En ce qui concerne les performances des requêtes, il existe de nombreuses sources d'informations intéressantes dans SQL Server, et l'une de mes préférées est le plan de requête lui-même. Dans les dernières versions, notamment à partir de SQL Server 2012, chaque nouvelle version a inclus plus de détails dans les plans d'exécution. Alors que la liste des améliorations continue de s'allonger, voici quelques attributs que j'ai trouvés précieux :
- NonParallelPlanReason (SQL Server 2012)
- Diagnostics de refoulement de prédicat résiduel (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- diagnostics de déversement tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Indicateurs de trace activés (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistiques d'exécution des requêtes de l'opérateur (SQL Server 2014 SP2, SQL Server 2016)
- Mémoire maximale activée pour une seule requête (SQL Server 2014 SP2, SQL Server 2016 SP1)
Pour voir ce qui existe pour chaque version de SQL Server, visitez la page Showplan Schema, où vous pouvez trouver le schéma pour chaque version depuis SQL Server 2005.
Bien que j'aime toutes ces données supplémentaires, il est important de noter que certaines informations sont plus pertinentes pour un plan d'exécution réel, par rapport à une estimation (par exemple, les informations de déversement de tempdb). Certains jours, nous pouvons capturer et utiliser le plan réel pour le dépannage, d'autres fois, nous devons utiliser le plan estimé. Très souvent, nous obtenons ce plan estimé - le plan qui a été utilisé pour des exécutions potentiellement problématiques - à partir du cache de plan de SQL Server. Et l'extraction de plans individuels est appropriée lors du réglage d'une requête, d'un ensemble ou de requêtes spécifiques. Mais qu'en est-il lorsque vous voulez des idées sur où concentrer vos efforts de réglage en termes de modèles ?
Le cache du plan SQL Server est une source prodigieuse d'informations en matière de réglage des performances, et je ne parle pas simplement de dépannage et d'essayer de comprendre ce qui s'exécute dans un système. Dans ce cas, je parle des informations d'extraction des plans eux-mêmes, qui se trouvent dans sys.dm_exec_query_plan, stocké au format XML dans la colonne query_plan.
Lorsque vous combinez ces données avec des informations de sys.dm_exec_sql_text (afin que vous puissiez facilement afficher le texte de la requête) et sys.dm_exec_query_stats (statistiques d'exécution), vous pouvez soudainement commencer à rechercher non seulement les requêtes qui frappent le plus ou exécutent le plus souvent, mais les plans qui contiennent un type de jointure particulier, ou une analyse d'index, ou ceux qui ont le coût le plus élevé. Ceci est communément appelé extraire le cache du plan, et plusieurs articles de blog expliquent comment procéder. Mon collègue, Jonathan Kehayias, dit qu'il déteste écrire du XML, mais il a plusieurs messages avec des requêtes pour extraire le cache du plan :
- Réglage du "seuil de coût pour le parallélisme" à partir du plan cache
- Rechercher des conversions de colonnes implicites dans le cache du plan
- Rechercher quelles requêtes dans le cache du plan utilisent un index spécifique
- Explorer le cache du plan SQL :trouver les index manquants
- Rechercher des recherches de clé dans le cache du plan
Si vous n'avez jamais exploré le contenu de votre cache de plan, les requêtes de ces articles sont un bon début. Cependant, le cache de plan a ses limites. Par exemple, il est possible d'exécuter une requête et de ne pas mettre le plan en cache. Si vous avez activé l'option d'optimisation pour les charges de travail ad hoc, par exemple, lors de la première exécution, le stub de plan compilé est stocké dans le cache du plan, et non le plan compilé complet. Mais le plus gros défi est que le cache du plan est temporaire. Il existe de nombreux événements dans SQL Server qui peuvent effacer entièrement le cache du plan ou l'effacer pour une base de données, et les plans peuvent être vieillis hors du cache s'ils ne sont pas utilisés, ou supprimés après une recompilation. Pour lutter contre cela, vous devez généralement interroger régulièrement le cache du plan ou créer un instantané du contenu d'une table de manière planifiée.
Cela change dans SQL Server 2016 avec Query Store.
Lorsqu'une base de données utilisateur a activé le magasin de requêtes, le texte et les plans des requêtes exécutées sur cette base de données sont capturés et conservés dans des tables internes. Plutôt qu'une vue temporaire de ce qui est en cours d'exécution, nous avons une image à long terme de ce qui a déjà été exécuté. La quantité de données conservées est déterminée par le paramètre CLEANUP_POLICY, dont la valeur par défaut est de 30 jours. Par rapport à un cache de plan qui peut ne représenter que quelques heures d'exécution de requêtes, les données du magasin de requêtes changent la donne.
Considérez un scénario dans lequel vous effectuez une analyse d'index - certains index ne sont pas utilisés et vous avez des recommandations à partir des DMV d'index manquants. Les DMV d'index manquants ne fournissent aucun détail sur la requête qui a généré la recommandation d'index manquant. Vous pouvez interroger le cache du plan à l'aide de la requête de l'article Trouver les index manquants de Jonathan. Si j'exécute cela sur mon instance SQL Server locale, j'obtiens quelques lignes de sortie liées à certaines requêtes que j'ai exécutées précédemment.

Je peux ouvrir le plan dans Plan Explorer et je vois qu'il y a un avertissement sur l'opérateur SELECT, qui concerne l'index manquant :
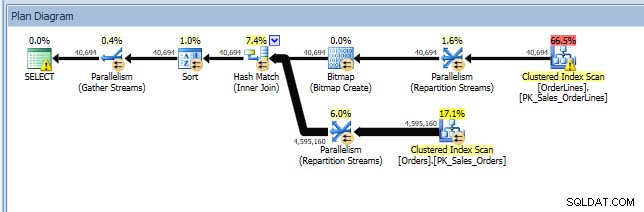
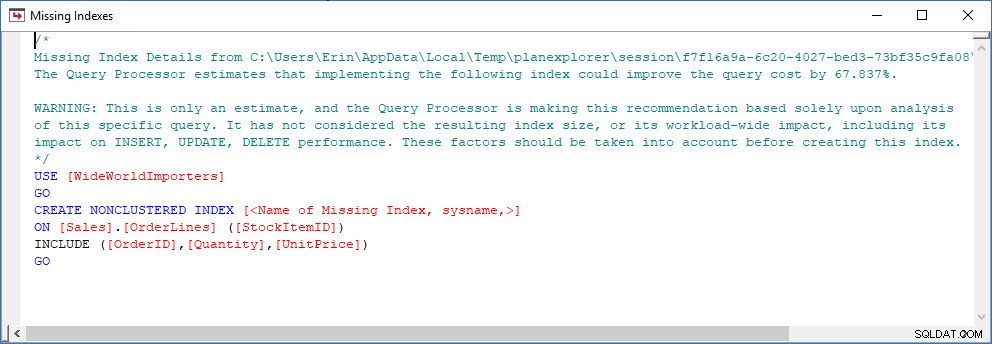
C'est un bon début, mais encore une fois, ma sortie dépend de tout ce qui se trouve dans le cache. Je peux prendre la requête de Jonathan et la modifier pour Query Store, puis l'exécuter sur ma base de données de démonstration WideWorldImporters :
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
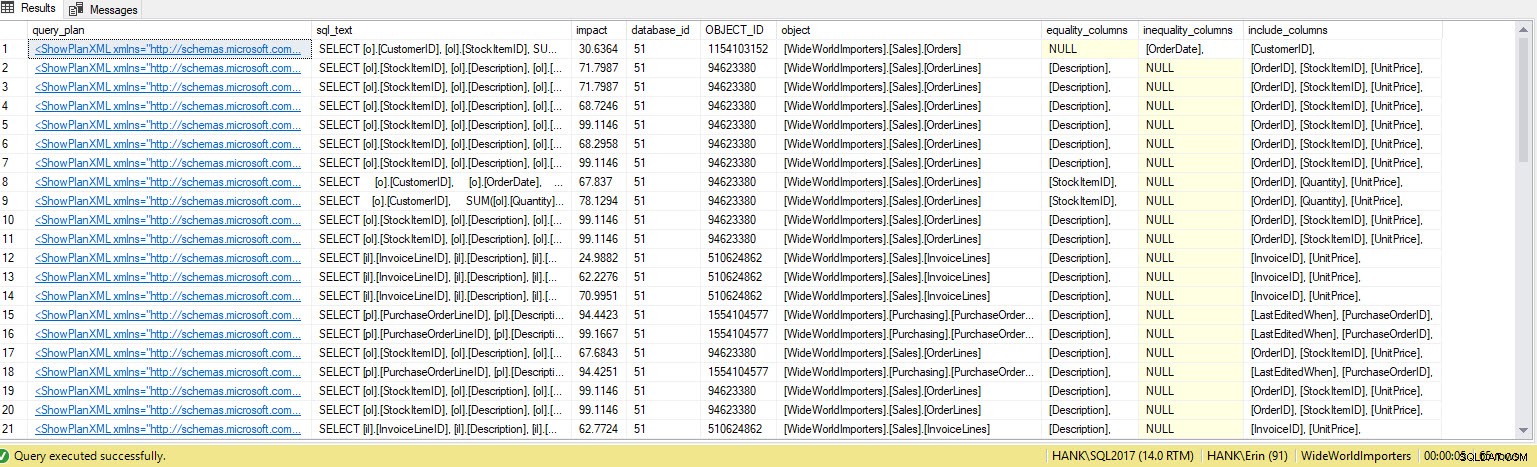
Je reçois beaucoup plus de lignes dans la sortie. Encore une fois, les données du magasin de requêtes représentent une vue plus large des requêtes exécutées sur le système, et l'utilisation de ces données nous donne une méthode complète pour déterminer non seulement quels index manquent, mais quelles requêtes ces index prendraient en charge. À partir de là, nous pouvons creuser plus profondément dans Query Store et examiner les mesures de performances et la fréquence d'exécution pour comprendre l'impact de la création de l'index et décider si la requête s'exécute assez souvent pour justifier l'index.
Si vous n'utilisez pas Query Store, mais que vous utilisez SentryOne, vous pouvez extraire ces mêmes informations de la base de données SentryOne. Le plan de requête est stocké dans la table dbo.PerformanceAnalysisPlan dans un format compressé. La requête que nous utilisons est donc une variante similaire à celle ci-dessus, mais vous remarquerez que la fonction DECOMPRESS est également utilisée :
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Sur un système SentryOne, j'ai eu la sortie suivante (et bien sûr, cliquer sur l'une des valeurs de query_plan ouvrira le plan graphique) :

Quelques avantages offerts par SentryOne par rapport à Query Store sont que vous n'avez pas besoin d'activer ce type de collection par base de données, et la base de données surveillée n'a pas à prendre en charge les exigences de stockage, puisque toutes les données sont stockées dans le référentiel. Vous pouvez également capturer ces informations sur toutes les versions prises en charge de SQL Server, pas seulement celles qui prennent en charge le magasin de requêtes. Notez cependant que SentryOne ne collecte que les requêtes qui dépassent des seuils tels que la durée et les lectures. Vous pouvez modifier ces seuils par défaut, mais c'est un élément à prendre en compte lors de l'exploration de la base de données SentryOne :toutes les requêtes ne peuvent pas être collectées. De plus, la fonction DECOMPRESS n'est pas disponible avant SQL Server 2016; pour les anciennes versions de SQL Server, vous souhaiterez soit :
- Sauvegardez la base de données SentryOne et restaurez-la sur SQL Server 2016 ou supérieur pour exécuter les requêtes ;
- bcp les données hors de la table dbo.PerformanceAnalysisPlan et importez-les dans une nouvelle table sur une instance SQL Server 2016 ;
- interroger la base de données SentryOne via un serveur lié à partir d'une instance SQL Server 2016 ; ou,
- interroger la base de données à partir du code de l'application qui peut analyser des éléments spécifiques après la décompression.
Avec SentryOne, vous avez la possibilité d'exploiter non seulement le cache du plan, mais également les données conservées dans le référentiel SentryOne. Si vous exécutez SQL Server 2016 ou une version ultérieure et que le magasin de requêtes est activé, vous pouvez également trouver ces informations dans sys.query_store_plan . Vous n'êtes pas limité à cet exemple de recherche d'index manquants ; toutes les requêtes des autres messages de cache de plan de Jonathan peuvent être modifiées pour être utilisées pour extraire des données de SentryOne ou de Query Store. De plus, si vous êtes suffisamment familiarisé avec XQuery (ou si vous souhaitez apprendre), vous pouvez utiliser le schéma Showplan pour comprendre comment analyser le plan pour trouver les informations souhaitées. Cela vous donne la possibilité de trouver des modèles et des anti-modèles dans vos plans de requête que votre équipe peut corriger avant qu'ils ne deviennent un problème.