Lorsque SQL Server optimise une requête, lors d'une phase d'exploration il produit des plans candidats et choisit parmi eux celui qui a le coût le plus bas. Le plan choisi est supposé avoir le temps d'exécution le plus bas parmi les plans explorés. Le fait est que l'optimiseur ne peut choisir qu'entre les stratégies qui y ont été encodées. Par exemple, lors de l'optimisation du regroupement et de l'agrégation, à la date de rédaction de cet article, l'optimiseur ne peut choisir qu'entre les stratégies Stream Aggregate et Hash Aggregate. J'ai couvert les stratégies disponibles dans les parties précédentes de cette série. Dans la partie 1, j'ai couvert la stratégie Stream Aggregate préordonnée, dans la partie 2, la stratégie Sort + Stream Aggregate, dans la partie 3, la stratégie Hash Aggregate et dans la partie 4, les considérations de parallélisme.
Ce que l'optimiseur SQL Server ne prend actuellement pas en charge, c'est la personnalisation et l'intelligence artificielle. Autrement dit, si vous pouvez trouver une stratégie qui, dans certaines conditions, est plus optimale que celles prises en charge par l'optimiseur, vous ne pouvez pas améliorer l'optimiseur pour la prendre en charge, et l'optimiseur ne peut pas apprendre à l'utiliser. Cependant, ce que vous pouvez faire, c'est réécrire la requête en utilisant des éléments de requête alternatifs qui peuvent être optimisés avec la stratégie que vous avez en tête. Dans cette cinquième et dernière partie de la série, je démontre cette technique de réglage de requête à l'aide de révisions de requête.
Un grand merci à Paul White (@SQL_Kiwi) pour son aide dans certains des calculs de coûts présentés dans cet article !
Comme dans les parties précédentes de la série, j'utiliserai l'exemple de base de données PerformanceV3. Utilisez le code suivant pour supprimer les index inutiles de la table Orders :
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Stratégie d'optimisation par défaut
Considérez les tâches de regroupement et d'agrégation de base suivantes :
Renvoyer la date de commande maximale pour chaque expéditeur, employé et client.
Pour des performances optimales, vous créez les index de support suivants :
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Voici les trois requêtes que vous utiliseriez pour gérer ces tâches, ainsi que les coûts de sous-arborescence estimés, ainsi que les statistiques d'E/S, de CPU et de temps écoulé :
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
La figure 1 montre les plans pour ces requêtes :
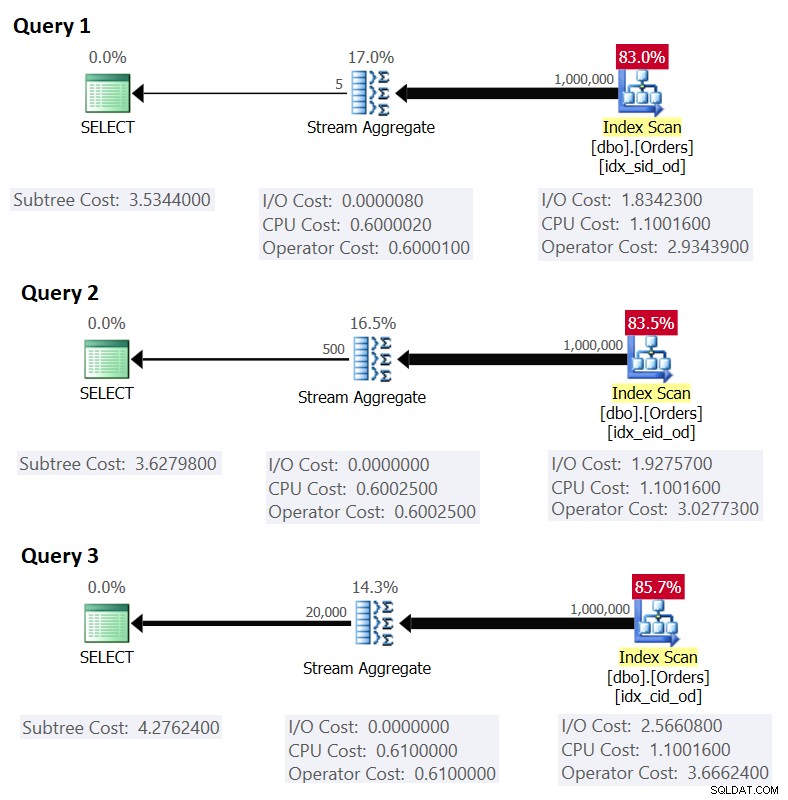 Figure 1 :Plans pour requêtes groupées
Figure 1 :Plans pour requêtes groupées
Rappelez-vous que si vous avez un index de couverture en place, avec les colonnes de l'ensemble de regroupement comme colonnes de clé principales, suivies de la colonne d'agrégation, SQL Server est susceptible de choisir un plan qui effectue une analyse ordonnée de l'index de couverture prenant en charge la stratégie Stream Aggregate . Comme le montrent les plans de la figure 1, l'opérateur d'analyse d'index est responsable de la majeure partie du coût du plan, et la partie E/S est la plus importante.
Avant de présenter une stratégie alternative et d'expliquer les circonstances dans lesquelles elle est plus optimale que la stratégie par défaut, évaluons le coût de la stratégie existante. Étant donné que la partie E/S est la plus importante pour déterminer le coût du plan de cette stratégie par défaut, commençons par estimer le nombre de lectures de pages logiques qui seront nécessaires. Plus tard, nous estimerons également le coût du plan.
Pour estimer le nombre de lectures logiques requises par l'opérateur Index Scan, vous devez savoir combien de lignes vous avez dans la table et combien de lignes tiennent dans une page en fonction de la taille des lignes. Une fois que vous avez ces deux opérandes, votre formule pour le nombre de pages requis au niveau feuille de l'index est alors CEILING(1e0 * @numrows / @rowsperpage). Si vous n'avez que la structure de la table et aucun exemple de données existant avec lequel travailler, vous pouvez utiliser cet article pour estimer le nombre de pages que vous auriez au niveau feuille de l'index de prise en charge. Si vous disposez de bonnes données d'échantillon représentatives, même si elles ne sont pas à la même échelle que dans l'environnement de production, vous pouvez calculer le nombre moyen de lignes qui tiennent dans une page en interrogeant le catalogue et les objets de gestion dynamique, comme ceci :
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Cette requête génère la sortie suivante dans notre exemple de base de données :
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Maintenant que vous avez le nombre de lignes qui tiennent dans une page feuille de l'index, vous pouvez estimer le nombre total de pages feuille dans l'index en fonction du nombre de lignes que vous attendez de votre table de production. Ce sera également le nombre prévu de lectures logiques à appliquer par l'opérateur Index Scan. En pratique, il y a plus dans le nombre de lectures qui pourraient avoir lieu que le nombre de pages au niveau feuille de l'index, comme les lectures supplémentaires produites par le mécanisme de lecture anticipée, mais je vais les ignorer pour garder notre discussion simple .
Par exemple, le nombre estimé de lectures logiques pour la requête 1 par rapport au nombre de lignes attendu est CEILING(1e0 * @numorws / 404). Avec 1 000 000 de lignes, le nombre attendu de lectures logiques est de 2 476. La différence entre 2 476 et le nombre de pages de ligne signalé de 2 473 peut être attribuée à l'arrondi que j'ai effectué lors du calcul du nombre moyen de lignes par page.
En ce qui concerne le coût du plan, j'ai expliqué comment désosser le coût de l'opérateur Stream Aggregate dans la partie 1 de la série. De la même manière, vous pouvez désosser le coût de l'opérateur Index Scan. Le coût du plan est alors la somme des coûts des opérateurs Index Scan et Stream Aggregate.
Pour calculer le coût de l'opérateur Index Scan, vous souhaitez commencer par rétroconcevoir certaines des constantes importantes du modèle de coût :
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Une fois les constantes de modèle de coût ci-dessus déterminées, vous pouvez procéder à l'ingénierie inverse des formules pour le coût d'E/S, le coût CPU et le coût total de l'opérateur pour l'opérateur Index Scan :
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
Par exemple, le coût de l'opérateur Index Scan pour la requête 1, avec 2 473 pages et 1 000 000 lignes, est :
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
Voici la formule de rétro-ingénierie pour le coût de l'opérateur Stream Aggregate :
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
Par exemple, pour la requête 1, nous avons 1 000 000 lignes et 5 groupes. Le coût estimé est donc de 0,6000105.
En combinant les coûts des deux opérateurs, voici la formule pour le coût total du plan :
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Pour la requête 1, avec 2 473 pages, 1 000 000 lignes et 5 groupes, vous obtenez :
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
Cela correspond à ce que la figure 1 montre comme coût estimé pour la requête 1.
Si vous vous basez sur une estimation du nombre de lignes par page, votre formule serait :
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Par exemple, pour la requête 1, avec 1 000 000 lignes, 404 lignes par page et 5 groupes, le coût estimé est :
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
Comme exercice, vous pouvez appliquer les nombres pour la requête 2 (1 000 000 lignes, 385 lignes par page, 500 groupes) et la requête 3 (1 000 000 lignes, 289 lignes par page, 20 000 groupes) dans notre formule, et voir que les résultats correspondent à ce La figure 1 montre.
Optimisation des requêtes avec réécritures de requêtes
La stratégie d'agrégation de flux préordonnée par défaut pour le calcul d'un agrégat MIN/MAX par groupe repose sur une analyse ordonnée d'un index de couverture de support (ou une autre activité préliminaire qui émet les lignes ordonnées). Une stratégie alternative, avec un index de couverture de support présent, consisterait à effectuer une recherche d'index par groupe. Voici une description d'un pseudo plan basé sur une telle stratégie pour une requête qui regroupe par grpcol et applique un MAX(aggcol) :
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; Si vous y réfléchissez, la stratégie par défaut basée sur l'analyse est optimale lorsque l'ensemble de regroupement a une faible densité (grand nombre de groupes, avec un petit nombre de lignes par groupe en moyenne). La stratégie basée sur les recherches est optimale lorsque l'ensemble de regroupement a une densité élevée (petit nombre de groupes, avec un grand nombre de lignes par groupe en moyenne). La figure 2 illustre les deux stratégies en indiquant quand chacune est optimale.
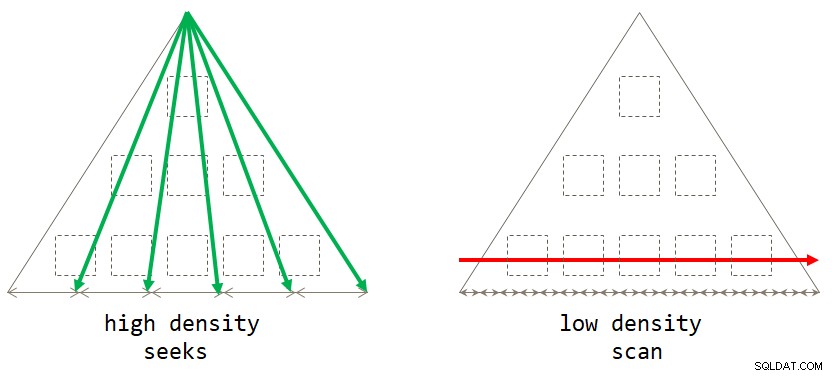 Figure 2 :Stratégie optimale basé sur la densité du jeu de regroupement
Figure 2 :Stratégie optimale basé sur la densité du jeu de regroupement
Tant que vous écrivez la solution sous la forme d'une requête groupée, actuellement SQL Server ne prendra en compte que la stratégie d'analyse. Cela fonctionnera bien pour vous lorsque l'ensemble de regroupement a une faible densité. Lorsque vous avez une densité élevée, afin d'obtenir la stratégie de recherche, vous devrez appliquer une réécriture de requête. Une façon d'y parvenir consiste à interroger la table qui contient les groupes et à utiliser une sous-requête d'agrégat scalaire sur la table principale pour obtenir l'agrégat. Par exemple, pour calculer la date de commande maximale pour chaque expéditeur, vous utiliserez le code suivant :
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; Les directives d'indexation pour la table principale sont les mêmes que celles pour prendre en charge la stratégie par défaut. Nous avons déjà ces index en place pour les trois tâches susmentionnées. Vous voudriez probablement aussi un index de support sur les colonnes du jeu de regroupement dans la table contenant les groupes pour minimiser le coût d'E/S par rapport à cette table. Utilisez le code suivant pour créer ces index de support pour nos trois tâches :
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
Un petit problème cependant est que la solution basée sur la sous-requête n'est pas un équivalent logique exact de la solution basée sur la requête groupée. Si vous avez un groupe sans présence dans la table principale, le premier renverra le groupe avec un NULL comme agrégat, tandis que le second ne renverra pas du tout le groupe. Un moyen simple d'obtenir un véritable équivalent logique de la requête groupée consiste à appeler la sous-requête à l'aide de l'opérateur CROSS APPLY dans la clause FROM au lieu d'utiliser une sous-requête scalaire dans la clause SELECT. N'oubliez pas que CROSS APPLY ne renverra pas une ligne de gauche si la requête appliquée renvoie un ensemble vide. Voici les trois requêtes de solution mettant en œuvre cette stratégie pour nos trois tâches, ainsi que leurs statistiques de performances :
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; Les plans de ces requêtes sont illustrés à la figure 3.
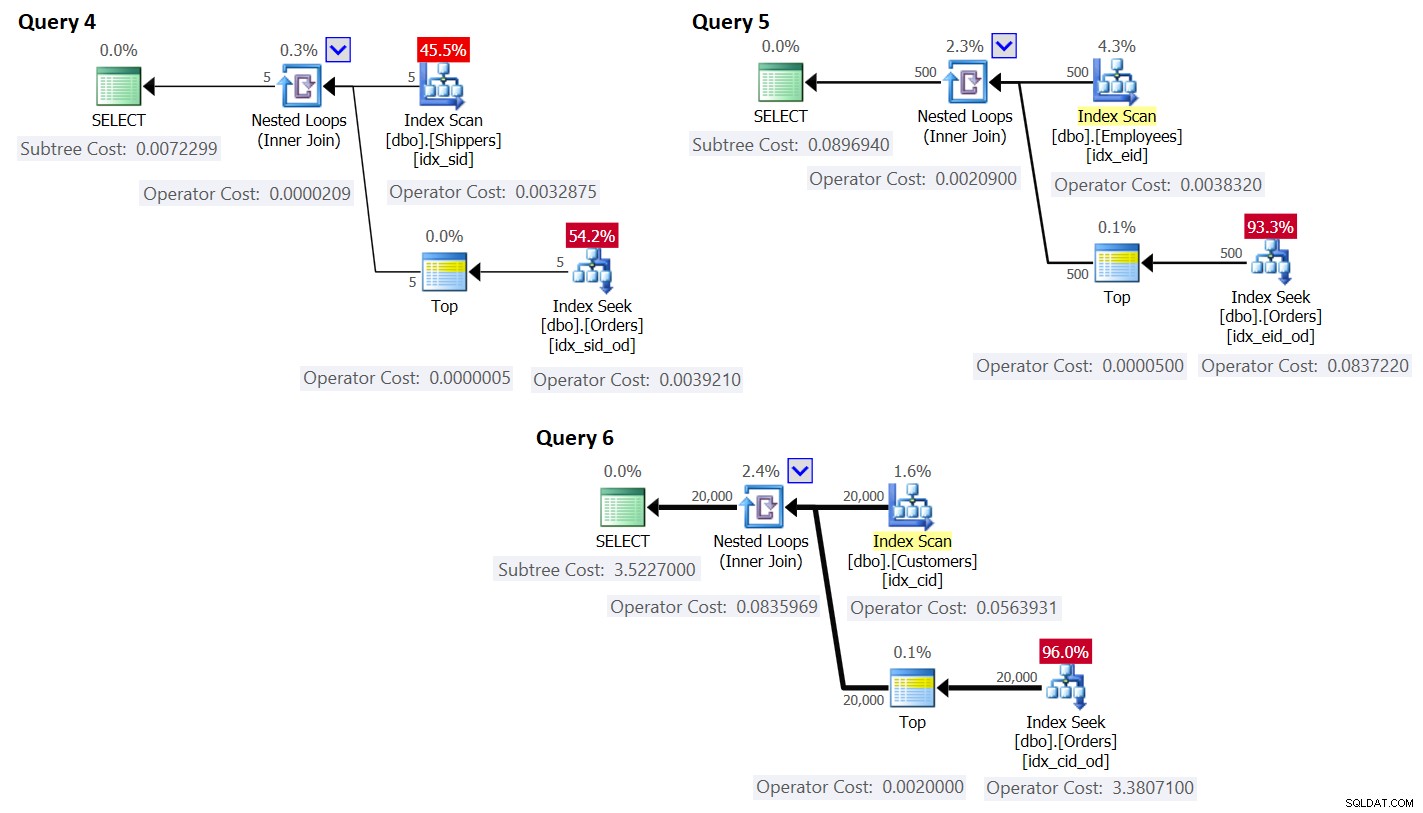 Figure 3 :Plans pour requêtes avec réécriture
Figure 3 :Plans pour requêtes avec réécriture
Comme vous pouvez le voir, les groupes sont obtenus en parcourant l'index sur la table des groupes, et l'agrégat est obtenu en appliquant une recherche dans l'index sur la table principale. Plus la densité de l'ensemble de regroupement est élevée, plus ce plan est optimal par rapport à la stratégie par défaut pour la requête groupée.
Tout comme nous l'avons fait précédemment pour la stratégie d'analyse par défaut, estimons le nombre de lectures logiques et planifions le coût de la stratégie de recherche. Le nombre estimé de lectures logiques correspond au nombre de lectures pour l'exécution unique de l'opérateur Index Scan qui récupère les groupes, plus les lectures pour toutes les exécutions de l'opérateur Index Seek.
Le nombre estimé de lectures logiques pour l'opérateur Index Scan est négligeable par rapport aux recherches; encore, c'est CEILING (1e0 * @numgroups / @rowsperpage). Prenez la requête 4 comme exemple; disons que l'index idx_sid correspond à environ 600 lignes par page feuille (le nombre réel dépend des valeurs réelles du shipperid puisque le type de données est VARCHAR(5)). Avec 5 groupes, toutes les lignes tiennent dans une seule feuille. Si vous aviez 5 000 groupes, ils tiendraient sur 9 pages.
Le nombre estimé de lectures logiques pour toutes les exécutions de l'opérateur Index Seek est @numgroups * @indexdepth. La profondeur de l'index peut être calculée comme :
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
En utilisant la requête 4 comme exemple, disons que nous pouvons contenir environ 404 lignes par page feuille de l'index idx_sid_od et environ 352 lignes par page non feuille. Encore une fois, les nombres réels dépendront des valeurs réelles stockées dans la colonne shipperid puisque son type de données est VARCHAR(5)). Pour les estimations, n'oubliez pas que vous pouvez utiliser les calculs décrits ici. Avec de bons exemples de données représentatifs disponibles, vous pouvez utiliser la requête suivante pour déterminer le nombre de lignes pouvant tenir dans les pages feuilles et non feuilles de l'index donné :
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; J'ai obtenu le résultat suivant :
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
Avec ces nombres, la profondeur de l'index par rapport au nombre de lignes de la table est :
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Avec 1 000 000 de lignes dans la table, cela donne une profondeur d'index de 3. À environ 50 millions de lignes, la profondeur de l'index passe à 4 niveaux, et à environ 17,62 milliards de lignes, elle passe à 5 niveaux.
Quoi qu'il en soit, en ce qui concerne le nombre de groupes et le nombre de lignes, en supposant les nombres de lignes par page ci-dessus, la formule suivante calcule le nombre estimé de lectures logiques pour la requête 4 :
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Par exemple, avec 5 groupes et 1 000 000 lignes, vous n'obtenez que 16 lectures au total ! Rappelez-vous que la stratégie par défaut basée sur l'analyse pour la requête groupée implique autant de lectures logiques que CEILING(1e0 * @numrows / @rowsperpage). En utilisant la requête 1 comme exemple, et en supposant environ 404 lignes par page feuille de l'index idx_sid_od, avec le même nombre de lignes de 1 000 000, vous obtenez environ 2 476 lectures. Augmentez le nombre de lignes dans la table d'un facteur de 1 000 à 1 000 000 000, mais conservez le nombre de groupes fixe. Le nombre de lectures requises avec la stratégie de recherche change très peu à 21, alors que le nombre de lectures requises avec la stratégie d'analyse augmente linéairement à 2 475 248.
La beauté de la stratégie de recherche est que tant que le nombre de groupes est petit et fixe, il a une mise à l'échelle presque constante par rapport au nombre de lignes dans la table. En effet, le nombre de recherches est déterminé par le nombre de groupes et la profondeur de l'index est liée au nombre de lignes dans la table de manière logarithmique, où la base du journal est le nombre de lignes qui tiennent dans une page non-feuille. À l'inverse, la stratégie basée sur l'analyse a une mise à l'échelle linéaire par rapport au nombre de lignes impliquées.
La figure 4 montre le nombre de lectures estimé pour les deux stratégies, appliquées par la requête 1 et la requête 4, étant donné un nombre fixe de groupes de 5 et différents nombres de lignes dans la table principale.
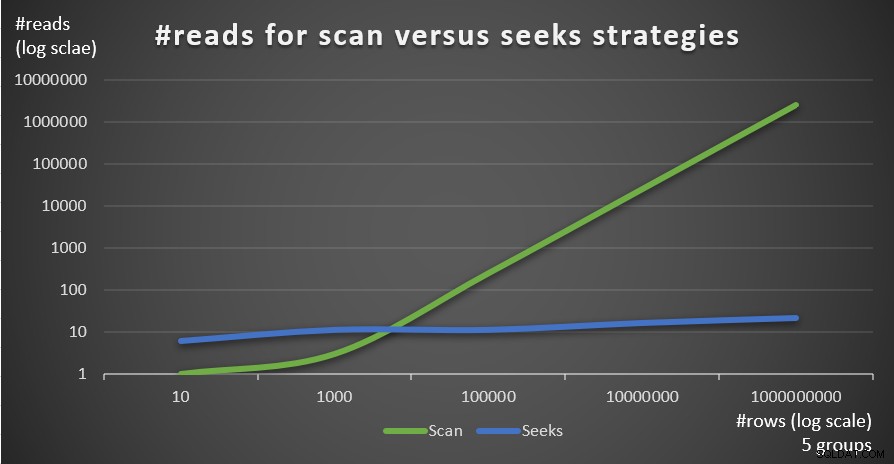 Figure 4 : #lectures pour les stratégies de balayage et de recherche (5 groupes)
Figure 4 : #lectures pour les stratégies de balayage et de recherche (5 groupes)
La figure 5 montre le nombre de lectures estimé pour les deux stratégies, étant donné un nombre fixe de lignes de 1 000 000 dans le tableau principal et un nombre différent de groupes.
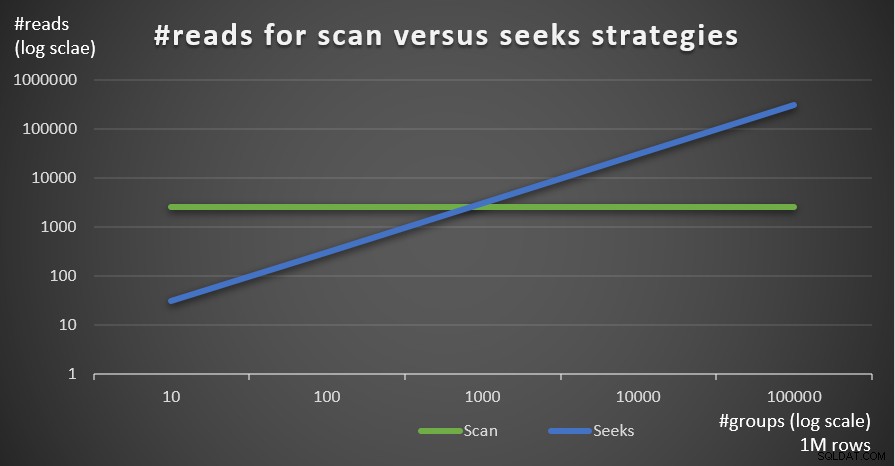 Figure 5 :#lectures pour les stratégies d'analyse et de recherche (1 million de lignes)
Figure 5 :#lectures pour les stratégies d'analyse et de recherche (1 million de lignes)
Vous pouvez très clairement voir que plus la densité de l'ensemble de regroupement est élevée (plus petit nombre de groupes) et plus la table principale est grande, plus la stratégie de recherche est préférée en termes de nombre de lectures. Si vous vous interrogez sur le modèle d'E/S utilisé par chaque stratégie ; bien sûr, les opérations de recherche d'index effectuent des E/S aléatoires, alors qu'une opération de balayage d'index effectue des E/S séquentielles. Pourtant, il est assez clair quelle stratégie est la plus optimale dans les cas les plus extrêmes.
En ce qui concerne le coût du plan de requête, encore une fois, en utilisant le plan de la requête 4 de la figure 3 comme exemple, décomposons-le en opérateurs individuels dans le plan.
La formule de rétro-ingénierie pour le coût de l'opérateur Index Scan est :
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
Dans notre cas, avec 5 groupes, qui tiennent tous sur une seule page, le coût est :
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
Le coût indiqué dans le plan est le même.
Comme auparavant, vous pouvez estimer le nombre de pages au niveau feuille de l'index en fonction du nombre estimé de lignes par page à l'aide de la formule CEILING(1e0 * @numrows / @rowsperpage), qui dans notre cas est CEILING(1e0 * @ numgroups / @groupsperpage). Supposons que l'index idx_sid corresponde à environ 600 lignes par page feuille, avec 5 groupes dont vous auriez besoin pour lire une page. Quoi qu'il en soit, la formule de coût de l'opérateur Index Scan devient alors :
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
La formule de calcul des coûts de rétro-ingénierie pour l'opérateur Nested Loops est :
@executions * 0.00000418
Dans notre cas, cela se traduit par :
@numgroups * 0.00000418
Pour la requête 4, avec 5 groupes, vous obtenez :
5 * 0.00000418 = 0.0000209
Le coût indiqué dans le plan est le même.
La formule de calcul des coûts de rétro-ingénierie pour l'opérateur Top est :
@executions * @toprows * 0.00000001
Dans notre cas, cela se traduit par :
@numgroups * 1 * 0.00000001
Avec 5 groupes, vous obtenez :
5 * 0.0000001 = 0.0000005
Le coût indiqué dans le plan est le même.
Quant à l'opérateur Index Seek, ici j'ai reçu une grande aide de Paul White; Merci mon ami! Le calcul est différent pour la première exécution et pour les rebinds (exécutions non premières qui ne réutilisent pas le résultat de l'exécution précédente). Comme nous l'avons fait avec l'opérateur Index Scan, commençons par identifier les constantes du modèle de coût :
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Pour une exécution, sans objectif de ligne appliqué, les coûts d'E/S et de CPU sont :
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
Puisque nous utilisons TOP (1), nous n'avons qu'une seule page et une seule ligne impliquées, donc les coûts sont :
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
Ainsi, le coût de la première exécution de l'opérateur Index Seek dans notre cas est :
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
Quant au coût des reliures, comme d'habitude, il est composé de coûts CPU et d'E/S. Appelons-les respectivement @rebindcpu et @rebindio. Avec la requête 4, ayant 5 groupes, nous avons 4 rebinds (appelez-le @rebinds). Le coût @rebindcpu est la partie facile. La formule est :
@rebindcpu = @rebinds * (@cpubase + @cpurow)
Dans notre cas, cela se traduit par :
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
La partie @rebindio est légèrement plus complexe. Ici, la formule de calcul des coûts calcule, statistiquement, le nombre prévu de pages distinctes que les reliures sont censées lire en utilisant l'échantillonnage avec remplacement. Nous appellerons cet élément @pswr (pour les pages distinctes échantillonnées avec remplacement). L'idée est que nous avons @indexdatapages nombre de pages dans l'index (dans notre cas, 2 473) et @rebinds nombre de reliures (dans notre cas, 4). En supposant que nous ayons la même probabilité de lire une page donnée avec chaque reliure, combien de pages distinctes devrions-nous lire au total ? Cela équivaut à avoir un sac avec 2 473 balles et à tirer quatre fois aveuglément une balle du sac puis à la remettre dans le sac. Statistiquement, combien de balles distinctes comptez-vous tirer au total ? La formule pour cela, en utilisant nos opérandes, est :
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
Avec nos numéros, vous obtenez :
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
Ensuite, vous calculez le nombre de lignes et de pages que vous avez en moyenne par groupe :
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
Dans notre requête 4, la cardinalité est de 1 000 000 et la densité est de 1/5 =0,2. Ainsi, vous obtenez :
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
Ensuite, vous calculez le coût des E/S sans filtrage (appelez-le @io) comme :
@io = @randomio + (@seqio * (@grouppages - 1e0))
Dans notre cas, vous obtenez :
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
Et enfin, puisque la recherche extrait une seule ligne dans chaque rebind, vous calculez @rebindio en utilisant la formule suivante :
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
Dans notre cas, vous obtenez :
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
Enfin, le coût de l'opérateur est :
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
C'est le même que le coût de l'opérateur Index Seek indiqué dans le plan pour la requête 4.
Vous pouvez maintenant agréger les coûts de tous les opérateurs pour obtenir le coût complet du plan de requête. Vous obtenez :
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Après simplification, vous obtenez la formule de coût complète suivante pour notre stratégie Seeks :
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) À titre d'exemple, en utilisant T-SQL, voici le calcul du coût du plan de requête avec notre stratégie Seeks pour la requête 4 :
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; Ce calcul calcule le coût de 0,0072295 pour la requête 4. Le coût estimé illustré à la figure 3 est de 0,0072299. C'est assez proche ! À titre d'exercice, calculez les coûts des requêtes 5 et 6 à l'aide de cette formule et vérifiez que vous obtenez des chiffres proches de ceux indiqués dans la figure 3.
Rappelez-vous que la formule de calcul des coûts pour la stratégie par défaut basée sur l'analyse est (appelez-la Scan stratégie):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
En utilisant la requête 1 comme exemple, et en supposant 1 000 000 de lignes dans le tableau, 404 lignes par page et 5 groupes, le coût estimé du plan de requête de la stratégie d'analyse est de 3,5366.
La figure 6 montre les coûts estimés du plan de requête pour les deux stratégies, appliquées par la requête 1 (analyse) et la requête 4 (recherche), en fonction d'un nombre fixe de groupes de 5 et de différents nombres de lignes dans la table principale.
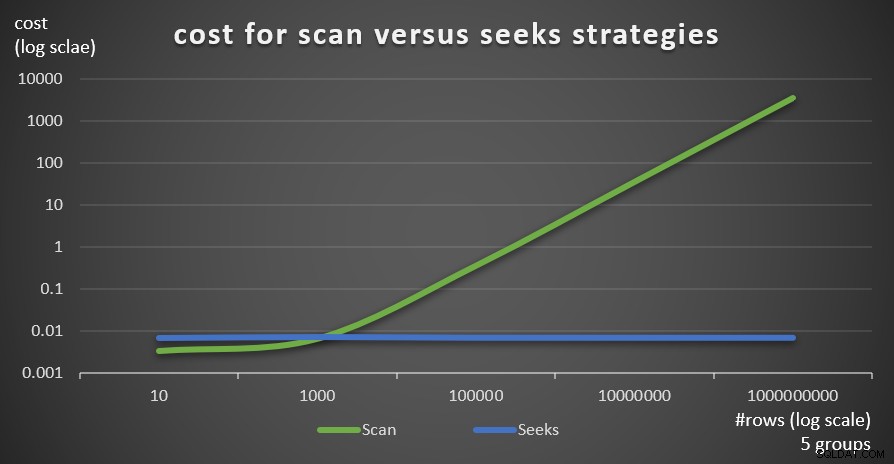 Figure 6 :coût pour stratégies d'analyse et de recherche (5 groupes)
Figure 6 :coût pour stratégies d'analyse et de recherche (5 groupes)
La figure 7 montre les coûts estimés du plan de requête pour les deux stratégies, étant donné un nombre fixe de lignes dans la table principale de 1 000 000 et un nombre différent de groupes.
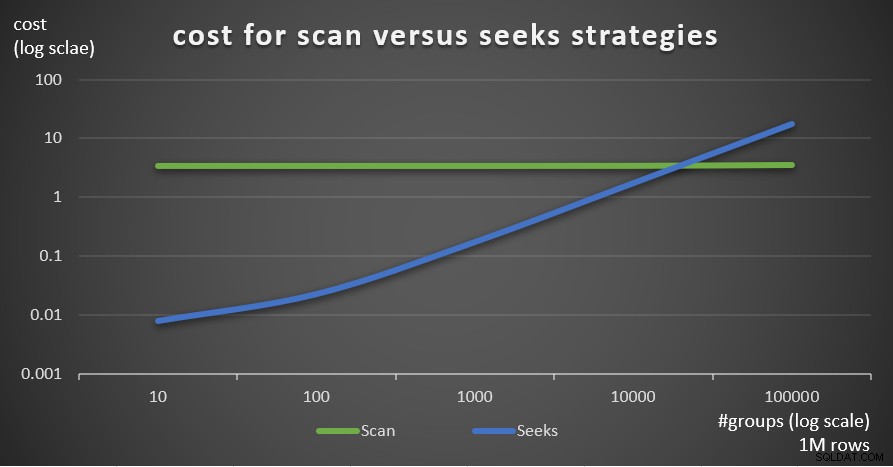 Figure 7 :coût pour stratégies d'analyse et de recherche (1 million de lignes)
Figure 7 :coût pour stratégies d'analyse et de recherche (1 million de lignes)
Comme il ressort de ces résultats, plus la densité de l'ensemble de regroupement est élevée et plus il y a de lignes dans le tableau principal, plus la stratégie de recherche est optimale par rapport à la stratégie d'analyse. Ainsi, dans les scénarios à haute densité, assurez-vous d'essayer la solution basée sur APPLY. En attendant, nous pouvons espérer que Microsoft ajoutera cette stratégie en tant qu'option intégrée pour les requêtes groupées.
Conclusion
Cet article conclut une série en cinq parties sur les seuils d'optimisation des requêtes pour les requêtes qui regroupent et agrègent des données. L'un des objectifs de la série était de discuter des spécificités des différents algorithmes que l'optimiseur peut utiliser, des conditions dans lesquelles chaque algorithme est préféré et du moment où vous devez intervenir avec vos propres réécritures de requêtes. Un autre objectif était d'expliquer le processus de découverte des différentes options et de les comparer. De toute évidence, le même processus d'analyse peut être appliqué au filtrage, à la jointure, au fenêtrage et à de nombreux autres aspects de l'optimisation des requêtes. J'espère que vous vous sentez maintenant mieux équipé qu'auparavant pour gérer le réglage des requêtes.