Les professionnels des données n'utilisent pas toujours des bases de données qui ont une conception optimale. Parfois, les choses qui vous font pleurer sont des choses que nous nous sommes faites, car elles semblaient être de bonnes idées à l'époque. Parfois, ils sont dus à des applications tierces. Parfois, ils vous précèdent simplement.
Celui auquel je pense dans cet article est lorsque votre colonne datetime (ou datetime2, ou mieux encore, datetimeoffset) est en fait deux colonnes - une pour la date et une pour l'heure. (Si vous avez à nouveau une colonne séparée pour le décalage, je vous ferai un câlin la prochaine fois que je vous verrai, car vous avez probablement dû faire face à toutes sortes de blessures.)
J'ai fait une enquête sur Twitter et j'ai découvert qu'il s'agit d'un problème très réel auquel environ la moitié d'entre vous doivent faire face de temps en temps.
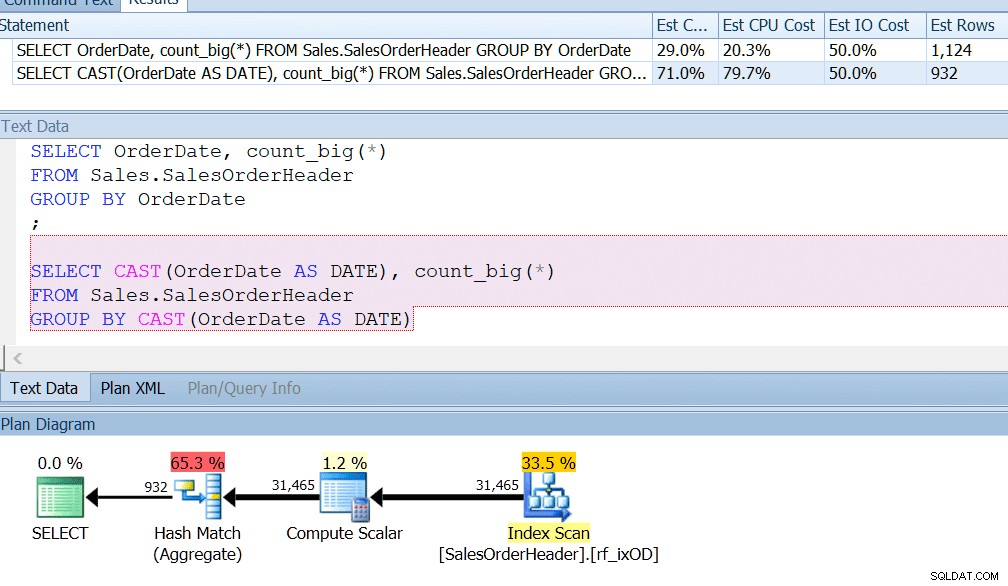
AdventureWorks le fait presque - si vous regardez dans la table Sales.SalesOrderHeader, vous verrez une colonne datetime appelée OrderDate, qui contient toujours des dates exactes. Je parie que si vous êtes un développeur de rapports chez AdventureWorks, vous avez probablement écrit des requêtes qui recherchent le nombre de commandes un jour particulier, en utilisant GROUP BY OrderDate, ou quelque chose comme ça. Même si vous saviez qu'il s'agissait d'une colonne datetime et qu'il était possible qu'elle stocke également une heure autre que minuit, vous diriez toujours GROUP BY OrderDate juste pour utiliser correctement un index. GROUP BY CAST (OrderDate AS DATE) ne suffit pas.
J'ai un index sur OrderDate, comme vous le feriez si vous interrogeiez régulièrement cette colonne, et je peux voir que le regroupement par CAST (OrderDate AS DATE) est environ quatre fois pire du point de vue du processeur.
Je comprends donc pourquoi vous seriez heureux d'interroger votre colonne comme s'il s'agissait d'une date, sachant simplement que vous aurez un monde de douleur si l'utilisation de cette colonne change. Peut-être que vous résolvez cela en ayant une contrainte sur la table. Peut-être que vous venez de mettre votre tête dans le sable.
Et quand quelqu'un arrive et dit "Vous savez, nous devrions également stocker l'heure à laquelle les commandes sont passées", eh bien, vous pensez à tout le code qui suppose que OrderDate est simplement une date, et imaginez qu'avoir une colonne séparée appelée OrderTime (type de données de temps, s'il vous plaît) sera l'option la plus sensée. Je comprends. Ce n'est pas idéal, mais cela fonctionne sans casser trop de choses.
À ce stade, je vous recommande également de créer OrderDateTime, qui serait une colonne calculée joignant les deux (ce que vous devriez faire en ajoutant le nombre de jours depuis le jour 0 à CAST(OrderDate as datetime2), plutôt que d'essayer d'ajouter le temps à date, qui est généralement beaucoup plus désordonnée). Et puis indexez OrderDateTime, car ce serait judicieux.
Mais assez souvent, vous vous retrouverez avec la date et l'heure dans des colonnes séparées, sans pratiquement rien que vous puissiez faire à ce sujet. Vous ne pouvez pas ajouter de colonne calculée, car il s'agit d'une application tierce et vous ne savez pas ce qui pourrait casser. Êtes-vous sûr qu'ils ne font jamais SELECT * ? Un jour, j'espère qu'ils nous laisseront ajouter des colonnes et les cacher, mais pour le moment, vous risquez certainement de casser des trucs.
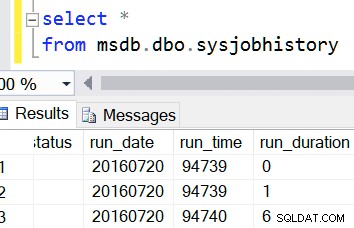
Et, vous savez, même msdb le fait. Ce sont tous les deux des entiers. Et c'est à cause de la rétrocompatibilité, je suppose. Mais je doute que vous envisagiez d'ajouter une colonne calculée à une table dans msdb.
Alors, comment interrogeons-nous cela ? Supposons que nous voulions trouver les entrées qui se trouvaient dans une plage datetime particulière ?
Faisons quelques expériences.
Commençons par créer une table de 3 millions de lignes et indexons les colonnes qui nous intéressent.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (J'aurais pu en faire un index clusterisé, mais je pense qu'un index non clusterisé est plus typique pour votre environnement.)
Nos données ressemblent à ceci, et je veux trouver des lignes entre, disons, le 2 août 2011 à 8h30 et le 5 août 2011 à 21h30.
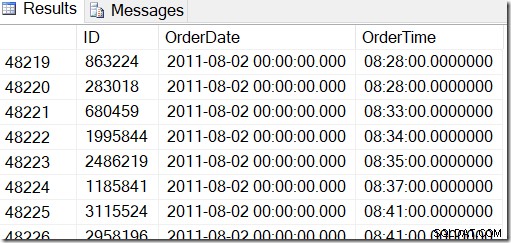
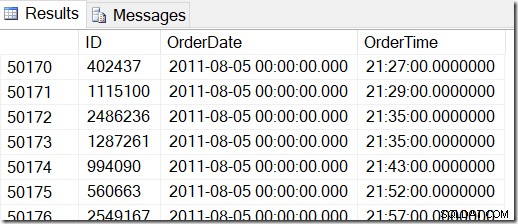
En parcourant les données, je peux voir que je veux toutes les lignes entre 48221 et 50171. C'est 50171-48221 + 1 =1951 lignes (le +1 est parce que c'est une plage inclusive). Cela m'aide à être sûr que mes résultats sont corrects. Vous auriez probablement des éléments similaires sur votre machine, mais pas exacts, car j'ai utilisé des valeurs aléatoires lors de la génération de ma table.
Je sais que je ne peux pas faire quelque chose comme ça :
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
… parce que cela n'inclurait pas quelque chose qui s'est passé du jour au lendemain le 4. Cela me donne 1268 lignes - clairement pas juste.
Une option consiste à combiner les colonnes :
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Cela donne les bons résultats. Cela fait. C'est juste que c'est complètement non-sargable, et nous donne un Scan sur toutes les lignes de notre table. Sur nos 3 millions de lignes, l'exécution peut prendre quelques secondes.
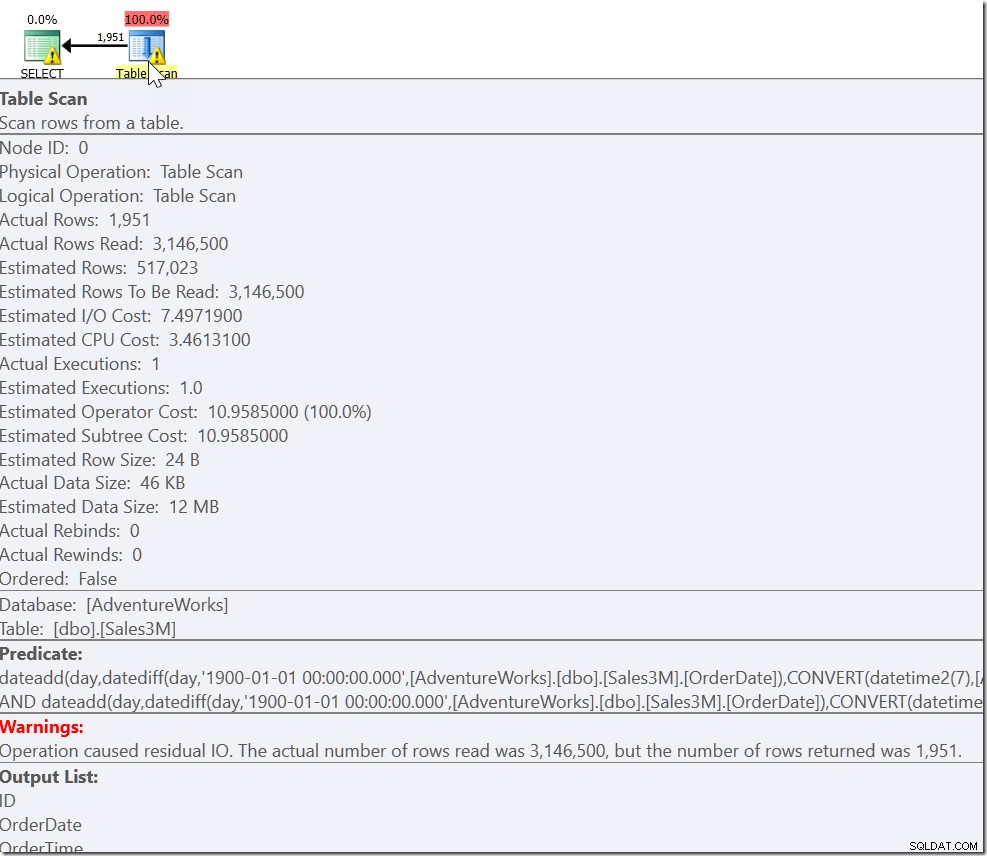
Notre problème est que nous avons un cas ordinaire et deux cas particuliers. Nous savons que chaque ligne qui satisfait OrderDate> '20110802' AND OrderDate <'20110805' est celle que nous voulons. Mais nous avons également besoin de chaque ligne située à ou après 8h30 le 20110802 et à ou avant 21h30 le 20110805. Et cela nous amène à :
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OU est horrible, je sais. Cela peut également conduire à des scans, mais pas nécessairement. Ici, je vois trois recherches d'index, concaténées puis vérifiées pour leur unicité. L'optimiseur de requête se rend évidemment compte qu'il ne doit pas renvoyer deux fois la même ligne, mais ne se rend pas compte que les trois conditions s'excluent mutuellement. Et en fait, si vous faisiez cela sur une plage en une seule journée, vous obtiendriez de mauvais résultats.
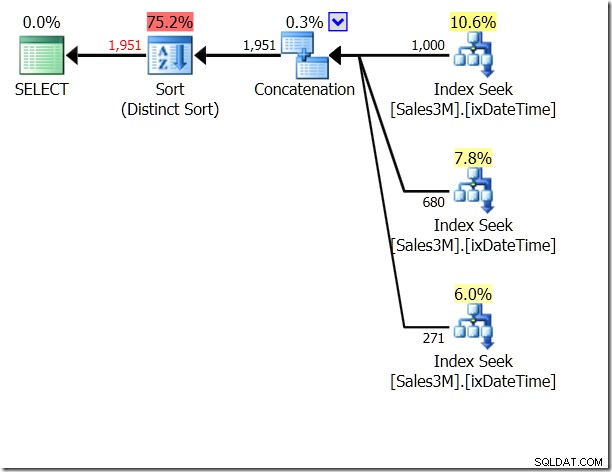
Nous pourrions utiliser UNION ALL à ce sujet, ce qui signifierait que le QO ne se soucierait pas de savoir si les conditions s'excluaient mutuellement. Cela nous donne trois Seeks qui sont concaténés - c'est plutôt bien.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Mais c'est toujours trois recherches. Statistics IO me dit que c'est 20 lectures sur ma machine.

Maintenant, quand je pense à la sargabilité, je ne pense pas seulement à éviter de mettre des colonnes d'index dans des expressions, je pense aussi à ce qui pourrait aider quelque chose à sembler sargable.
Prenez WHERE LastName LIKE 'Far%' par exemple. Quand je regarde le plan pour cela, je vois un Seek, avec un Seek Predicate, qui recherche n'importe quel nom de Far jusqu'à (mais non compris) FaS. Et puis il y a un prédicat résiduel vérifiant la condition LIKE. Ce n'est pas parce que le QO considère que LIKE est sargable. Si c'était le cas, il pourrait utiliser LIKE dans le prédicat Seek. C'est parce qu'il sait que tout ce qui est satisfait par cette condition LIKE doit être dans cette plage.
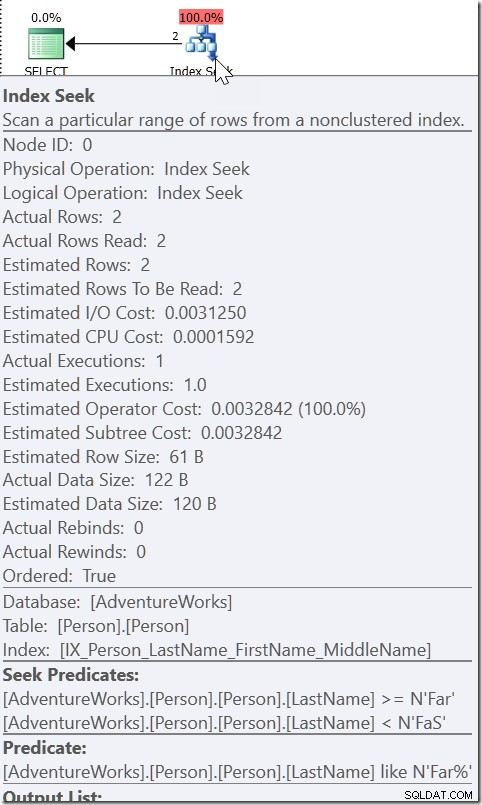
Prenez WHERE CAST(OrderDate AS DATE) ='20110805'
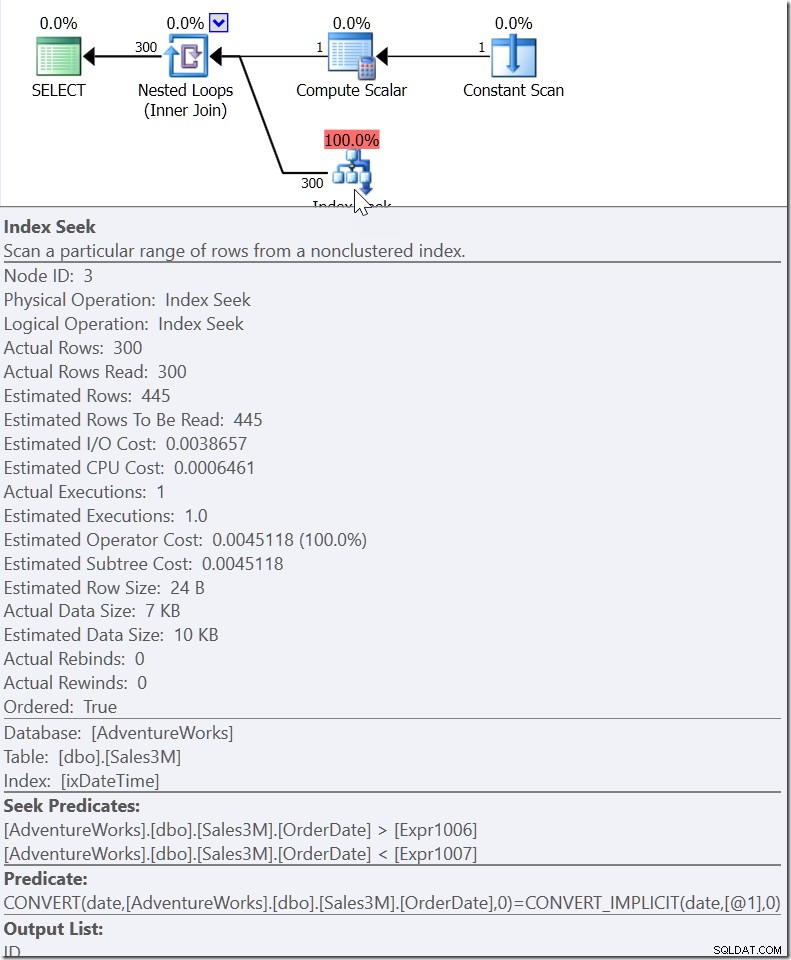
Ici, nous voyons un Seek Predicate qui recherche des valeurs OrderDate entre deux valeurs qui ont été élaborées ailleurs dans le plan, mais en créant une plage dans laquelle les bonnes valeurs doivent exister. Ce n'est pas>=20110805 00:00 et <20110806 00:00 (c'est ce que j'aurais fait), c'est autre chose. La valeur du début de cette plage doit être inférieure à 20110805 00:00, car elle est>, et non>=. Tout ce que nous pouvons vraiment dire, c'est que lorsque quelqu'un au sein de Microsoft a mis en œuvre la manière dont le QO devrait répondre à ce type de prédicat, il lui a donné suffisamment d'informations pour proposer ce que j'appelle un "prédicat d'assistance".
Maintenant, j'aimerais que Microsoft rende plus de fonctions sargables, mais cette demande particulière a été fermée bien avant qu'ils ne retirent Connect.
Mais peut-être que ce que je veux dire, c'est qu'ils créent plus de prédicats d'assistance.
Le problème avec les prédicats d'assistance est qu'ils lisent presque certainement plus de lignes que vous ne le souhaitez. Mais c'est toujours bien mieux que de parcourir tout l'index.
Je sais que toutes les lignes que je veux retourner auront OrderDate entre 20110802 et 20110805. C'est juste qu'il y en a que je ne veux pas.
Je pourrais simplement les supprimer, et ce serait valide :
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
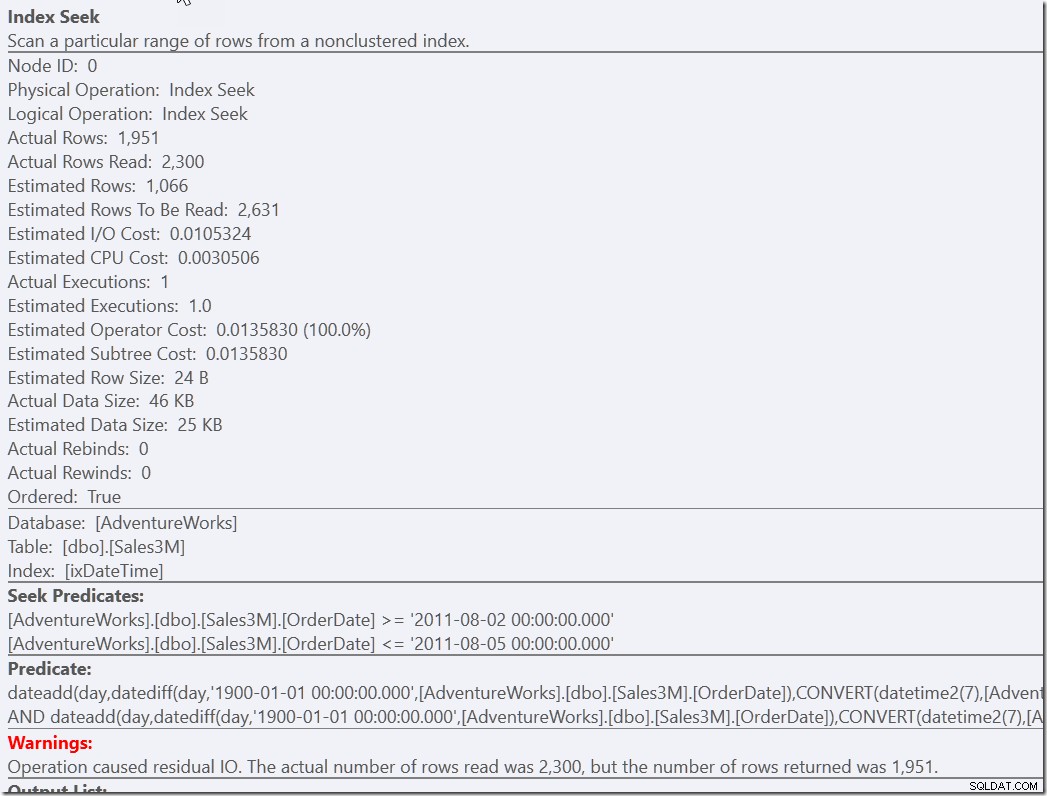
Mais j'ai l'impression que c'est une solution qui nécessite un effort de réflexion pour être trouvée. Moins d'effort du côté du développeur consiste simplement à fournir un prédicat d'assistance à notre version correcte mais lente.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Ces deux requêtes trouvent les 2300 lignes qui correspondent aux bons jours, puis doivent vérifier toutes ces lignes par rapport aux autres prédicats. L'un doit vérifier les deux conditions NOT, l'autre doit effectuer une conversion de type et des calculs. Mais les deux sont beaucoup plus rapides que ce que nous avions auparavant, et font une seule recherche (13 lectures). Bien sûr, je reçois des avertissements concernant un RangeScan inefficace, mais c'est ma préférence plutôt que d'en faire trois efficaces.
À certains égards, le plus gros problème avec ce dernier exemple est qu'une personne bien intentionnée verrait que le prédicat d'assistance est redondant et pourrait le supprimer. C'est le cas avec tous les prédicats d'assistance. Alors mettez un commentaire.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Si vous avez quelque chose qui ne rentre pas dans un bon prédicat sargable, trouvez-en un qui l'est, puis déterminez ce que vous devez en exclure. Vous pourriez juste trouver une solution plus agréable.
@rob_farley