Vous pensez peut-être que la maintenance de la base de données n'est pas votre affaire. Mais si vous concevez vos modèles de manière proactive, vous obtenez des bases de données qui facilitent la vie de ceux qui doivent les maintenir.
Une bonne conception de base de données nécessite de la proactivité, une qualité appréciée dans tout environnement de travail. Au cas où vous ne seriez pas familier avec le terme, la proactivité est la capacité d'anticiper les problèmes et d'avoir des solutions prêtes quand des problèmes surviennent - ou mieux encore, de planifier et d'agir pour que les problèmes ne se produisent pas en premier lieu.
Les employeurs comprennent que la proactivité de leurs employés ou sous-traitants est synonyme d'économies de coûts. C'est pourquoi ils l'apprécient et pourquoi ils encouragent les gens à le pratiquer.
Dans votre rôle de modélisateur de données, la meilleure façon de faire preuve de proactivité est de concevoir des modèles qui anticipent et évitent les problèmes qui nuisent régulièrement à la maintenance des bases de données. Ou, du moins, cela simplifie considérablement la solution à ces problèmes.
Même si vous n'êtes pas responsable de la maintenance de la base de données, la modélisation pour une maintenance facile de la base de données présente de nombreux avantages. Par exemple, cela vous évite d'être appelé à tout moment pour résoudre des urgences de données qui vous font perdre un temps précieux que vous pourriez consacrer aux tâches de conception ou de modélisation que vous aimez tant !
Simplifier la vie des informaticiens
Lors de la conception de nos bases de données, nous devons penser au-delà de la livraison d'un DER et de la génération de scripts de mise à jour. Une fois qu'une base de données entre en production, les ingénieurs de maintenance doivent faire face à toutes sortes de problèmes potentiels, et une partie de notre tâche en tant que modélisateurs de bases de données consiste à minimiser les risques que ces problèmes se produisent.
Commençons par examiner ce que signifie créer une bonne conception de base de données et comment cette activité est liée aux tâches de maintenance régulières de la base de données.
Qu'est-ce que la modélisation des données ?
La modélisation des données consiste à créer une représentation abstraite, généralement graphique, d'un référentiel d'informations. L'objectif de la modélisation des données est d'exposer les attributs et les relations entre les entités dont les données sont stockées dans le référentiel.
Les modèles de données sont construits autour des besoins d'un problème métier. Les règles et exigences sont définies en amont grâce à l'apport d'experts métiers afin de pouvoir être intégrées dans la conception d'un nouveau référentiel de données ou adaptées dans l'itération d'un référentiel existant.
Idéalement, les modèles de données sont des documents vivants qui évoluent avec l'évolution des besoins de l'entreprise. Ils jouent un rôle important dans le soutien des décisions commerciales et dans la planification de l'architecture et de la stratégie des systèmes. Les modèles de données doivent être synchronisés avec les bases de données qu'ils représentent afin qu'ils soient utiles aux routines de maintenance de ces bases de données.
Défis courants de maintenance de la base de données
La maintenance d'une base de données nécessite une surveillance constante, automatisée ou non, pour s'assurer qu'elle ne perd pas ses vertus. Les meilleures pratiques de maintenance de base de données garantissent que les bases de données conservent toujours leur :
- Intégrité et qualité des informations
- Performances
- Disponibilité
- Évolutivité
- Adaptabilité aux changements
- Traçabilité
- Sécurité
De nombreux conseils de modélisation des données sont disponibles pour vous aider à créer une bonne conception de base de données à chaque fois. Celles abordées ci-dessous visent spécifiquement à assurer ou faciliter la maintenance des qualités de bases de données évoquées ci-dessus.
Intégrité et qualité des informations
L'un des objectifs fondamentaux des meilleures pratiques de maintenance de la base de données est de garantir que les informations contenues dans la base de données conservent leur intégrité. Ceci est essentiel pour que les utilisateurs gardent confiance dans les informations.
Il existe deux types d'intégrité :l'intégrité physique et l'intégrité logique .
Intégrité physique
Le maintien de l'intégrité physique d'une base de données se fait en protégeant les informations des facteurs externes tels que les pannes de matériel ou de courant. L'approche la plus courante et largement acceptée consiste à utiliser une stratégie de sauvegarde adéquate qui permet la récupération d'une base de données dans un délai raisonnable si une catastrophe la détruit.
Pour les administrateurs de base de données et les administrateurs de serveur qui gèrent le stockage des bases de données, il est utile de savoir si les bases de données peuvent être partitionnées en sections avec des fréquences de mise à jour différentes. Cela leur permet d'optimiser l'utilisation du stockage et les plans de sauvegarde.
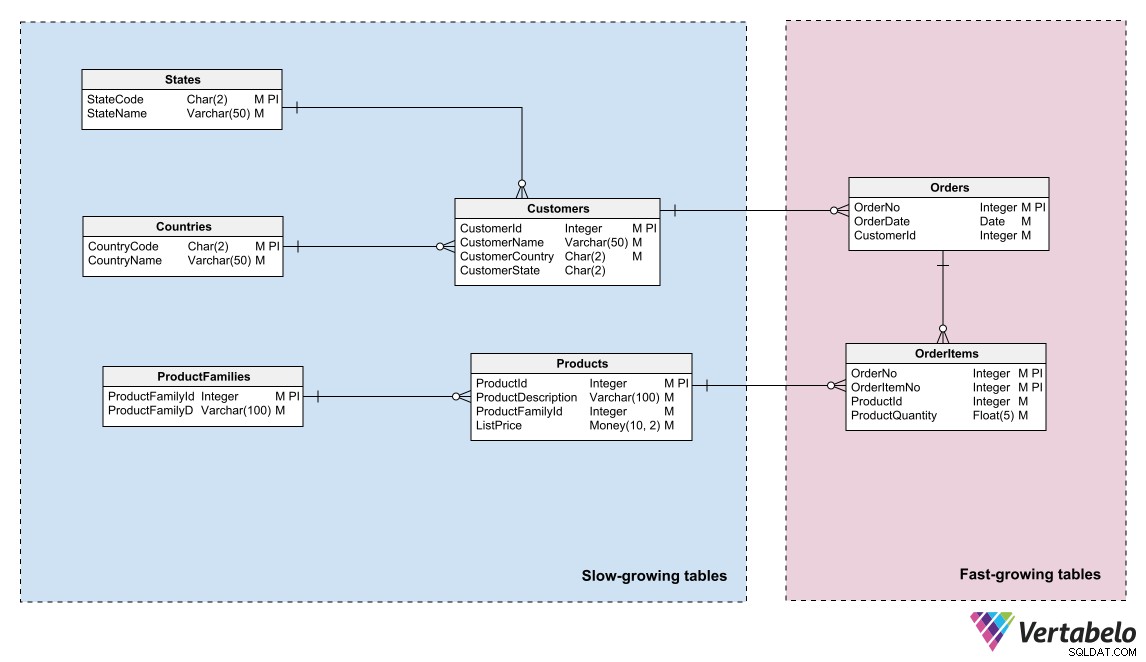
Les modèles de données peuvent refléter ce partitionnement en identifiant les zones de différentes « températures » de données et en regroupant les entités dans ces zones. La « température » fait référence à la fréquence à laquelle les tables reçoivent de nouvelles informations. Les tableaux qui sont mis à jour très fréquemment sont les « plus chauds »; ceux qui ne sont jamais ou rarement mis à jour sont les "plus froids".

Modèle de données d'un système de commerce électronique différenciant les données chaudes, chaudes et froides.
Un administrateur de base de données ou un administrateur système peut utiliser ce regroupement logique pour partitionner les fichiers de base de données et créer différents plans de sauvegarde pour chaque partition.
Intégrité logique
Le maintien de l'intégrité logique d'une base de données est essentiel pour la fiabilité et l'utilité des informations qu'elle délivre. Si une base de données manque d'intégrité logique, les applications qui l'utilisent révèlent tôt ou tard des incohérences dans les données. Face à ces incohérences, les utilisateurs se méfient des informations et recherchent simplement des sources de données plus fiables.
Parmi les tâches de maintenance de la base de données, le maintien de l'intégrité logique des informations est une extension de la tâche de modélisation de la base de données, seulement qu'il commence après la mise en production de la base de données et se poursuit tout au long de sa vie. La partie la plus critique de ce domaine de la maintenance est l'adaptation aux changements.
Gestion du changement
Les modifications des règles métier ou des exigences constituent une menace constante pour l'intégrité logique des bases de données. Vous pouvez vous sentir satisfait du modèle de données que vous avez construit, sachant qu'il est parfaitement adapté à l'entreprise, qu'il répond avec les bonnes informations à toute requête et qu'il omet toute anomalie d'insertion, de mise à jour ou de suppression. Profitez de ce moment de satisfaction, car il est de courte durée !
La maintenance d'une base de données implique de faire face à la nécessité d'apporter quotidiennement des modifications au modèle. Cela vous oblige à ajouter de nouveaux objets ou à modifier ceux qui existent déjà, à modifier la cardinalité des relations, à redéfinir les clés primaires, à changer les types de données et à faire d'autres choses qui font frissonner les modélisateurs.
Les changements se produisent tout le temps. Il se peut qu'une exigence ait été mal expliquée depuis le début, que de nouvelles exigences soient apparues ou que vous ayez involontairement introduit une faille dans votre modèle (après tout, nous, modélisateurs de données, ne sommes que des humains).
Vos modèles doivent être faciles à modifier lorsqu'un besoin de changement se fait sentir. Il est essentiel d'utiliser un outil de conception de base de données pour la modélisation qui vous permette de versionner vos modèles, de générer des scripts pour migrer une base de données d'une version à une autre et de documenter correctement chaque décision de conception.
Sans ces outils, chaque modification que vous apportez à votre conception crée des risques d'intégrité qui se révèlent aux moments les plus inopportuns. Vertabelo vous offre toutes ces fonctionnalités et s'occupe de maintenir l'historique des versions d'un modèle sans même que vous ayez à y penser.
La gestion automatique des versions intégrée à Vertabelo est d'une aide précieuse pour maintenir les modifications apportées à un modèle de données.
La gestion des changements et le contrôle des versions sont également des facteurs cruciaux pour intégrer les activités de modélisation des données dans le cycle de vie du développement logiciel.
Refactoring
Lorsque vous appliquez des modifications à une base de données en cours d'utilisation, vous devez être sûr à 100 % qu'aucune information n'est perdue et que son intégrité n'est pas affectée par les modifications. Pour ce faire, vous pouvez utiliser des techniques de refactoring. Ils sont normalement appliqués lorsque vous souhaitez améliorer une conception sans affecter sa sémantique, mais ils peuvent également être utilisés pour corriger des erreurs de conception ou adapter un modèle à de nouvelles exigences.
Il existe un grand nombre de techniques de refactoring. Ils sont généralement utilisés pour donner une nouvelle vie aux bases de données héritées, et il existe des procédures de manuel qui garantissent que les modifications ne nuisent pas aux informations existantes. Des livres entiers ont été écrits à ce sujet; Je vous recommande de les lire.
Mais pour résumer, nous pouvons regrouper les techniques de refactoring dans les catégories suivantes :
- Qualité des données : Apporter des changements qui assurent l'uniformité et la cohérence des données. Les exemples incluent l'ajout d'une table de recherche et la migration vers celle-ci de données répétées dans une autre table et l'ajout d'une contrainte sur une colonne.
- Structural : Apporter des modifications aux structures de table qui ne modifient pas la sémantique du modèle. Les exemples incluent la combinaison de deux colonnes en une seule, l'ajout d'une clé de remplacement et la division d'une colonne en deux.
- Intégrité référentielle : Appliquer des modifications pour s'assurer qu'une ligne référencée existe dans une table associée ou qu'une ligne non référencée peut être supprimée. Les exemples incluent l'ajout d'une contrainte de clé étrangère sur une colonne et l'ajout d'une contrainte de valeur non nulle sur une table.
- Architecture : Apporter des modifications visant à améliorer l'interaction des applications avec la base de données. Les exemples incluent la création d'un index, la mise en lecture seule d'une table et l'encapsulation d'une ou plusieurs tables dans une vue.
Les techniques qui modifient la sémantique du modèle, ainsi que celles qui n'altèrent en rien le modèle de données, ne sont pas considérées comme des techniques de refactoring. Celles-ci incluent l'insertion de lignes dans une table, l'ajout d'une nouvelle colonne, la création d'une nouvelle table ou vue et la mise à jour des données dans une table.
Maintenir la qualité des informations
La qualité de l'information dans une base de données est la mesure dans laquelle les données répondent aux attentes de l'organisation en matière d'exactitude, de validité, d'exhaustivité et de cohérence. Le maintien de la qualité des données tout au long du cycle de vie d'une base de données est essentiel pour que ses utilisateurs puissent prendre des décisions correctes et éclairées en utilisant les données qu'elle contient.
Votre responsabilité en tant que modélisateur de données est de vous assurer que vos modèles maintiennent la qualité de leurs informations au plus haut niveau possible. Pour ce faire :
- La conception doit suivre au moins la 3e forme normale afin qu'aucune anomalie d'insertion, de mise à jour ou de suppression ne se produise. Cette considération s'applique principalement aux bases de données à usage transactionnel, où les données sont ajoutées, mises à jour et supprimées régulièrement. Elle ne s'applique pas strictement dans les bases de données à usage analytique (c'est-à-dire les entrepôts de données), car la mise à jour et la suppression des données sont rarement effectuées, voire jamais.
- Les types de données de chaque champ de chaque table doivent être appropriés à l'attribut qu'ils représentent dans le modèle logique. Cela va au-delà de la définition correcte si un champ est d'un type de données numérique, date ou alphanumérique. Il est également important de définir correctement la plage et la précision des valeurs prises en charge par chaque champ. Un exemple :un attribut de type Date implémenté dans une base de données en tant que champ Date/Heure peut causer des problèmes dans les requêtes, car une valeur stockée avec sa partie heure autre que zéro peut tomber en dehors de la portée d'une requête qui utilise une plage de dates.
- Les dimensions et les faits qui définissent la structure d'un entrepôt de données doivent correspondre aux besoins de l'entreprise. Lors de la conception d'un entrepôt de données, les dimensions et les faits du modèle doivent être définis correctement dès le début. Apporter des modifications une fois la base de données opérationnelle s'accompagne d'un coût de maintenance très élevé.
Gérer la croissance
Un autre défi majeur dans la maintenance d'une base de données est d'empêcher sa croissance d'atteindre la limite de capacité de stockage de manière inattendue. Pour faciliter la gestion de l'espace de stockage, vous pouvez appliquer le même principe que celui utilisé dans les procédures de sauvegarde :regroupez les tables de votre modèle en fonction de leur vitesse de croissance.
Une division en deux zones est généralement suffisante. Placez les tableaux avec des ajouts de lignes fréquents dans une zone, ceux auxquels des lignes sont rarement insérées dans une autre. La segmentation du modèle de cette manière permet aux administrateurs de stockage de partitionner les fichiers de base de données en fonction du taux de croissance de chaque zone. Ils peuvent répartir les partitions sur différents supports de stockage avec différentes capacités ou possibilités de croissance.
Un regroupement de tables en fonction de leur taux de croissance permet de déterminer les besoins en stockage et de gérer sa croissance.
Journalisation
Nous créons un modèle de données en nous attendant à ce qu'il fournisse les informations telles qu'elles sont au moment de la requête. Cependant, nous avons tendance à négliger la nécessité d'une base de données pour se souvenir de tout ce qui s'est passé dans le passé, sauf si les utilisateurs l'exigent spécifiquement.
Une partie de la maintenance d'une base de données consiste à savoir comment, quand, pourquoi et par qui une donnée particulière a été modifiée. Cela peut être pour des choses telles que découvrir quand le prix d'un produit a changé ou examiner les changements dans le dossier médical d'un patient dans un hôpital. La journalisation peut être utilisée même pour corriger les erreurs de l'utilisateur ou de l'application, car elle vous permet de restaurer l'état des informations à un point antérieur sans avoir à recourir à des procédures de restauration de sauvegarde compliquées.
Encore une fois, même si les utilisateurs n'en ont pas explicitement besoin, la prise en compte de la nécessité d'une journalisation proactive est un moyen très précieux de faciliter la maintenance de la base de données et de démontrer votre capacité à anticiper les problèmes. Le fait de disposer de données de journalisation permet des réponses immédiates lorsque quelqu'un a besoin d'examiner des informations historiques.
Il existe différentes stratégies pour qu'un modèle de base de données prenne en charge la journalisation, qui ajoutent toutes de la complexité au modèle. Une approche est appelée journalisation sur place, qui ajoute des colonnes à chaque table pour enregistrer les informations de version. Il s'agit d'une option simple qui n'implique pas la création de schémas séparés ou de tables spécifiques à la journalisation. Cependant, cela a un impact sur la conception du modèle car les clés primaires d'origine des tables ne sont plus valides en tant que clés primaires - leurs valeurs sont répétées dans des lignes qui représentent différentes versions des mêmes données.
Une autre option pour conserver les informations du journal consiste à utiliser des tables fantômes. Les tables fantômes sont des répliques des tables modèles avec l'ajout de colonnes pour enregistrer les données de suivi du journal. Cette stratégie ne nécessite pas de modifier les tables du modèle d'origine, mais vous devez vous rappeler de mettre à jour les tables fantômes correspondantes lorsque vous modifiez votre modèle de données.
Une autre stratégie consiste à utiliser un sous-schéma de tables génériques qui enregistrent chaque insertion, suppression ou modification de toute autre table.
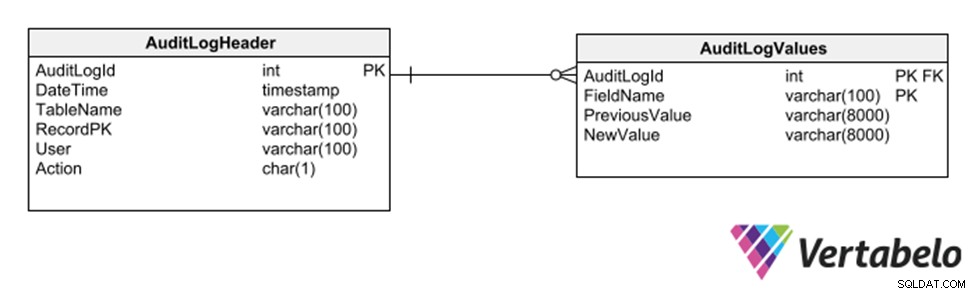
Tables génériques pour conserver une piste d'audit d'une base de données.
Cette stratégie présente l'avantage de ne pas nécessiter de modifications du modèle d'enregistrement d'une piste d'audit. Cependant, comme il utilise des colonnes génériques de type varchar, il limite les types de données pouvant être enregistrées dans le journal de suivi.
Maintenance des performances et création d'index
Pratiquement toutes les bases de données ont de bonnes performances lorsqu'elles commencent tout juste à être utilisées et que leurs tables ne contiennent que quelques lignes. Mais dès que les applications commencent à le remplir de données, les performances peuvent se dégrader très rapidement si des précautions ne sont pas prises dans la conception du modèle. Lorsque cela se produit, les DBA et les administrateurs système font appel à vous pour les aider à résoudre les problèmes de performances.
La création/suggestion automatique d'index sur les bases de données de production est un outil utile pour résoudre les problèmes de performances "dans le feu de l'action". Les moteurs de base de données peuvent analyser les activités de la base de données pour voir quelles opérations prennent le plus de temps et où il est possible d'accélérer en créant des index.
Cependant, il est préférable d'être proactif et d'anticiper la situation en définissant des index dans le cadre du modèle de données. Cela réduit considérablement les efforts de maintenance pour améliorer les performances de la base de données. Si vous n'êtes pas familier avec les avantages des index de base de données, je vous suggère de lire tout sur les index, en commençant par les bases.
Il existe des règles pratiques qui fournissent suffisamment de conseils pour créer les index les plus importants pour des requêtes efficaces. La première consiste à générer des index pour la clé primaire de chaque table. Pratiquement chaque SGBDR génère automatiquement un index pour chaque clé primaire, vous pouvez donc oublier cette règle.
Une autre règle consiste à générer des index pour les clés alternatives d'une table, en particulier dans les tables pour lesquelles une clé de substitution est créée. Si une table a une clé naturelle qui n'est pas utilisée comme clé primaire, les requêtes pour joindre cette table avec d'autres le font très probablement avec la clé naturelle, pas le substitut. Ces requêtes ne fonctionnent pas correctement à moins que vous ne créiez un index sur la clé naturelle.
La règle d'or suivante pour les index est de les générer pour tous les champs qui sont des clés étrangères. Ces champs sont d'excellents candidats pour établir des jointures avec d'autres tables. S'ils sont inclus dans les index, ils sont utilisés par les analyseurs de requêtes pour accélérer l'exécution et améliorer les performances de la base de données.
Enfin, c'est une bonne idée d'utiliser un outil de profilage sur une base de données intermédiaire ou QA lors des tests de performances pour détecter toute opportunité de création d'index qui n'est pas évidente. L'intégration des index suggérés par les outils de profilage dans le modèle de données est extrêmement utile pour atteindre et maintenir les performances de la base de données une fois qu'elle est en production.
Sécurité
Dans votre rôle de modélisateur de données, vous pouvez aider à maintenir la sécurité de la base de données en fournissant une base solide et sécurisée dans laquelle stocker les données pour l'authentification des utilisateurs. Gardez à l'esprit que ces informations sont très sensibles et ne doivent pas être exposées à des cyberattaques.
Pour que votre conception simplifie la maintenance de la sécurité de la base de données, suivez les meilleures pratiques de stockage des données d'authentification, dont la principale est de ne pas stocker les mots de passe dans la base de données même sous forme cryptée. Stocker uniquement son hachage au lieu du mot de passe pour chaque utilisateur permet à une application d'authentifier la connexion d'un utilisateur sans créer de risque d'exposition du mot de passe.
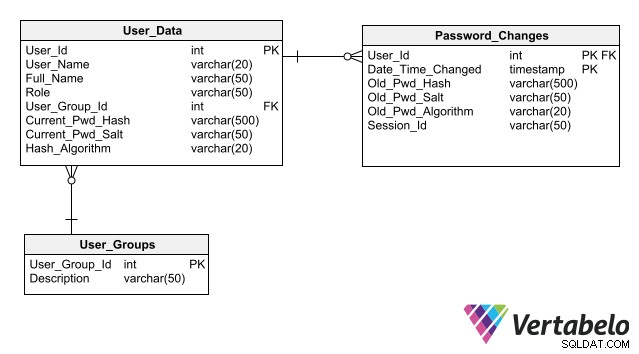
Un schéma complet pour l'authentification des utilisateurs qui inclut des colonnes pour stocker les hachages de mot de passe.
Vision pour l'avenir
Créez donc vos modèles pour une maintenance facile de la base de données avec de bonnes conceptions de base de données en tenant compte des conseils donnés ci-dessus. Avec des modèles de données plus maintenables, votre travail est plus beau et vous gagnez l'appréciation des administrateurs de base de données, des ingénieurs de maintenance et des administrateurs système.
Vous investissez également dans la tranquillité d'esprit. La création de bases de données facilement maintenables signifie que vous pouvez passer vos heures de travail à concevoir de nouveaux modèles de données, plutôt que de devoir corriger des bases de données qui ne fournissent pas les informations correctes à temps.