Dans un plan de reprise après sinistre, votre objectif de point de récupération (RPO) est un paramètre de récupération clé qui dicte la quantité de données que vous pouvez vous permettre de perdre. Le RPO est répertorié dans le temps, de quelques secondes à plusieurs jours. En effet, le RPO dépend directement de votre système de sauvegarde. Il marque l'âge de vos données de sauvegarde que vous devez récupérer afin de reprendre les opérations normales.
Si vous faites une sauvegarde nocturne à 22 h. et votre système de base de données tombe en panne irréparable à 15 heures. le lendemain, vous perdez tout ce qui a été modifié depuis votre dernière sauvegarde. Votre RPO dans ce contexte particulier est la sauvegarde de la veille, ce qui signifie que vous pouvez vous permettre de perdre l'équivalent d'une journée de modifications.
Le schéma ci-dessous de notre livre blanc sur la reprise après sinistre illustre le concept.
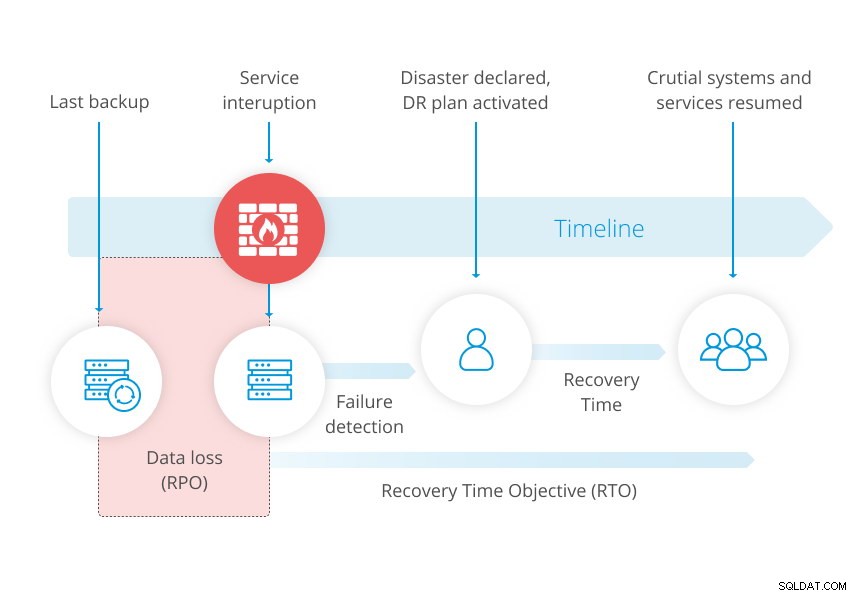
Pour un RPO plus serré, une sauvegarde peut cependant ne pas suffire. Lors de la sauvegarde de votre base de données, vous prenez en fait un instantané des données à un moment donné. Ainsi, lorsque vous restaurez une sauvegarde, vous manquerez les modifications qui se sont produites entre la dernière sauvegarde et l'échec.
C'est là qu'intervient le concept de Point In Time Recovery (PITR).
Qu'est-ce que le PITR ?
Point In Time Recovery (PITR), comme son nom l'indique, consiste à restaurer la base de données à un moment donné dans le passé. Pour pouvoir le faire, nous devrons restaurer une sauvegarde, puis appliquer toutes les modifications qui se sont produites après la sauvegarde jusqu'à juste avant l'échec.
Pour PostgreSQL, les modifications sont stockées dans les journaux WAL (pour plus de détails sur les WAL et les données qu'ils stockent, vous pouvez consulter ce blog).
Il y a donc deux choses dont nous devons nous assurer pour pouvoir effectuer un PITR :les sauvegardes et les WAL (nous devons leur mettre en place un archivage continu).
Pour effectuer le PITR, nous devrons récupérer la sauvegarde puis appliquer les WAL.
Quand cela pourrait-il être utile ?
Vous pouvez utiliser cette stratégie chaque fois que vous restaurez à partir d'un problème qui a causé la corruption des données. Vous devez garder à l'esprit que vous essayez de minimiser la perte de données, mais certains problèmes peuvent rendre les données inutiles par la suite.
Quelques exemples de cela peuvent être des modifications de données non planifiées (DML ou DDL), une panne de support ou des maintenances de base de données (comme des mises à niveau) qui entraînent une corruption des données. Vous ne pourrez pas récupérer les modifications de données qui se sont produites après le problème.
Supposons qu'un utilisateur ait effectué une DML à tort, ce qui fait que les données d'une table entière sont modifiées ou supprimées à tort. Vous pouvez effectuer un PITR de la base de données dans un emplacement séparé, puis exporter le contenu de la table. Vous pouvez ensuite restaurer cette table dans la base de données existante, en revenant ainsi à une copie de l'état de la table avant que le problème ne se produise.
Bien sûr, il n'est pas toujours possible de restaurer uniquement une partie de la base de données de cette manière, donc dans ce cas, vous devrez restaurer toute la base de données à un point donné, et vous aurez une perte de données minime mais inévitable (vous manquerez tous les changements qui se sont produits après le problème).
Comment l'utiliser avec ClusterControl ?
Dans un blog précédent, nous avons pu voir comment implémenter PITR manuellement, voyons maintenant comment utiliser ClusterControl pour effectuer cette tâche.
Activation de la récupération ponctuelle
Pour activer la fonction PITR, nous devons activer l'archivage WAL. Pour cela, nous pouvons aller dans ClusterControl -> Select PostgreSQL Cluster -> Node actions -> Enable WAL Archiving, ou simplement aller dans ClusterControl -> Select PostgreSQL Cluster -> Backup -> Settings et activer l'option "Enable Point-In-Time Recovery". (WAL Archiving)" comme nous le verrons dans l'image suivante.
Nous devons garder à l'esprit que pour activer l'archivage WAL, nous devons redémarrer notre base de données. ClusterControl peut également le faire pour nous.
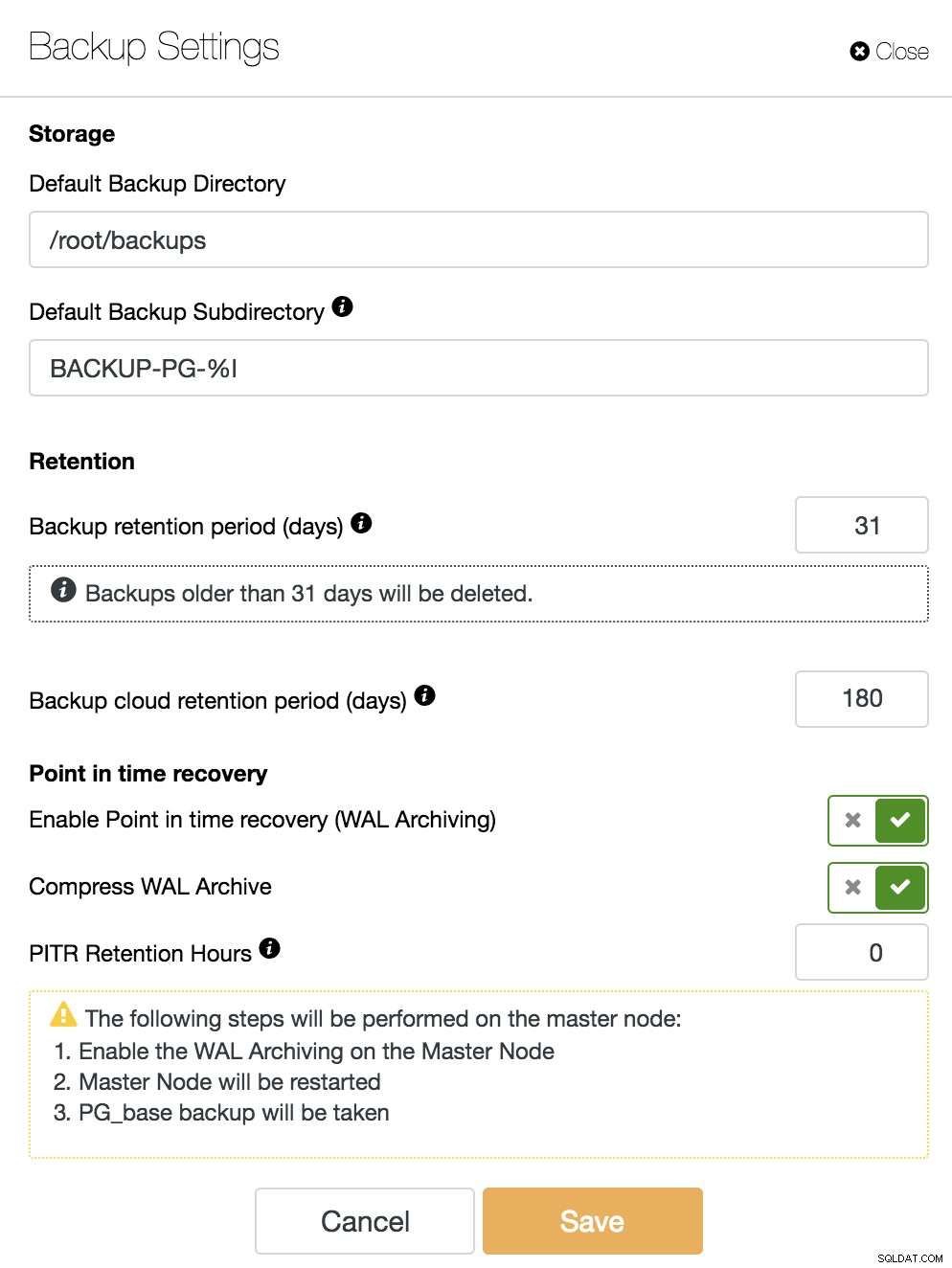
En plus des options communes à toutes les sauvegardes comme le "Répertoire de sauvegarde" et la "Période de rétention de la sauvegarde", nous pouvons également spécifier ici la période de rétention WAL. Par défaut est 0, ce qui signifie pour toujours.
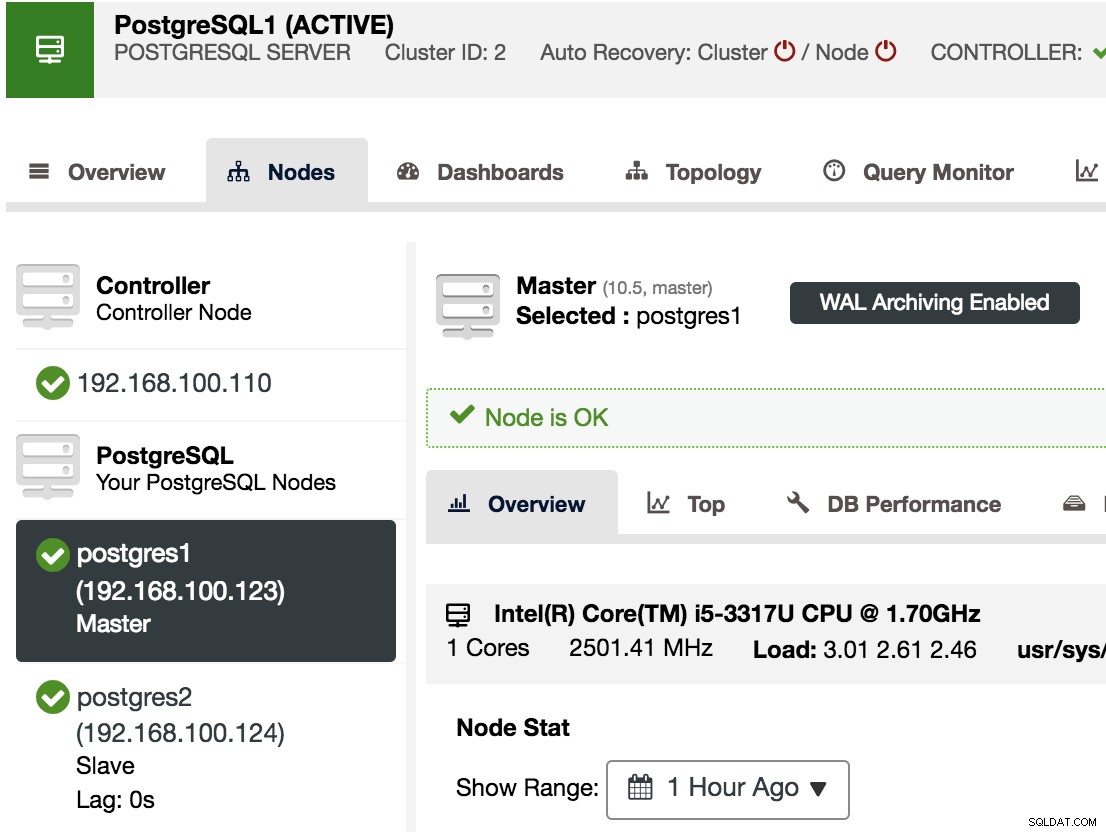
Pour confirmer que nous avons activé l'archivage WAL, nous pouvons sélectionner notre nœud maître dans ClusterControl -> Select PostgreSQL Cluster -> Nodes, et nous devrions voir le message WAL Archiving Enabled, comme nous pouvons le voir dans l'image suivante.
Création d'une sauvegarde compatible avec la récupération ponctuelle
Après avoir activé l'archivage WAL, comme nous l'avons vu à l'étape précédente, nous pouvons créer notre sauvegarde compatible avec PITR. Pour cela, allez dans ClusterControl -> Sélectionnez PostgreSQL Cluster -> Sauvegarde -> Créer une sauvegarde.
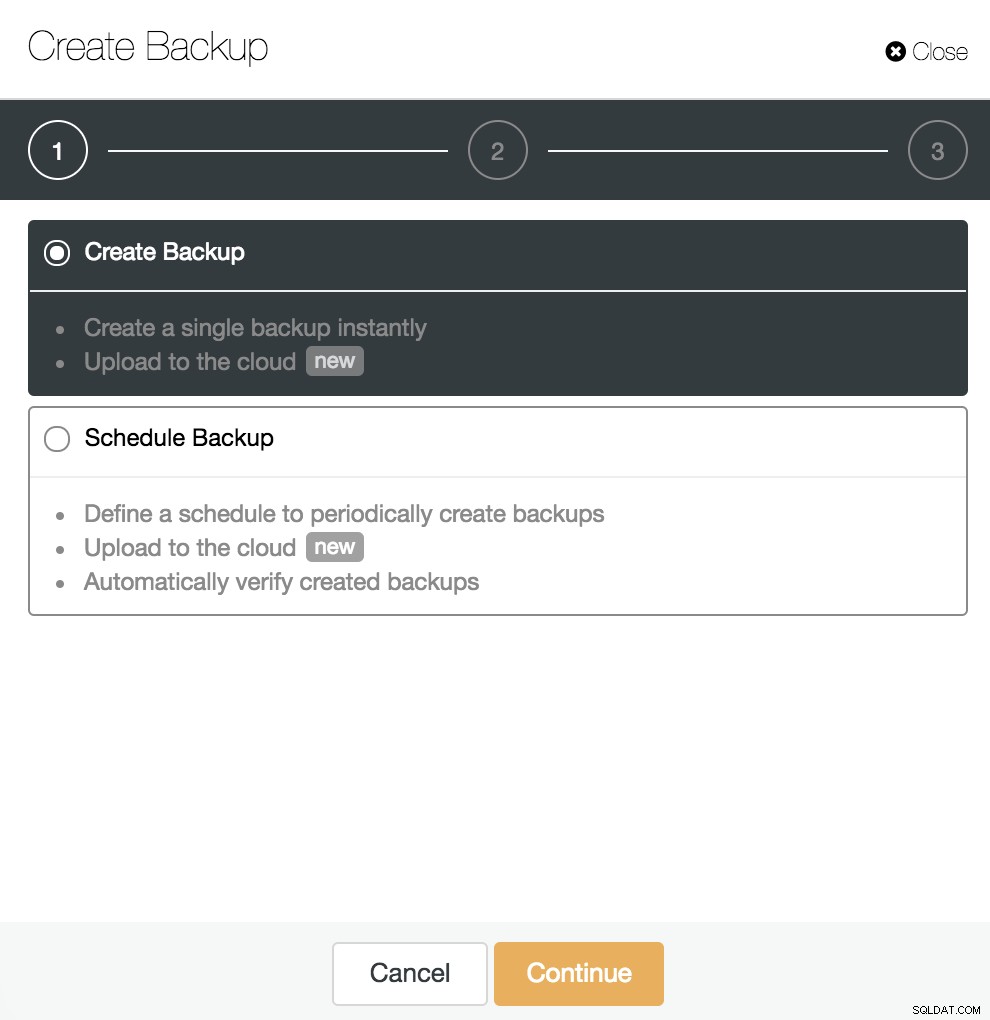
Nous pouvons créer une nouvelle sauvegarde ou en configurer une planifiée. Pour notre exemple, nous allons créer une seule sauvegarde instantanément.
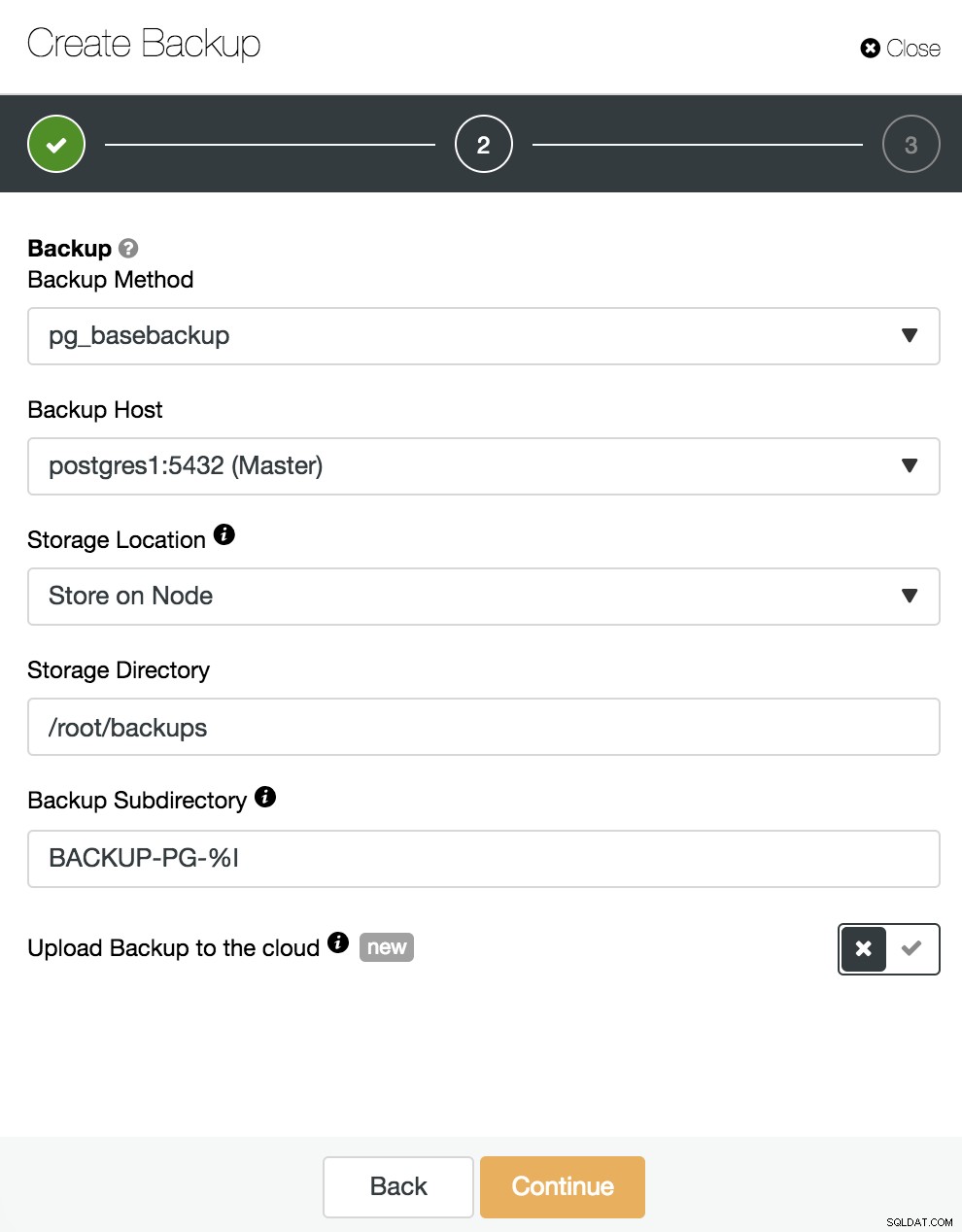
Ici, nous devons choisir la méthode "pg_basebackup", compatible avec PITR, le serveur à partir duquel la sauvegarde sera prise (pour être compatible avec PITR, il doit être le maître), et où nous voulons stocker la sauvegarde. Nous pouvons également télécharger notre sauvegarde sur le cloud (AWS, Google ou Azure) en activant le bouton correspondant.
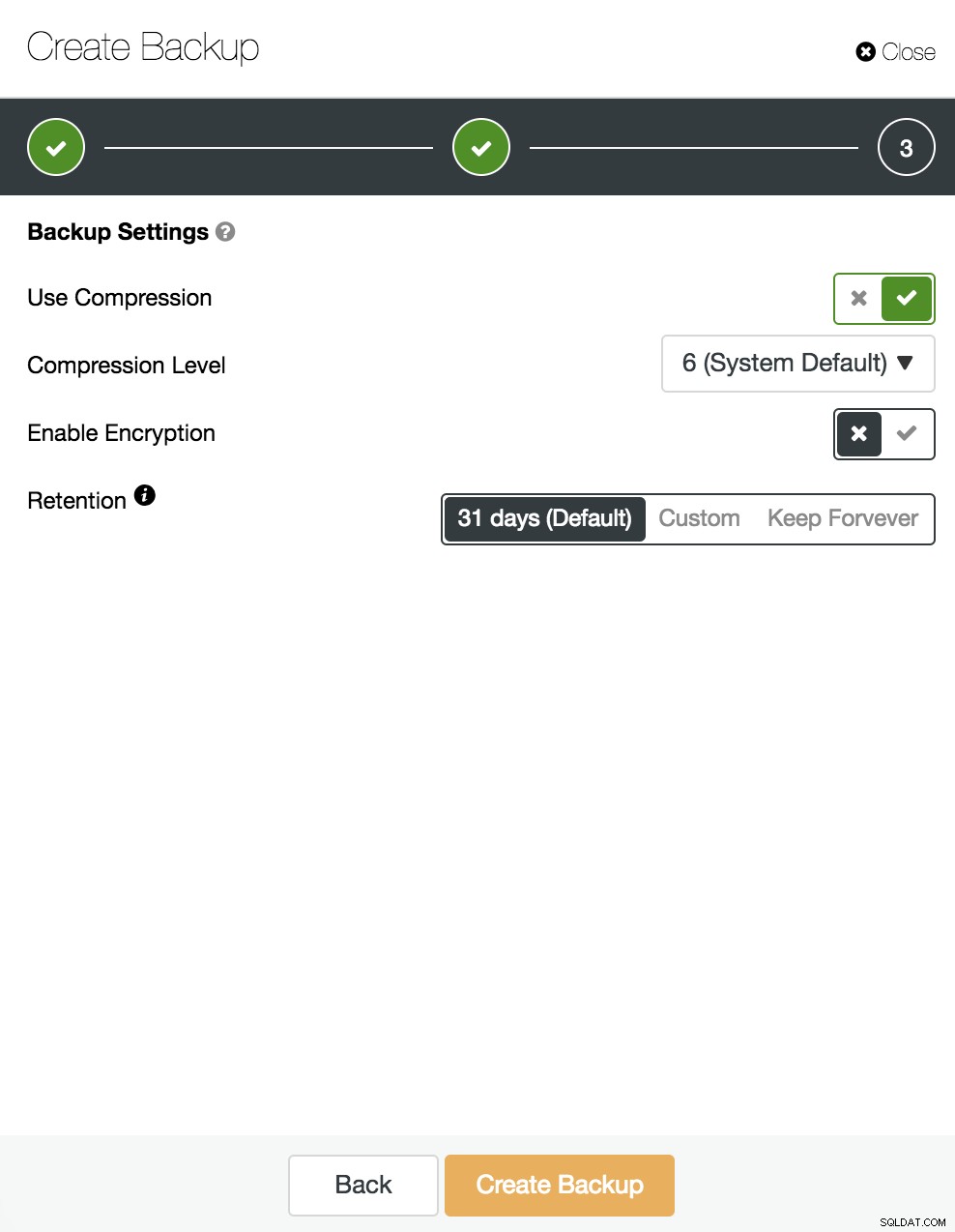
Ensuite, nous spécifions l'utilisation de la compression, du cryptage et de la conservation de notre sauvegarde.
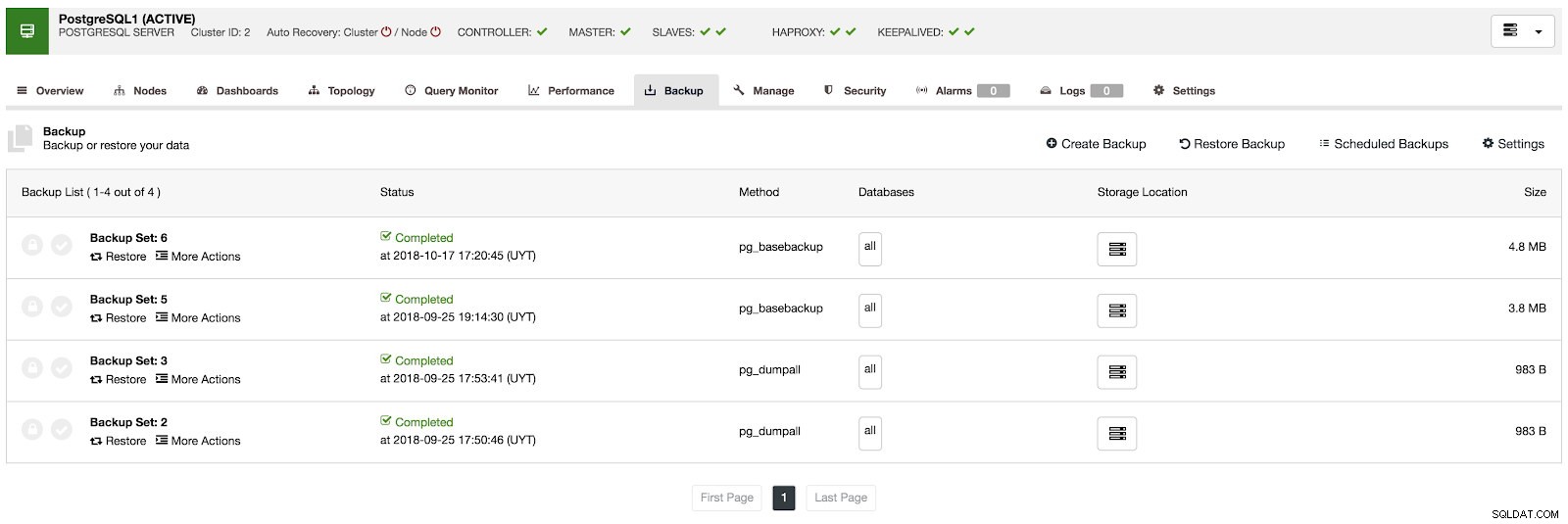
Dans la section de sauvegarde, nous pouvons voir la progression de la sauvegarde et des informations telles que la méthode, la taille, l'emplacement, etc.
Récupération ponctuelle à partir d'une sauvegarde
Une fois la sauvegarde terminée, nous pouvons la restaurer à l'aide de la fonction ClusterControl PITR. Pour cela, dans notre section de sauvegarde (ClusterControl -> Select PostgreSQL Cluster -> Backup), nous pouvons sélectionner "Restaurer la sauvegarde", ou directement "Restaurer" sur la sauvegarde que nous voulons restaurer.
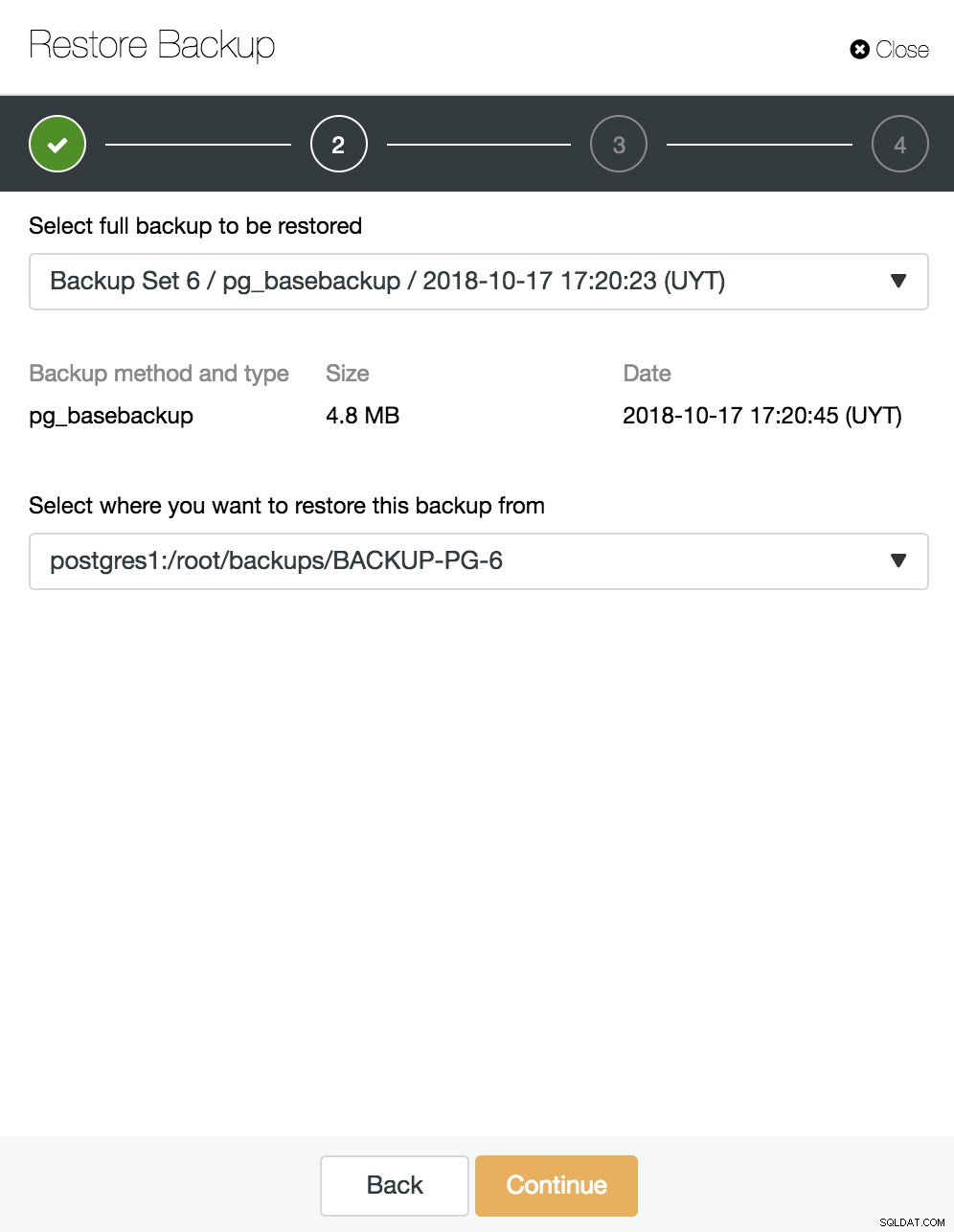
Ici, nous choisissons quelle sauvegarde nous voulons restaurer et à partir de quel répertoire.
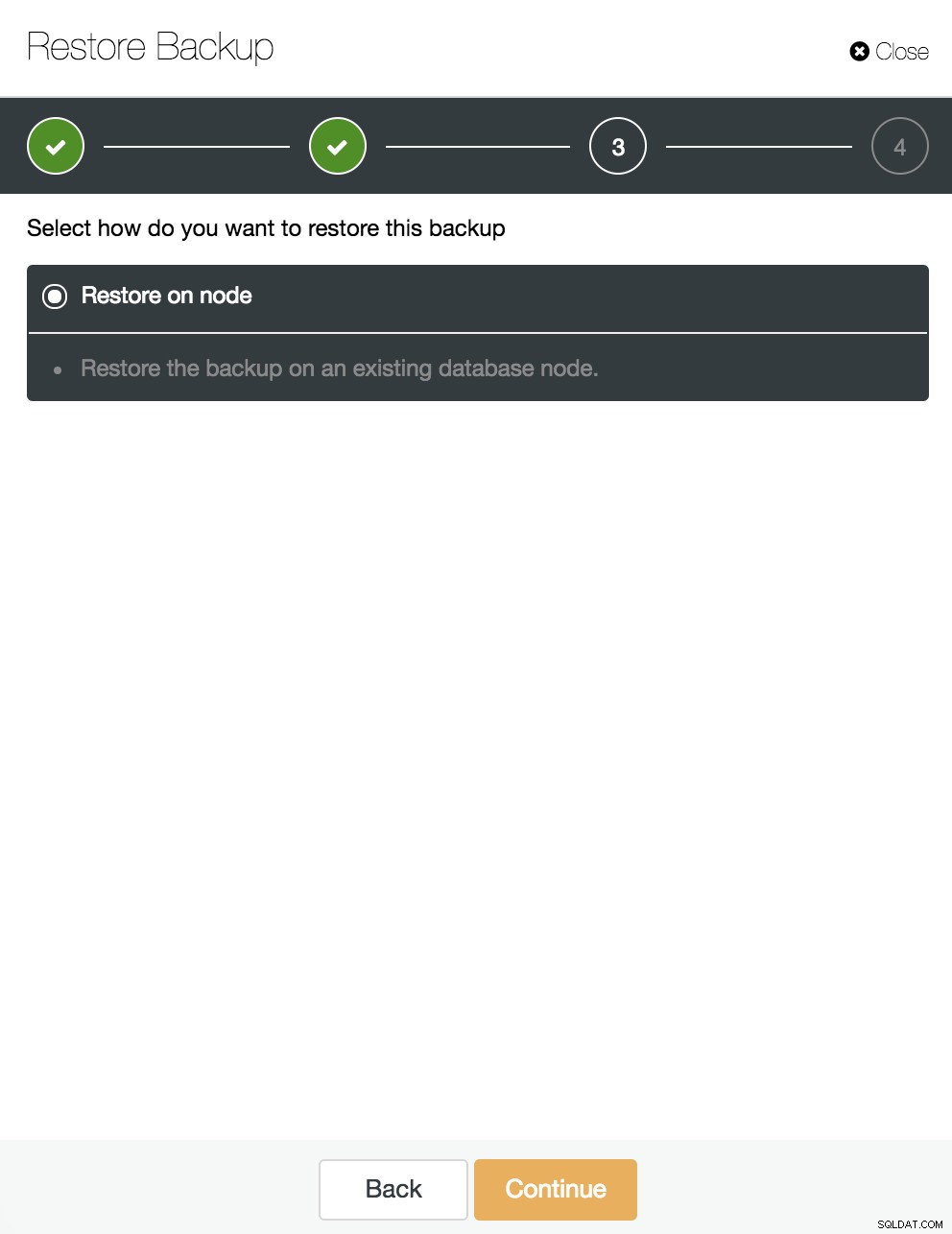
Nous laissons l'option "Restaurer sur le nœud" sélectionnée et continuons.
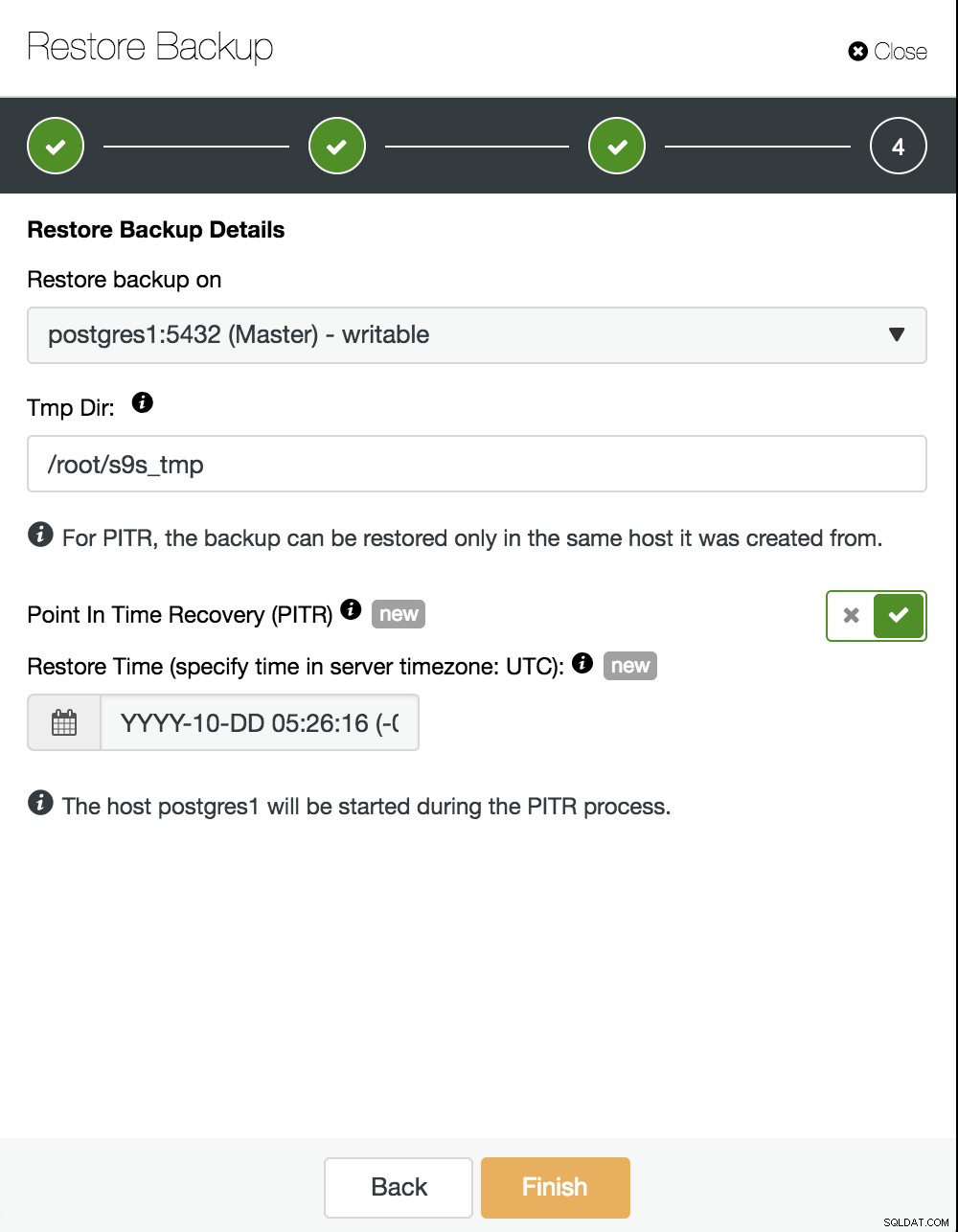
Nous devons maintenant choisir où restaurer notre sauvegarde et activer l'option PITR. En spécifiant l'heure, ce sera l'heure jusqu'à laquelle nous récupérerons. Tenez compte du fait que le fuseau horaire UTC est utilisé et que notre service PostgreSQL dans le maître sera redémarré.
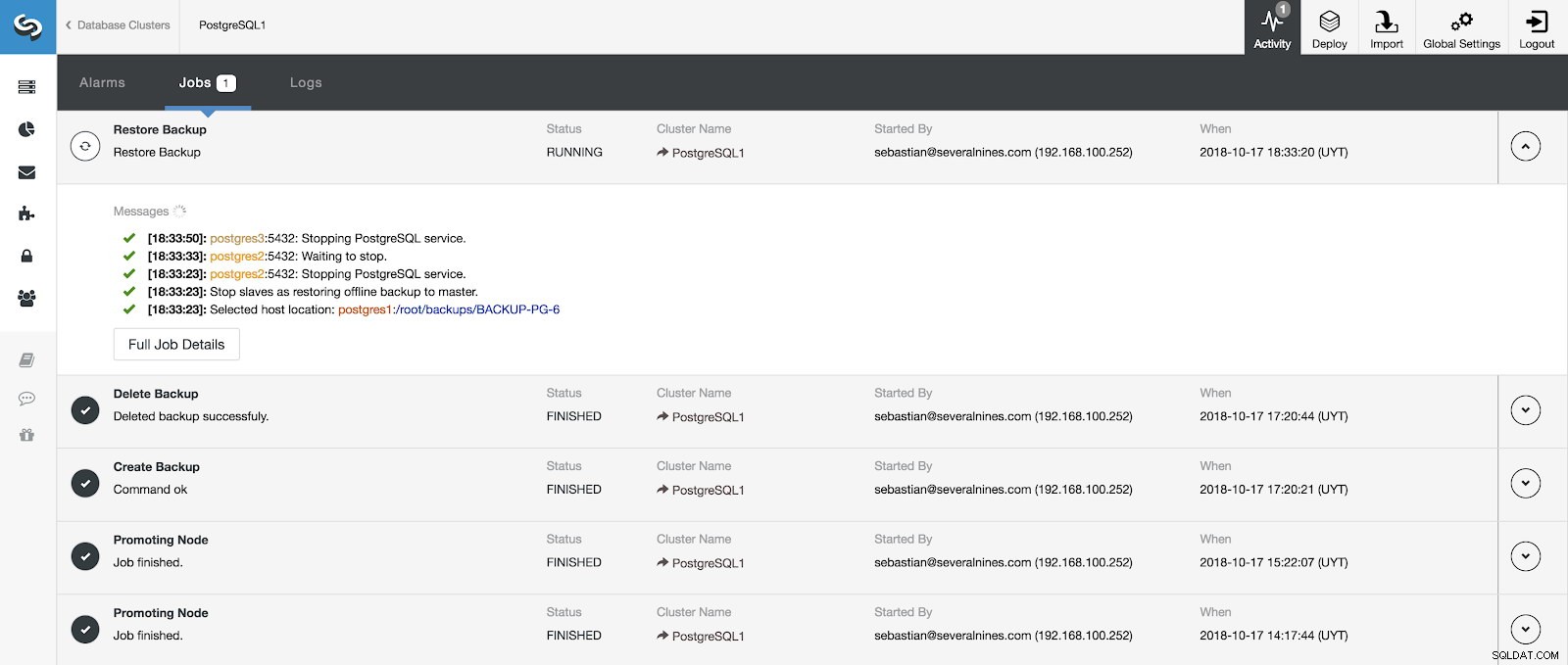
Nous pouvons surveiller la progression de notre restauration à partir de la section Activité de notre ClusterControl.
Conclusion
Le PITR est une fonctionnalité nécessaire pour respecter un RPO serré. Nous devons le configurer correctement pour garantir un plan de reprise après sinistre correct. ClusterControl fournit une interface facile à utiliser pour vous aider à implémenter PITR pour vos bases de données PostgreSQL.



