PostgreSQL, également connue comme la base de données open source la plus avancée au monde, a une nouvelle version depuis le 24 septembre 2020 dernier, et maintenant qu'elle est mature, nous pouvons vérifier ce qu'il y a de nouveau pour commencer à réfléchir à un projet de migration. PostgreSQL 13 est disponible avec de nombreuses nouvelles fonctionnalités et améliorations. Dans ce blog, nous mentionnerons certaines de ces nouvelles fonctionnalités et verrons comment déployer ou mettre à niveau votre version actuelle de PostgreSQL.
Nouvelles fonctionnalités et améliorations de PostgreSQL 13
Commençons par mentionner certaines des nouvelles fonctionnalités et améliorations de cette version de PostgreSQL 13 que vous pouvez voir dans la documentation officielle.
Partitionnement
-
Autoriser l'élagage des partitions et les jointures par partition dans plus de cas
-
Prise en charge des déclencheurs AVANT au niveau de la ligne sur les tables partitionnées
-
Autoriser la réplication logique des tables partitionnées via la publication
-
Autoriser la réplication logique dans des tables partitionnées sur les abonnés
-
Autoriser l'utilisation de variables de ligne entière dans les expressions de partitionnement
Index
-
Stocker plus efficacement les doublons dans les index B-tree
-
Autoriser les index GiST et SP-GiST sur les colonnes de boîte à prendre en charge les requêtes de points ORDER BY box <->
-
Permettre aux index GIN de gérer plus efficacement ! Clauses (NOT) dans les recherches tsquery
-
Autoriser les classes d'opérateurs d'index à prendre des paramètres
Optimiseur
-
Améliorer l'estimation de la sélectivité de l'optimiseur pour les opérateurs de confinement/correspondance
-
Autoriser la définition de la cible des statistiques pour les statistiques étendues
-
Autoriser l'utilisation de plusieurs objets statistiques étendus dans une seule requête
-
Autoriser l'utilisation d'objets statistiques étendus pour les clauses OR et les listes de constantes IN/ANY
-
Autoriser les fonctions dans les clauses FROM à être extraites (en ligne) si elles évaluent des constantes
Performances
-
Mettre en œuvre le tri incrémentiel et améliorer les performances de tri des valeurs inet
-
Autoriser l'agrégation de hachage à utiliser le stockage sur disque pour les grands ensembles de résultats d'agrégation
-
Autoriser les insertions, pas seulement les mises à jour et les suppressions, à déclencher l'activité de nettoyage dans autovacuum
-
Ajouter le paramètre maintenance_io_concurrency pour contrôler la simultanéité des E/S pour les opérations de maintenance
-
Autoriser les écritures WAL à ignorer lors d'une transaction qui crée ou réécrit une relation, si wal_level est minimal
-
Améliorer les performances lors de la relecture des commandes DROP DATABASE lorsque de nombreux espaces de table sont utilisés
-
Accélérer les conversions d'entiers en texte
-
Réduire l'utilisation de la mémoire pour les chaînes de requête et les scripts d'extension contenant de nombreuses instructions SQL
Surveillance
-
Autoriser EXPLAIN, auto_explain, autovacuum et pg_stat_statements à suivre les statistiques d'utilisation des WAL
-
Autoriser la journalisation d'un échantillon d'instructions SQL, plutôt que de toutes les instructions
-
Ajoutez le type de backend à csvlog et éventuellement la sortie de journal log_line_prefix
-
Améliorer le contrôle de la journalisation des paramètres des instructions préparées
-
Ajoutez leader_pid à pg_stat_activity pour signaler le processus leader d'un travailleur parallèle
-
Ajouter la vue système pg_stat_progress_basebackup pour signaler la progression des sauvegardes de base en continu
-
Ajouter une vue système pg_stat_progress_analyze pour signaler la progression de l'ANALYSE
-
Ajouter la vue système pg_shmem_allocations pour afficher l'utilisation de la mémoire partagée
Réplication et restauration
-
Autoriser la modification des paramètres de configuration de la réplication en continu en rechargeant
-
Autoriser les récepteurs WAL à utiliser un emplacement de réplication temporaire lorsqu'un emplacement permanent n'est pas spécifié
-
Autoriser le stockage WAL pour les slots de réplication à limiter par max_slot_wal_keep_size
-
Autoriser la promotion de veille à annuler toute pause demandée
-
Générer une erreur si la récupération n'atteint pas la cible de récupération spécifiée
-
Autoriser le contrôle de la quantité de mémoire utilisée par le décodage logique avant qu'elle ne soit déversée sur le disque
-
Autoriser la poursuite de la récupération même si des pages invalides sont référencées par WAL
Commandes utilitaires
-
Autoriser VACUUM à traiter les index d'une table en parallèle
-
Signaler l'utilisation du tampon de temps de planification dans la sortie BUFFER d'EXPLAIN
-
Faites en sorte que CREATE TABLE LIKE propage la propriété NO INHERIT d'une contrainte CHECK à la table créée
-
Ajouter ALTER TABLE ... DROP EXPRESSION pour permettre de supprimer la propriété GENERATED d'une colonne
-
Ajouter la syntaxe ALTER VIEW pour renommer les colonnes de vue
-
Ajouter des options ALTER TYPE pour modifier les propriétés TOAST d'un type de base et les fonctions de support
-
Ajouter l'option CREATE DATABASE LOCALE
-
Autoriser DROP DATABASE à déconnecter les sessions utilisant la base de données cible, permettant à la suppression de réussir
Et bien d'autres changements. Nous venons d'en mentionner quelques-uns pour éviter un article de blog plus volumineux. Voyons maintenant comment déployer cette nouvelle version.
Comment déployer PostgreSQL 13
Pour cela, nous supposerons que vous avez installé ClusterControl, sinon, vous pouvez suivre la documentation correspondante pour l'installer.
Pour effectuer un déploiement à partir de ClusterControl, sélectionnez simplement l'option Déployer et suivez les instructions qui s'affichent.
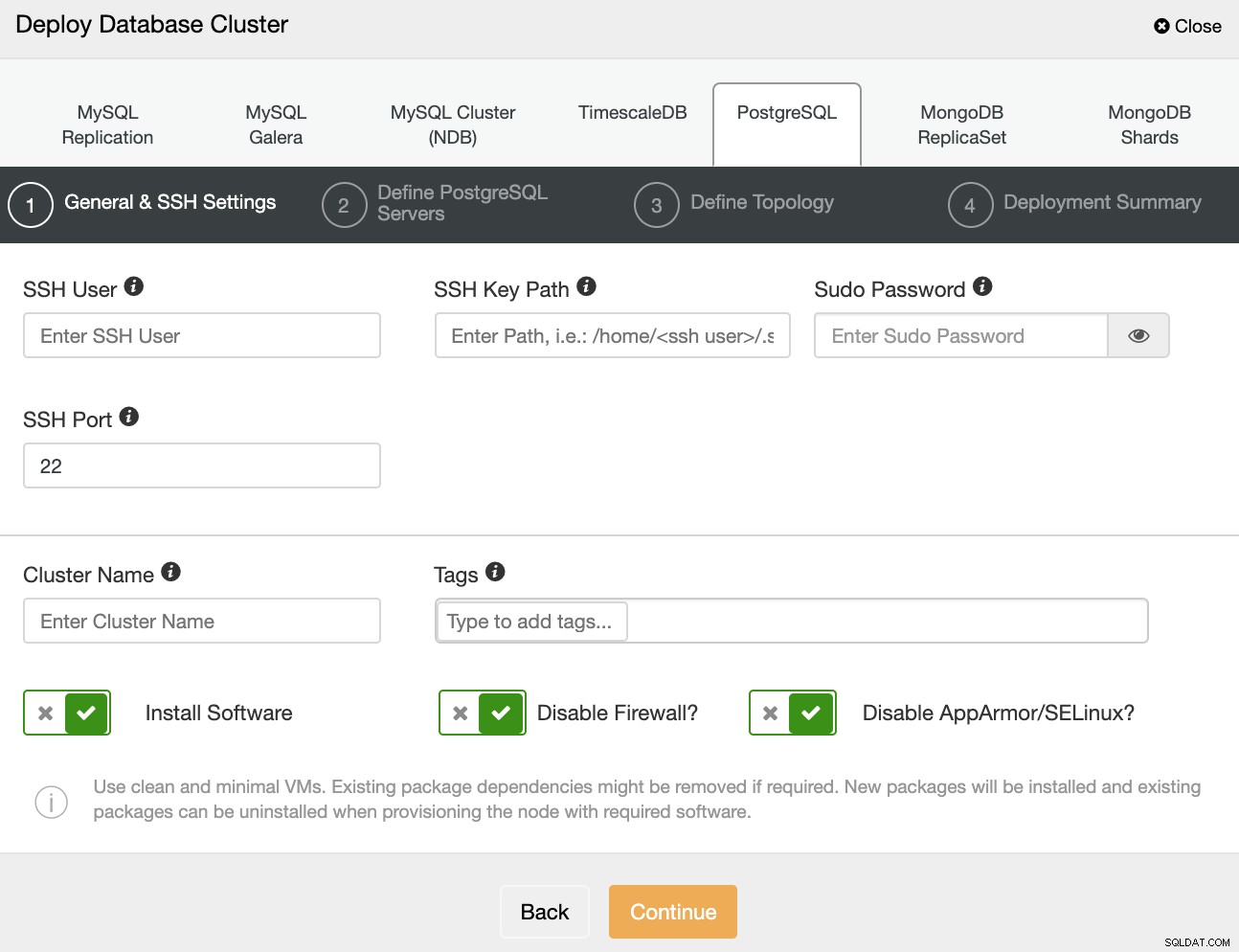
Lorsque vous sélectionnez PostgreSQL, vous devez spécifier l'utilisateur, la clé ou le mot de passe et le port pour vous connecter en SSH à vos serveurs. Vous pouvez également ajouter un nom pour votre nouveau cluster et si vous souhaitez que ClusterControl installe le logiciel et les configurations correspondants pour vous.
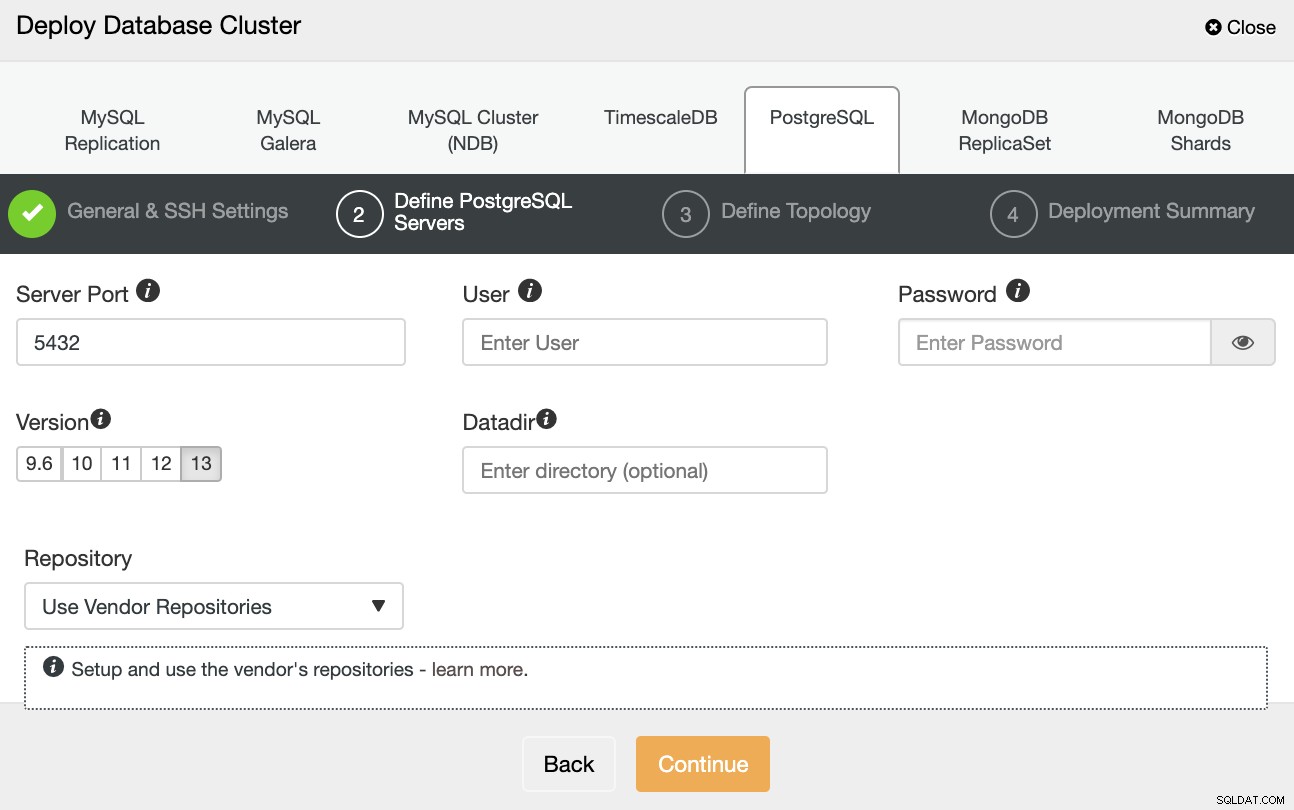
Après avoir configuré les informations d'accès SSH, vous devez définir les informations d'identification de la base de données , version et datadir (facultatif). Vous pouvez également spécifier le référentiel à utiliser.
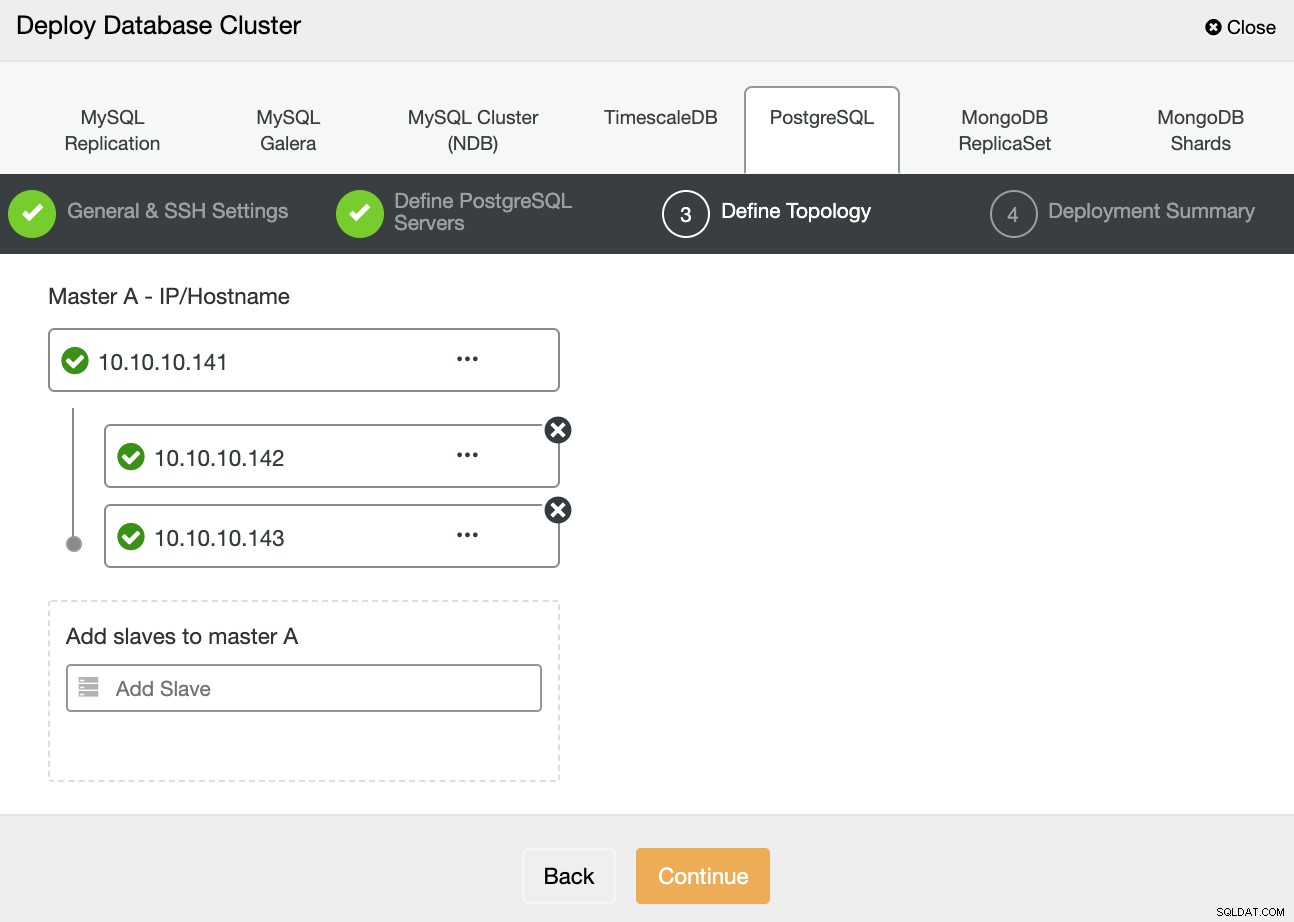
À l'étape suivante, vous devez ajouter vos serveurs au cluster que vous allez créer à l'aide de l'adresse IP ou du nom d'hôte.
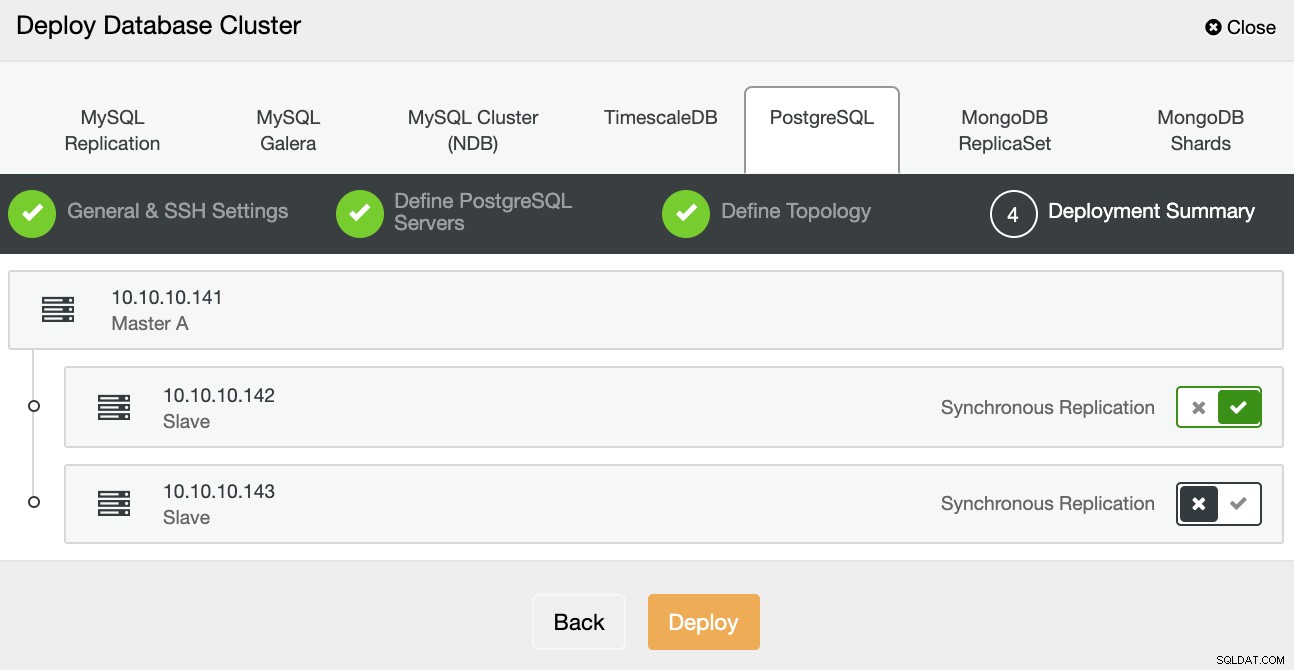
Dans la dernière étape, vous pouvez choisir si votre réplication sera synchrone ou Asynchrone, puis appuyez simplement sur Déployer.
Une fois la tâche terminée, vous pouvez voir votre nouveau cluster PostgreSQL dans le l'écran principal de ClusterControl.

Maintenant que votre cluster est créé, vous pouvez effectuer plusieurs tâches dessus, comme l'ajout d'équilibreurs de charge (HAProxy), de pooleurs de connexions (PgBouncer) ou de nouveaux esclaves de réplication à partir de la même interface utilisateur ClusterControl.
Mettre à jour vers PostgreSQL 13
Si vous souhaitez mettre à niveau votre version actuelle de PostgreSQL vers cette nouvelle version, vous disposez de trois options principales pour effectuer cette tâche.
-
Pg_dump :c'est un outil de sauvegarde logique qui vous permet de vider vos données et de les restaurer dans le nouveau PostgreSQL version. Ici, vous aurez une période d'indisponibilité qui variera en fonction de la taille de vos données. Vous devez arrêter le système ou éviter de nouvelles données dans le nœud principal, exécuter pg_dump, déplacer le vidage généré vers le nouveau nœud de base de données et le restaurer. Pendant ce temps, vous ne pouvez pas écrire dans votre base de données PostgreSQL principale pour éviter l'incohérence des données.
-
Pg_upgrade :il s'agit d'un outil PostgreSQL permettant de mettre à niveau votre version PostgreSQL sur place. Cela pourrait être dangereux dans un environnement de production et nous ne recommandons pas cette méthode dans ce cas. En utilisant cette méthode, vous aurez également des temps d'arrêt, mais ils seront probablement beaucoup moins longs qu'avec la méthode pg_dump précédente.
-
Réplication logique :Depuis PostgreSQL 10, vous pouvez utiliser cette méthode de réplication qui vous permet d'effectuer des mises à jour de version majeures avec zéro (ou presque zéro) temps d'arrêt. De cette manière, vous pouvez ajouter un nœud de secours dans la dernière version de PostgreSQL, et lorsque la réplication est à jour, vous pouvez effectuer un processus de basculement pour promouvoir le nouveau nœud PostgreSQL.
Pour des informations plus détaillées sur les nouvelles fonctionnalités de PostgreSQL 13, vous pouvez vous référer à la documentation officielle.



