Le mois dernier, j'ai posté un défi pour créer un générateur de séries de nombres efficace. Les réponses ont été écrasantes. Il y avait beaucoup d'idées et de suggestions brillantes, avec de nombreuses applications bien au-delà de ce défi particulier. Cela m'a fait réaliser à quel point il est formidable de faire partie d'une communauté et que des choses incroyables peuvent être accomplies lorsqu'un groupe de personnes intelligentes unissent leurs forces. Merci Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason et John Number2 pour le partage de vos idées et commentaires.
Au départ, je pensais écrire un seul article pour résumer les idées soumises, mais il y en avait trop. Je vais donc diviser la couverture en plusieurs articles. Ce mois-ci, je me concentrerai principalement sur les améliorations suggérées par Charlie et Alan Burstein pour les deux solutions originales que j'ai publiées le mois dernier sous la forme de TVF en ligne appelées dbo.GetNumsItzikBatch et dbo.GetNumsItzik. Je nommerai les versions améliorées dbo.GetNumsAlanCharlieItzikBatch et dbo.GetNumsAlanCharlieItzik, respectivement.
C'est tellement excitant !
Les solutions originales d'Itzik
Pour rappel, les fonctions que j'ai couvertes le mois dernier utilisent un CTE de base qui définit un constructeur de valeur de table avec 16 lignes. Les fonctions utilisent une série de CTE en cascade, chacun appliquant un produit (jointure croisée) de deux instances de son CTE précédent. De cette façon, avec cinq CTE au-delà de celui de base, vous pouvez obtenir un ensemble de 4 294 967 296 lignes maximum. Un CTE appelé Nums utilise la fonction ROW_NUMBER pour produire une série de nombres commençant par 1. Enfin, la requête externe calcule les nombres dans la plage demandée entre les entrées @low et @high.
La fonction dbo.GetNumsItzikBatch utilise une jointure factice à une table avec un index columnstore pour obtenir un traitement par lots. Voici le code pour créer la table factice :
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Et voici le code définissant la fonction dbo.GetNumsItzikBatch :
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; J'ai utilisé le code suivant pour tester la fonction avec "Supprimer les résultats après exécution" activé dans SSMS :
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de performances que j'ai obtenues pour cette exécution :
CPU time = 16985 ms, elapsed time = 18348 ms.
La fonction dbo.GetNumsItzik est similaire, sauf qu'elle n'a pas de jointure fictive et obtient normalement un traitement en mode ligne tout au long du plan. Voici la définition de la fonction :
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Voici le code que j'ai utilisé pour tester la fonction :
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de performances que j'ai obtenues pour cette exécution :
CPU time = 19969 ms, elapsed time = 21229 ms.
Améliorations d'Alan Burstein et de Charlie
Alan et Charlie ont suggéré plusieurs améliorations à mes fonctions, certaines avec des implications modérées sur les performances et d'autres avec des conséquences plus dramatiques. Je vais commencer par les découvertes de Charlie concernant la surcharge de compilation et le pliage constant. Je couvrirai ensuite les suggestions d'Alan, y compris les séquences basées sur 1 par rapport aux séquences basées sur @low (également partagées par Charlie et Jeff Moden), en évitant les tris inutiles et en calculant une plage de nombres dans l'ordre opposé.
Résultats du temps de compilation
Comme Charlie l'a noté, un générateur de séries de nombres est souvent utilisé pour générer des séries avec un très petit nombre de lignes. Dans ces cas, le temps de compilation du code peut devenir une partie substantielle du temps de traitement total de la requête. C'est particulièrement important lors de l'utilisation d'iTVF, car contrairement aux procédures stockées, ce n'est pas le code de requête paramétré qui est optimisé, mais plutôt le code de requête après l'intégration des paramètres. En d'autres termes, les paramètres sont remplacés par les valeurs d'entrée avant l'optimisation, et le code avec les constantes est optimisé. Ce processus peut avoir des implications à la fois négatives et positives. L'une des implications négatives est que vous obtenez plus de compilations lorsque la fonction est appelée avec différentes valeurs d'entrée. Pour cette raison, les temps de compilation doivent absolument être pris en compte, en particulier lors de l'utilisation très fréquente de la fonction avec de petites plages.
Voici les temps de compilation trouvés par Charlie pour les différentes cardinalités CTE de base :
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Il est curieux de voir que parmi ceux-ci, 16 est l'optimum, et qu'il y a un saut très spectaculaire lorsque vous montez au niveau suivant, qui est 256. Rappelez-vous que les fonctions dbo.GetNumsItzikBacth et dbo.GetNumsItzik utilisent la cardinalité CTE de base de 16 .
Pliage constant
Le pliage constant est souvent une implication positive qui, dans les bonnes conditions, peut être activée grâce au processus d'intégration des paramètres qu'un iTVF expérimente. Par exemple, supposons que votre fonction ait une expression @x + 1, où @x est un paramètre d'entrée de la fonction. Vous appelez la fonction avec @x =5 en entrée. L'expression en ligne devient alors 5 + 1, et si elle est éligible pour un pliage constant (plus sur cela sous peu), devient alors 6. Si cette expression fait partie d'une expression plus élaborée impliquant des colonnes, et est appliquée à plusieurs millions de lignes, cela peut se traduisent par des économies non négligeables en cycles CPU.
La partie délicate est que SQL Server est très pointilleux sur ce qu'il faut plier constamment et ce qu'il ne faut pas plier constamment. Par exemple, SQL Server ne sera pas constant fold col1 + 5 + 1, ni 5 + col1 + 1. Mais il pliera 5 + 1 + col1 en 6 + col1. Je sais. Ainsi, par exemple, si votre fonction renvoie SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, vous pouvez activer le pliage constant avec la petite modification suivante :SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Vous ne me croyez pas ? Examinez les plans pour les trois requêtes suivantes dans la base de données PerformanceV5 (ou des requêtes similaires avec vos données) et voyez par vous-même :
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
J'ai obtenu les trois expressions suivantes dans les opérateurs Compute Scalar pour ces trois requêtes, respectivement :
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Vous voyez où je veux en venir ? Dans mes fonctions, j'ai utilisé l'expression suivante pour définir la colonne de résultat n :
@low + rownum - 1 AS n
Charlie s'est rendu compte qu'avec la petite modification suivante, il pouvait activer le pliage constant :
@low - 1 + rownum AS n
Par exemple, le plan de la requête précédente que j'ai fournie sur dbo.GetNumsItzik, avec @low =1, avait à l'origine l'expression suivante définie par l'opérateur Compute Scalar :
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Après avoir appliqué la modification mineure ci-dessus, l'expression dans le plan devient :
[Expr1154] = Scalar Operator((0)+[Expr1153])
C'est génial !
En ce qui concerne les implications sur les performances, rappelez-vous que les statistiques de performances que j'ai obtenues pour la requête contre dbo.GetNumsItzikBatch avant le changement étaient les suivantes :
CPU time = 16985 ms, elapsed time = 18348 ms.
Voici les chiffres que j'ai obtenus après le changement :
CPU time = 16375 ms, elapsed time = 17932 ms.
Voici les chiffres que j'ai obtenus pour la requête contre dbo.GetNumsItzik à l'origine :
CPU time = 19969 ms, elapsed time = 21229 ms.
Et voici les chiffres après le changement :
CPU time = 19266 ms, elapsed time = 20588 ms.
Les performances se sont améliorées de quelques pour cent. Mais attendez, il y a plus! Si vous avez besoin de traiter les données commandées, les implications sur les performances peuvent être beaucoup plus dramatiques, comme j'y reviendrai plus loin dans la section sur la commande.
Séquence basée sur 1 contre @low et numéros de ligne opposés
Alan, Charlie et Jeff ont noté que dans la grande majorité des cas réels où vous avez besoin d'une plage de nombres, vous en avez besoin pour commencer par 1, ou parfois 0. Il est beaucoup moins courant d'avoir besoin d'un point de départ différent. Il pourrait donc être plus logique que la fonction renvoie toujours une plage qui commence par, disons, 1, et lorsque vous avez besoin d'un point de départ différent, appliquez tous les calculs en externe dans la requête à la fonction.
Alan a en fait eu l'idée élégante de faire en sorte que le TVF en ligne renvoie à la fois une colonne commençant par 1 (simplement le résultat direct de la fonction ROW_NUMBER) aliasée rn et une colonne commençant par @low aliasée n. Étant donné que la fonction est intégrée, lorsque la requête externe n'interagit qu'avec la colonne rn, la colonne n n'est même pas évaluée et vous bénéficiez des performances. Lorsque vous avez besoin que la séquence commence par @low, vous interagissez avec la colonne n et payez le coût supplémentaire applicable, il n'est donc pas nécessaire d'ajouter des calculs externes explicites. Alan a même suggéré d'ajouter une colonne appelée op qui calcule les nombres dans l'ordre opposé et n'interagit avec elle que lorsqu'elle a besoin d'une telle séquence. La colonne op est basée sur le calcul :@high + 1 – rownum. Cette colonne a une signification lorsque vous devez traiter les lignes dans l'ordre décroissant des nombres, comme je le démontrerai plus tard dans la section de commande.
Alors, appliquons les améliorations de Charlie et Alan à mes fonctions.
Pour la version en mode batch, assurez-vous de créer d'abord la table factice avec l'index columnstore, s'il n'est pas déjà présent :
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Utilisez ensuite la définition suivante pour la fonction dbo.GetNumsAlanCharlieItzikBatch :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Voici un exemple d'utilisation de la fonction :
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Ce code génère la sortie suivante :
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Ensuite, testez les performances de la fonction avec 100 millions de lignes, en renvoyant d'abord la colonne n :
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de performances que j'ai obtenues pour cette exécution :
CPU time = 16375 ms, elapsed time = 17932 ms.
Comme vous pouvez le voir, il y a une petite amélioration par rapport à dbo.GetNumsItzikBatch à la fois en CPU et en temps écoulé grâce au pliage constant qui a eu lieu ici.
Testez la fonction, mais cette fois en renvoyant la colonne rn :
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de performances que j'ai obtenues pour cette exécution :
CPU time = 15890 ms, elapsed time = 18561 ms.
Le temps CPU a encore été réduit, bien que le temps écoulé semble avoir légèrement augmenté dans cette exécution par rapport à l'interrogation de la colonne n.
La figure 1 présente les plans pour les deux requêtes.
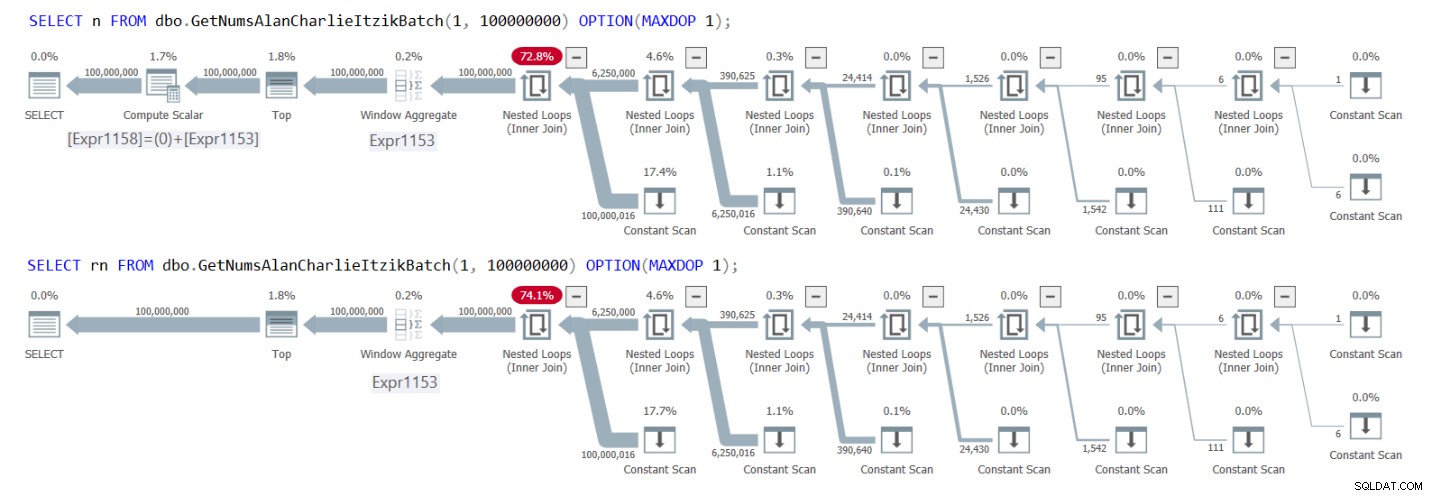 Figure 1 :Plans pour GetNumsAlanCharlieItzikBatch renvoyant n contre rn
Figure 1 :Plans pour GetNumsAlanCharlieItzikBatch renvoyant n contre rn
Vous pouvez clairement voir dans les plans que lors de l'interaction avec la colonne rn, il n'y a pas besoin de l'opérateur Compute Scalar supplémentaire. Notez également dans le premier plan le résultat de l'activité de pliage constant que j'ai décrite plus tôt, où @low - 1 + rownum était aligné sur 1 - 1 + rownum, puis plié en 0 + rownum.
Voici la définition de la version en mode ligne de la fonction appelée dbo.GetNumsAlanCharlieItzik :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Utilisez le code suivant pour tester la fonction, en interrogeant d'abord la colonne n :
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Voici les statistiques de performances que j'ai obtenues :
CPU time = 19047 ms, elapsed time = 20121 ms.
Comme vous pouvez le voir, c'est un peu plus rapide que dbo.GetNumsItzik.
Ensuite, interrogez la colonne rn :
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Les chiffres de performance s'améliorent encore à la fois sur le CPU et sur le front du temps écoulé :
CPU time = 17656 ms, elapsed time = 18990 ms.
Considérations relatives à la commande
Les améliorations susmentionnées sont certes intéressantes, et l'impact sur les performances est non négligeable, mais pas très significatif. Un impact beaucoup plus dramatique et profond sur les performances peut être observé lorsque vous devez traiter les données classées par colonne numérique. Cela peut être aussi simple que de devoir renvoyer les lignes commandées, mais est tout aussi pertinent pour tout besoin de traitement basé sur la commande, par exemple, un opérateur Stream Aggregate pour le regroupement et l'agrégation, un algorithme Merge Join pour la jointure, etc.
Lors de l'interrogation de dbo.GetNumsItzikBatch ou dbo.GetNumsItzik et de la commande par n, l'optimiseur ne se rend pas compte que l'expression de commande sous-jacente @low + rownum - 1 est préservant l'ordre par rapport à rownum. L'implication est un peu similaire à celle d'une expression de filtrage non SARGable, seulement avec une expression de tri, cela se traduit par un opérateur de tri explicite dans le plan. Le tri supplémentaire affecte le temps de réponse. Cela affecte également la mise à l'échelle, qui devient généralement n log n au lieu de n.
Pour le démontrer, interrogez dbo.GetNumsItzikBatch, en demandant la colonne n, triée par n :
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
J'ai obtenu les statistiques de performances suivantes :
CPU time = 34125 ms, elapsed time = 39656 ms.
Le temps d'exécution fait plus que doubler par rapport au test sans la clause ORDER BY.
Testez la fonction dbo.GetNumsItzik de la même manière :
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
J'ai obtenu les numéros suivants pour ce test :
CPU time = 52391 ms, elapsed time = 55175 ms.
Ici aussi, le temps d'exécution fait plus que doubler par rapport au test sans la clause ORDER BY.
La figure 2 présente les plans pour les deux requêtes.
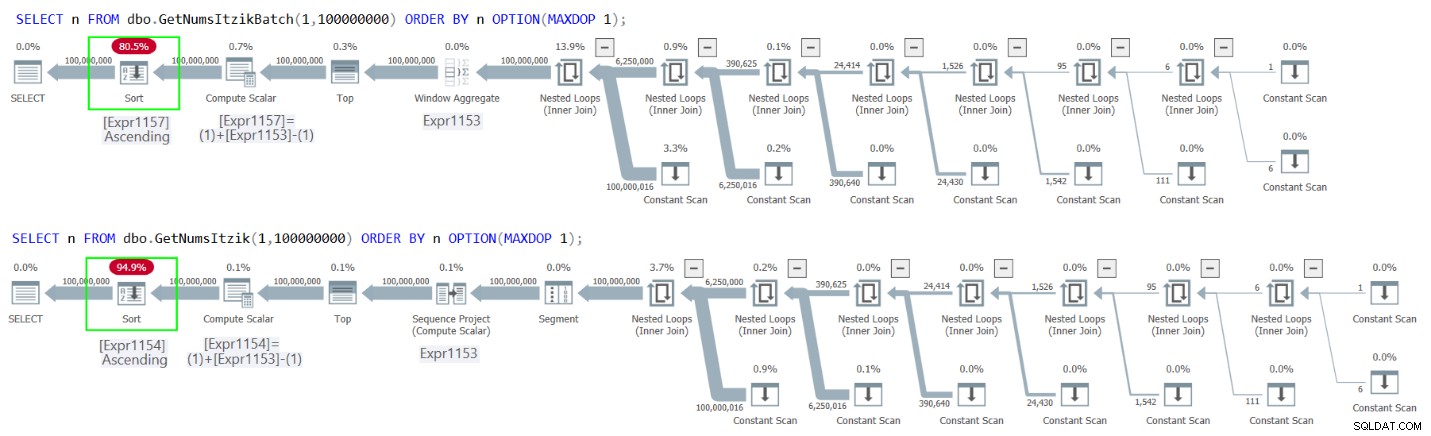 Figure 2 :Plans pour GetNumsItzikBatch et GetNumsItzik triés par n
Figure 2 :Plans pour GetNumsItzikBatch et GetNumsItzik triés par n
Dans les deux cas, vous pouvez voir l'opérateur de tri explicite dans les plans.
Lors de l'interrogation de dbo.GetNumsAlanCharlieItzikBatch ou dbo.GetNumsAlanCharlieItzik et de la commande par rn, l'optimiseur n'a pas besoin d'ajouter un opérateur de tri au plan. Vous pouvez donc retourner n, mais trier par rn, et ainsi éviter un tri. Ce qui est un peu choquant, cependant, et je le dis dans le bon sens, c'est que la version révisée de n, qui subit un pliage constant, préserve l'ordre ! Il est facile pour l'optimiseur de se rendre compte que 0 + rownum est une expression préservant l'ordre par rapport à rownum, et donc d'éviter un tri.
Essayez-le. Interrogez dbo.GetNumsAlanCharlieItzikBatch, en renvoyant n et en triant par n ou rn, comme ceci :
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
J'ai obtenu les chiffres de performance suivants :
CPU time = 16500 ms, elapsed time = 17684 ms.
C'est bien sûr grâce au fait qu'il n'y avait pas besoin d'un opérateur de tri dans le plan.
Exécutez un test similaire sur dbo.GetNumsAlanCharlieItzik :
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
J'ai obtenu les numéros suivants :
CPU time = 19546 ms, elapsed time = 20803 ms.
La figure 3 présente les plans pour les deux requêtes :
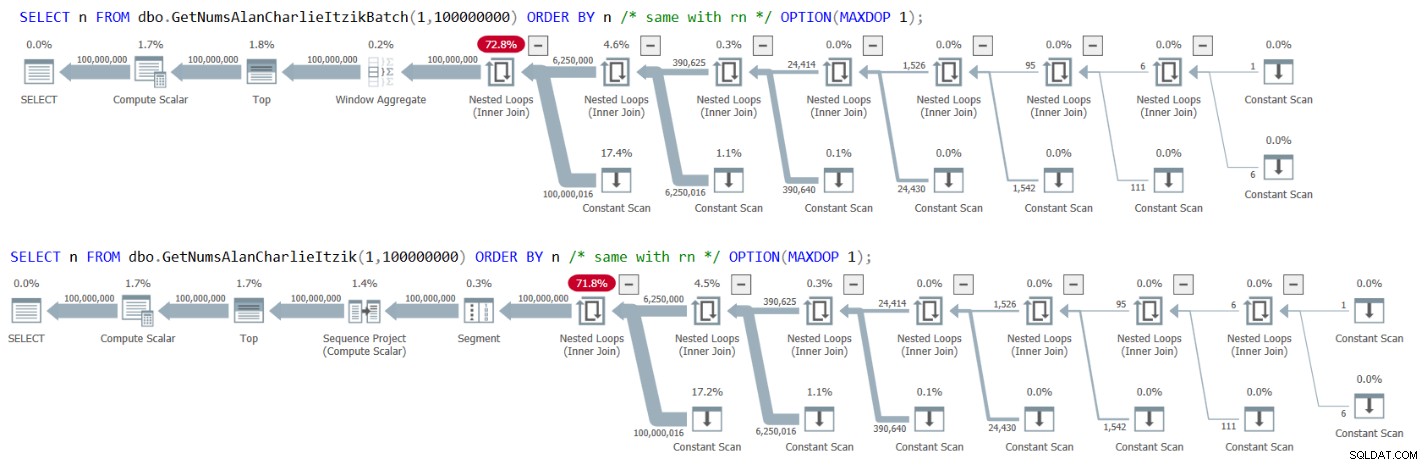
Figure 3 :Plans pour GetNumsAlanCharlieItzikBatch et GetNumsAlanCharlieItzik triés par n ou rn
Notez qu'il n'y a pas d'opérateur de tri dans les plans.
Donne envie de chanter…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Merci Charly !
Mais que se passe-t-il si vous devez renvoyer ou traiter les nombres dans l'ordre décroissant ? La tentative évidente est d'utiliser ORDER BY n DESC, ou ORDER BY rn DESC, comme ceci :
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Malheureusement, les deux cas entraînent un tri explicite dans les plans, comme le montre la figure 4.
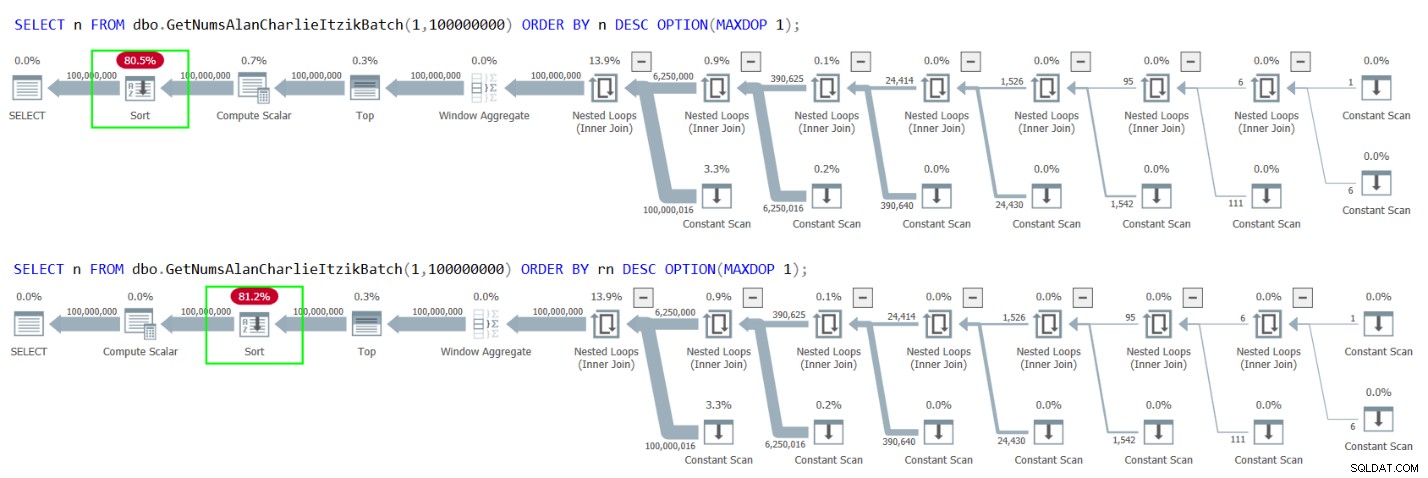 Figure 4 :Plans pour GetNumsAlanCharlieItzikBatch trié par n ou rn décroissant
Figure 4 :Plans pour GetNumsAlanCharlieItzikBatch trié par n ou rn décroissant
C'est là que l'astuce astucieuse d'Alan avec la colonne op devient une bouée de sauvetage. Renvoie la colonne op en triant par n ou rn, comme ceci :
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette requête est illustré à la figure 5.
 Figure 5 :Plan pour GetNumsAlanCharlieItzikBatch renvoyant op et triant par n ou rn croissant
Figure 5 :Plan pour GetNumsAlanCharlieItzikBatch renvoyant op et triant par n ou rn croissant
Vous récupérez les données triées par n décroissant et il n'y a pas besoin d'un tri dans le plan.
Merci Alain !
Résumé des performances
Alors qu'avons-nous appris de tout cela ?
Les temps de compilation peuvent être un facteur, en particulier lors de l'utilisation fréquente de la fonction avec de petites plages. Sur une échelle logarithmique de base 2, le doux 16 semble être un joli nombre magique.
Comprenez les particularités du pliage constant et utilisez-les à votre avantage. Lorsqu'un iTVF a des expressions qui impliquent des paramètres, des constantes et des colonnes, placez les paramètres et les constantes dans la partie principale de l'expression. Cela augmentera la probabilité de repli, réduira la surcharge du processeur et augmentera la probabilité de préservation des commandes.
Vous pouvez avoir plusieurs colonnes utilisées à des fins différentes dans un iTVF et interroger celles qui sont pertinentes dans chaque cas sans vous soucier de payer pour celles qui ne sont pas référencées.
Lorsque vous avez besoin que la séquence de nombres soit renvoyée dans l'ordre inverse, utilisez la colonne n ou rn d'origine dans la clause ORDER BY dans l'ordre croissant et renvoyez la colonne op, qui calcule les nombres dans l'ordre inverse.
La figure 6 résume les chiffres de performance que j'ai obtenus dans les différents tests.
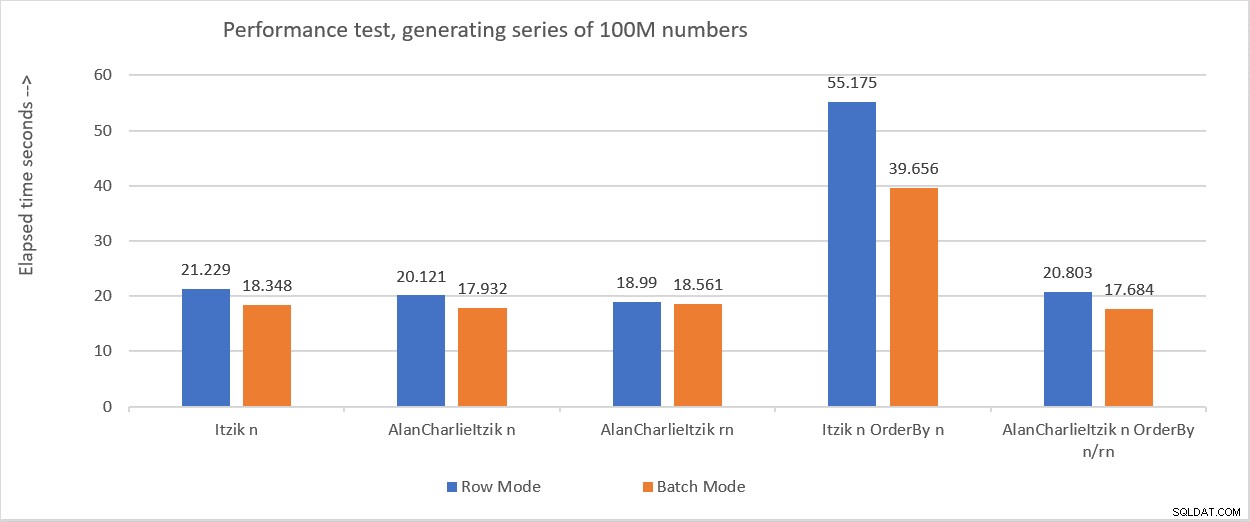 Figure 6 :Résumé des performances
Figure 6 :Résumé des performances
Le mois prochain, je continuerai à explorer d'autres idées, idées et solutions au défi du générateur de séries de nombres.