySQL. Pour les backends de la base de données, ce changement sera très bénéfique, même si la partie préparation peut prendre du temps. Si vous passez par des tests appropriés, la migration finale devrait être assez simple et sûre.