Dans le cadre de l'apprentissage du didacticiel Oracle SQL, voici de bons détails sur le groupe par oracle
Les fonctions de groupe, contrairement aux fonctions à valeur unique, fonctionnent sur l'ensemble de lignes et renvoient une ligne par groupe. L'ensemble de lignes peut être un tableau entier ou le tableau divisé en groupes
Les types de fonctions de groupe dans Oracle incluent :
| AVG([Distinct/all] n) | Types de données numériques uniquement. La valeur moyenne de la colonne n en ignorant les valeurs nulles |
| COUNT({*/[Distinct/all]expr}) | Il s'agit uniquement d'une fonction de groupe qui inclut des valeurs nulles. Il compte le nombre de lignes dans l'instruction select qui satisfait la clause where. Count(*) inclut toutes les valeurs nulles et en double |
| MAX([Distinct/all] expr) | Il peut être utilisé avec n'importe quel type de données. Il donne la valeur maximale de expr en ignorant les valeurs nulles |
| MIN([Distinct/all] expr) | Il peut être utilisé avec n'importe quel type de données. . Il donne une valeur minimale de expr en ignorant les valeurs nulles |
| STDDEV([Distinct/all] n) | Types de données numériques uniquement. Il donne un écart type de n en ignorant les valeurs nulles |
| SOMME ([Distinct/tous] n) | Types de données numériques uniquement et ne peut pas avoir d'autres opérateurs arithmétiques dans la fonction. Il fournit la somme de n en ignorant les valeurs nulles |
| VARIANCE([Distinct/tous] n) | Types de données numériques uniquement. Il donne une variance de n en ignorant les valeurs nulles |
Syntaxe :
SELECT col1, col2, … col_n, aggregate_function (aggregate_expression) FROM tables [WHERE conditions] GROUP BY col1, col2, … col_n Having group condition;
Le serveur Oracle a effectué les étapes suivantes
- Tout d'abord, les lignes sont sélectionnées en fonction de la clause where
- Les lignes sont groupées
- La fonction de groupe est appliquée à chaque groupe
- Le groupe qui correspond au critère de la clause having est affiché
Ainsi, la clause WHERE est évaluée en premier (restreint les résultats de la requête), puis la clause GROUP BY (regroupe les résultats de WHERE), puis la clause HAVING (restreint davantage les résultats, en restreignant les groupes renvoyés).
Quelques points importants sur le groupe par oracle
(1) GROUP BY :décompose les résultats des fonctions de groupe d'un grand tableau de données en groupes logiques plus petits.
(2) La clause WHERE ne peut pas restreindre un groupe, utilisez donc la clause HAVING.
(3) N'utilisez pas l'alias de colonne dans la clause GROUP BY.
(4) HAVING :restreint l'affichage des groupes à ceux "ayant" les conditions spécifiées.
(5) La fonction NVL permet à une fonction GROUP BY d'inclure des valeurs nulles dans son calcul.
(6) Toute colonne ou expression de la liste de sélection qui n'est pas une fonction d'agrégation doit figurer dans la clause group by
Exemples de fonctions de groupe dans Oracle
Commençons par créer les exemples de tables, puis essayons le groupe par oracle sql
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
insert into emp values( 7698, 'Blake', 'MANAGER', 7839, to_date('1-5-2007','dd-mm-yyyy'), 2850, null, 10 );
insert into emp values( 7782, 'Clark', 'MANAGER', 7839, to_date('9-6-2008','dd-mm-yyyy'), 2450, null, 10 );
insert into emp values( 7788, 'Scott', 'ANALYST', 7566, to_date('9-6-2012','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7789, 'TPM', 'ANALYST', 7566, to_date('9-6-2017','dd-mm-yyyy'), 3000, null, null );
insert into emp values( 7560, 'T1OM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, 20 );
insert into emp values( 7790, 'TOM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, null );
commit;
Select * from emp; 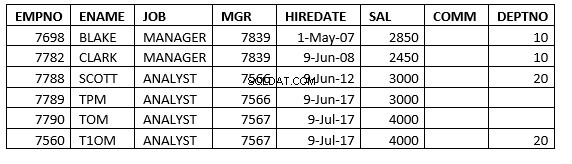
Colonne unique
Select dept , avg(sal) from emp group by dept;
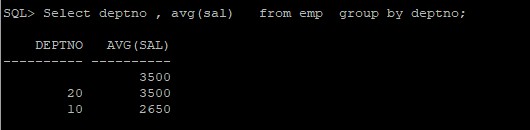
Colonnes multiples
Select deptno ,job, sum(sal) from emp group by deptno,job

Fonction de comptage
SELECT dept, COUNT(*) AS "Np of employees" FROM emp WHERE sal < 15000
GROUP BY dept;
Fonction Min
SELECT dept, MIN(sal) AS "Lowest salary" FROM emp
GROUP BY dept;
J'espère que cet article vous plaira
Articles connexes
Fonctions analytiques dans oracle :les fonctions analytiques Oracle calculent une valeur agrégée basée sur un groupe de lignes en utilisant la clause over partition by oracle , elles diffèrent des fonctions agrégées
rang dans oracle :RANK, DENSE_RANK et ROW_NUMBER sont analytiques oracle fonction qui sont utilisées pour classer les lignes dans le groupe de lignes appelé fenêtre
Fonction Lead dans Oracle :Découvrez la fonction LAG dans Oracle et la fonction Lead dans Oracle, comment les utiliser dans les requêtes analytiques et comment cela fonctionne dans Oracle sql
Requêtes Top-N dans Oracle :consultez cette page sur l'exploration des différentes façons de réaliser des requêtes Top-N dans Oracle et la pagination dans la base de données oracle de requête oracle.