Il y a quelques semaines, j'ai commencé à configurer un environnement de démonstration avec plusieurs configurations de groupes de disponibilité AlwaysOn. J'avais un cluster WSFC à 5 nœuds - chaque nœud avait une instance nommée autonome de SQL Server 2012, et il y avait également deux instances de cluster de basculement (FCI) qui étaient configurées au-dessus de ces nœuds. Un schéma rapide :
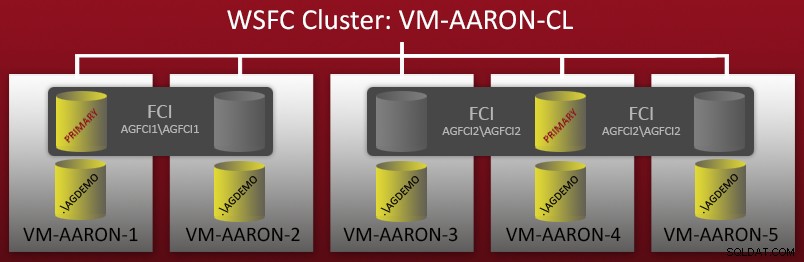
Vous pouvez donc voir qu'il y a 5 instances nommées autonomes (.\AGDEMO sur chaque nœud), puis deux FCI - une avec les propriétaires possibles VM-AARON-1 et VM-AARON-2 (AGFCI1\AGFCI1 ), puis une avec les propriétaires possibles VM-AARON-3, VM-AARON-4 et VM-AARON-5 (AGFCI2\AGFCI2 ). Maintenant, schématiser manuellement cela devrait devenir beaucoup plus complexe (plus à ce sujet plus tard), donc je vais l'éviter pour des raisons évidentes. L'exigence était essentiellement d'avoir plusieurs types de configurations AG :
- Primaire sur une FCI avec un réplica sur une ou plusieurs instances autonomes
- Primaire sur une FCI avec une réplique sur une autre FCI
- Primaire sur une instance autonome avec un réplica sur une ou plusieurs FCI
- Primaire sur une instance autonome avec un réplica sur une ou plusieurs instances autonomes
- Primaire sur une instance autonome avec des répliques sur les instances autonomes et les FCI
Et puis des combinaisons (si possible) de validation synchrone ou asynchrone, de basculement manuel ou automatique et de secondaires en lecture seule. Certaines limitations techniques limiteraient les permutations possibles ici, par exemple :
- Le basculement manuel est nécessaire avec toute réplique qui se trouve sur une FCI
- Aucun nœud WSFC ne peut héberger (ou même être éventuellement propriétaire) plusieurs instances, qu'elles soient autonomes ou en cluster, qui sont impliquées dans le même groupe de disponibilité. Vous obtenez ce message d'erreur :Échec de la création, de la jointure ou de l'ajout d'un réplica au groupe de disponibilité « MyGroup », car le nœud « VM-AARON-1 » est un propriétaire possible pour le réplica « AGFCI1\AGFCI1 » et « VM-AARON-1\ AGDEMO'. Si un réplica est une instance de cluster de basculement, supprimez le nœud superposé de ses propriétaires possibles et réessayez. (Microsoft SQL Server, erreur :19405)
La plupart des scénarios que j'essayais de représenter ne sont pas pratiques dans des scénarios réels, mais ils sont largement et théoriquement possibles . Si vous ne l'avez pas encore deviné, cet environnement est configuré explicitement pour tester de nouvelles fonctionnalités autour des groupes de disponibilité que nous prévoyons d'offrir dans une future version de SQL Sentry. Nous avons donné un aperçu de certaines de ces technologies lors de notre keynote avec Fusion-io lors de la récente conférence SQL Intersection à Las Vegas.
Obstacle n° 1
La configuration des groupes de disponibilité à l'aide de l'assistant dans SSMS est assez simple. À moins, par exemple, que vous ayez des chemins de fichiers hétérogènes. L'assistant dispose d'une validation qui garantit que les mêmes chemins de données et de journaux existent sur toutes les répliques. Cela peut être pénible si vous utilisez le chemin de données par défaut pour deux instances nommées différentes, ou si vous avez des configurations de lettre de lecteur différentes (ce qui se produit souvent lorsque des FCI sont impliquées).
La vérification de la compatibilité de l'emplacement du fichier de base de données sur le réplica secondaire a généré une erreur. (Microsoft.SqlServer.Management.HadrTasks)Les emplacements de dossier suivants n'existent pas sur l'instance de serveur qui héberge le réplica secondaire VM-AARON-1\AGDEMO :
P:\MSSQL11.AGFCI2\MSSQL\DATA ;
(Microsoft.SqlServer.Management.HadrTasks)
Maintenant, il va sans dire que vous ne voulez pas mettre en place ce scénario dans n'importe quel type d'environnement qui doit résister à l'épreuve du temps. Les choses iront très vite si, par exemple, vous ajoutez plus tard un nouveau fichier à l'une des bases de données. Mais pour un environnement de test/démo, une preuve de concept ou un environnement dont vous pensez qu'il sera stable pendant un temps considérable, ne vous inquiétez pas :vous pouvez toujours le faire sans l'assistant.
Malheureusement, pour ajouter l'insulte à l'injure, l'assistant ne vous laisse pas le scripter. Vous ne pouvez pas dépasser l'erreur de validation et il n'y a pas de Script bouton :
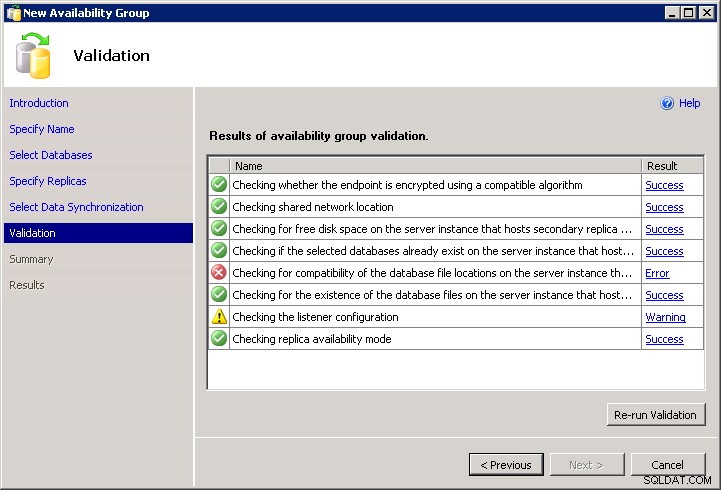
Cela signifie donc que vous devez le coder vous-même (puisque le DDL n'effectue aucune validation "utile" pour vous). Si vous avez d'autres instances où les mêmes chemins existent, vous pouvez le faire en suivant le même assistant, en dépassant l'écran de validation, puis en cliquant sur Script au lieu de Finish , et changez le(s) nom(s) de serveur et ajoutez avec WITH MOVE options à la restauration initiale. Ou vous pouvez simplement écrire le vôtre à partir de zéro, quelque chose comme ceci (le script suppose que vous avez déjà configuré les points de terminaison et les autorisations, et que toutes les instances ont la fonctionnalité Groupes de disponibilité activée) :
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Obstacle #2
Si vous avez plusieurs instances sur le même serveur, vous constaterez peut-être que les deux instances ne peuvent pas partager le port 5022 pour leur point de terminaison de mise en miroir de base de données (qui est le même point de terminaison utilisé par les groupes de disponibilité). Cela signifie que vous devrez supprimer et recréer le point de terminaison pour le définir sur un port disponible à la place.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Maintenant, je pourrais spécifier une instance avec un point de terminaison sur ServerName:5023 .
Obstacle n° 3
Cependant, une fois que j'ai fait cela, lorsque j'arrivais à la dernière étape du script ci-dessus, après exactement 48 secondes - à chaque fois - j'obtenais ce message d'erreur inutile :
Msg 35250, Niveau 16, État 7, Ligne 2La connexion au réplica principal n'est pas active. La commande n'a pu être exécutée.
Cela m'a amené à rechercher toutes sortes de problèmes potentiels - vérifier les pare-feu et SQL Server Configuration Manager, par exemple, pour tout ce qui bloquerait les ports entre les instances. Non. J'ai trouvé diverses erreurs dans le journal des erreurs de SQL Server :
La tentative de connexion à la mise en miroir de la base de données a échoué avec l'erreur :"Échec de l'établissement de la liaison de connexion. Il n'y a pas d'algorithme de chiffrement compatible. État 22.'.La tentative de connexion à la mise en miroir de la base de données a échoué avec l'erreur :"Échec de l'établissement de la liaison de connexion. Un appel au système d'exploitation a échoué :(80090303) 0x80090303 (la cible spécifiée est inconnue ou inaccessible). État 66.'.
Un délai d'expiration de connexion s'est produit lors de la tentative d'établissement d'une connexion au réplica de disponibilité 'VM-AARON-1\AGDEMO' avec l'ID [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Soit un problème de réseau ou de pare-feu existe, soit l'adresse de point de terminaison fournie pour le réplica n'est pas le point de terminaison de mise en miroir de la base de données de l'instance du serveur hôte.
Il s'avère (et grâce à Thomas Stringer (@SQLife)) que ce problème était causé par une combinaison de symptômes :(a) Kerberos n'était pas configuré correctement et (b) l'algorithme de chiffrement pour le hadr_endpoint que j'avais créé était par défaut. à RC4. Ce serait bien si toutes les instances autonomes utilisaient également RC4, mais ce n'était pas le cas. Pour faire court, j'ai supprimé et recréé les points de terminaison à nouveau , sur toutes les instances. Comme il s'agissait d'un environnement de laboratoire et que je n'avais pas vraiment besoin de l'assistance de Kerberos (et parce que j'avais déjà investi suffisamment de temps dans ces problèmes pour ne pas vouloir rechercher les problèmes de Kerberos également), j'ai configuré tous les points de terminaison pour utiliser Négocier avec AES :
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) a récemment écrit sur un blog à propos d'un problème similaire.)
Maintenant, enfin, j'ai pu créer des groupes de disponibilité avec toutes les différentes exigences que j'avais, entre des nœuds avec des chemins de fichiers hétérogènes et en utilisant plusieurs instances sur le même nœud (mais pas dans le même groupe). Voici un aperçu de ce à quoi ressemblera l'une de nos vues de gestion AlwaysOn (cliquez pour agrandir pour un meilleur aperçu) :
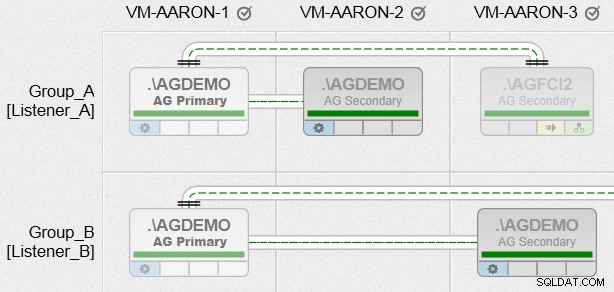
Maintenant, c'est juste un peu taquin, et c'est totalement intentionnel. Je publierai plus d'informations sur cette fonctionnalité dans les semaines à venir !
Conclusion
Lorsque vous passez suffisamment de temps à examiner un problème, vous pouvez ignorer certaines choses assez évidentes. Dans ce cas, il y avait des problèmes évidents cachés par des messages d'erreur carrément peu intuitifs. Je tiens à remercier Joe Sack (@JosephSack), Allan Hirt (@SQLHA) et Thomas Stringer (@SQLife) pour avoir tout abandonné pour aider un autre membre de la communauté dans le besoin.