Remarque :Cet article a été initialement publié uniquement dans notre eBook, Techniques hautes performances pour SQL Server, Volume 3. Vous pouvez en savoir plus sur nos eBooks ici.
Une exigence que je vois parfois est d'avoir une requête renvoyée avec des commandes regroupées par client, montrant le total maximum dû vu pour toute commande à ce jour (un "max en cours"). Alors imaginez ces exemples de lignes :
| SalesOrderID | ID client | Date de commande | Total dû |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45.29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89.84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45.54 |
| 55 | 1 | 2014-01-07 | 99.24 |
| 62 | 2 | 2014-01-08 | 12.55 |
Quelques lignes d'exemples de données
Les résultats souhaités à partir des exigences énoncées sont les suivants :en termes clairs, triez les commandes de chaque client par date et répertoriez chaque commande. S'il s'agit de la valeur TotalDue la plus élevée pour toutes les commandes vues jusqu'à cette date, imprimez le total de cette commande, sinon imprimez la valeur TotalDue la plus élevée de toutes les commandes précédentes :
| SalesOrderID | ID client | Date de commande | Total dû | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45.29 | 45.29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45.29 |
| 31 | 1 | 2014-01-07 | 99.24 | 99.24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89.84 | 89.84 |
| 55 | 2 | 2014-01-06 | 45.54 | 89.84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89.84 |
Exemple de résultats souhaités
Beaucoup de gens voudraient instinctivement utiliser un curseur ou une boucle while pour y parvenir, mais il existe plusieurs approches qui n'impliquent pas ces constructions.
Sous-requête corrélée
Cette approche semble être l'approche la plus simple et la plus directe du problème, mais il a été prouvé à maintes reprises qu'elle ne s'adapte pas, car les lectures augmentent de façon exponentielle à mesure que la table s'agrandit :
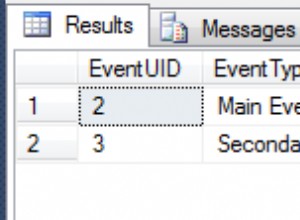
SELECT /* Sous-requête corrélée */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =(SELECT MAX(TotalDue) FROM Sales.SalesOrderHeader WHERE CustomerID =h.CustomerID AND SalesOrderID <=h.SalesOrderID) FROM Sales.SalesOrderHeader AS h COMMANDER PAR CustomerID, SalesOrderID ;
Voici le plan contre AdventureWorks2014, en utilisant SQL Sentry Plan Explorer :
 Plan d'exécution pour la sous-requête corrélée (cliquez pour agrandir)
Plan d'exécution pour la sous-requête corrélée (cliquez pour agrandir)
CROSS APPLY auto-référencé
Cette approche est presque identique à l'approche des sous-requêtes corrélées, en termes de syntaxe, de forme de plan et de performances à grande échelle.
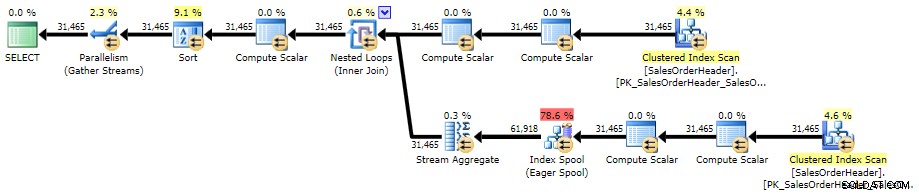
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDueFROM Sales.SalesOrderHeader AS hCROSS APPLY( SELECT MaxTotalDue =MAX(TotalDue) FROM Sales.SalesOrderHeader AS i WHERE i.CustomerID =h.CustomerID AND i.SalesOrderID <=h.SalesOrderID) AS xORDER BY h.CustomerID, h.SalesOrderID ;
Le plan est assez similaire au plan de sous-requêtes corrélées, la seule différence étant l'emplacement d'un tri :
 Plan d'exécution pour CROSS APPLY (cliquez pour agrandir)
Plan d'exécution pour CROSS APPLY (cliquez pour agrandir)
CTE récursif
Dans les coulisses, cela utilise des boucles, mais jusqu'à ce que nous l'exécutions réellement, nous pouvons prétendre que ce n'est pas le cas (bien que ce soit facilement le morceau de code le plus compliqué que je voudrais jamais écrire pour résoudre ce problème particulier):
;WITH /* CTE récursif */ cte AS ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue FROM ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader ) AS x WHERE rn =1 UNION ALL SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue, MaxTotalDue =CASE WHEN r.TotalDue> cte.MaxTotalDue THEN r.TotalDue ELSE cte .MaxTotalDue END FROM cte CROSS APPLY ( SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, rn =ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID) FROM Sales.SalesOrderHeader AS h WHERE h.CustomerID =cte.CustomerID AND h.SalesOrderID> cte.SalesOrderID ) AS r WHERE r.rn =1)SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDueFROM cteORDER BY CustomerID, SalesOrderIDOPTION (MAXRECURSION 0);
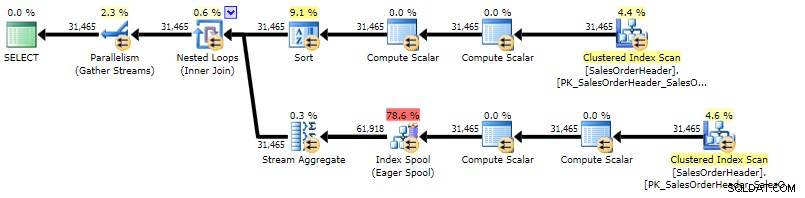
Vous pouvez immédiatement voir que le plan est plus complexe que les deux précédents, ce qui n'est pas surprenant compte tenu de la complexité de la requête :
 Plan d'exécution pour CTE récursif (cliquez pour agrandir)
Plan d'exécution pour CTE récursif (cliquez pour agrandir)
En raison de certaines mauvaises estimations, nous voyons une recherche d'index avec une recherche de clé d'accompagnement qui aurait probablement dû être remplacée par une seule analyse, et nous obtenons également une opération de tri qui doit finalement se répandre sur tempdb (vous pouvez le voir dans l'info-bulle si vous survolez l'opérateur de tri avec l'icône d'avertissement):

MAX() SUR (LIGNES NON LIMITÉES)
Il s'agit d'une solution uniquement disponible dans SQL Server 2012 et versions ultérieures, car elle utilise des extensions nouvellement introduites pour les fonctions de fenêtre.
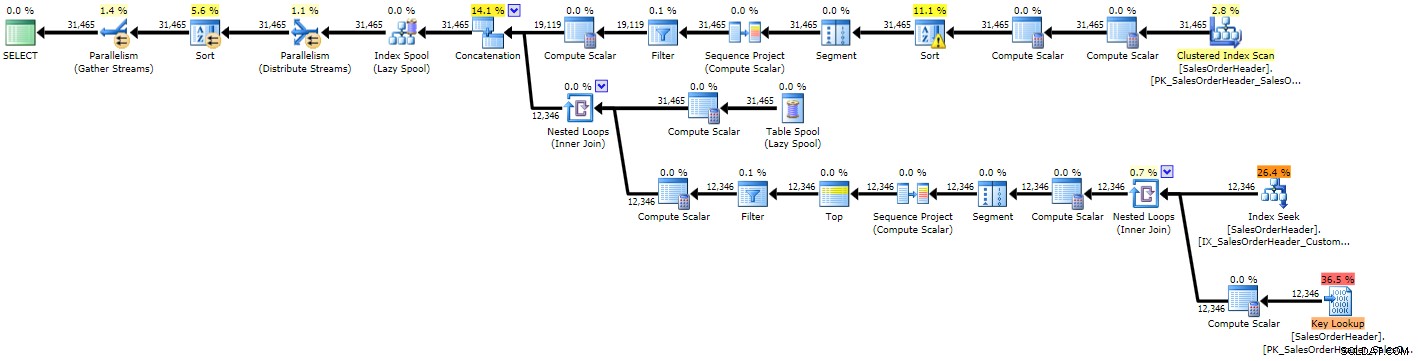
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue =MAX(TotalDue) OVER (PARTITION BY CustomerID ORDER BY SalesOrderID ROWS UNBOUNDED PRECEDING) FROM Sales.SalesOrderHeaderORDER BY CustomerID, SalesOrderID;Le plan montre exactement pourquoi il s'adapte mieux que tous les autres ; il n'a qu'une seule opération de balayage d'index clusterisé, au lieu de deux (ou le mauvais choix d'un balayage et d'une recherche + recherche dans le cas du CTE récursif) :
Plan d'exécution pour MAX() OVER() (cliquez pour agrandir)
Comparaison des performances
Les plans nous amènent certainement à croire que le nouveau
MAX() OVER()La capacité de SQL Server 2012 est un vrai gagnant, mais qu'en est-il des métriques d'exécution tangibles ? Voici comment les exécutions se comparent :
Les deux premières requêtes étaient presque identiques ; alors que dans ce cas le
CROSS APPLYétait meilleure en termes de durée globale par une petite marge, la sous-requête corrélée la dépasse parfois un peu à la place. Le CTE récursif est considérablement plus lent à chaque fois, et vous pouvez voir les facteurs qui y contribuent, à savoir les mauvaises estimations, la quantité massive de lectures, la recherche de clé et l'opération de tri supplémentaire. Et comme je l'ai déjà démontré avec des totaux cumulés, la solution SQL Server 2012 est meilleure dans presque tous les aspects.Conclusion
Si vous utilisez SQL Server 2012 ou une version supérieure, vous souhaitez absolument vous familiariser avec toutes les extensions des fonctions de fenêtrage introduites pour la première fois dans SQL Server 2005 - elles peuvent vous donner des améliorations de performances assez sérieuses lorsque vous revisitez du code qui est toujours en cours d'exécution " à l'ancienne." Si vous souhaitez en savoir plus sur certaines de ces nouvelles fonctionnalités, je vous recommande vivement le livre d'Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Si vous n'êtes pas encore sur SQL Server 2012, dans ce test au moins, vous pouvez choisir entre
CROSS APPLYet la sous-requête corrélée. Comme toujours, vous devez tester différentes méthodes par rapport à vos données sur votre matériel.