JPA (Annotation de persistance Java ) est la solution standard de Java pour combler le fossé entre les modèles de domaine orientés objet et les systèmes de bases de données relationnelles. L'idée est de mapper les classes Java aux tables relationnelles et les propriétés de ces classes aux lignes de la table. Cela modifie la sémantique de l'expérience globale du codage Java en faisant collaborer de manière transparente deux technologies différentes au sein du même paradigme de programmation. Cet article fournit une vue d'ensemble et son implémentation de support en Java.
Un aperçu
Les bases de données relationnelles sont peut-être les plus stables de toutes les technologies de persistance disponibles en informatique au lieu de toutes les complexités qu'elles impliquent. En effet, aujourd'hui, même à l'ère des soi-disant « big data », les bases de données relationnelles « NoSQL » sont constamment demandées et florissantes. Les bases de données relationnelles sont une technologie stable non pas par de simples mots mais par son existence au fil des ans. NoSQL peut être utile pour traiter de grandes quantités de données structurées dans l'entreprise, mais les nombreuses charges de travail transactionnelles sont mieux gérées via des bases de données relationnelles. De plus, il existe d'excellents outils d'analyse associés aux bases de données relationnelles.
Pour communiquer avec la base de données relationnelle, l'ANSI a standardisé un langage appelé SQL (Langage de requête structuré ). Une instruction écrite dans ce langage peut être utilisée à la fois pour définir et manipuler des données. Mais, le problème de SQL dans le traitement de Java est qu'ils ont une structure syntaxique incompatible et très différente au cœur, ce qui signifie que SQL est procédural alors que Java est orienté objet. Ainsi, une solution de travail est recherchée telle que Java puisse parler de manière orientée objet et que la base de données relationnelle soit toujours capable de se comprendre. JPA est la réponse à cet appel et fournit le mécanisme pour établir une solution de travail entre les deux.
Mappage relationnel à l'objet
Les programmes Java interagissent avec les bases de données relationnelles en utilisant JDBC (Connectivité de la base de données Java ) API. Un pilote JDBC est la clé de la connectivité et permet à un programme Java de manipuler cette base de données à l'aide de l'API JDBC. Une fois la connexion établie, le programme Java lance des requêtes SQL sous la forme de String s pour communiquer les opérations de création, d'insertion, de mise à jour et de suppression. C'est suffisant à toutes fins pratiques, mais peu pratique du point de vue d'un programmeur Java. Et si la structure des tables relationnelles pouvait être remodelée en classes Java pures et que vous pouviez ensuite les traiter de la manière habituelle orientée objet ? La structure d'une table relationnelle est une représentation logique des données sous forme de tableau. Les tables sont composées de colonnes décrivant les attributs d'entité et les lignes sont la collection d'entités. Par exemple, une table EMPLOYEE peut contenir les entités suivantes avec leurs attributs.
| Emp_number | Nom | dept_no | Salaire | Lieu |
| 112233 | Pierre | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Les lignes sont uniques par clé primaire (emp_number) dans une table ; cela permet une recherche rapide. Une table peut être liée à une ou plusieurs tables par une clé, telle qu'une clé étrangère (dept_no), qui se rapporte à la ligne équivalente dans une autre table.
Selon la spécification Java Persistence 2.1, JPA ajoute la prise en charge de la génération de schémas, des méthodes de conversion de type, de l'utilisation du graphe d'entité dans les requêtes et de l'opération de recherche, du contexte de persistance non synchronisé, de l'appel de procédure stockée et de l'injection dans les classes d'écoute d'entité. Il inclut également des améliorations du langage de requête Java Persistence, de l'API Criteria et du mappage des requêtes natives.
Bref, il fait tout pour donner l'illusion qu'il n'y a pas de partie procédurale dans le traitement des bases de données relationnelles et que tout est orienté objet.
Mise en œuvre JPA
JPA décrit la gestion des données relationnelles dans l'application Java. Il s'agit d'une spécification et il existe un certain nombre d'implémentations de celle-ci. Certaines implémentations populaires sont Hibernate, EclipseLink et Apache OpenJPA. JPA définit les métadonnées via des annotations dans des classes Java ou via des fichiers de configuration XML. Cependant, nous pouvons utiliser à la fois XML et des annotations pour décrire les métadonnées. Dans un tel cas, la configuration XML remplace les annotations. Ceci est raisonnable car les annotations sont écrites avec le code Java, alors que les fichiers de configuration XML sont externes au code Java. Par conséquent, plus tard, le cas échéant, des modifications doivent être apportées aux métadonnées ; dans le cas d'une configuration basée sur des annotations, elle nécessite un accès direct au code Java. Cela peut toujours ne pas être possible. Dans un tel cas, nous pouvons écrire une configuration de métadonnées nouvelle ou modifiée dans un fichier XML sans aucune indication de changement dans le code d'origine et avoir toujours l'effet souhaité. C'est l'avantage d'utiliser la configuration XML. Cependant, la configuration basée sur les annotations est plus pratique à utiliser et est le choix populaire parmi les programmeurs.
- Hiberner est la plus populaire et la plus avancée parmi toutes les implémentations JPA grâce à Red Hat. Il utilise ses propres ajustements et fonctionnalités ajoutées qui peuvent être utilisées en plus de son implémentation JPA. Il a une plus grande communauté d'utilisateurs et est bien documenté. Certaines des fonctionnalités propriétaires supplémentaires sont la prise en charge de la multilocation, la jonction d'entités non associées dans les requêtes, la gestion de l'horodatage, etc.
- EclipseLink est basé sur TopLink et est une implémentation de référence des versions JPA. Il fournit des fonctionnalités JPA standard en plus de certaines fonctionnalités propriétaires intéressantes, telles que la prise en charge de la multilocation, la gestion des événements de modification de la base de données, etc.
Utilisation de JPA dans un programme Java SE
Pour utiliser JPA dans un programme Java, vous avez besoin d'un fournisseur JPA tel que Hibernate ou EclipseLink, ou toute autre bibliothèque. De plus, vous avez besoin d'un pilote JDBC qui se connecte à la base de données relationnelle spécifique. Par exemple, dans le code suivant, nous avons utilisé les bibliothèques suivantes :
- Fournisseur : Lien Eclipse
- Pilote JDBC : Pilote JDBC pour MySQL (connecteur/J)
Nous établirons une relation entre deux tables (Employé et Département) comme un à un et un à plusieurs, comme illustré dans le diagramme EER suivant (voir Figure 1).
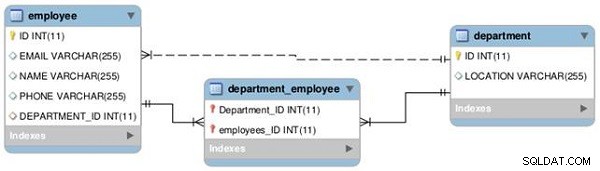
Figure 1 : Relations entre les tables
L'employé table est mappée à une classe d'entités à l'aide d'annotations comme suit :
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
Et, le département table est mappée à une classe d'entité comme suit :
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Le fichier de configuration, persistence.xml , est créé dans le META-INF annuaire. Ce fichier contient la configuration de la connexion, telle que le pilote JDBC utilisé, le nom d'utilisateur et le mot de passe pour l'accès à la base de données, ainsi que d'autres informations pertinentes requises par le fournisseur JPA pour établir la connexion à la base de données.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Les entités ne persistent pas elles-mêmes. La logique doit être appliquée pour manipuler les entités afin de gérer leur cycle de vie persistant. Le EntityManager L'interface fournie par le JPA permet à l'application de gérer et de rechercher des entités dans la base de données relationnelle. Nous créons un objet de requête à l'aide de EntityManager pour communiquer avec la base de données. Pour obtenir EntityManager pour une base de données donnée, nous utiliserons un objet qui implémente une EntityManagerFactory interface. Il y a un statique méthode, appelée createEntityManagerFactory , dans la Persistance classe qui renvoie EntityManagerFactory pour l'unité de persistance spécifiée en tant que String argument. Dans l'implémentation rudimentaire suivante, nous avons implémenté la logique.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Maintenant, nous sommes prêts à créer l'interface principale de l'application. Ici, nous avons implémenté uniquement l'opération d'insertion par souci de simplicité et de contraintes d'espace.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Remarque : Veuillez consulter la documentation de l'API Java appropriée pour obtenir des informations détaillées sur les API utilisées dans le code précédent. |
Conclusion
Comme cela devrait être évident, la terminologie de base du contexte JPA et Persistence est plus vaste que l'aperçu donné ici, mais commencer par un aperçu rapide vaut mieux que le code sale long et complexe et ses détails conceptuels. Si vous avez une petite expérience de programmation dans le noyau JDBC, vous apprécierez sans aucun doute comment JPA peut vous simplifier la vie. Nous approfondirons progressivement JPA au fur et à mesure que nous avancerons dans les prochains articles.



