"Mais il a bien fonctionné sur notre serveur de développement !"
Combien de fois l'ai-je entendu lorsque des problèmes de performances de requête SQL se sont produits ici et là ? Je l'ai dit moi-même à l'époque. J'ai supposé qu'une requête exécutée en moins d'une seconde fonctionnerait correctement sur les serveurs de production. Mais j'avais tort.
Pouvez-vous vous rapporter à cette expérience ? Si vous êtes toujours dans ce bateau aujourd'hui pour une raison quelconque, ce poste est pour vous. Cela vous donnera une meilleure métrique pour affiner les performances de vos requêtes SQL. Nous parlerons de trois des chiffres les plus critiques dans STATISTICS IO.
À titre d'exemple, nous utiliserons l'exemple de base de données AdventureWorks.
Avant de commencer à exécuter les requêtes ci-dessous, activez STATISTICS IO. Voici comment procéder dans une fenêtre de requête :
USE AdventureWorks
GO
SET STATISTICS IO ONUne fois que vous exécutez une requête avec STATISTICS IO ON, différents messages apparaîtront. Vous pouvez les voir dans l'onglet Messages de la fenêtre de requête dans SQL Server Management Studio (voir Figure 1) :
Maintenant que nous en avons terminé avec la courte introduction, approfondissons.
1. Lectures logiques élevées
Le premier point de notre liste est le coupable le plus courant - les lectures logiques élevées.
Les lectures logiques correspondent au nombre de pages lues à partir du cache de données. Une page a une taille de 8 Ko. Le cache de données, quant à lui, fait référence à la RAM utilisée par SQL Server.
Les lectures logiques sont cruciales pour le réglage des performances. Ce facteur définit la quantité dont un serveur SQL a besoin pour produire l'ensemble de résultats requis. Par conséquent, la seule chose à retenir est la suivante :plus les lectures logiques sont élevées, plus le serveur SQL doit fonctionner longtemps. Cela signifie que votre requête sera plus lente. Réduisez le nombre de lectures logiques et vous augmenterez les performances de vos requêtes.
Mais pourquoi utiliser des lectures logiques au lieu du temps écoulé ?
- Le temps écoulé dépend d'autres actions effectuées par le serveur, et pas seulement de votre requête.
- Le temps écoulé peut varier d'un serveur de développement à un serveur de production. Cela se produit lorsque les deux serveurs ont des capacités et des configurations matérielles et logicielles différentes.
Si vous vous fiez au temps écoulé, vous direz :"Mais tout s'est bien passé sur notre serveur de développement !" tôt ou tard.
Pourquoi utiliser des lectures logiques au lieu de lectures physiques ?
- Les lectures physiques correspondent au nombre de pages lues à partir des disques vers le cache de données (en mémoire). Une fois que les pages nécessaires à une requête sont dans le cache de données, il n'est pas nécessaire de les relire à partir des disques.
- Lorsque la même requête est réexécutée, les lectures physiques seront nulles.
Les lectures logiques sont le choix logique pour affiner les performances des requêtes SQL.
Pour voir cela en action, passons à un exemple.
Exemple de lectures logiques
Supposons que vous ayez besoin d'obtenir la liste des clients dont les commandes ont été expédiées le 11 juillet 2011. Vous obtenez cette requête assez simple :
SELECT
d.FirstName
,d.MiddleName
,d.LastName
,d.Suffix
,a.OrderDate
,a.ShipDate
,a.Status
,b.ProductID
,b.OrderQty
,b.UnitPrice
FROM Sales.SalesOrderHeader a
INNER JOIN Sales.SalesOrderDetail b ON a.SalesOrderID = b.SalesOrderID
INNER JOIN Sales.Customer c ON a.CustomerID = c.CustomerID
INNER JOIN Person.Person d ON c.PersonID = D.BusinessEntityID
WHERE a.ShipDate = '07/11/2011'C'est simple. Cette requête aura le résultat suivant :

Ensuite, vous vérifiez le résultat STATISTICS IO de cette requête :

La sortie affiche les lectures logiques de chacune des quatre tables utilisées dans la requête. Au total, la somme des lectures logiques est de 729. Vous pouvez également voir des lectures physiques avec une somme totale de 21. Cependant, essayez de relancer la requête et elle sera nulle.
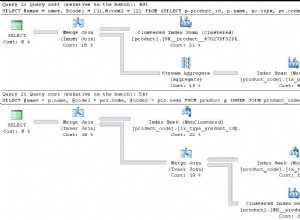
Examinez de plus près les lectures logiques de SalesOrderHeader . Vous vous demandez pourquoi il a 689 lectures logiques ? Peut-être avez-vous pensé à inspecter le plan d'exécution de la requête ci-dessous :
D'une part, il y a une analyse d'index qui s'est produite dans SalesOrderHeader avec un coût de 93 %. Que pourrait-il se passer ? Supposons que vous avez vérifié ses propriétés :
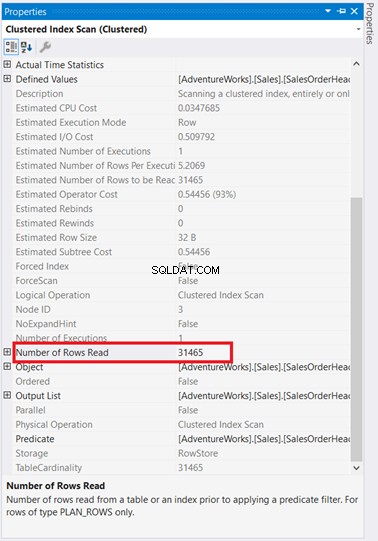
Waouh ! 31 465 lignes lues pour seulement 5 lignes renvoyées ? C'est absurde !
Réduction du nombre de lectures logiques
Il n'est pas si difficile de réduire ces 31 465 lignes lues. SQL Server nous a déjà donné un indice. Procédez comme suit :
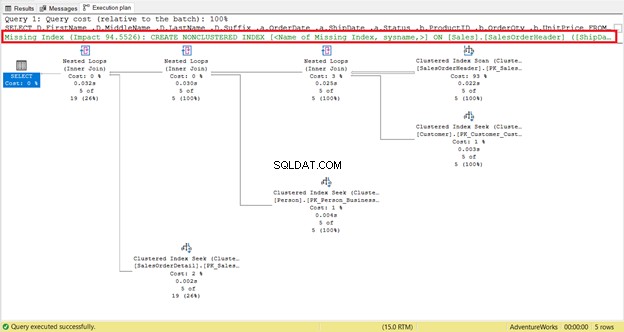
ÉTAPE 1 :Suivez les recommandations de SQL Server et ajoutez l'index manquant
Avez-vous remarqué la recommandation d'index manquante dans le plan d'exécution (Figure 4) ? Cela résoudra-t-il le problème ?
Il existe un moyen de le savoir :
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_ShipDate]
ON [Sales].[SalesOrderHeader] ([ShipDate])Réexécutez la requête et voyez les changements dans les lectures logiques STATISTICS IO.

Comme vous pouvez le voir dans STATISTICS IO (Figure 6), il y a une énorme diminution des lectures logiques de 689 à 17. Les nouvelles lectures logiques globales sont de 57, ce qui représente une amélioration significative par rapport aux 729 lectures logiques. Mais pour être sûr, inspectons à nouveau le plan d'exécution.
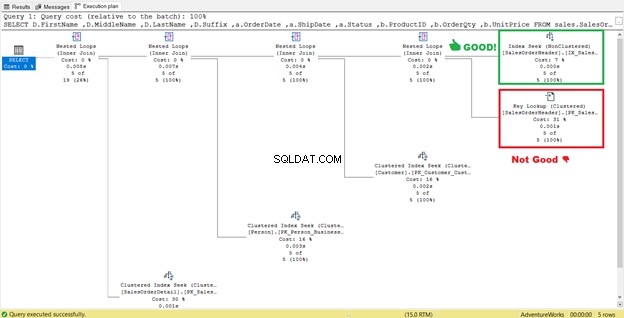
Il semble qu'il y ait une amélioration du plan entraînant une réduction des lectures logiques. Le balayage d'index est maintenant une recherche d'index. SQL Server n'aura plus besoin d'inspecter ligne par ligne pour obtenir les enregistrements avec le Shipdate='07/11/2011′ . Mais quelque chose se cache toujours dans ce plan, et ce n'est pas correct.
Vous avez besoin de l'étape 2.
ÉTAPE 2 :Modifier l'index et ajouter aux colonnes incluses :OrderDate, Status et CustomerID
Voyez-vous cet opérateur Key Lookup dans le plan d'exécution (Figure 7) ? Cela signifie que l'index non clusterisé créé n'est pas suffisant - le processeur de requêtes doit à nouveau utiliser l'index clusterisé.
Vérifions ses propriétés.
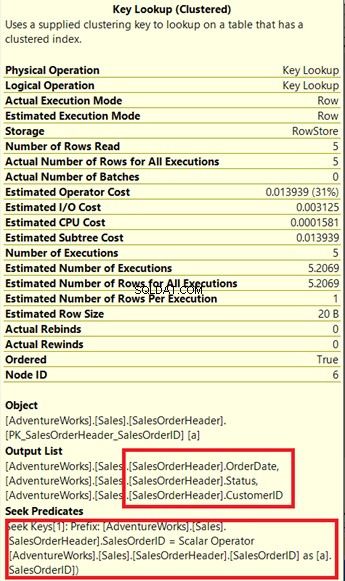
Notez la case ci-jointe sous la liste de sortie . Il arrive que nous ayons besoin de OrderDate , Statut , et ID client dans le jeu de résultats. Pour obtenir ces valeurs, le processeur de requêtes a utilisé l'index clusterisé (voir la section Seek Predicates ) pour accéder à la table.
Nous devons supprimer cette recherche de clé. La solution consiste à inclure le OrderDate , Statut , et ID client colonnes dans l'index créé précédemment.
- Cliquez avec le bouton droit sur IX_SalesOrderHeader_ShipDate dans SSMS.
- Sélectionnez Propriétés .
- Cliquez sur les Colonnes incluses onglet.
- Ajouter Date de commande , Statut , et ID client .
- Cliquez sur OK .
Après avoir recréé l'index, réexécutez la requête. Cela supprimera-t-il Key Lookup et réduire les lectures logiques ?

Ça a marché! De 17 lectures logiques à 2 (Figure 9).
Et la recherche de clé ?
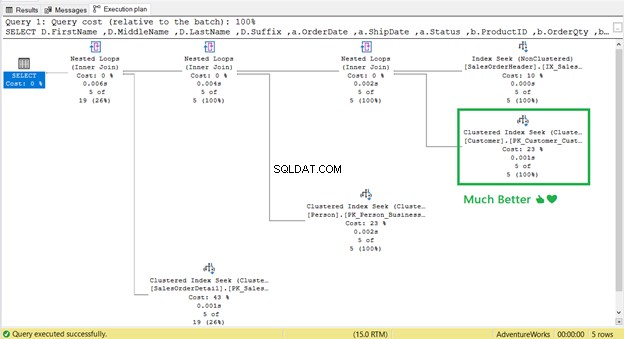
C'est parti! Recherche d'index cluster a remplacé Key Lookup.
Les plats à emporter
Alors, qu'avons-nous appris ?
L'un des principaux moyens de réduire les lectures logiques et d'améliorer les performances des requêtes SQL consiste à créer un index approprié. Mais il y a un hic. Dans notre exemple, cela a réduit les lectures logiques. Parfois, le contraire sera vrai. Cela peut également affecter les performances d'autres requêtes connexes.
Par conséquent, vérifiez toujours les E/S STATISTIQUES et le plan d'exécution après avoir créé l'index.
2. Lectures logiques High Lob
C'est à peu près la même chose que le point 1, mais il traitera des types de données texte , texte , image , varchar (max ), nvarchar (max ), varbinaire (max ), ou columnstore pages d'index.
Prenons un exemple :générer des lectures logiques lob.
Exemple de lectures logiques Lob
Supposons que vous souhaitiez afficher un produit avec son prix, sa couleur, sa vignette et une image plus grande sur une page Web. Ainsi, vous obtenez une requête initiale comme celle ci-dessous :
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,b.Name AS ProductSubcategory
,d.ThumbNailPhoto
,d.LargePhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
ORDER BY ProductSubcategory, ProductName, a.ColorEnsuite, vous l'exécutez et voyez le résultat comme celui ci-dessous :

Comme vous êtes un gars (ou une fille) très performant, vous vérifiez immédiatement les STATISTICS IO. Le voici :

C'est comme de la saleté dans les yeux. 665 lectures logiques lob ? Vous ne pouvez pas accepter cela. Sans oublier 194 lectures logiques chacune de ProductPhoto et ProductProductPhoto les tables. Vous pensez en effet que cette requête a besoin de quelques modifications.
Réduction des lectures logiques Lob
La requête précédente renvoyait 97 lignes. Tous les 97 vélos. Pensez-vous que c'est bon à afficher sur une page Web ?
Un index peut aider, mais pourquoi ne pas d'abord simplifier la requête ? De cette façon, vous pouvez être sélectif sur ce que SQL Server renverra. Vous pouvez réduire les lectures logiques lob.
- Ajoutez un filtre pour la sous-catégorie de produit et laissez le client choisir. Ensuite, incluez ceci dans la clause WHERE.
- Supprimez la ProductSubcategory colonne puisque vous ajouterez un filtre pour la sous-catégorie de produit.
- Supprimez la GrandePhoto colonne. Interrogez-le lorsque l'utilisateur sélectionne un produit spécifique.
- Utilisez la pagination. Le client ne pourra pas voir les 97 vélos à la fois.
Sur la base des opérations décrites ci-dessus, nous modifions la requête comme suit :
- Supprimer ProductSubcategory et GrandePhoto colonnes du jeu de résultats.
- Utilisez OFFSET et FETCH pour prendre en charge la pagination dans la requête. Interrogez seulement 10 produits à la fois.
- Ajouter ProductSubcategoryID dans la clause WHERE en fonction de la sélection du client.
- Supprimez la ProductSubcategory colonne dans la clause ORDER BY.
La requête ressemblera désormais à ceci :
DECLARE @pageNumber TINYINT
DECLARE @noOfRows TINYINT = 10 -- each page will display 10 products at a time
SELECT
a.ProductID
,a.Name AS ProductName
,a.ListPrice
,a.Color
,d.ThumbNailPhoto
FROM Production.Product a
INNER JOIN Production.ProductSubcategory b ON a.ProductSubcategoryID = b.ProductSubcategoryID
INNER JOIN Production.ProductProductPhoto c ON a.ProductID = c.ProductID
INNER JOIN Production.ProductPhoto d ON c.ProductPhotoID = d.ProductPhotoID
WHERE b.ProductCategoryID = 1 -- Bikes
AND a.ProductSubcategoryID = 2 -- Road Bikes
ORDER BY ProductName, a.Color
OFFSET (@pageNumber-1)*@noOfRows ROWS FETCH NEXT @noOfRows ROWS ONLY
-- change the OFFSET and FETCH values based on what page the user is.Avec les modifications apportées, les lectures logiques lob s'amélioreront-elles ? STATISTICS IO signale désormais :

Photo du produit la table a maintenant 0 lectures logiques lob - de 665 lectures logiques lob à aucune. C'est une amélioration.
À emporter
L'un des moyens de réduire les lectures logiques lob consiste à réécrire la requête pour la simplifier.
Supprimez les colonnes inutiles et réduisez les lignes renvoyées au minimum requis. Si nécessaire, utilisez OFFSET et FETCH pour la pagination.
Pour vous assurer que les modifications de la requête ont amélioré les lectures logiques lob et les performances des requêtes SQL, vérifiez toujours STATISTICS IO.
3. Lectures logiques élevées de table de travail/fichier de travail
Enfin, il est logique de lire Worktable et Fichier de travail . Mais quels sont ces tableaux ? Pourquoi apparaissent-ils alors que vous ne les utilisez pas dans votre requête ?
Avoir table de travail et Fichier de travail apparaissant dans STATISTICS IO signifie que SQL Server a besoin de beaucoup plus de travail pour obtenir les résultats souhaités. Il recourt à l'utilisation de tables temporaires dans tempdb , à savoir Tables de travail et Fichiers de travail . Il n'est pas nécessairement dangereux de les avoir dans la sortie STATISTICS IO, tant que les lectures logiques sont nulles et que cela ne cause pas de problèmes au serveur.
Ces tableaux peuvent apparaître lorsqu'il y a ORDER BY, GROUP BY, CROSS JOIN ou DISTINCT, entre autres.
Exemple de lectures logiques de table de travail/fichier de travail
Supposons que vous deviez interroger tous les magasins sans vente de certains produits.
Vous proposez initialement ce qui suit :
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
,ISNULL(c.OrderTotal,0) AS OrderTotal
FROM Sales.Store a
CROSS JOIN Production.Product b
LEFT JOIN (SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID, b.OrderDate) c ON a.SalesPersonID
= c.SalesPersonID
AND b.ProductID = c.ProductID
WHERE c.OrderTotal IS NULL
ORDER BY a.SalesPersonID, b.ProductIDCette requête a renvoyé 3 649 lignes :
Vérifions ce que dit l'E/S STATISTIQUES :

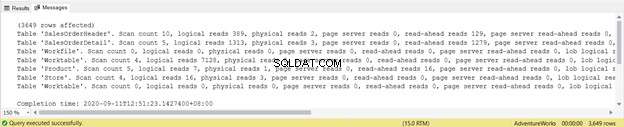
Il convient de noter que la table de travail les lectures logiques sont de 7128. Les lectures logiques globales sont de 8853. Si vous vérifiez le plan d'exécution, vous verrez de nombreux parallélismes, correspondances de hachage, spools et analyses d'index.
Réduction des lectures logiques de table de travail/fichier de travail
Je ne pouvais pas construire une seule instruction SELECT avec un résultat satisfaisant. Ainsi, le seul choix est de décomposer l'instruction SELECT en plusieurs requêtes. Voir ci-dessous :
SELECT DISTINCT
a.SalesPersonID
,b.ProductID
INTO #tmpStoreProducts
FROM Sales.Store a
CROSS JOIN Production.Product b
SELECT
b.SalesPersonID
,a.ProductID
,SUM(a.LineTotal) AS OrderTotal
INTO #tmpProductOrdersPerSalesPerson
FROM Sales.SalesOrderDetail a
INNER JOIN Sales.SalesOrderHeader b ON a.SalesOrderID = b.SalesOrderID
WHERE b.SalesPersonID IS NOT NULL
GROUP BY b.SalesPersonID, a.ProductID
SELECT
a.SalesPersonID
,a.ProductID
FROM #tmpStoreProducts a
LEFT JOIN #tmpProductOrdersPerSalesPerson b ON a.SalesPersonID = b.SalesPersonID AND
a.ProductID = b.ProductID
WHERE b.OrderTotal IS NULL
ORDER BY a.SalesPersonID, a.ProductID
DROP TABLE #tmpProductOrdersPerSalesPerson
DROP TABLE #tmpStoreProductsIl fait plusieurs lignes de plus et utilise des tables temporaires. Voyons maintenant ce que révèle l'OI STATISTIQUES :
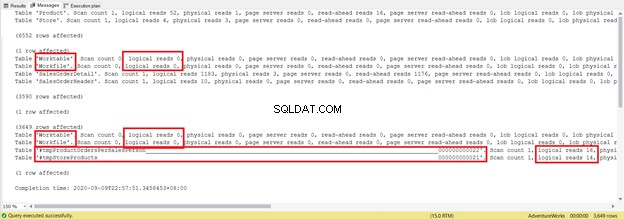
Essayez de ne pas vous concentrer sur la longueur de ce rapport statistique - c'est seulement frustrant. Au lieu de cela, ajoutez des lectures logiques à partir de chaque table.
Pour un total de 1279, il s'agit d'une diminution significative, car il s'agissait de 8853 lectures logiques à partir de la seule instruction SELECT.
Nous n'avons ajouté aucun index aux tables temporaires. Vous pourriez en avoir besoin si beaucoup plus d'enregistrements sont ajoutés à SalesOrderHeader et SalesOrderDetail . Mais vous avez compris.
À emporter
Parfois, 1 instruction SELECT semble bonne. Cependant, dans les coulisses, c'est le contraire qui est vrai. Tables de travail et Fichiers de travail avec des lectures logiques élevées retardent les performances de vos requêtes SQL.
Si vous ne pouvez pas penser à une autre façon de reconstruire la requête et que les index sont inutiles, essayez l'approche "diviser pour mieux régner". Les tables de travail et Fichiers de travail peut toujours apparaître dans l'onglet Message de SSMS, mais les lectures logiques seront nulles. Par conséquent, le résultat global sera moins de lectures logiques.
L'essentiel des performances des requêtes SQL et des E/S STATISTIQUES
Quel est le problème avec ces 3 statistiques d'E/S désagréables ?
La différence dans les performances des requêtes SQL sera comme la nuit et le jour si vous faites attention à ces chiffres et que vous les réduisez. Nous avons seulement présenté quelques façons de réduire les lectures logiques comme :
- créer des index appropriés ;
- simplification des requêtes :suppression des colonnes inutiles et réduction de l'ensemble de résultats ;
- diviser une requête en plusieurs requêtes.
Il y a plus comme la mise à jour des statistiques, la défragmentation des index et la définition du bon FILLFACTOR. Pouvez-vous ajouter plus à cela dans la section des commentaires ?
Si vous aimez cet article, partagez-le sur vos réseaux sociaux préférés.