Le IGNORE_DUP_KEY l'option pour les index uniques spécifie comment SQL Server répond à une tentative de INSERT valeurs en double :cela ne s'applique qu'aux tables (pas aux vues) et uniquement aux insertions. Toute partie d'insertion d'un MERGE l'instruction ignore tout IGNORE_DUP_KEY paramètre d'index.
Lorsque IGNORE_DUP_KEY est OFF , le premier doublon rencontré génère une erreur , et aucune des nouvelles lignes n'est insérée.
Lorsque IGNORE_DUP_KEY est ON , les lignes insérées qui violeraient l'unicité sont ignorées. Les lignes restantes sont insérées avec succès. Un avertissement message est émis à la place d'une erreur :
Résumé de l'article
Le IGNORE_DUP_KEY L'option d'index peut être spécifiée pour les index uniques clusterisés et non clusterisés. L'utiliser sur un index clusterisé peut entraîner des performances bien inférieures que pour un index unique non clusterisé.
L'ampleur de la différence de performances dépend du nombre de violations d'unicité rencontrées lors de l'INSERT opération. Plus il y a de violations, plus l'index unique clusterisé est performant en comparaison. S'il n'y a aucune violation, l'insertion d'index clusterisé peut même être plus performante.
Inserts d'index uniques en cluster
Pour un index unique clusterisé avec IGNORE_DUP_KEY défini, les doublons sont gérés par le moteur de stockage .
Une grande partie du travail impliqué dans l'insertion de chaque ligne est effectuée avant que le doublon ne soit détecté. Par exemple, un Insert d'index clusterisé l'opérateur navigue dans l'arborescence de l'index clusterisé jusqu'au point où la nouvelle ligne irait, en prenant les verrous de page et la hiérarchie habituelle des verrous, avant de découvrir la clé en double.
Lorsque la condition de clé en double est détectée, une erreur est relevé. Au lieu d'annuler l'exécution et de renvoyer l'erreur au client, l'erreur est gérée en interne. La ligne problématique n'est pas insérée et l'exécution se poursuit en recherchant la prochaine ligne à insérer. Si cette ligne rencontre une clé en double, une autre erreur est générée et gérée, et ainsi de suite.
Les exceptions sont très coûteuses à lancer et à attraper. Un nombre important de doublons ralentira considérablement l'exécution.
Inserts d'index uniques non clusterisés
Pour un index unique non clusterisé avec IGNORE_DUP_KEY défini, les doublons sont gérés par le processeur de requêtes . Les doublons sont détectés et un avertissement est émis avant chaque tentative d'insertion.
Le processeur de requêtes supprime les doublons du flux d'insertion, garantissant qu'aucun doublon n'est vu par le moteur de stockage. Par conséquent, aucune erreur de violation de clé unique n'est générée ou gérée en interne.
Le compromis
Il existe un compromis entre le coût de la détection et de la suppression des clés en double dans le plan d'exécution, par rapport au coût d'exécution d'un travail important lié à l'insertion, et le lancement et la détection d'erreurs lorsqu'un doublon est trouvé.
Si les doublons sont censés être très rares , la solution du moteur de stockage (clustered index) pourrait bien être plus efficace. Lorsque les doublons sont moins rares, l'approche du processeur de requêtes sera probablement payante. Le point de croisement exact dépendra de facteurs tels que l'efficacité d'exécution des composants du plan d'exécution utilisés pour détecter et supprimer les doublons.
Le reste de cet article fournit une démonstration et examine plus en détail pourquoi l'approche du moteur de stockage peut fonctionner si mal.
Démo
Le script suivant crée une table temporaire avec un million de lignes. Il contient 1 000 valeurs uniques et 1 000 lignes pour chaque valeur unique. Cet ensemble de données sera utilisé comme source de données pour les insertions dans des tables avec différentes configurations d'index.
DROP TABLE IF EXISTS #Data;GOCREATE TABLE #Data (c1 integer NOT NULL);GOSET NOCOUNT ON;SET STATISTICS XML OFF; DECLARE @Loop entier =1, @N entier =1 ; TANT QUE @N <=1000BEGIN SET @Loop =1 ; COMMENCER LA TRANSACTION ; -- Ajouter 1 000 copies de la valeur de boucle actuelle WHILE @Loop <=50 BEGIN INSERT #Data (c1) VALUES (@N), (@N), (@N), (@N), (@N), ( @N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), (@N), ( @N), (@N), (@N), (@N), (@N); SET @boucle +=1 ; FINIR; ENGAGER LA TRANSACTION ; SET @N +=1;FIN; CREATE CLUSTERED INDEX cx ON #Data (c1) WITH (MAXDOP =1);
Référence
L'insertion suivante dans une variable de table avec un index clusterisé non unique prend environ 900 ms :
DECLARE @T table ( c1 entier NOT NULL INDEX cuq CLUSTERED (c1)); INSERT @T (c1) SELECT D.c1 FROM #Data AS D ;
Notez l'absence de IGNORE_DUP_KEY sur la variable de table cible.
Index unique clusterisé
Insertion des mêmes données dans un cluster unique indexer avec IGNORE_DUP_KEY définir ON prend environ 15 900 ms — presque 18 fois pire :
DECLARE @T table ( c1 entier NOT NULL UNIQUE CLUSTERED WITH (IGNORE_DUP_KEY =ON)); INSERT @T (c1) SELECT D.c1 FROM #Data AS D ;
Index unique non clusterisé
Insertion des données dans un fichier non clusterisé unique indexer avec IGNORE_DUP_KEY définir ON prend environ 700 ms :
DECLARE @T table ( c1 integer NOT NULL UNIQUE NONCLUSTERED WITH (IGNORE_DUP_KEY =ON)); INSERT @T (c1) SELECT D.c1 FROM #Data AS D ;
Résumé des performances
Le test de référence prend 900 ms pour insérer la totalité d'un million de lignes. Le test d'index non cluster prend 700 ms pour insérer uniquement les 1 000 clés distinctes. Le test d'index clusterisé prend 15 900 ms pour insérer les mêmes 1 000 lignes uniques.
Ce test est délibérément mis en place pour mettre en évidence les mauvaises performances de l'implémentation du moteur de stockage, en générant 999 unités de travail perdu (loquets, verrous, gestion des erreurs) pour chaque ligne réussie.
Le message voulu n'est pas que IGNORE_DUP_KEY fonctionnera toujours mal sur les index clusterisés, juste que c'est possible, et il peut y avoir une grande différence entre les index clusterisés et non clusterisés.
Plan d'exécution d'index cluster
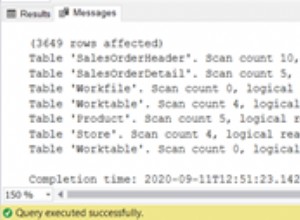
Il n'y a pas grand-chose à voir dans le plan d'insertion d'index cluster :
Il y a 1 000 000 de lignes transmises à l'insertion d'index cluster opérateur, qui est affiché comme "renvoyant" 1 000 lignes. En fouillant dans les détails du plan, nous pouvons voir :
- 1 244 008 lectures logiques au niveau de l'opérateur d'insertion.
- La majeure partie du temps d'exécution est consacrée à l'insertion opérateur.
- 11 ms de
SOS_SCHEDULER_YIELDattend (c'est-à-dire aucune autre attente).
Rien qui explique vraiment les 15 900 ms du temps écoulé.
Pourquoi les performances sont si médiocres
Il est évident que ce plan devra faire beaucoup de travail pour chaque ligne :
- Naviguez dans les niveaux de l'arborescence de l'index clusterisé, en les verrouillant et en les verrouillant au fur et à mesure, pour trouver le point d'insertion du nouvel enregistrement.
- Si l'une des pages d'index nécessaires n'est pas en mémoire, elle devra être extraite du disque.
- Construire une nouvelle ligne b-tree en mémoire.
- Préparer les enregistrements de journal.
- Si un doublon de clé est trouvé (qui n'est pas un enregistrement fantôme), génère une erreur, gère cette erreur en interne, libère la ligne actuelle et reprend à un point approprié du code pour traiter la ligne candidate suivante.
Tout cela représente une bonne quantité de travail, et rappelez-vous que tout se passe pour chaque ligne .
La partie sur laquelle je veux me concentrer est la génération et la gestion des erreurs, car c'est extrêmement chere. Les aspects restants notés ci-dessus ont déjà été rendus aussi bon marché que possible en utilisant une variable de table et une table temporaire dans la démo.
Exceptions
La première chose que je veux faire est de montrer que l'insertion d'index cluster l'opérateur déclenche réellement une exception lorsqu'il rencontre une clé en double.
Une façon de le montrer directement consiste à attacher un débogueur et à capturer une trace de pile au moment où l'exception est levée :
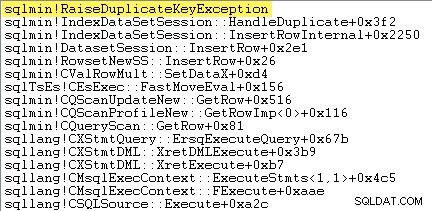
Le point important ici est que lancer et attraper des exceptions coûte très cher.
La surveillance de SQL Server à l'aide de l'enregistreur de performances Windows pendant l'exécution du test et l'analyse des résultats dans l'analyseur de performances Windows indiquent :
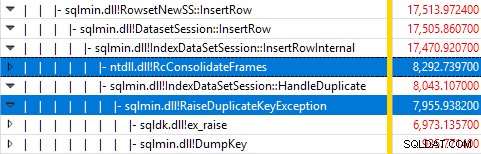
Presque tout le temps d'exécution de la requête est passé dans sqlmin!IndexDataSetSession::InsertRowInternal comme on pourrait s'y attendre pour une requête qui ne fait rien d'autre que d'insérer des lignes.
La surprise est que 45 % de ce temps est consacré à la génération d'exceptions via sqlmin!RaiseDuplicateKeyException et 47 % supplémentaires sont dépensés dans le bloc de capture d'exception associé (le ntdll!RcConsolidateFrames hiérarchie) .
Pour résumer :la génération et la capture d'exceptions représentent 92 % du temps d'exécution de notre requête test d'insertion d'index clusterisé.
Problèmes de collecte de données
Les lecteurs attentifs peuvent remarquer une quantité importante - environ 12 % - de temps de levée d'exception passé dans sqlmin!DumpKey dans le graphique de l'Analyseur de performances Windows. Cela vaut la peine d'être exploré rapidement, ainsi que quelques éléments connexes.
Dans le cadre de la génération d'une exception, SQL Server doit collecter certaines données qui ne sont disponibles qu'au moment où l'erreur s'est produite. Le numéro d'erreur associé à une exception de clé en double est 2627. Le texte du message dans sys.messages pour ce numéro d'erreur est :
Les informations pour remplir ces marqueurs de lieu doivent être collectées au moment où l'erreur est signalée - elles ne seront pas disponibles plus tard ! Cela signifie rechercher et formater le type de contrainte, son nom, le nom complet de l'objet cible et la valeur de clé spécifique. Tout cela prend du temps.
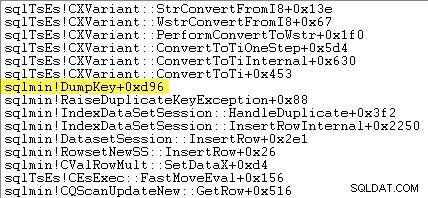
La trace de pile suivante montre que le serveur formate la valeur de clé en double en tant que chaîne Unicode pendant le DumpKey appeler :
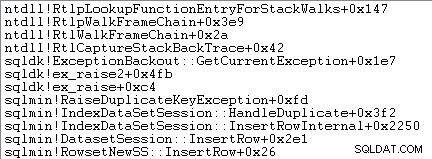
La gestion des exceptions implique également la capture d'une trace de pile :
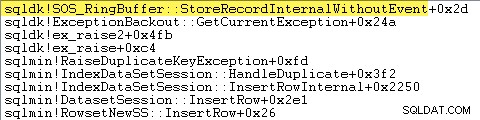
SQL Server enregistre également des informations sur les exceptions (y compris les cadres de pile) dans un petit tampon circulaire, comme le montre ce qui suit :
Vous pouvez voir ces entrées de tampon circulaire à l'aide d'une commande telle que :
SELECT TOP (10) date_time =DATEADD ( MILLISECOND, DORB.[timestamp] - DOSI.ms_ticks, SYSDATETIME() ), record =CONVERT(xml, DORB.record)FROM sys.dm_os_ring_buffers AS DORBCROSS JOIN sys.dm_os_sys_info AS DOSIWHERE DORB.ring_buffer_type =N'RING_BUFFER_EXCEPTION'ORDER BY DORB.[timestamp] DESC ;
Un exemple d'enregistrement xml pour une exception de clé en double suit. Notez les cadres de pile :
2627 14 <État>10 0 0X00007FFAC659E80A 0X00007FFACBAC0EFD 0X00007FFACBAA1252 0X00007FFACBA9E040 0X00007FFACAB55D53 0X00007FFACAB55C06 0X00007FFACB3E3D0B 0X00007FFAC92020EC 0X00007FFACAB5B2FA 0X00007FFACABA3B9B 0X00007FFACAB3D89F 0X00007FFAC6A9D108 0X00007FFAC6AB2BBF 0X00007FFAC6AB296F 0X00007FFAC6A9B7D0 0X00007FFAC6A9B233 Tout ce travail de fond se produit pour chaque exception. Dans notre test, cela signifie que cela se produit 999 000 fois, une fois pour chaque ligne qui rencontre une violation de clé en double.
Il existe de nombreuses façons de voir cela, par exemple en exécutant une trace du profileur à l'aide de l'exception événement dans les erreurs et avertissements classe. Dans notre cas de test, cela finira éventuellement produire 999 000 lignes avec TextData des éléments comme ceci :
Violation de la contrainte UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'
Impossible d'insérer la clé en double dans l'objet 'dbo.@T'.
La valeur de la clé en double est (173).Attacher Profiler signifie que chaque événement de gestion des exceptions acquiert une charge supplémentaire importante, car les données supplémentaires nécessaires sont collectées et formatées. Les données par défaut mentionnées précédemment sont toujours collectées, même si personne ne consomme activement les informations.
Pour être clair :les chiffres de performance rapportés dans cet article ont tous été obtenus sans débogueur attaché et sans autre surveillance active.
Plan d'exécution d'index non clusterisé
Bien qu'il soit beaucoup plus rapide, le plan d'insertion d'index non clusterisé est un peu plus complexe, je vais donc le diviser en deux parties.
Le thème général est que ce plan est plus rapide car il élimine les doublons avant essayant de les insérer dans la table cible.
Partie 1
Tout d'abord, le côté droit du plan d'index non cluster :
Cette partie du plan rejette toutes les lignes qui ont une correspondance clé dans la table cible pour l'index unique avec
IGNORE_DUP_KEYdéfinirON.Vous vous attendez peut-être à voir un Anti Semi Join ici, mais SQL Server ne dispose pas de l'infrastructure nécessaire pour émettre l'avertissement de clé en double requis avec un Anti Semi Join opérateur. (Si cela n'a pas déjà de sens, cela devrait le faire sous peu.)
Au lieu de cela, nous obtenons un plan avec un certain nombre de fonctionnalités intéressantes :
- Le balayage d'index groupé est
Ordered:Truepour fournir une entrée à la Merge Left Semi Join trié par colonnec1dans le#Datatableau. - Le balayage de l'index de la variable de table est
Ordered:False - Le tri ordonne les lignes par colonne
c1dans la variable de tableau. Cette commande aurait pu être fournie par un commandé parcours de l'index des variables de la table surc1, mais l'optimiseur décide du tri est le moyen le moins cher de fournir le niveau de protection d'Halloween requis. - La variable de tableau Index Scan a un
UPDLOCKinterne etSERIALIZABLEconseils appliqués pour assurer la stabilité de la cible pendant l'exécution du plan. - La Merge Left Semi Join vérifie les correspondances dans la variable de table pour chaque valeur de
c1renvoyé par le#Datatable. Contrairement à une semi jointure classique, elle émet chaque ligne reçue sur son entrée supérieure. Il définit un indicateur dans une colonne de sonde pour indiquer si la ligne actuelle a trouvé une correspondance ou non. La colonne de sonde est émise depuis la Merge Left Semi Join sous la forme d'une expression nomméeExpr1012. - L'affirmation l'opérateur vérifie la valeur de la colonne sonde
Expr1012. La première fois qu'il voit une ligne avec une valeur de colonne de sonde non nulle (indiquant qu'une correspondance de clé d'index a été trouvée), il émet un "La clé en double a été ignorée" message. - L'affirmation ne transmet que les lignes où la colonne de sonde est nulle. Cela élimine les lignes entrantes qui produiraient une erreur de clé en double.
Tout cela peut sembler complexe, mais c'est essentiellement aussi simple que de définir un indicateur si une correspondance est trouvée, d'émettre un avertissement la première fois que l'indicateur est défini et de ne transmettre que les lignes vers l'insert qui n'existent pas déjà dans la table cible .
Partie 2
La deuxième partie du plan suit l'Assert opérateur :
La partie précédente du plan supprimait les lignes qui avaient une correspondance dans la table cible. Cette partie du plan supprime les doublons dans le jeu d'insertion .
Par exemple, imaginez qu'il n'y a pas de lignes dans la table cible où c1 = 1 . Nous pouvons toujours provoquer une erreur de clé en double si nous essayons d'insérer deux lignes avec c1 = 1 à partir de la table source. Nous devons éviter cela pour respecter la sémantique de IGNORE_DUP_KEY = ON .
Cet aspect est géré par le Segment et Haut opérateurs.
Le segment l'opérateur définit un nouveau drapeau (étiqueté Segment1015 ) lorsqu'il rencontre une ligne avec une nouvelle valeur pour c1 . Puisque les lignes sont présentées dans c1 ordre (grâce au Merge qui préserve l'ordre ), le plan peut s'appuyer sur toutes les lignes avec le même c1 valeur arrivant dans un flux contigu.
Le Haut l'opérateur transmet une ligne pour chaque groupe de doublons, comme indiqué par le Segment drapeau. Si le Haut l'opérateur rencontre plusieurs lignes pour le même Segment groupe (c1 value), il émet un « La clé en double a été ignorée » avertissement, si c'est la première fois que le plan rencontre cette condition.
L'effet net de tout cela est qu'une seule ligne est transmise aux opérateurs d'insertion pour chaque valeur unique de c1 , et un avertissement est généré si nécessaire.
Le plan d'exécution a maintenant éliminé toutes les violations potentielles de clé en double, donc l'insertion de table restante et Insertion d'index les opérateurs peuvent insérer en toute sécurité des lignes dans le tas et l'index non clusterisé sans craindre une erreur de clé en double.
Rappelez-vous que le UPDLOCK et SERIALIZABLE les conseils appliqués à la table cible garantissent que l'ensemble ne peut pas changer pendant l'exécution. En d'autres termes, une instruction simultanée ne peut pas modifier la table cible de sorte qu'une erreur de clé en double se produise au niveau de Insert les opérateurs. Ce n'est pas un problème ici puisque nous utilisons une variable de table privée, mais SQL Server ajoute toujours les conseils par mesure de sécurité générale.
Sans ces indications, un processus simultané pourrait ajouter une ligne à la table cible qui générerait une violation de clé en double, malgré les vérifications effectuées par la partie 1 du plan. SQL Server doit s'assurer que les résultats de la vérification d'existence restent valides.
Le lecteur curieux peut voir certaines des fonctionnalités décrites ci-dessus en activant les indicateurs de trace 3604 et 8607 pour voir l'arborescence de sortie de l'optimiseur :
PhyOp_RestrRemap PhyOp_StreamUpdate(INS TBL :@T, iid 0x2 as IDX, Sort(QCOL :.c1, )), { - COL :Bmk10001013 =COL :Bmk1000 - COL :c11014 =QCOL :.c1} PhyOp_StreamUpdate(INS TBL :@T, iid 0x0 as TBLInsLocator(COL :Bmk1000 ) REPORT-COUNT), { - QCOL :.c1=QCOL :[D].c1} PhyOp_GbTop Group(QCOL :[D].c1,) WARN-DUP PhyOp_StreamCheck ( WarnIgnoreDuplicate TABLE) PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL :Expr1012 ( QCOL :[D].c1) =( QCOL :.c1) PhyOp_Range TBL :#Data(alias TBL :D)(1) ASC PhyOp_Sort +s -d QCOL :. c1 PhyOp_Range TBL :@T(2) Conseils ASC (UPDLOCK SERIALIZABLE FORCEDINDEX) ScaOp_Comp x_cmpIs ScaOp_Identifier QCOL :[D].c1 ScaOp_Identifier QCOL :.c1 ScaOp_Logical x_lopIsNotNull ScaOp_Identifier COL :E xpr1012 Réflexions finales
Le IGNORE_DUP_KEY L'option index n'est pas quelque chose que la plupart des gens utiliseront très souvent. Néanmoins, il est intéressant de voir comment cette fonctionnalité est implémentée et pourquoi il peut y avoir de grandes différences de performances entre IGNORE_DUP_KEY sur les index clusterisés et non clusterisés.
Dans de nombreux cas, il sera payant de suivre l'exemple du processeur de requêtes et de chercher à écrire des requêtes qui éliminent explicitement les doublons, plutôt que de s'appuyer sur IGNORE_DUP_KEY . Dans notre exemple, cela reviendrait à écrire :
DECLARE @T table (c1 entier NOT NULL UNIQUE CLUSTERED -- no IGNORE_DUP_KEY !); INSERT @T (c1) SELECT DISTINCT -- Supprimer les doublons D.c1 FROM #Data AS D;
Cela s'exécute en environ 400 ms , juste pour info.