Ce message fournit de nouvelles informations sur les conditions préalables au chargement groupé minimalement enregistré lors de l'utilisation de INSERT...SELECT dans les tables indexées .
L'installation interne qui permet ces cas s'appelle FastLoadContext . Il peut être activé de SQL Server 2008 à 2014 inclus à l'aide de l'indicateur de trace documenté 610. À partir de SQL Server 2016, FastLoadContext est activé par défaut ; l'indicateur de suivi n'est pas requis.
Sans FastLoadContext , les seules insertions d'index pouvant être enregistrées de manière minimale sont ceux dans un vide index clusterisé sans index secondaires, comme indiqué dans la deuxième partie de cette série. La journalisation minimale les conditions pour les tables de tas non indexées ont été couvertes dans la première partie.
Pour plus d'informations, consultez le guide de chargement des performances des données et l'équipe Tiger notes sur les changements de comportement pour SQL Server 2016.
Contexte de chargement rapide
Pour rappel, le RowsetBulk installation (couverte dans les parties 1 et 2) permet une journalisation minimale chargement groupé pour :
- Tas vide et non vide tableaux avec :
- Verrouillage des tables ; et
- Aucun index secondaire.
- Tables groupées vides , avec :
- Verrouillage des tables ; et
- Aucun index secondaire ; et
DMLRequestSort=truesur l'insertion d'index cluster opérateur.
Le FastLoadContext le chemin du code ajoute la prise en charge de minimally-logged et concurrent chargement groupé sur :
- Vides et non vides regroupés index b-tree.
- Vides et non vides non clusterisés index b-tree maintenus par un dédié Insertion d'index opérateur de plan.
Le FastLoadContext nécessite également DMLRequestSort=true sur l'opérateur du plan correspondant dans tous les cas.
Vous avez peut-être remarqué un chevauchement entre RowsetBulk et FastLoadContext pour les tables en cluster vides sans index secondaires. Un TABLOCK l'indice n'est pas nécessaire avec FastLoadContext , mais il n'est pas obligatoire d'être absent Soit. En conséquence, un insert approprié avec TABLOCK peut toujours être éligible à la journalisation minimale via FastLoadContext en cas d'échec, le RowsetBulk détaillé tests.
FastLoadContext peut être désactivé sur SQL Server 2016 à l'aide de l'indicateur de trace documenté 692. L'événement étendu du canal de débogage fastloadcontext_enabled peut être utilisé pour surveiller FastLoadContext utilisation par partition d'index (ensemble de lignes). Cet événement ne se déclenche pas pour RowsetBulk charges.
Journalisation mixte
Un seul INSERT...SELECT instruction utilisant FastLoadContext peut se connecter entièrement certaines lignes pendant la journalisation minimale autres.
Les lignes sont insérées une à la fois par l'insertion d'index opérateur et entièrement connecté dans les cas suivants :
- Toutes les lignes ajoutées à la première page d'index, si l'index était vide au début de l'opération.
- Lignes ajoutées à existantes pages d'index.
- Lignes déplacées entre les pages par un fractionnement de page.
Sinon, les lignes du flux d'insertion commandé sont ajoutées à une toute nouvelle page à l'aide d'un outil optimisé et minimalement enregistré chemin de code. Une fois qu'autant de lignes que possible sont écrites dans la nouvelle page, celle-ci est directement liée à la structure d'index cible existante.
La page nouvellement ajoutée ne sera pas nécessairement être complet (bien que ce soit évidemment le cas idéal) car SQL Server doit faire attention à ne pas ajouter de lignes à la nouvelle page qui appartiennent logiquement à un existant sommaire. La nouvelle page sera "cousue" dans l'index en tant qu'unité, de sorte que nous ne pouvons pas avoir de lignes sur la nouvelle page qui appartiennent ailleurs. Il s'agit principalement d'un problème lors de l'ajout de lignes dans la plage de clés existante de l'index, plutôt qu'avant le début ou après la fin de la plage de clés d'index existante.
C'est encore possible pour ajouter de nouvelles pages dans la plage de clés d'index existante, mais les nouvelles lignes doivent être triées plus haut que la clé la plus élevée sur le précédent page d'index existante et trier plus bas que la clé la plus basse sur le suivant page d'index existante. Pour avoir les meilleures chances d'obtenir une journalisation minimale dans ces circonstances, assurez-vous que les lignes insérées ne chevauchent pas autant que possible les lignes existantes.
Conditions DMLRequestSort
N'oubliez pas que FastLoadContext ne peut être activé que si DMLRequestSort est défini sur true pour l'insertion d'index correspondante opérateur dans le plan d'exécution.
Il existe deux chemins de code principaux qui peuvent définir DMLRequestSort à vrai pour les insertions d'index. L'un ou l'autre chemin retour vrai est suffisant.
1. FOptimiserInsérer
Le sqllang!CUpdUtil::FOptimizeInsert le code nécessite :
- Plus de 250 lignes estimé à insérer ; et
- Plus de 2 pages estimé insérer la taille des données ; et
- L'indice cible doit avoir moins de 3 pages feuilles .
Ces conditions sont les mêmes que pour RowsetBulk sur un index cluster vide, avec une exigence supplémentaire pour pas plus de deux pages d'index de niveau feuille. Notez bien que cela fait référence à la taille de l'index existant avant l'insertion, pas la taille estimée des données à ajouter.
Le script ci-dessous est une modification de la démo utilisée dans les parties précédentes de cette série. Il montre une journalisation minimale lorsque moins de trois pages d'index sont remplies avant le test INSERT...SELECT court. Le schéma de table de test est tel que 130 lignes peuvent tenir sur une seule page de 8 Ko lorsque la gestion des versions de ligne est désactivée pour la base de données. Le multiplicateur dans le premier TOP la clause peut être modifiée pour déterminer le nombre de pages d'index existantes avant le test INSERT...SELECT est exécuté :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (3 * 130) -- Change the 3 here
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
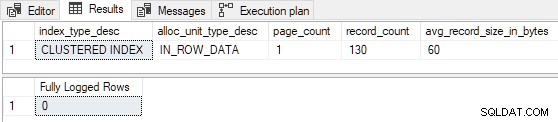
GO Lorsque l'index clusterisé est préchargé avec 3 pages , l'insert de test est entièrement enregistré (enregistrements détaillés du journal des transactions omis par souci de brièveté) :
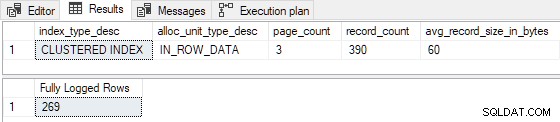
Lorsque le tableau est préchargé avec seulement 1 ou 2 pages , l'insert de test est enregistré au minimum :
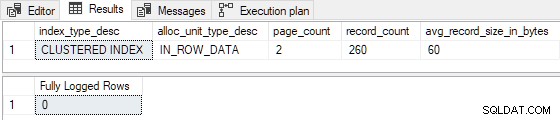
Lorsque le tableau n'est pas préchargé avec n'importe quelle page, le test équivaut à exécuter la démonstration de table en cluster vide de la deuxième partie, mais sans le TABLOCK indice :
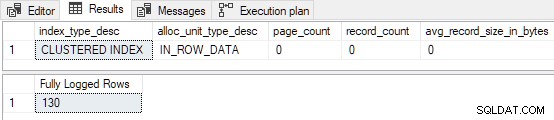
Les 130 premières lignes sont entièrement enregistrées . C'est parce que l'index était vide avant de commencer et que 130 lignes tiennent sur la première page. N'oubliez pas que la première page est toujours entièrement enregistrée lorsque FastLoadContext est utilisé et l'index était vide auparavant. Les 139 lignes restantes sont insérées avec une journalisation minimale .
Si un TABLOCK un indice est ajouté à l'encart, toutes les pages sont minimalement enregistrés (y compris le premier) car le chargement de l'index cluster vide se qualifie désormais pour le RowsetBulk mécanisme (au prix de la prise d'un Sch-M verrou).
2. FDemandRowsSortedForPerformance
Si le FOptimizeInsert les tests échouent, DMLRequestSort peut toujours être défini sur true par un deuxième ensemble de tests dans le sqllang!CUpdUtil::FDemandRowsSortedForPerformance code. Ces conditions sont un peu plus complexes, il sera donc utile de définir quelques paramètres :
P– nombre de pages de niveau feuille existantes dans l'index cible .I– estimé nombre de lignes à insérer.R=P/I(pages cibles par ligne insérée).T– nombre de partitions cibles (1 pour non partitionné).
La logique pour déterminer la valeur de DMLRequestSort est alors :
- Si
P <= 16renvoie faux , sinon :- Si
R < 8:- Si
P > 524renvoie vrai , sinon faux .
- Si
- Si
R >= 8:- Si
T > 1etI > 250renvoie vrai , sinon faux .
- Si
- Si
Les tests ci-dessus sont évalués par le processeur de requêtes lors de la compilation du plan. Il y a une condition finale évalué par le code du moteur de stockage (IndexDataSetSession::WakeUpInternal ) au moment de l'exécution :
DMLRequestSortest actuellement vrai; etI >= 100.
Nous décomposerons ensuite toute cette logique en éléments gérables.
Plus de 16 pages cibles existantes
Le premier essai P <= 16 signifie que les index avec moins de 17 pages feuille existantes ne seront pas éligibles pour FastLoadContext via ce chemin de code. Pour être tout à fait clair sur ce point, P est le nombre de pages de niveau feuille dans l'index cible avant le INSERT...SELECT est exécuté.
Pour illustrer cette partie de la logique, nous allons précharger le tableau groupé de test avec 16 pages de données. Cela a deux effets importants (rappelez-vous que les deux chemins de code doivent renvoyer false se retrouver avec un faux valeur pour DMLRequestSort ):
- Il garantit que le précédent
FOptimizeInsertle test échoue , car la troisième condition n'est pas remplie (P < 3). - Le
P <= 16condition dansFDemandRowsSortedForPerformancene sera également pas être rencontré.
Nous attendons donc FastLoadContext ne pas être activé. Le script de démonstration modifié est :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (16 * 130) -- 16 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (269)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)'; Les 269 lignes sont entièrement enregistrées comme prévu :
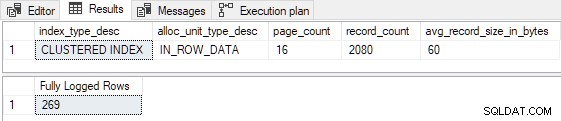
Notez que quel que soit le nombre de nouvelles lignes à insérer, le script ci-dessus ne sera jamais produire une journalisation minimale à cause du P <= 16 test (et P < 3 tester dans FOptimizeInsert ).
Si vous choisissez d'exécuter la démo vous-même avec un plus grand nombre de lignes, commentez la section qui affiche les enregistrements individuels du journal des transactions, sinon vous attendrez très longtemps et SSMS risque de se bloquer. (Pour être juste, cela pourrait le faire de toute façon, mais pourquoi ajouter au risque.)
Taux de pages par ligne insérée
S'il y en a 17 ou plus pages feuilles dans l'index existant, le précédent P <= 16 le test n'échouera pas. La prochaine section de logique traite du ratio de pages existantes aux lignes nouvellement insérées . Cela doit également réussir pour obtenir une journalisation minimale . Pour rappel, les conditions applicables sont :
- Rapport
R=P/I. - Si
R < 8:- Si
P > 524renvoie vrai , sinon faux .
- Si
Il faut aussi retenir le test final du moteur de stockage pour au moins 100 lignes :
I >= 100.
Réorganiser un peu ces conditions, tous des éléments suivants doit être vrai :
P > 524(pages d'index existantes)I >= 100(lignes insérées estimées)P / I < 8(rapportR)
Il existe plusieurs façons de remplir ces trois conditions simultanément. Choisissons les valeurs minimales possibles pour P (525) et I (100) donnant un R valeur de (525 / 100) =5,25. Cela satisfait le (R < 8 test), nous nous attendons donc à ce que cette combinaison entraîne une journalisation minimale :
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- 130 rows per page for this table
-- structure with row versioning off
INSERT dbo.Test
(c1)
SELECT TOP (525 * 130) -- 525 pages
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show physical index statistics
-- to confirm the number of pages
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.Test', N'U'),
1, -- Index ID
NULL, -- Partition ID
'DETAILED'
) AS DDIPS
WHERE
DDIPS.index_level = 0; -- leaf level only
GO
-- Clear the plan cache
DBCC FREEPROCCACHE;
GO
-- Clear the log
CHECKPOINT;
GO
-- Main test
INSERT dbo.Test
(c1)
SELECT TOP (100)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
Le INSERT...SELECT de 100 lignes est en effet enregistré au minimum :
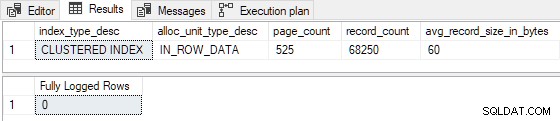
Réduire l'estimation lignes insérées à 99 (casse I >= 100 ), et/ou réduire le nombre de pages d'index existantes à 524 (casser P > 524 ) entraîne une journalisation complète . Nous pourrions également apporter des modifications telles que R n'est plus inférieur à 8 pour produire une journalisation complète . Par exemple, en définissant P = 1000 et I = 125 donne R = 8 , avec les résultats suivants :
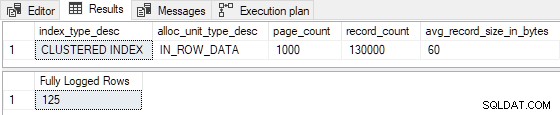
Les 125 lignes insérées ont été entièrement consignées comme prévu. (Cela n'est pas dû à la journalisation complète de la première page, puisque l'index n'était pas vide auparavant.)
Taux de pages pour les index partitionnés
Si tous les tests précédents échouent, le test restant nécessite R >= 8 et ne peut seulement être satisfait lorsque le nombre de partitions (T ) est supérieur à 1 et il y en a plus de 250 estimés lignes insérées (I ). Rappel :
- Si
R >= 8:- Si
T > 1etI > 250renvoie vrai , sinon faux .
- Si
Une subtilité :pour partitionné index, la règle qui dit que toutes les lignes de la première page sont entièrement enregistrées (pour un index initialement vide) s'applique par partition . Pour un objet avec 15 000 partitions, cela signifie 15 000 "premières" pages entièrement enregistrées.
Résumé et réflexions finales
Les formules et l'ordre d'évaluation décrits dans le corps sont basés sur l'inspection du code à l'aide d'un débogueur. Ils ont été présentés sous une forme qui représente fidèlement la synchronisation et l'ordre utilisés dans le code réel.
Il est possible de réorganiser et de simplifier un peu ces conditions, pour produire un résumé plus concis des exigences pratiques pour la journalisation minimale lors de l'insertion dans un b-tree en utilisant INSERT...SELECT . Les expressions raffinées ci-dessous utilisent les trois paramètres suivants :
P=nombre de existants indexer les pages de niveau feuille.I=estimé nombre de lignes à insérer.S=estimé insérer la taille des données dans les pages de 8 Ko.
Chargement groupé d'ensembles de lignes
- Utilise
sqlmin!RowsetBulk. - Nécessite un vide cible d'index clusterisé avec
TABLOCK(ou équivalent). - Nécessite
DMLRequestSort = truesur l'insertion d'index cluster opérateur. DMLRequestSortest définitruesiI > 250etS > 2.- Toutes les lignes insérées sont minimalement enregistrées .
- Un
Sch-Mle verrou empêche l'accès simultané à la table.
Contexte de chargement rapide
- Utilise
sqlmin!FastLoadContext. - Active la consignation minimale insère dans les index b-tree :
- En cluster ou non en cluster.
- Avec ou sans verrou de table.
- Index cible vide ou non.
- Nécessite
DMLRequestSort = truesur l'encart d'index associé opérateur de plan. - Seules les lignes écrites sur les nouvelles pages sont chargés en masse et enregistrés de manière minimale .
- La première page d'un index précédemment vide la partition est toujours entièrement enregistrée .
- Minimum absolu de
I >= 100. - Nécessite l'indicateur de trace 610 avant SQL Server 2016.
- Disponible par défaut à partir de SQL Server 2016 (l'indicateur de trace 692 est désactivé).
DMLRequestSort est défini true pour :
- N'importe quel index (partitionné ou non) si :
I > 250etP < 3etS > 2; ouI >= 100etP > 524etP < I * 8
Pour les index partitionnés uniquement (avec> 1 partition), DMLRequestSort est également défini true si :
I > 250etP > 16etP >= I * 8
Il y a quelques cas intéressants découlant de ces FastLoadContext condition :
- Tous insère dans un fichier non partitionné index avec entre 3 et 524 (inclus) les pages feuille existantes seront entièrement enregistrées quel que soit le nombre et la taille totale des lignes ajoutées. Cela affectera plus particulièrement les grandes insertions dans les petits tableaux (mais pas vides).
- Tous insère dans un partitionné index entre 3 et 16 les pages existantes seront entièrement enregistrées .
- Grands inserts à grand non partitionné les index peuvent ne pas être minimalement enregistrés en raison de l'inégalité
P < I * 8. QuandPest grand, un estimé proportionnellement grand nombre de lignes insérées (I) est requis. Par exemple, un index de 8 millions de pages ne peut pas prendre en charge la journalisation minimale lors de l'insertion de 1 million de lignes ou moins.
Index non cluster
Les mêmes considérations et calculs appliqués aux index clusterisés dans les démos s'appliquent aux index non clusterisés index b-tree également, tant que l'index est maintenu par un opérateur de plan dédié (un large , ou par index plan). Index non clusterisés gérés par un opérateur de table de base (par exemple, Clustered Index Insert ) ne sont pas éligibles pour FastLoadContext .
Notez que les paramètres de la formule doivent être évalués à nouveau pour chaque élément non clusterisé opérateur d'index :taille de ligne calculée, nombre de pages d'index existantes et estimation de la cardinalité.
Remarques générales
Faites attention aux estimations de faible cardinalité à l'insertion d'index opérateur, car ceux-ci affecteront le I et S paramètres. Si un seuil n'est pas atteint en raison d'une erreur d'estimation de cardinalité, l'insertion sera entièrement enregistrée .
N'oubliez pas que DMLRequestSort est mis en cache avec le plan — il n'est pas évalué à chaque exécution d'un plan réutilisé. Cela peut introduire une forme du problème de sensibilité aux paramètres bien connu (également connu sous le nom de "reniflage de paramètres").
La valeur de P (pages feuille d'index) n'est pas actualisé au début de chaque instruction. L'implémentation actuelle met en cache la valeur pour l'ensemble du lot . Cela peut avoir des effets secondaires inattendus. Par exemple, un TRUNCATE TABLE dans le même lot en tant que INSERT...SELECT ne réinitialisera pas P à zéro pour les calculs décrits dans cet article - ils continueront à utiliser la valeur pré-tronquée et une recompilation n'aidera pas. Une solution de contournement consiste à soumettre des modifications importantes dans des lots séparés.
Drapeaux de suivi
Il est possible de forcer FDemandRowsSortedForPerformance pour retourner vrai en définissant non documenté et non pris en charge trace flag 2332, comme je l'ai écrit dans Optimisation des requêtes T-SQL qui modifient les données. Lorsque TF 2332 est actif, le nombre de lignes estimées à insérer doit encore être au moins 100 . TF 2332 affecte la journalisation minimale décision pour FastLoadContext uniquement (il est efficace pour les tas partitionnés dans la mesure où DMLRequestSort est concerné, mais n'a aucun effet sur le tas lui-même, puisque FastLoadContext ne s'applique qu'aux index).
Un large/par index la forme du plan pour la maintenance des index non clusterisés peut être forcée pour les tables rowstore à l'aide de l'indicateur de trace 8790 (non officiellement documenté, mais mentionné dans un article de la base de connaissances ainsi que dans mon article lié pour TF2332 juste au-dessus).
Lecture connexe
Le tout par Sunil Agarwal de l'équipe SQL Server :
- Quelles sont les optimisations d'importation groupée ?
- Optimisations d'importation en masse (journalisation minimale)
- Modifications minimales de la journalisation dans SQL Server 2008
- Modifications minimales de la journalisation dans SQL Server 2008 (partie 2)
- Modifications minimales de la journalisation dans SQL Server 2008 (partie 3)