Le mardi T-SQL de ce mois-ci est animé par Mike Donnelly (@SQLMD), et il résume le sujet comme suit :
Le sujet de ce mois-ci est simple, mais très ouvert. Vous devez apprendre quelque chose de nouveau, puis écrire un article de blog l'expliquant.Eh bien, à partir du moment où Mike a annoncé le sujet, je n'ai pas vraiment cherché à apprendre quelque chose de nouveau, et alors que le week-end approchait et que je savais que lundi allait m'agresser en tant que juré, j'ai pensé que j'allais devoir m'asseoir ce mois.
Ensuite, Martin Smith m'a appris quelque chose que je n'ai jamais su, ou que je savais depuis longtemps mais que j'ai oublié (parfois vous ne savez pas ce que vous ne savez pas, et parfois vous ne pouvez pas vous souvenir de ce que vous n'avez jamais su et de ce que vous ne pouvez pas rappelles toi). Mon souvenir était que changer une colonne de NOT NULL à NULL devrait être une opération de métadonnées uniquement, les écritures sur n'importe quelle page étant différées jusqu'à ce que cette page soit mise à jour pour d'autres raisons, puisque le NULL le bitmap n'aurait pas vraiment besoin d'exister jusqu'à ce qu'au moins une ligne devienne NULL .
Sur ce même message, @ypercube m'a également rappelé cette citation pertinente de Books Online (faute de frappe et tout) :
La modification d'une colonne de NOT NULL à NULL n'est pas prise en charge en tant qu'opération en ligne lorsque la colonne modifiée est référencée par des index non clusterisés."Pas une opération en ligne" peut être interprété comme "pas une opération de métadonnées uniquement" - ce qui signifie qu'il s'agira en fait d'une opération de taille de données (plus votre index est grand, plus cela prendra de temps).
J'ai entrepris de le prouver avec une expérience assez simple (mais longue) sur une colonne cible spécifique pour convertir de NOT NULL à NULL . Je créerais 3 tables, toutes avec une clé primaire clusterisée, mais chacune avec un index non clusterisé différent. L'un aurait la colonne cible comme colonne clé, le second comme un INCLUDE colonne, et la troisième ne référencerait pas du tout la colonne cible.
Voici mes tables et comment je les ai remplies :
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Chaque table avait 100 000 lignes, les index clusterisés avaient 310 pages et les index non clusterisés avaient soit 272 pages (test1 et test2 ) ou 174 pages (test3 ). (Ces valeurs sont faciles à obtenir à partir de sys.dm_db_index_physical_stats .)
Ensuite, j'avais besoin d'un moyen simple de capturer les opérations enregistrées au niveau de la page - j'ai choisi sys.fn_dblog() , bien que j'aurais pu creuser plus profondément et regarder les pages directement. Je n'ai pas pris la peine de jouer avec les valeurs LSN à transmettre à la fonction, puisque je ne l'exécutais pas en production et que je ne me souciais pas beaucoup des performances, donc après les tests, j'ai simplement vidé les résultats de la fonction, à l'exclusion de toutes les données qui a été enregistré avant ALTER TABLE opérations.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Maintenant, je pouvais exécuter mes tests, qui étaient beaucoup plus simples que la configuration.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Maintenant, je pouvais examiner les opérations enregistrées dans chaque cas :
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Les résultats semblent suggérer que chaque page feuille de l'index non clusterisé est touchée pour les cas où la colonne cible a été mentionnée dans l'index de quelque manière que ce soit, mais aucune opération de ce type ne se produit pour le cas où la colonne cible n'est mentionnée dans aucun index non cluster :
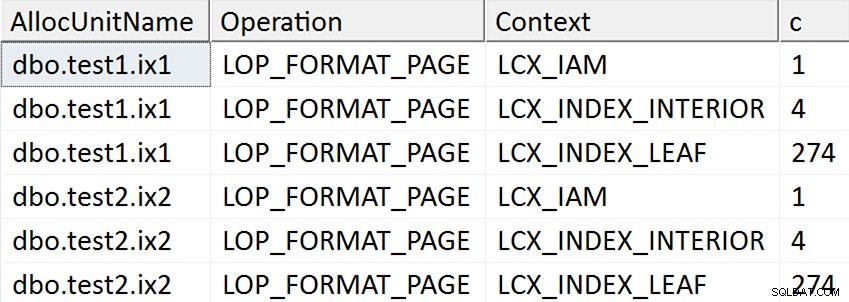
En fait, dans les deux premiers cas, de nouvelles pages sont allouées (vous pouvez valider cela avec DBCC IND , comme Spörri l'a fait dans sa réponse), donc l'opération peut se produire en ligne, mais cela ne veut pas dire qu'elle est rapide (puisqu'il doit encore écrire une copie de toutes ces données et faire le NULL changement de bitmap dans le cadre de l'écriture de chaque nouvelle page et consigner toute cette activité).
Je pense que la plupart des gens soupçonneraient que changer une colonne de NOT NULL à NULL serait des métadonnées uniquement dans tous les scénarios, mais j'ai montré ici que ce n'est pas vrai si la colonne est référencée par un index non clusterisé (et des choses similaires se produisent, qu'il s'agisse d'une clé ou de INCLUDE colonne). Peut-être que cette opération peut également être forcée à être ONLINE dans Azure SQL Database aujourd'hui, ou ce sera possible dans la prochaine version majeure ? Cela n'accélérera pas nécessairement les opérations physiques réelles, mais cela empêchera le blocage en conséquence.
Je n'ai pas testé ce scénario (et l'analyse pour savoir s'il est vraiment en ligne est de toute façon plus difficile dans Azure), et je ne l'ai pas non plus testé sur un tas. Quelque chose que je pourrai revoir dans un prochain article. En attendant, faites attention aux hypothèses que vous pourriez faire sur les opérations portant uniquement sur les métadonnées.