"Waitstats nous aide à identifier les compteurs liés aux performances. Mais les informations d'attente en elles-mêmes ne suffisent pas à diagnostiquer avec précision les problèmes de performances. Le composant de files d'attente de notre méthodologie provient des compteurs de Performance Monitor, qui fournissent une vue des performances du système du point de vue des ressources.Tom Davidson, Ouverture de Microsoft Performance-Tuning Toolbox
SQL Server Pro Magazine, décembre 2003
Les attentes et les files d'attente sont utilisées comme méthodologie d'optimisation des performances de SQL Server depuis que Tom Davidson a publié l'article ci-dessus ainsi que le livre blanc bien connu sur les attentes et les files d'attente de SQL Server 2005 en 2006. Lorsqu'elles sont appliquées en combinaison avec des métriques de ressources, les attentes peuvent être utiles pour évaluer certaines caractéristiques de performance de la charge de travail et aider à orienter les efforts de réglage. Les données d'attente sont mises en évidence par de nombreuses solutions de surveillance des performances de SQL Server, et je suis partisan du réglage à l'aide de cette méthodologie depuis le début. L'approche a eu une influence sur la conception du tableau de bord des performances de SQL Sentry, qui présente les attentes flanquées de files d'attente (indicateurs de ressources clés) pour fournir une vue complète des performances du serveur.
Cependant, certains semblent avoir manqué le point de vue de Davidson concernant l'importance des ressources et s'appuient presque entièrement sur les temps d'attente pour présenter une image des performances des requêtes et de la santé du système. Les statistiques d'attente proviennent directement du moteur SQL Server et sont faciles à utiliser et à catégoriser. Les requêtes en attente signifient des applications et des utilisateurs en attente, et personne n'aime attendre ! Il est plus facile d'évangéliser le réglage avec les attentes comme solution unique pour accélérer les requêtes et les applications que pour raconter toute l'histoire, ce qui est plus complexe.
Malheureusement, une approche axée sur l'attente à l'exclusion de l'analyse des ressources peut induire en erreur et, dans le pire des cas, vous laisser voler à l'aveuglette. Les membres de l'équipe SentryOne, Kevin Kline et Steve Wright, en ont déjà parlé ici et ici. Dans cet article, je vais approfondir certaines recherches récentes rendues possibles par Query Store qui ont jeté un nouvel éclairage sur la façon dont le réglage exclusif des attentes peut vraiment être déficient.
Les principales requêtes qui ne l'étaient pas
Récemment, un client SentryOne m'a contacté au sujet de problèmes de performances avec sa base de données SentryOne. Il existe une seule base de données SQL Server au cœur de chaque environnement de surveillance SentryOne, et ce client surveillait environ 600 serveurs avec notre logiciel. À cette échelle, il n'est pas rare de voir des problèmes de performances de requête occasionnels et d'effectuer un petit réglage, et certaines prétendues nouvelles requêtes dans la charge de travail étaient à l'origine de leurs préoccupations.
J'ai participé à une session de partage d'écran pour jeter un coup d'œil, et le client m'a d'abord présenté les données d'un système différent qui surveillait également la base de données SentryOne. Le système a utilisé une approche d'attente au niveau de la requête et a montré que deux procédures stockées étaient responsables d'environ la moitié des attentes sur le serveur de base de données SQL Sentry. C'était inhabituel car ces deux procédures s'exécutent toujours très rapidement et n'ont jamais été révélatrices d'un réel problème de performances dans notre base de données. Perplexe, je suis passé à SQL Sentry pour voir ce qu'il nous montrerait, et j'ai été surpris de voir que sur le même intervalle, la procédure n°1 dans l'autre système était n°6, n°7 et n°8 en termes de durée totale, CPU et lectures logiques respectivement :
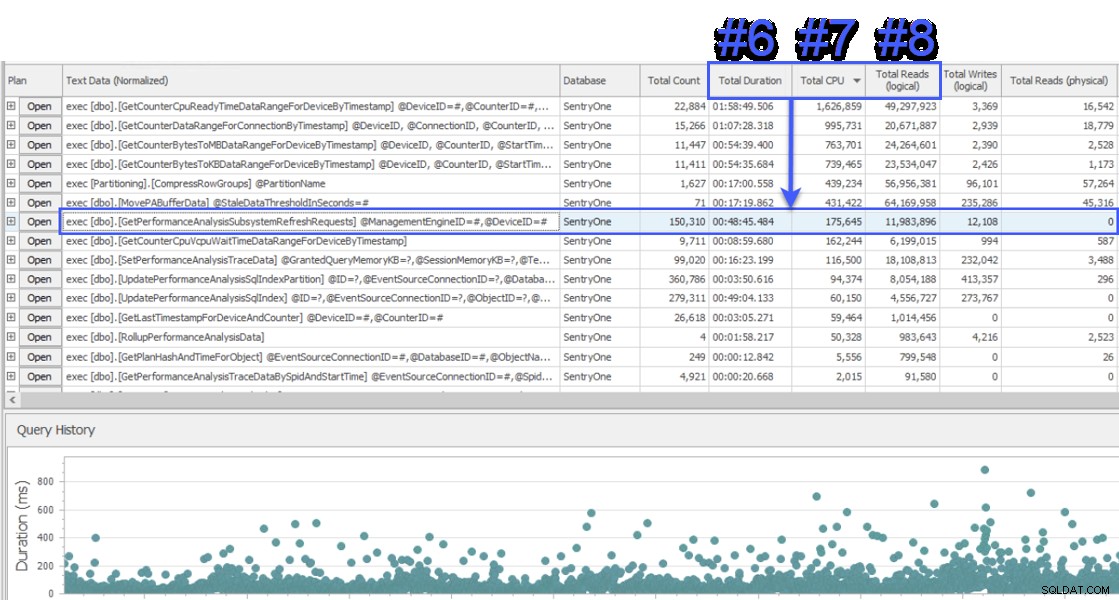 Vue "Top SQL" de SQL Sentry
Vue "Top SQL" de SQL Sentry
Du point de vue de la consommation de ressources, cela signifiait que les requêtes au-dessus représentaient 75 % de la durée totale, 87 % du CPU total et 88 % des lectures logiques. De plus, la procédure n°2 dans l'autre système n'était même pas dans le top 30 de SQL Sentry, à aucun point de vue ! Ces deux requêtes étaient loin du top 2, et les requêtes qui représentaient la plupart des réels la consommation sur le système étaient fortement sous-représentées.
J'avais toujours supposé qu'il y avait une corrélation plus forte entre les meilleurs serveurs et les principaux consommateurs de ressources, mais je n'avais jamais effectué une comparaison directe au niveau des requêtes comme celle-ci, donc ces résultats étaient pour le moins surprenants. Mon intérêt piqué, j'ai décidé d'enquêter pour déterminer si cette situation était typique ou anormale.
Query Store 2017 à la rescousse
Dans SQL Server 2017 et versions ultérieures, le magasin de requêtes capture les attentes au niveau de la requête en plus de la consommation des ressources de requête. Erin Stellato a fait un excellent post sur Query Store attend ici. Il est moins coûteux et plus précis que l'interrogation attend les DMV chaque seconde dans l'espoir d'attraper les requêtes en cours, l'approche standard utilisée par d'autres outils, y compris celui susmentionné.
SQL Sentry a toujours capturé les attentes, mais au niveau de l'instance SQL Server, en raison de ces problèmes de surcharge et de précision. Les attentes détaillées des requêtes sont disponibles sur demande via Plan Explorer intégré, et nous évaluons l'augmentation des attentes au niveau de l'instance avec les données au niveau des requêtes de Query Store, lorsqu'elles sont disponibles.
Pour cette entreprise, j'ai demandé l'aide du SentryOne Product Advisory Council, un groupe de clients SentryOne, de partenaires et d'amis de l'industrie qui participent à un canal Slack privé. J'ai partagé ce script pour vider les 8 heures de données précédentes de Query Store et j'ai reçu des résultats pour 11 serveurs de production dans plusieurs secteurs verticaux, y compris les services financiers, l'édition de jeux, le suivi de la condition physique et l'assurance.
Les catégories d'attente du magasin de requêtes sont documentées ici. Toutes les catégories ont été incluses dans l'analyse à l'exception de celles-ci, qui ont été supprimées pour les raisons citées :
- Parallélisme - Cela peut gonfler énormément le temps d'attente d'une requête bien au-delà de sa durée réelle, car plusieurs threads peuvent annuler les attentes associées, ce qui confond la corrélation avec la durée et d'autres mesures. De plus, bien que la séparation CXPACKET/CXCONSUMER soit utile, CXPACKET signifie toujours que vous avez du parallélisme et n'est pas nécessairement problématique ou exploitable.
- Processeur - Le temps d'attente du signal peut être utile pour déterminer les goulots d'étranglement du processeur via la corrélation avec les attentes de ressources, mais le magasin de requêtes n'inclut actuellement que SOS_SCHEDULER_YIELD dans cette catégorie, ce qui n'est pas une attente au sens traditionnel, comme indiqué ici. Il ne se prête pas à une comparaison ou à une corrélation facile, en particulier lorsque SQL Server se trouve sur une machine virtuelle qui réside sur un hôte sursouscrit. Par exemple, sur un serveur, les temps d'attente CPU du magasin de requêtes représentaient 227 % du temps CPU total pour toutes les requêtes sans aucun parallélisme, ce qui ne devrait pas être possible.
- Attente de l'utilisateur et inactif - Ces catégories sont composées exclusivement d'attentes de minuterie et de file d'attente et ont été exclues pour la même raison qu'il faut toujours exclure ces types - elles sont inoffensives et ne font que créer du bruit.
En passant, j'ai récemment parlé avec le père de Query Store, Conor Cunningham, de la probabilité de modifications futures des types et catégories d'attente de Query Store et il a indiqué que c'était certainement possible… nous devrons donc garder un œil sur il.
Résultats d'analyse TL;DR
Après une analyse approfondie, j'ai confirmé que les résultats observés sur le système du client ne sont pas anormaux, mais plutôt banals. Cela signifie que si vous dépendez d'un outil axé sur les attentes pour surveiller et régler vos charges de travail, il est fort probable que vous vous concentriez sur les mauvaises requêtes et que vous manquiez les responsables de la plupart de la durée de la requête et de la consommation de ressources sur un système. Étant donné que la consommation de CPU et d'E/S se traduit directement par les dépenses en matériel de serveur et en cloud, cela est important.
La plupart des requêtes n'attendent pas
Une découverte intéressante et importante que je vais couvrir en premier est que la plupart des requêtes ne génèrent aucune attente. Sur un total de 56 438 requêtes sur tous les serveurs, seules 9 781 (17 %) avaient un temps d'attente, et seulement 8 092 (14 %) avaient un temps d'attente de types significatifs. Si vous utilisez uniquement les attentes pour déterminer les requêtes à optimiser, vous manquerez la plupart des requêtes dans la charge de travail.
Corréler les temps d'attente et les ressources
J'ai analysé la relation entre les attentes et la consommation de ressources en classant toutes les requêtes sur chaque système par attentes et ressources et en utilisant les classements pour calculer une corrélation de Spearman. Ce que nous essayons en fin de compte de déterminer, c'est si les meilleurs serveurs ont tendance à être les meilleurs consommateurs. Il s'avère que ce n'est pas le cas.
Tableau 1 affiche les coefficients de corrélation à l'échelle des couleurs pour l'attente moyenne des requêtes temps à d'autres mesures - une valeur de 1,00 (bleu foncé) représente des données parfaitement corrélées. Comme vous pouvez le constater, la corrélation avec les attentes et d'autres mesures sur la plupart des serveurs n'est pas forte, et pour un serveur, il existe une corrélation négative avec la plupart des mesures.
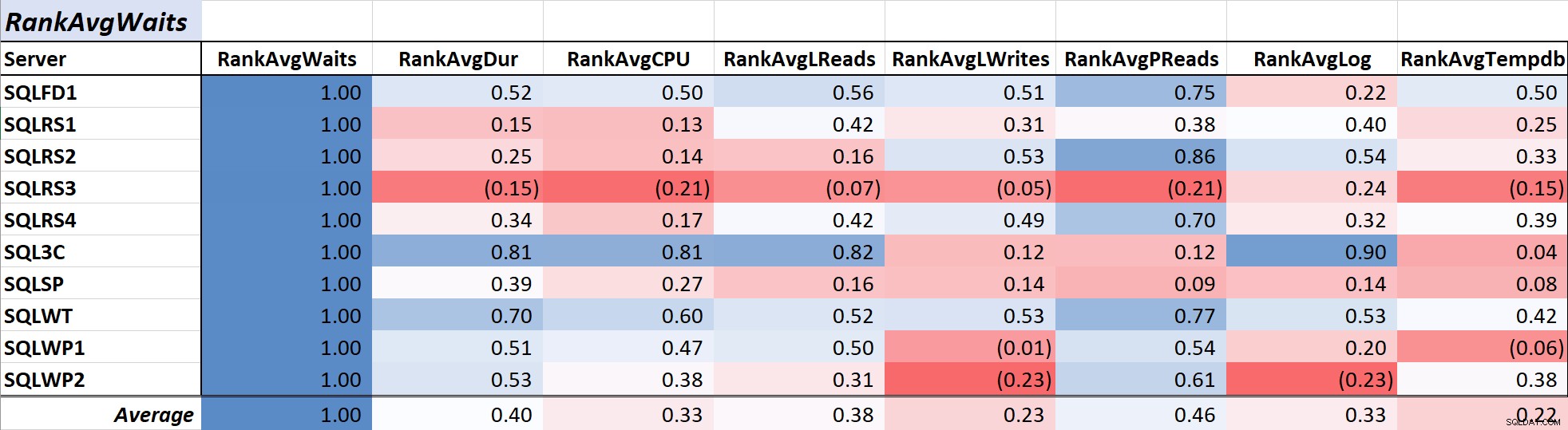 Tableau 1 :Corrélation avec le temps d'attente moyen des requêtes (ms)
Tableau 1 :Corrélation avec le temps d'attente moyen des requêtes (ms)
La durée des requêtes est souvent une préoccupation majeure pour les administrateurs de base de données et les développeurs, car elle se répercute directement sur l'expérience utilisateur. Tableau 2 montre la corrélation entre la durée moyenne des requêtes et les autres mesures. La corrélation avec la durée et les deux principales mesures de ressources, CPU et lectures logiques, est assez forte à 0,97 et 0,75 respectivement.
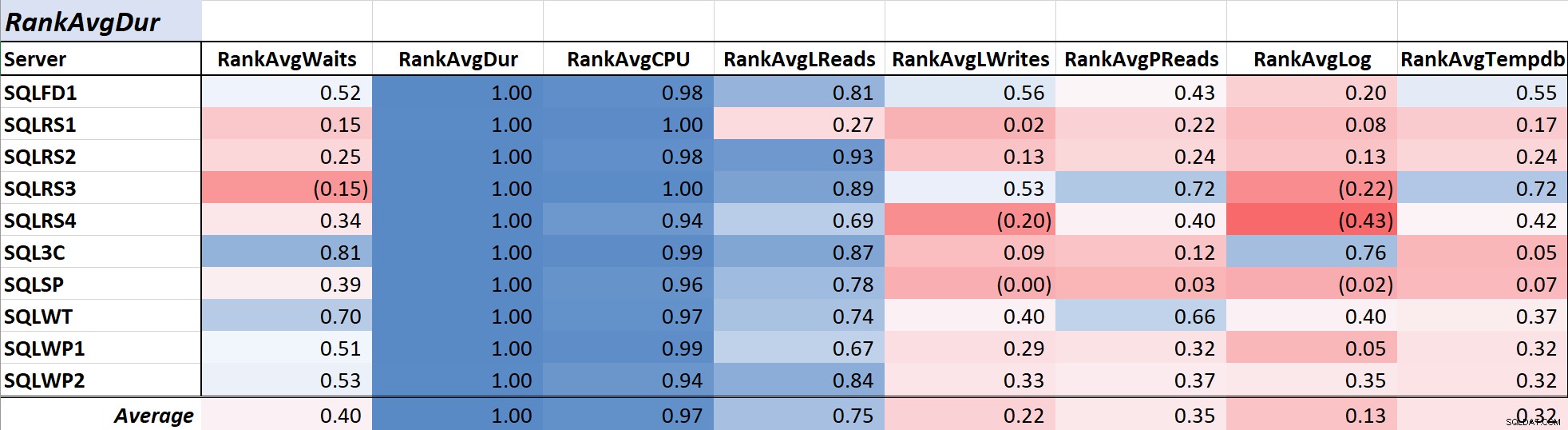 Tableau 2 :Corrélation avec la durée moyenne des requêtes (ms)
Tableau 2 :Corrélation avec la durée moyenne des requêtes (ms)
Étant donné que les lectures logiques utilisent toujours le processeur et, comme la durée, le processeur est mesuré en millisecondes, cette relation n'est pas surprenante. Les résultats sont cohérents avec l'idée que si vous voulez que vos applications de base de données s'exécutent aussi rapidement que possible, se concentrer sur la réduction du processeur de requête et des lectures logiques sera plus efficace pour réduire la durée que d'utiliser uniquement les attentes. Heureusement, le faire via une meilleure conception des requêtes, une meilleure indexation, etc. est généralement une proposition plus simple que de réduire directement le temps d'attente des requêtes. Le collègue Aaron Bertrand présente efficacement certaines des mises en garde lors du réglage avec les attentes ici.
% du temps d'attente total
Ensuite, j'ai regardé si les requêtes avec le temps d'attente le plus élevé avaient tendance à représenter la plus grande consommation de ressources. Nous voulons déterminer si ce que nous avons vu sur le système du client est atypique, où les 2 principales requêtes en attente représentaient un pourcentage relativement faible de la consommation totale des ressources.
Graphique 1 ci-dessous montre le % du CPU total et des lectures logiques pour chaque serveur pris en compte par les requêtes représentant 75 % du temps d'attente total. Un seul serveur avait une ressource dépassant 75 % - lectures sur SQLRS3. Pour le reste, les requêtes responsables de 75 % du temps d'attente consommaient moins de 75 % des ressources – souvent beaucoup moins. Cela reflète ce que nous avons vu sur le système du client et est cohérent avec l'analyse de corrélation.
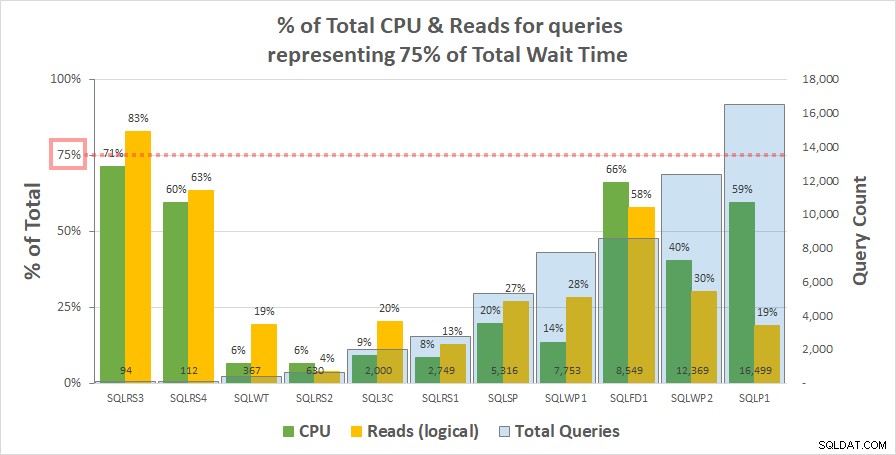 Graphique 1
Graphique 1
Notez qu'il semble y avoir une relation avec le nombre total de requêtes dans la charge de travail. Ceci est représenté par la série de colonnes bleu clair sur l'axe y secondaire et le graphique est trié par ordre croissant de cette série. Les deux serveurs avec les mesures de ressources les plus élevées à 75 % d'attentes avaient également le moins de requêtes (SQLRS3 et SQLRS4). Plus la charge de travail est petite, plus l'influence potentielle d'un petit nombre de requêtes est grande, et bien sûr, sur les deux serveurs, seules deux requêtes représentaient la plupart des attentes et des ressources. Une façon de voir cela est que les temps d'attente aident le plus à identifier vos requêtes les plus lourdes lorsque vous en avez le moins besoin.
Temps d'attente et durée de la requête
Enfin, j'ai évalué le % du temps d'attente total par rapport à la durée totale de la requête sur chaque système. Tableau 3 a des colonnes pour :
- Durée totale de la requête en ms
- Temps d'attente total ms – brut
- Temps d'attente total ms - sans parallélisme, inactivité et attentes utilisateur (Rev1)
- Temps d'attente total ms - sans parallélisme, inactivité, attentes utilisateur et CPU (Rev2)
- Le % de durée pour les 3 colonnes de temps d'attente, avec des barres de données
- Nombre total de requêtes uniques, avec barres de données
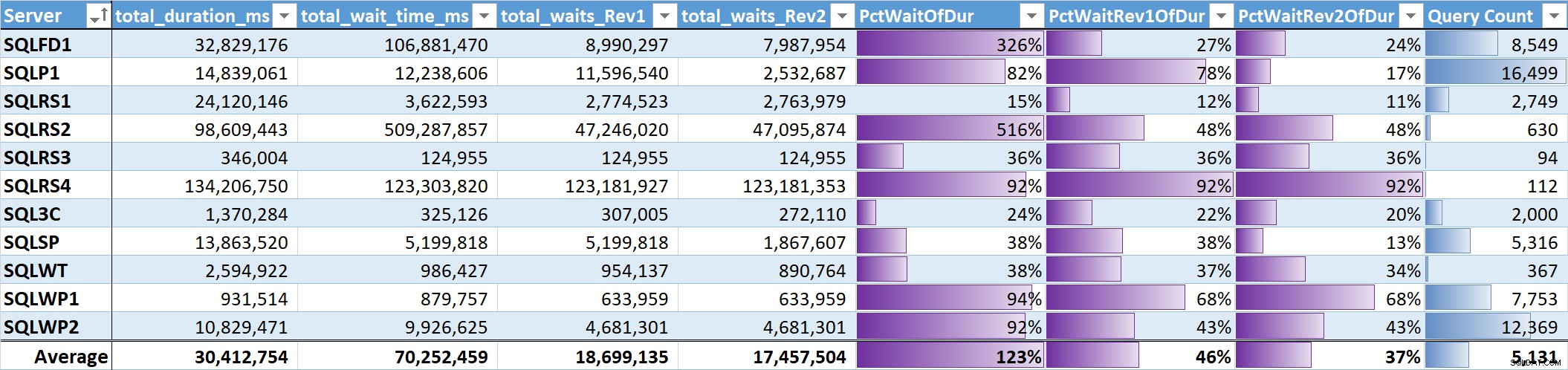 Tableau 3
Tableau 3
La moyenne non pondérée des attentes significatives (Rev2) sur tous les systèmes représente 37 % de la durée totale des requêtes. Sur cinq des systèmes, il était inférieur à 25 %, et sur seulement deux systèmes, il était supérieur à 50 %. Sur le système avec 92 % de temps d'attente (SQLRS4), celui avec le moins de requêtes, deux requêtes représentaient 99 % des attentes, 97 % de la durée, 84 % du CPU et 86 % des lectures.
Bien que le temps d'attente puisse représenter une partie importante du temps d'exécution des requêtes sur certains systèmes, et qu'il semble intuitif que si vous réduisez le temps d'attente, la durée des requêtes diminuera également, nous avons vu que le temps d'attente et la durée sont faiblement corrélés. Il est peu probable que ce soit aussi simple, et ma propre expérience le corrobore. Plus de recherche est nécessaire ici.
Optimisation complète avec Plan Explorer et SQL Sentry
Comme le suggère fréquemment cet excellent livre blanc sur les compétences SQL, les attentes élevées sont souvent dues à des requêtes et des index non optimisés. L'explorateur de plans gratuit SentryOne est spécialement conçu pour réduire la consommation de ressources grâce à un réglage efficace des requêtes à l'aide de son module d'analyse d'index et de nombreuses autres fonctionnalités innovantes. SQL Sentry intègre Plan Explorer directement dans les modules Top SQL, Blocking et Deadlocks, afin que vous puissiez capturer et régler automatiquement les requêtes problématiques en un seul endroit. Vous pouvez facilement sélectionner une plage d'intérêt sur les graphiques historiques d'attente, de CPU ou d'E/S du tableau de bord SQL Sentry et passer à la vue Top SQL pour trouver les requêtes les plus consommatrices de ressources pendant cette période. Ensuite, d'un simple clic, vous pouvez ouvrir une requête dans Plan Explorer et obtenir des attentes détaillées au niveau de la requête et ressources à la demande en cas de besoin. Je ne pense pas qu'il existe une meilleure incarnation de la méthodologie complète de réglage des attentes et des files d'attente que celle-ci.
 Tableau "Attentes" du tableau de bord SQL Sentry
Tableau "Attentes" du tableau de bord SQL Sentry
 L'explorateur de plans SentryOne gratuit montrant les attentes au fil du temps, ainsi que le niveau d'opération coûts et ressources
L'explorateur de plans SentryOne gratuit montrant les attentes au fil du temps, ainsi que le niveau d'opération coûts et ressources
Conclusion
Le réglage avec les attentes et les files d'attente est tout aussi applicable aux performances de SQL Server aujourd'hui qu'il l'était en 2006. Cependant, se concentrer sur les attentes à l'exclusion des ressources est une activité dangereuse, car il ressort clairement des données que cela conduira à des performances généralement non optimisées et des systèmes peu rentables. En ce qui concerne les ressources matérielles et les dépenses liées au cloud, vous payez en fin de compte les ressources de calcul et d'E/S, et non le temps d'attente. Il est donc opportun d'optimiser directement la consommation. D'après mon expérience, à mesure que la consommation de ressources et les conflits associés diminuent, le temps d'attente diminue naturellement.
Reconnaissance
Je voulais remercier Fred Frost, Lead Data Scientist chez SentryOne, pour sa précieuse contribution et son examen critique de cette analyse.



