Cet article est le quatrième d'une série sur les seuils d'optimisation. La série couvre le regroupement et l'agrégation de données, expliquant les différents algorithmes que SQL Server peut utiliser et le modèle de coût qui l'aide à choisir entre les algorithmes. Dans cet article, je me concentre sur les considérations de parallélisme. Je couvre les différentes stratégies de parallélisme que SQL Server peut utiliser, les seuils pour choisir entre un plan série et un plan parallèle, et la logique d'établissement des coûts que SQL Server applique en utilisant un concept appelé degré de parallélisme pour l'établissement des coûts (DOP pour le chiffrage).
Je vais continuer à utiliser la table dbo.Orders dans l'exemple de base de données PerformanceV3 dans mes exemples. Avant d'exécuter les exemples de cet article, exécutez le code suivant pour supprimer quelques index inutiles :
SUPPRIMER L'INDEX SI EXISTE idx_nc_sid_od_cid SUR dbo.Orders ;SUPPRIMER L'INDEX SI EXISTE idx_unc_od_oid_i_cid_eid SUR dbo.Orders ;
Les deux seuls index qui doivent rester sur cette table sont idx_cl_od (cluster avec orderdate comme clé) et PK_Orders (non cluster avec orderid comme clé).
Stratégies de parallélisme
En plus de devoir choisir entre différentes stratégies de regroupement et d'agrégation (Stream Aggregate préordonné, Sort + Stream Aggregate, Hash Aggregate), SQL Server doit également choisir d'opter pour un plan série ou parallèle. En fait, il peut choisir entre plusieurs stratégies de parallélisme différentes. SQL Server utilise une logique d'établissement des coûts qui se traduit par des seuils d'optimisation qui, dans différentes conditions, font qu'une stratégie est préférée aux autres. Nous avons déjà discuté en profondeur de la logique d'établissement des coûts utilisée par SQL Server dans les plans en série dans les parties précédentes de la série. Dans cette section, je présenterai un certain nombre de stratégies de parallélisme que SQL Server peut utiliser pour gérer le regroupement et l'agrégation. Dans un premier temps, je n'entrerai pas dans les détails de la logique d'établissement des coûts, je me contenterai plutôt de décrire les options disponibles. Plus loin dans l'article, j'expliquerai le fonctionnement des formules d'établissement des coûts et un facteur important dans ces formules appelé DOP pour l'établissement des coûts.
Comme vous l'apprendrez plus tard, SQL Server prend en compte le nombre de processeurs logiques de la machine dans ses formules de coût pour les plans parallèles. Dans mes exemples, sauf indication contraire, je suppose que le système cible dispose de 8 processeurs logiques. Si vous voulez essayer les exemples que je vais fournir, afin d'obtenir les mêmes plans et valeurs de coûts que moi, vous devez également exécuter le code sur une machine avec 8 processeurs logiques. S'il se trouve que votre machine a un nombre différent de processeurs, vous pouvez émuler une machine avec 8 processeurs, à des fins de calcul des coûts, comme suit :
DBCC OPTIMIZER_WHATIF(CPUs, 8);
Même si cet outil n'est pas officiellement documenté et pris en charge, il est très pratique à des fins de recherche et d'apprentissage.
La table Orders de notre exemple de base de données contient 1 000 000 de lignes avec des ID de commande compris entre 1 et 1 000 000. Pour démontrer trois stratégies de parallélisme différentes pour le regroupement et l'agrégation, je vais filtrer les commandes dont l'ID de commande est supérieur ou égal à 300 001 (700 000 correspondances) et regrouper les données de trois manières différentes (par custid [20 000 groupes avant le filtrage], par empid [500 groupes] et par shipperid [5 groupes]), et calculez le nombre de commandes par groupe.
Utilisez le code suivant pour créer des index afin de prendre en charge les requêtes groupées :
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid);CREATE INDEX idx_oid_i_cid ON dbo.Orders(orderid) INCLUDE(custid);Les requêtes suivantes implémentent le filtrage et le regroupement susmentionnés :
-- Requête 1 :Serial SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Requête 2 :Parallèle, pas local/global SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid ; -- Requête 3 :Local parallel global parallel SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid ; -- Requête 4 :Local parallel global serial SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid ;Notez que la requête 1 et la requête 2 sont identiques (toutes deux regroupées par custid), seule la première force un plan série et la seconde obtient un plan parallèle sur une machine à 8 processeurs. J'utilise ces deux exemples pour comparer les stratégies série et parallèle pour la même requête.
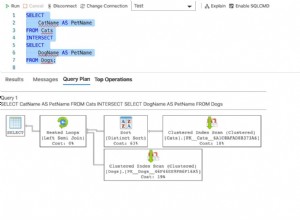
La figure 1 montre les plans estimés pour les quatre requêtes :
Figure 1 :Stratégies de parallélisme
Pour l'instant, ne vous inquiétez pas des valeurs de coût indiquées dans la figure et de la mention du terme DOP pour l'établissement des coûts. J'y reviendrai plus tard. Tout d'abord, concentrez-vous sur la compréhension des stratégies et des différences entre elles.
La stratégie utilisée dans le plan de série pour la requête 1 devrait vous être familière depuis les parties précédentes de la série. Le plan filtre les commandes pertinentes à l'aide d'une recherche dans l'index de couverture que vous avez créé précédemment. Ensuite, avec le nombre estimé de lignes à regrouper et agréger, l'optimiseur préfère la stratégie Hash Aggregate à la stratégie Sort + Stream Aggregate.
Le plan pour la requête 2 utilise une stratégie de parallélisme simple qui n'emploie qu'un seul opérateur d'agrégation. Un opérateur Index Seek parallèle distribue des paquets de lignes aux différents threads de manière circulaire. Chaque paquet de lignes peut contenir plusieurs ID client distincts. Pour qu'un seul opérateur d'agrégation puisse calculer le nombre final correct de groupes, toutes les lignes appartenant au même groupe doivent être gérées par le même thread. Pour cette raison, un opérateur d'échange Parallelism (Repartition Streams) est utilisé pour repartitionner les flux par l'ensemble de regroupement (custid). Enfin, un opérateur d'échange Parallelism (Gather Streams) est utilisé pour rassembler les flux des multiples threads en un seul flux de lignes de résultats.
Les plans pour la requête 3 et la requête 4 utilisent une stratégie de parallélisme plus complexe. Les plans commencent de manière similaire au plan de la requête 2 où un opérateur de recherche d'index parallèle distribue des paquets de lignes à différents threads. Ensuite, le travail d'agrégation se fait en deux étapes :un opérateur d'agrégation regroupe et agrège localement les lignes du thread actuel (notez le membre de résultat partialagg1004), et un deuxième opérateur d'agrégation regroupe et agrège globalement les résultats des agrégats locaux (notez le globalagg1005 membre de résultat). Chacune des deux étapes d'agrégation, locale et globale, peut utiliser n'importe lequel des algorithmes d'agrégation que j'ai décrits plus tôt dans la série. Les deux plans pour la requête 3 et la requête 4 commencent par un agrégat de hachage local et se poursuivent avec un agrégat de tri + flux global. La différence entre les deux est que le premier utilise le parallélisme dans les deux étapes (donc un échange Repartition Streams est utilisé entre les deux et un échange Gather Streams après l'agrégat global), et le second gère l'agrégat local dans une zone parallèle et le global agrégé dans une zone série (par conséquent, un échange Gather Streams est utilisé entre les deux).
Lorsque vous effectuez vos recherches sur l'optimisation des requêtes en général, et sur le parallélisme en particulier, il est bon de se familiariser avec les outils qui vous permettent de contrôler divers aspects de l'optimisation pour voir leurs effets. Vous savez déjà comment forcer un plan série (avec un indice MAXDOP 1) et comment émuler un environnement qui, à des fins de coût, possède un certain nombre de CPU logiques (DBCC OPTIMIZER_WHATIF, avec l'option CPUs). Un autre outil pratique est l'indicateur de requête ENABLE_PARALLEL_PLAN_PREFERENCE (introduit dans SQL Server 2016 SP1 CU2), qui maximise le parallélisme. Ce que je veux dire par là, c'est que si un plan parallèle est supporté pour la requête, le parallélisme sera privilégié dans toutes les parties du plan qui peuvent être manipulées en parallèle, comme si c'était gratuit. Par exemple, observez dans la figure 1 que, par défaut, le plan de la requête 4 gère l'agrégat local dans une zone série et l'agrégat global dans une zone parallèle. Voici la même requête, mais cette fois avec l'indicateur de requête ENABLE_PARALLEL_PLAN_PREFERENCE appliqué (nous l'appellerons Requête 5) :
SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Le plan de la requête 5 est illustré à la figure 2 :
Figure 2 :Maximiser le parallélisme
Notez que cette fois, les agrégats locaux et globaux sont gérés dans des zones parallèles.
Choix du forfait série/parallèle
Rappelez-vous que lors de l'optimisation des requêtes, SQL Server crée plusieurs plans candidats et sélectionne celui dont le coût est le plus bas parmi ceux qu'il a produits. Le terme coût est un peu impropre puisque le plan candidat avec le coût le plus bas est censé être, selon les estimations, celui avec le temps d'exécution le plus bas, et non celui avec la plus faible quantité de ressources utilisées globalement. Par exemple, entre un plan candidat série et un plan parallèle produit pour la même requête, le plan parallèle utilisera probablement plus de ressources, car il doit utiliser des opérateurs d'échange qui synchronisent les threads (distribuer, répartir et rassembler les flux). Cependant, pour que le plan parallèle nécessite moins de temps pour s'exécuter que le plan série, les économies réalisées en effectuant le travail avec plusieurs threads doivent compenser le travail supplémentaire effectué par les opérateurs d'échange. Et cela doit être reflété par les formules de coût que SQL Server utilise lorsque le parallélisme est impliqué. Pas une tâche simple à faire avec précision !
En plus du coût du plan parallèle devant être inférieur au coût du plan en série pour être préféré, le coût de l'alternative au plan en série doit être supérieur ou égal au seuil de coût pour le parallélisme . Il s'agit d'une option de configuration du serveur définie sur 5 par défaut qui empêche que les requêtes avec un coût assez faible soient traitées avec du parallélisme. L'idée ici est qu'un système avec un grand nombre de petites requêtes bénéficierait globalement davantage de l'utilisation de plans en série, au lieu de gaspiller beaucoup de ressources sur la synchronisation des threads. Vous pouvez toujours avoir plusieurs requêtes avec des plans en série exécutés en même temps, en utilisant efficacement les ressources multi-processeurs de la machine. En fait, de nombreux professionnels de SQL Server aiment augmenter le seuil de coût du parallélisme de sa valeur par défaut de 5 à une valeur plus élevée. Un système exécutant simultanément un assez petit nombre de requêtes volumineuses bénéficierait beaucoup plus de l'utilisation de plans parallèles.
Pour récapituler, pour que SQL Server préfère un plan parallèle à l'alternative en série, le coût du plan en série doit être au moins le seuil de coût pour le parallélisme, et le coût du plan parallèle doit être inférieur au coût du plan en série (impliquant potentiellement temps d'exécution réduit).
Avant d'entrer dans les détails des formules de calcul des coûts réels, je vais illustrer avec des exemples différents scénarios où un choix est fait entre des plans en série et en parallèle. Assurez-vous que votre système suppose 8 processeurs logiques pour obtenir des coûts de requête similaires aux miens si vous souhaitez essayer les exemples.
Considérez les requêtes suivantes (nous les appellerons requête 6 et requête 7) :
-- Requête 6 :Serial SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid ; -- Requête 7 :SELECT parallèle forcé empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Les plans de ces requêtes sont illustrés à la figure 3.
Figure 3 :coût de série
Ici, le coût du plan parallèle [forcé] est inférieur au coût du plan en série ; cependant, le coût du plan en série est inférieur au seuil de coût par défaut pour le parallélisme de 5, donc SQL Server a choisi le plan en série par défaut.
Considérez les requêtes suivantes (nous les appellerons requête 8 et requête 9) :
-- Requête 8 :SELECT parallèle empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid ; -- Requête 9 :SELECT série forcé empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION(MAXDOP 1);Les plans de ces requêtes sont illustrés à la figure 4.
Figure 4 :coût de série>=seuil de coût pour le parallélisme, coût parallèle
Ici, le coût du plan en série [forcé] est supérieur ou égal au seuil de coût pour le parallélisme, et le coût du plan parallèle est inférieur au coût du plan en série, donc SQL Server a choisi le plan parallèle par défaut.
Considérez les requêtes suivantes (nous les appellerons requête 10 et requête 11) :
-- Requête 10 :Serial SELECT *FROM dbo.OrdersWHERE orderid>=100000 ; -- Requête 11 :SELECT parallèle forcé *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Les plans de ces requêtes sont illustrés à la figure 5.
Figure 5 :coût de série>=seuil de coût pour le parallélisme, coût parallèle>=coût de série
Ici, le coût du plan de série est supérieur ou égal au seuil de coût pour le parallélisme ; cependant, le coût du plan en série est inférieur au coût du plan parallèle [forcé], donc SQL Server a choisi le plan en série par défaut.
Il y a une autre chose que vous devez savoir sur la tentative de maximiser le parallélisme avec l'indicateur ENABLE_PARALLEL_PLAN_PREFERENCE. Pour que SQL Server puisse même utiliser un plan parallèle, il doit y avoir un activateur de parallélisme comme un prédicat résiduel, un tri, un agrégat, etc. Un plan qui applique uniquement un parcours d'index ou une recherche d'index sans prédicat résiduel, et sans aucun autre activateur de parallélisme, sera traité avec un plan en série. Considérez les requêtes suivantes comme exemple (nous les appellerons Requête 12 et Requête 13) :
-- Requête 12 SELECT *FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Requête 13 SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Les plans de ces requêtes sont illustrés à la figure 6.
Figure 6 :Activateur de parallélisme
La requête 12 obtient un plan en série malgré l'indice car il n'y a pas d'activateur de parallélisme. La requête 13 obtient un plan parallèle car il y a un prédicat résiduel impliqué.
Calculer et tester le DOP pour l'établissement des coûts
Microsoft a dû calibrer les formules de calcul des coûts pour tenter d'avoir un coût de plan parallèle inférieur au coût du plan en série reflétant un temps d'exécution inférieur et vice versa. Une idée potentielle était de prendre le coût du processeur de l'opérateur série et de le diviser simplement par le nombre de processeurs logiques dans la machine pour produire le coût du processeur de l'opérateur parallèle. Le nombre logique de CPU dans la machine est le principal facteur déterminant le degré de parallélisme de la requête, ou DOP en abrégé (le nombre de threads pouvant être utilisés dans une zone parallèle du plan). La pensée simpliste ici est que si un opérateur prend T unités de temps pour se terminer lors de l'utilisation d'un thread, et que le degré de parallélisme de la requête est D, il faudrait à l'opérateur T/D le temps de se terminer lors de l'utilisation de D threads. En pratique, les choses ne sont pas si simples. Par exemple, vous avez généralement plusieurs requêtes exécutées simultanément et pas une seule, auquel cas une seule requête n'obtiendra pas toutes les ressources CPU de la machine. Ainsi, Microsoft a eu l'idée du degré de parallélisme pour les coûts (DOP pour costing, en bref). Cette mesure est généralement inférieure au nombre de processeurs logiques dans la machine et correspond au facteur par lequel le coût du processeur de l'opérateur série est divisé pour calculer le coût du processeur de l'opérateur parallèle.
Normalement, le DOP pour l'établissement des coûts est calculé comme le nombre de processeurs logiques divisé par 2, en utilisant la division entière. Il y a cependant des exceptions. Lorsque le nombre de processeurs est de 2 ou 3, le DOP pour le coût est défini sur 2. Avec 4 processeurs ou plus, le DOP pour le coût est défini sur #CPUs / 2, encore une fois, en utilisant la division entière. C'est jusqu'à un certain maximum, qui dépend de la quantité de mémoire disponible sur la machine. Dans une machine avec jusqu'à 4 096 Mo de mémoire, le DOP maximum pour l'évaluation des coûts est de 8 ; avec plus de 4 096 Mo, le DOP maximum pour l'établissement des coûts est de 32.
Pour tester cette logique, vous savez déjà comment émuler un nombre souhaité de processeurs logiques à l'aide de DBCC OPTIMIZER_WHATIF, avec l'option CPUs, comme ceci :
DBCC OPTIMIZER_WHATIF(CPUs, 8);En utilisant la même commande avec l'option MemoryMBs, vous pouvez émuler la quantité de mémoire souhaitée en Mo, comme suit :
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);Utilisez le code suivant pour vérifier l'état existant des options émulées :
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Statut); DBCC TRACEOFF(3604);Utilisez le code suivant pour réinitialiser toutes les options :
DBCC OPTIMIZER_WHATIF(ResetAll);Voici une requête T-SQL que vous pouvez utiliser pour calculer le DOP pour l'établissement des coûts en fonction d'un nombre d'entrées de processeurs logiques et d'une quantité de mémoire :
DECLARE @NumCPUs AS INT =8, @MemoryMBs AS INT =16384 ; SELECT CASE WHEN @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 WHEN @NumCPUs>=4 THEN (SELECT MIN(n) FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n)) END AS DOP4CFROM (VALUES( CASE WHEN @MemoryMBs <=4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C);Avec les valeurs d'entrée spécifiées, cette requête renvoie 4.
Le tableau 1 détaille le DOP pour l'établissement des coûts que vous obtenez en fonction du nombre logique de processeurs et de la quantité de mémoire de votre machine.
| #CPU | DOP pour le coût lorsque MemoryMBs <=4096 | DOP pour le coût lorsque MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tableau 1 :DOP pour le calcul des coûts
À titre d'exemple, reprenons les requêtes 1 et 2 présentées précédemment :
-- Requête 1 :SELECT série forcé custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Requête 2 :Naturellement parallèle SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid ;
Les plans de ces requêtes sont illustrés à la figure 7.
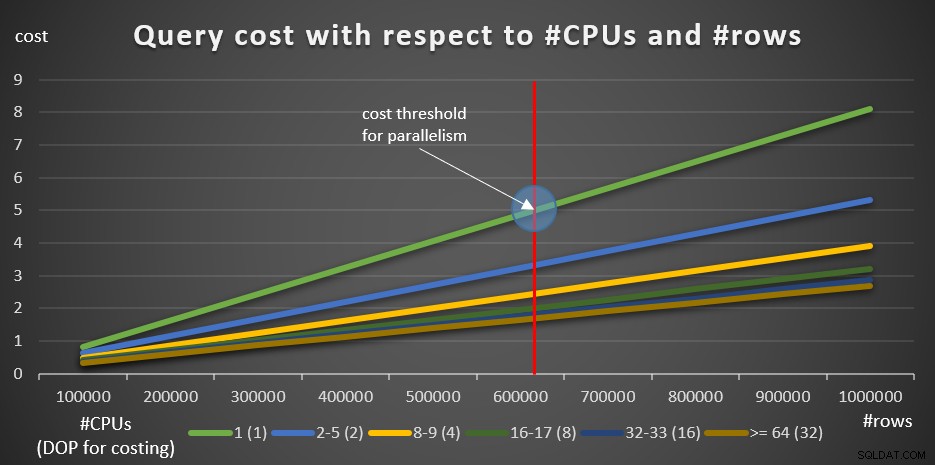 Figure 7 :DOP pour coût
Figure 7 :DOP pour coût
La requête 1 force un plan série, tandis que la requête 2 obtient un plan parallèle dans mon environnement (émulant 8 processeurs logiques et 16 384 Mo de mémoire). Cela signifie que le DOP pour l'établissement des coûts dans mon environnement est de 4. Comme mentionné, le coût CPU d'un opérateur parallèle est calculé comme le coût CPU de l'opérateur série divisé par le DOP pour l'établissement des coûts. Vous pouvez voir que c'est effectivement le cas dans notre plan parallèle avec les opérateurs Index Seek et Hash Aggregate qui s'exécutent en parallèle.
Quant aux coûts des opérateurs d'échange, ils sont constitués d'un coût de démarrage et d'un coût constant par ligne, que vous pouvez facilement désosser.
Notez que dans la stratégie de regroupement et d'agrégation parallèle simple, qui est celle utilisée ici, les estimations de cardinalité dans les plans en série et en parallèle sont les mêmes. C'est parce qu'un seul opérateur d'agrégation est employé. Plus tard, vous verrez que les choses sont différentes lorsque vous utilisez la stratégie locale/globale.
Les requêtes suivantes permettent d'illustrer l'effet du nombre de processeurs logiques et du nombre de lignes impliquées sur le coût de la requête (10 requêtes, avec des incréments de 100 000 lignes) :
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=900001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=800001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=700001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=600001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=500001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=200001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=100001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=000001GROUP BY empid ;
La figure 8 montre les résultats.
Figure 8 :coût de la requête par rapport aux #CPU et aux #lignes
La ligne verte représente les coûts des différentes requêtes (avec les différents nombres de lignes) utilisant un plan en série. Les autres lignes représentent les coûts des plans parallèles avec différents nombres de CPU logiques, et leur DOP respectif pour le calcul des coûts. La ligne rouge représente le point où le coût de la requête en série est de 5, le seuil de coût par défaut pour le paramètre de parallélisme. A gauche de ce point (moins de lignes à regrouper et agréger), normalement, l'optimiseur ne prendra pas en compte un plan parallèle. Afin de pouvoir rechercher les coûts des plans parallèles en dessous du seuil de coût pour le parallélisme, vous pouvez faire l'une des deux choses. Une option consiste à utiliser l'indicateur de requête ENABLE_PARALLEL_PLAN_PREFERENCE, mais pour rappel, cette option maximise le parallélisme au lieu de simplement le forcer. Si ce n'est pas l'effet souhaité, vous pouvez simplement désactiver le seuil de coût pour le parallélisme, comme ceci :
EXEC sp_configure 'afficher les options avancées', 1; RECONFIGURER ; EXEC sp_configure 'seuil de coût pour le parallélisme', 0 ; EXEC sp_configure 'afficher les options avancées', 0; RECONFIGURER ;
Évidemment, ce n'est pas une décision intelligente dans un système de production, mais parfaitement utile à des fins de recherche. C'est ce que j'ai fait pour produire les informations du graphique de la figure 8.
En commençant par 100K lignes et en ajoutant des incréments de 100K, tous les graphiques semblent impliquer que si le seuil de coût pour le parallélisme n'était pas un facteur, un plan parallèle aurait toujours été préféré. C'est en effet le cas avec nos requêtes et le nombre de lignes impliquées. Cependant, essayez un plus petit nombre de lignes, en commençant par 10 000 et en augmentant par incréments de 10 000 en utilisant les cinq requêtes suivantes (encore une fois, maintenez le seuil de coût pour le parallélisme désactivé pour le moment) :
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=990001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=980001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=970001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=960001GROUP BY empid ; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=950001GROUP BY empid ;
La figure 9 montre les coûts de requête avec les plans série et parallèle (émulation de 4 processeurs, DOP pour le coût de 2).
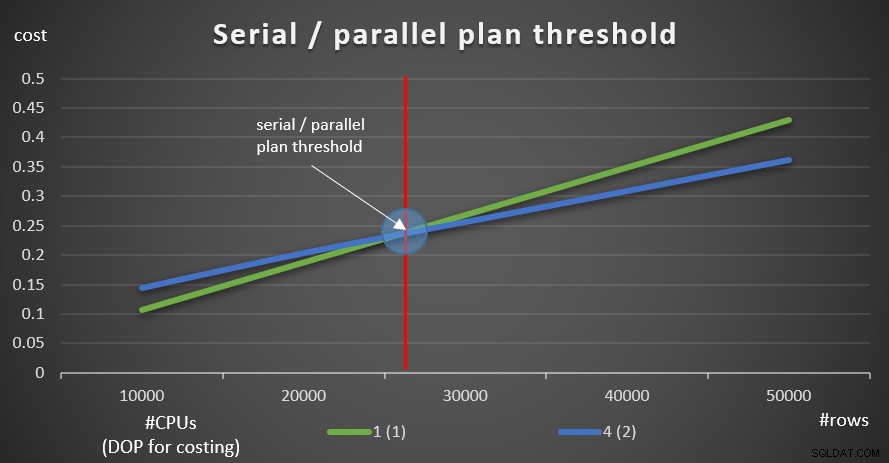 Figure 9 :Série / seuil du plan parallèle
Figure 9 :Série / seuil du plan parallèle
Comme vous pouvez le voir, il existe un seuil d'optimisation jusqu'auquel le plan en série est préféré, et au-dessus duquel le plan parallèle est préféré. Comme mentionné, dans un système normal où vous maintenez le seuil de coût pour le paramètre de parallélisme à la valeur par défaut de 5, ou plus, le seuil effectif est de toute façon plus élevé que dans ce graphique.
Plus tôt, j'ai mentionné que lorsque SQL Server choisit la stratégie de parallélisme de regroupement et d'agrégation simple, les estimations de cardinalité des plans série et parallèle sont les mêmes. La question est de savoir comment SQL Server gère les estimations de cardinalité pour la stratégie de parallélisme local/global.
Pour comprendre cela, j'utiliserai les requêtes 3 et 4 de nos exemples précédents :
-- Requête 3 :Local parallel global parallel SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid ; -- Requête 4 :Local parallel global serial SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid ;
Dans un système avec 8 processeurs logiques et un DOP effectif pour une valeur de coût de 4, j'ai obtenu les plans illustrés à la figure 10.
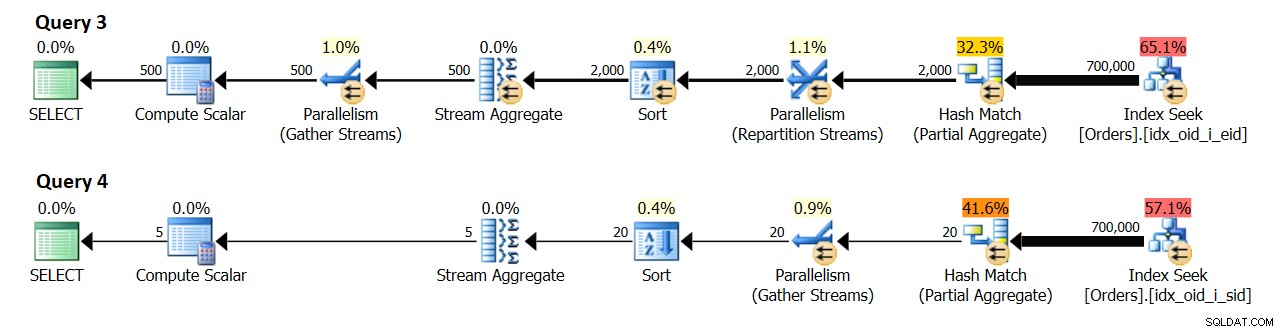 Figure 10 :Estimation de la cardinalité
Figure 10 :Estimation de la cardinalité
La requête 3 regroupe les commandes par empid. 500 groupes d'employés distincts sont attendus à terme.
La requête 4 regroupe les commandes par shipperid. 5 groupes d'expéditeurs distincts sont attendus à terme.
Curieusement, il semble que l'estimation de cardinalité pour le nombre de groupes produits par l'agrégat local soit { nombre de groupes distincts attendus par chaque thread } * { DOP pour l'établissement des coûts }. En pratique, vous vous rendez compte que le nombre sera généralement deux fois plus élevé puisque ce qui compte, c'est le DOP pour l'exécution (c'est-à-dire juste le DOP), qui est basé principalement sur le nombre de processeurs logiques. Cette partie est un peu délicate à émuler à des fins de recherche car la commande DBCC OPTIMIZER_WHATIF avec l'option CPU affecte le calcul du DOP pour le coût, mais le DOP pour l'exécution ne sera pas supérieur au nombre réel de CPU logiques que votre instance SQL Server voit. Ce nombre est essentiellement basé sur le nombre de planificateurs avec lesquels SQL Server démarre. Vous pouvez contrôler le nombre de planificateurs SQL Server démarre avec le paramètre de démarrage -P{ #schedulers }, mais c'est un outil de recherche un peu plus agressif par rapport à une option de session.
Quoi qu'il en soit, sans émuler aucune ressource, ma machine de test dispose de 4 processeurs logiques, ce qui entraîne un DOP pour le coût 2 et un DOP pour l'exécution 4. Dans mon environnement, l'agrégat local dans le plan de la requête 3 affiche une estimation de 1 000 groupes de résultats (500 x 2) et un réel de 2 000 (500 x 4). De même, l'agrégat local dans le plan de la requête 4 affiche une estimation de 10 groupes de résultats (5 x 2) et une valeur réelle de 20 (5 x 4).
Une fois les tests terminés, exécutez le code suivant pour le nettoyage :
-- Définissez le seuil de coût pour le parallélisme sur la valeur par défaut EXEC sp_configure 'show advanced options', 1; RECONFIGURER ; EXEC sp_configure 'seuil de coût pour le parallélisme', 5 ; EXEC sp_configure 'afficher les options avancées', 0; RECONFIGURE;GO -- Réinitialiser les options OPTIMIZER_WHATIF DBCC OPTIMIZER_WHATIF(ResetAll); -- Supprimer les index DROP INDEX idx_oid_i_sid ON dbo.Orders ; DROP INDEX idx_oid_i_eid ON dbo.Orders ; DROP INDEX idx_oid_i_cid ON dbo.Orders ;
Conclusion
Dans cet article, j'ai décrit un certain nombre de stratégies de parallélisme utilisées par SQL Server pour gérer le regroupement et l'agrégation. Un concept important à comprendre dans l'optimisation des requêtes avec des plans parallèles est le degré de parallélisme (DOP) pour l'établissement des coûts. J'ai montré un certain nombre de seuils d'optimisation, y compris un seuil entre les plans en série et en parallèle, et le seuil de coût de réglage pour le parallélisme. La plupart des concepts que j'ai décrits ici ne sont pas propres au regroupement et à l'agrégation, mais sont tout aussi applicables aux considérations de plan parallèle dans SQL Server en général. Le mois prochain, je continuerai la série en discutant de l'optimisation avec les réécritures de requêtes.