Être responsable des performances de SQL Server peut être une tâche ardue. Il y a de nombreux domaines que nous devons surveiller et comprendre. Nous devons également être en mesure de rester au top de toutes ces mesures et de savoir ce qui se passe sur nos serveurs à tout moment. J'aime demander aux administrateurs de base de données à quoi ils pensent en premier lorsqu'ils entendent l'expression « réglage de SQL Server » ; la réponse écrasante que j'obtiens est "l'ajustement des requêtes". Je reconnais que le réglage des requêtes est très important et constitue une tâche sans fin à laquelle nous sommes confrontés, car les charges de travail changent en permanence.
Cependant, il existe de nombreux autres aspects à prendre en compte lorsque l'on pense aux performances de SQL Server. De nombreux paramètres au niveau de l'instance, du système d'exploitation et de la base de données doivent être modifiés à partir des valeurs par défaut. Être consultant me permet de travailler dans de nombreux secteurs d'activité différents et d'être exposé à toutes sortes de problèmes de performance. Lorsque je travaille avec un nouveau client, j'essaie de toujours effectuer un audit de santé du serveur pour savoir à quoi j'ai affaire. Lors de ces audits, l'une des choses que j'ai constatées à plusieurs reprises a été des latences de lecture et d'écriture excessives sur les disques où résident les données et les fichiers journaux de SQL Server.
Latence de lecture/écriture
Pour afficher vos latences de disque dans SQL Server, vous pouvez interroger rapidement et facilement le DMV sys.dm_io_virtual_file_stats . Ce DMV accepte deux paramètres :database_id et file_id . Ce qui est génial, c'est que vous pouvez passer NULL comme valeurs et renvoie les latences pour tous les fichiers de toutes les bases de données. Les colonnes de sortie incluent :
- database_id
- file_id
- sample_ms
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_written
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Comme vous pouvez le voir dans la liste des colonnes, il y a des informations vraiment utiles que ce DMV récupère, mais en exécutant simplement SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); n'aide pas beaucoup à moins que vous n'ayez mémorisé vos identifiants de base de données et que vous puissiez faire quelques calculs dans votre tête.
Lorsque j'interroge les statistiques du fichier, j'utilise une requête du billet de blog de Paul Randal, "Comment examiner les latences du sous-système IO à partir de SQL Server". Ce script facilite la lecture des noms de colonne, inclut le lecteur sur lequel se trouve le fichier, le nom de la base de données et le chemin d'accès au fichier.
En interrogeant ce DMV, vous pouvez facilement savoir où se trouvent les points chauds d'E/S pour vos fichiers. Vous pouvez voir où se trouvent les latences d'écriture et de lecture les plus élevées et quelles bases de données sont les coupables. Sachant cela, vous pourrez commencer à examiner les opportunités de réglage pour ces bases de données spécifiques. Cela peut inclure le réglage de l'index, la vérification pour voir si le pool de mémoire tampon est sous pression mémoire, éventuellement le déplacement de la base de données vers une partie plus rapide du sous-système d'E/S, ou éventuellement le partitionnement de la base de données et la répartition des groupes de fichiers sur d'autres LUN.
Donc, vous exécutez la requête et elle renvoie de nombreuses valeurs en ms pour la latence - quelles valeurs sont correctes et lesquelles sont mauvaises ?
Quelles valeurs sont bonnes ou mauvaises ?
Si vous demandez SQLskills, nous vous dirons quelque chose comme :
- Excellent :<1 ms
- Très bien :< 5 ms
- Bon : 5 - 10 ms
- Médiocre :10 - 20 ms
- Mauvais :20 - 100 ms
- Vraiment mauvais :100 - 500 ms
- OMG ! > 500 ms
Si vous effectuez une recherche sur Bing, vous trouverez des articles de Microsoft proposant des recommandations similaires à :
- Bon :< 10 ms
- D'accord :10 - 20 ms
- Mauvais :20 - 50 ms
- Très mauvais :> 50 ms
Comme vous pouvez le constater, il existe de légères variations dans les chiffres, mais le consensus est que tout ce qui dépasse 20 ms peut être considéré comme gênant. Cela étant dit, votre latence d'écriture moyenne peut être de 20 ms et c'est 100 % acceptable pour votre organisation et c'est correct. Vous devez connaître les latences d'E/S générales de votre système afin que, lorsque les choses tournent mal, vous sachiez ce qui est normal.
Mes latences de lecture/écriture sont mauvaises, que dois-je faire ?
Si vous constatez que les latences de lecture et d'écriture sont mauvaises sur votre serveur, vous pouvez commencer à rechercher des problèmes à plusieurs endroits. Il ne s'agit pas d'une liste exhaustive, mais de conseils pour savoir par où commencer.
- Analysez votre charge de travail. Votre stratégie d'indexation est-elle correcte ? Ne pas avoir les index appropriés entraînera la lecture de beaucoup plus de données à partir du disque. Analyse au lieu de rechercher.
- Vos statistiques sont-elles à jour ? De mauvaises statistiques peuvent entraîner de mauvais choix pour les plans d'exécution.
- Avez-vous des problèmes de détection de paramètres qui entraînent des plans d'exécution médiocres ?
- Le pool de mémoire tampon subit-il une pression de mémoire, par exemple à cause d'un cache de plan gonflé ?
- Des problèmes de réseau ? Votre structure SAN fonctionne-t-elle correctement ? Demandez à votre ingénieur de stockage de valider le chemin d'accès et le réseau.
- Déplacez les points chauds vers différentes baies de stockage. Dans certains cas, il peut s'agir d'une seule base de données ou de quelques bases de données qui causent tous les problèmes. Les isoler sur un ensemble de disques différent ou sur des disques haut de gamme plus rapides tels que les SSD peut être la meilleure solution logique.
- Pouvez-vous partitionner la base de données pour déplacer les tables gênantes vers un autre disque afin de répartir la charge ?
Statistiques d'attente
Tout comme la surveillance des statistiques de vos fichiers, la surveillance de vos statistiques d'attente peut vous en dire beaucoup sur les goulots d'étranglement dans votre environnement. Nous avons la chance d'avoir un autre DMV génial (sys.dm_os_wait_stats ) que nous pouvons interroger qui extraira toutes les informations d'attente disponibles collectées depuis le dernier redémarrage ou depuis la dernière fois que les attentes ont été réinitialisées ; il y a aussi des attentes liées aux performances du disque. Ce DMV renverra des informations importantes, notamment :
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
L'interrogation de ce DMV sur ma machine SQL Server 2014 a renvoyé 771 types d'attente. SQL Server attend toujours quelque chose, mais il y a beaucoup d'attentes dont nous ne devrions pas nous inquiéter. Pour cette raison, j'utilise une autre requête de Paul Randal ; son article de blog, "Statistiques d'attente, ou s'il vous plaît dites-moi où ça fait mal", a un excellent script qui exclut un tas d'attentes dont nous ne nous soucions pas vraiment. Paul énumère également de nombreuses attentes problématiques courantes et propose des conseils pour les attentes courantes.
Pourquoi les statistiques d'attente sont-elles importantes ?
La surveillance des temps d'attente élevés pour certains événements vous indiquera quand il y a des problèmes. Vous avez besoin d'une base de référence pour savoir ce qui est normal et quand les choses dépassent un seuil ou un niveau de douleur. Si vous avez un niveau PAGEIOLATCH_XX vraiment élevé alors vous savez que SQL Server doit attendre qu'une page de données soit lue à partir du disque. Il peut s'agir d'un disque, d'une mémoire, d'un changement de charge de travail ou d'un certain nombre d'autres problèmes.
Un client récent avec qui je travaillais constatait un comportement très inhabituel. Lorsque je me suis connecté au serveur de base de données et que j'ai pu observer le serveur sous une charge de travail, j'ai immédiatement commencé à vérifier les statistiques des fichiers, les statistiques d'attente, l'utilisation de la mémoire, l'utilisation de tempdb, etc. Une chose qui s'est immédiatement démarquée était WRITELOG étant l'attente la plus fréquente. Je sais que cette attente est liée à un vidage du journal sur le disque et m'a rappelé la série de Paul sur la réduction de la graisse du journal des transactions. Haut WRITELOG les attentes peuvent généralement être identifiées par des latences d'écriture élevées pour le fichier journal des transactions. J'ai donc utilisé mon script de statistiques de fichiers pour examiner les latences de lecture et d'écriture sur le disque. J'ai alors pu voir une latence d'écriture élevée sur le fichier de données mais pas sur mon fichier journal. En regardant le WRITELOG c'était une attente élevée mais le temps d'attente en ms était extrêmement faible. Cependant, quelque chose dans le deuxième post de la série de Paul était encore dans ma tête. Je devrais regarder les paramètres de croissance automatique de la base de données juste pour exclure "Mort par mille coupes". En regardant les propriétés de la base de données de la base de données, j'ai vu que le fichier de données était configuré pour croître automatiquement de 1 Mo et que le journal des transactions était configuré pour croître automatiquement de 10%. Les deux fichiers avaient presque 0 espace inutilisé. J'ai partagé avec le client ce que j'ai trouvé et comment cela tuait leur performance. Nous avons rapidement fait le changement approprié et les tests ont avancé, bien mieux d'ailleurs. Malheureusement, ce n'est pas la seule fois que j'ai rencontré ce problème précis. Une autre fois, une base de données avait une taille de 66 Go, elle y est arrivée par augmentation de 1 Mo.
Capturer vos données
De nombreux professionnels des données ont créé des processus pour capturer régulièrement les statistiques de fichiers et d'attente à des fins d'analyse. Étant donné que les statistiques d'attente sont cumulatives, vous souhaiterez les capturer et comparer les deltas entre différentes heures de la journée ou avant et après l'exécution de certains processus. Ce n'est pas trop compliqué et il existe de nombreux articles de blog disponibles où les gens partagent comment ils ont accompli cela. L'important est de mesurer ces données afin de pouvoir les surveiller. Comment savez-vous aujourd'hui que les choses vont mieux ou moins bien sur votre serveur de base de données si vous ne connaissez pas les données d'hier ?
Comment SQL Sentry peut-il vous aider ?
Je suis content que vous ayez demandé ! SQL Sentry Performance Advisor met la latence et l'attente au centre du tableau de bord. Toute anomalie est facile à repérer ; vous pouvez passer en mode historique et voir la tendance précédente et la comparer également aux périodes précédentes. Cela peut s'avérer inestimable lors de l'analyse de ces "que s'est-il passé?" des moments. Tout le monde a reçu cet appel :"Hier vers 15h00, le système a semblé se bloquer, pouvez-vous nous dire ce qui s'est passé ?" Euh, bien sûr, laissez-moi ouvrir Profiler et remonter le temps. Si vous disposez d'un outil de surveillance tel que Performance Advisor, vous aurez ces informations historiques à portée de main.
En plus des tableaux et des graphiques sur le tableau de bord, vous avez la possibilité d'utiliser des alertes intégrées pour des conditions telles que les attentes de disque élevées, les nombres VLF élevés, le processeur élevé, la faible espérance de vie des pages, et bien d'autres. Vous avez également la possibilité de créer vos propres conditions personnalisées, et vous pouvez apprendre des exemples sur le site SQL Sentry ou via Condition Exchange (Aaron Bertrand a blogué à ce sujet). J'ai abordé le côté des alertes dans mon dernier article sur les alertes de l'agent SQL Server.
Dans l'onglet Espace disque de Performance Advisor, il est très facile de voir des éléments tels que les paramètres de croissance automatique et le nombre élevé de VLF. Vous devriez le savoir, mais au cas où vous ne le feriez pas, la croissance automatique de 1 Mo ou 10 % n'est pas le meilleur réglage. Si vous voyez ces valeurs (Performance Advisor les met en évidence pour vous), vous pouvez rapidement en prendre note et planifier le temps nécessaire pour effectuer les ajustements appropriés. J'aime aussi la façon dont il affiche les VLF totaux; trop de VLF peuvent être très problématiques. Vous devriez lire le post de Kimberly "Transaction Log VLFs - too many or too few?" si vous ne l'avez pas déjà fait.
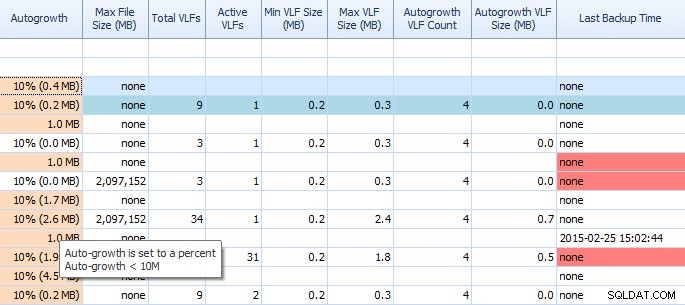 Grille partielle sur l'onglet Espace disque de Performance Advisor
Grille partielle sur l'onglet Espace disque de Performance Advisor
Performance Advisor peut également vous aider grâce à son module breveté d'activité de disque. Ici, vous pouvez voir que tempdb sur F :connaît une latence d'écriture importante ; vous pouvez le dire par les lignes rouges épaisses sous les graphiques du disque. Vous remarquerez peut-être également que F:est la seule lettre de lecteur dont le disque est représenté en rouge; il s'agit d'un indice visuel indiquant que le lecteur a une partition mal alignée, ce qui peut contribuer à des problèmes d'E/S.
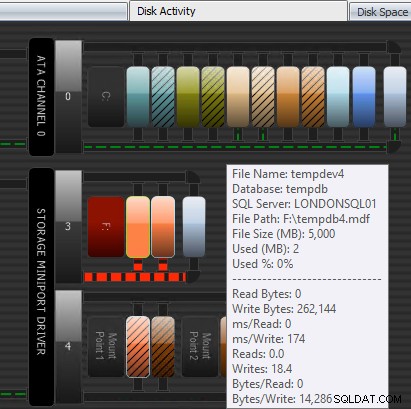 Module d'activité du disque Performance Advisor
Module d'activité du disque Performance Advisor
Et vous pouvez corréler ces informations dans les grilles ci-dessous - les problèmes sont également mis en évidence dans les grilles, et jetez un œil au ms/Write colonne :
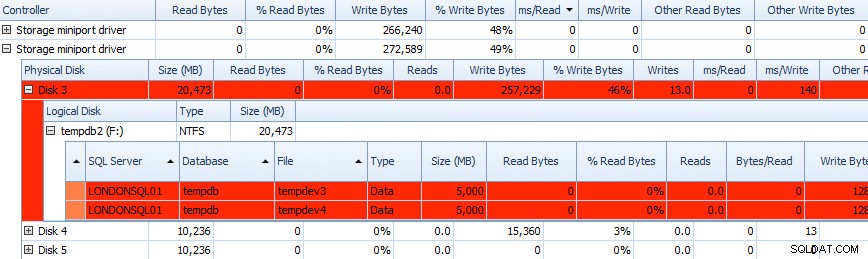 Grille partielle des données d'activité du disque Performance Advisor
Grille partielle des données d'activité du disque Performance Advisor
Vous pouvez également consulter ces informations rétroactivement; si quelqu'un se plaint d'un goulot d'étranglement de disque perçu hier après-midi ou mardi dernier, vous pouvez simplement revenir en arrière en utilisant les sélecteurs de date dans la barre d'outils et voir le débit et la latence moyens pour n'importe quelle plage. Pour plus d'informations sur le module Activité du disque, consultez le Guide de l'utilisateur.
Performance Advisor propose également de nombreux rapports intégrés dans les catégories Performance, Blocage, Top SQL, Espace disque/fichier et Interblocages. L'image ci-dessous vous montre comment accéder aux rapports sur l'espace disque/fichier. Avoir les rapports en quelques clics de souris est très utile pour pouvoir immédiatement creuser et voir ce qui se passe (ou se passait) sur votre serveur.
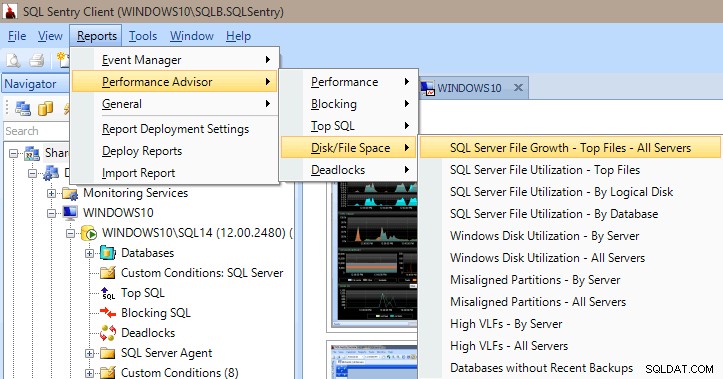 Rapports de Performance Advisor
Rapports de Performance Advisor
Résumé
L'important à retenir de cet article est de connaître vos mesures de performance. Une déclaration commune parmi les professionnels des données est que le disque est notre goulot d'étranglement n°1. Connaître les statistiques de fichiers de votre serveur contribuera grandement à comprendre les points faibles de votre serveur. En conjonction avec les statistiques de fichiers, vos statistiques d'attente sont également un excellent endroit pour regarder. Beaucoup de gens, dont moi-même, commencent par là. Avoir un outil comme SQL Sentry Performance Advisor peut vous aider considérablement à dépanner et à trouver les problèmes de performances avant qu'ils ne deviennent trop problématiques. cependant, si vous ne disposez pas d'un tel outil, familiarisez-vous avec sys.dm_os_wait_stats et sys.dm_io_virtual_file_stats vous servira bien pour commencer à régler votre serveur.