De nos jours, il est assez courant d'avoir une base de données répliquée dans un autre serveur/centre de données, et c'est aussi un must dans certains cas. Il existe différentes raisons de répliquer vos bases de données dans un environnement totalement séparé.
- Migrer vers un autre centre de données.
- Exigences de mise à niveau (matériel/logiciel).
- Maintenir un système opérationnel entièrement synchronisé dans un site de reprise après sinistre (DR) qui peut prendre le relais à tout moment
- Conservez une base de données esclave dans le cadre d'un plan de reprise après sinistre à moindre coût.
- Pour les besoins de géolocalisation (les données doivent être locales dans un pays spécifique).
- Avoir un environnement de test.
- Objectif de dépannage.
- Base de données de rapports.
Et, il existe différentes manières d'effectuer cette tâche de réplication :
- Sauvegarde/Restauration :Sauvegarder une base de données de production et la restaurer dans un nouveau serveur/environnement est la manière classique de le faire, mais c'est aussi une méthode démodée car vous ne garderez pas vos données à jour et vous devrez attendre pour chaque processus de restauration si vous avez besoin de données récentes. Si vous avez un cluster (maître-esclave, multi-maître), et si vous souhaitez le recréer, vous devez restaurer la sauvegarde initiale puis recréer le reste des nœuds, ce qui peut être une tâche chronophage.
- Cloner le cluster :Il est similaire au précédent mais le processus de sauvegarde et de restauration s'applique à l'ensemble du cluster, et non à un seul serveur de base de données spécifique. De cette façon, vous pouvez cloner l'intégralité du cluster dans la même tâche et vous n'avez pas besoin de recréer le reste des nœuds manuellement. Cette méthode a toujours le problème de maintenir les données à jour entre les clones.
- Réplication :Cette méthode inclut l'option de sauvegarde/restauration, mais après la restauration initiale, le processus de réplication gardera vos données synchronisées avec le nœud maître. De cette façon, si vous avez un cluster de bases de données, vous devez restaurer la sauvegarde sur un nœud et recréer tous les nœuds manuellement.
Dans ce blog, nous verrons une nouvelle fonctionnalité de ClusterControl 1.7.4 qui vous permet d'utiliser une combinaison de la méthode que nous avons mentionnée précédemment pour améliorer cette tâche.
Qu'est-ce que la réplication de cluster à cluster ?
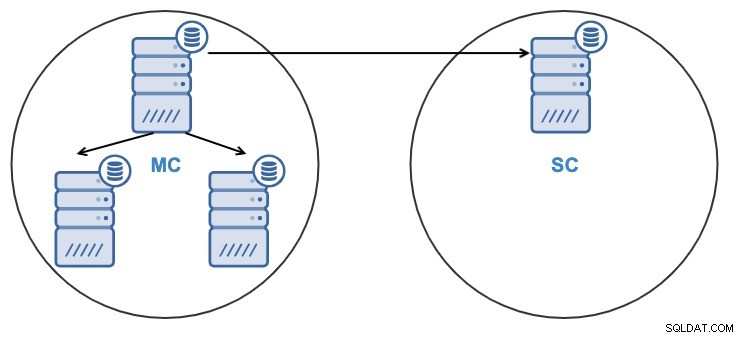
La réplication entre deux clusters n'est pas la même chose que l'extension d'un cluster pour qu'il s'exécute sur deux centres de données. Lors de la mise en place de la réplication entre deux clusters, nous avons en fait 2 systèmes distincts qui peuvent fonctionner de manière autonome. La réplication est utilisée pour les maintenir synchronisés, afin que le système esclave ait un état mis à jour et puisse prendre le relais.
Depuis ClusterControl 1.7.4, il est possible de créer un nouveau cluster en clonant directement un cluster source en cours d'exécution, ou en utilisant une sauvegarde récente du cluster source.
Après avoir cloné le cluster, vous aurez un cluster esclave (SC) recevant des données et un cluster maître (MC) envoyant des modifications à l'esclave.
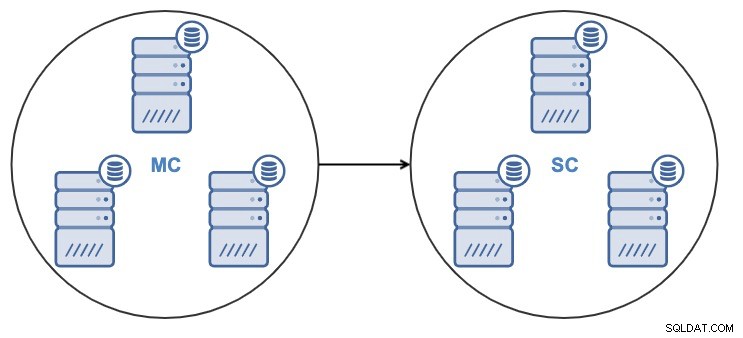
ClusterControl prend en charge la réplication de cluster à cluster pour les types de cluster suivants :
- Percona XtraDB Cluster version 5.6.x et ultérieure.
- MariaDB Galera Cluster version 10.x et ultérieure.
- PostgreSQL 9.6 et versions ultérieures.
Réplication de cluster à cluster pour Percona XtraDB / MariaDB Galera Cluster
Pour les moteurs basés sur MySQL, GTID est requis pour utiliser cette fonctionnalité, et la réplication asynchrone entre le cluster maître et esclave sera utilisée.
Il y a quelques actions à effectuer afin de préparer le cluster actuel pour cette tâche. Tout d'abord, au moins un nœud du cluster actuel doit avoir les journaux binaires activés. Ensuite, vous devez ajouter l'utilisateur de sauvegarde configuré dans le nœud de la base de données dans le fichier de configuration de ClusterControl, qui sera utilisé pour les tâches de gestion. Toutes ces actions peuvent être effectuées à l'aide de l'interface utilisateur ClusterControl ou de la CLI ClusterControl.
Vous êtes maintenant prêt à créer la réplication Percona XtraDB/MariaDB Galera Cluster-to-Cluster. Une fois le travail terminé, vous aurez :
- Un nœud du cluster esclave répliquera à partir d'un nœud du cluster maître.
- La réplication sera bidirectionnelle entre les clusters.
- Tous les nœuds du cluster esclave seront en lecture seule par défaut. Il est possible de désactiver le drapeau de lecture seule sur les nœuds un par un.
- Le clustering actif-actif n'est recommandé que si les applications ne touchent que des ensembles de données disjoints sur l'un ou l'autre des clusters, car le moteur n'offre aucune détection ou résolution de conflit.
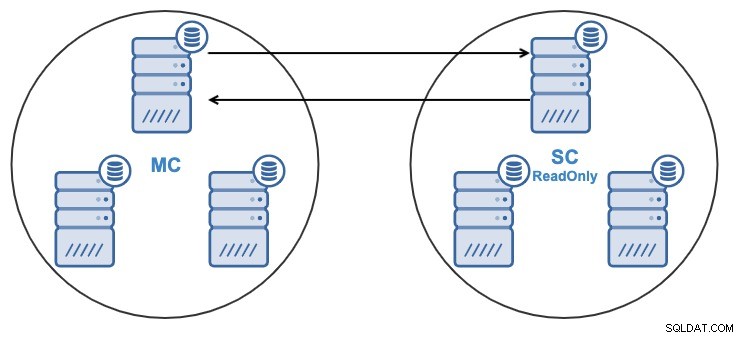
Depuis l'interface utilisateur ClusterControl ou la CLI ClusterControl, vous pourrez :
- Créer ce cluster de réplication.
- Activer la configuration Actif-Actif.
- Modifier la topologie du cluster.
- Reconstruire un cluster de réplication.
- Arrêter/Démarrer un esclave de réplication.
- Réinitialiser l'esclave de réplication (implémenté uniquement à l'aide de ClusterControl CLI atm).
Considérations
- L'utilisateur de sauvegarde doit être ajouté manuellement dans le fichier de configuration de ClusterControl.
- Les informations d'identification de l'utilisateur de sauvegarde doivent être les mêmes dans le cluster actuel et dans le nouveau cluster.
- Le mot de passe root MySQL spécifié lors de la création du cluster esclave doit être le même que le mot de passe root utilisé sur le cluster maître.
Limitations connues
- Le basculement automatique n'est pas encore pris en charge. Si le maître tombe en panne, il est de la responsabilité de l'administrateur de basculer vers un autre maître.
- Il est uniquement possible de "RÉINITIALISER" un esclave de réplication à partir de la CLI de ClusterControl car il n'est pas encore implémenté dans l'interface utilisateur de ClusterControl.
- Il est uniquement possible de reconstruire un cluster en mode lecture seule. Tous les nœuds d'un cluster doivent être en lecture seule pour être considérés comme un cluster en lecture seule.
Réplication de cluster à cluster pour PostgreSQL
La réplication de cluster à cluster ClusterControl est prise en charge sur PostgreSQL à l'aide de la réplication en continu.
En tant qu'exigence, il doit y avoir un serveur PostgreSQL avec le rôle "maître" de ClusterControl, et lorsque vous configurez le cluster esclave, les informations d'identification de l'administrateur doivent être identiques à celles du cluster maître.
Vous êtes maintenant prêt à créer la réplication PostgreSQL Cluster à Cluster. Une fois le travail terminé, vous aurez :
- Un nœud du cluster esclave répliquera à partir d'un nœud du cluster maître.
- La réplication sera unidirectionnelle entre les clusters.
- Le nœud du cluster esclave sera en lecture seule.
Depuis l'interface utilisateur ClusterControl ou la CLI ClusterControl, vous pourrez :
- Créer ce cluster de réplication.
- Reconstruire un cluster de réplication.
- Arrêter/Démarrer un esclave de réplication.
Considération
- Les informations d'identification de l'administrateur doivent être identiques dans le cluster maître et esclave.
Limitations connues
- La taille maximale du cluster esclave est d'un nœud.
- Le cluster esclave ne peut pas être mis en place à partir d'une sauvegarde.
- Les modifications de topologie ne sont pas prises en charge.
- Seule la réplication unidirectionnelle est prise en charge.
Conclusion
En utilisant cette nouvelle fonctionnalité ClusterControl, vous n'avez pas besoin de faire chaque étape pour créer une réplication de cluster séparément ou manuellement, et grâce à son utilisation, vous économiserez du temps et des efforts. Essayez-le !