J'ai récemment écrit un article sur DISTINCT et GROUP BY. C'est une comparaison qui a montré que GROUP BY est généralement une meilleure option que DISTINCT. C'est sur un autre site, mais assurez-vous de revenir sur sqlperformance.com juste après..
L'une des comparaisons de requêtes que j'ai montrées dans cet article était entre GROUP BY et DISTINCT pour une sous-requête, montrant que DISTINCT est beaucoup plus lent, car il doit récupérer le nom du produit pour chaque ligne de la table Sales, plutôt que juste pour chaque ProductID différent. Cela ressort clairement des plans de requête, où vous pouvez voir que dans la première requête, l'agrégat fonctionne sur les données d'une seule table, plutôt que sur les résultats de la jointure. Oh, et les deux requêtes donnent les mêmes 266 lignes.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

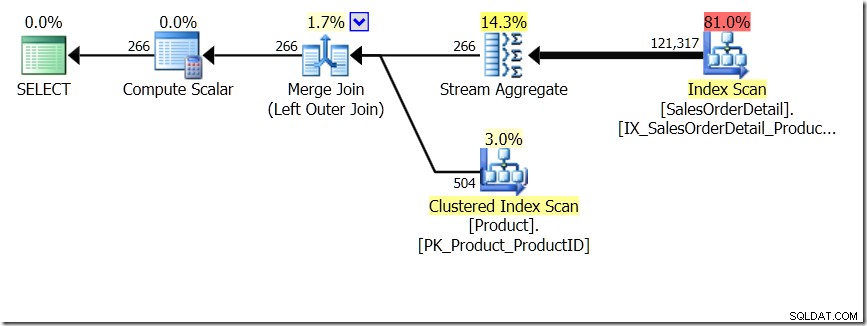
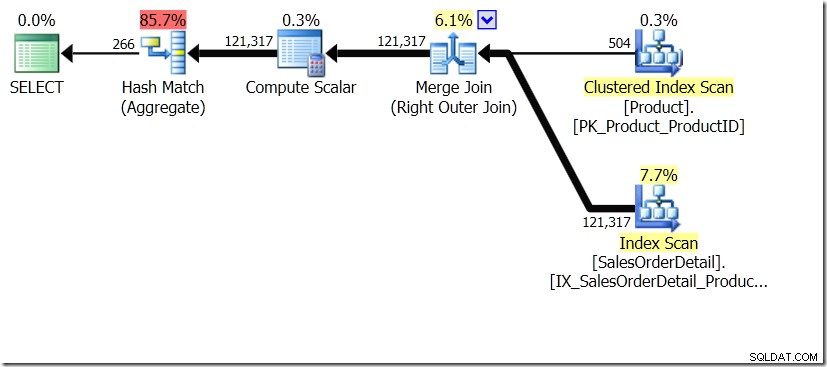
Maintenant, il a été souligné, y compris par Adam Machanic (@adammachanic) dans un tweet faisant référence au post d'Aaron sur GROUP BY v DISTINCT que les deux requêtes sont essentiellement différentes, que l'on demande en fait l'ensemble des combinaisons distinctes sur les résultats de la sous-requête, plutôt que d'exécuter la sous-requête sur les valeurs distinctes qui sont transmises. C'est ce que nous voyons dans le plan, et c'est la raison pour laquelle les performances sont si différentes.
Le fait est que nous supposerions tous que les résultats vont être identiques.
Mais c'est une supposition, et ce n'est pas une bonne.
Je vais imaginer un instant que l'optimiseur de requête a proposé un plan différent. J'ai utilisé des astuces pour cela, mais comme vous le savez, l'optimiseur de requête peut choisir de créer des plans de toutes sortes de formes pour toutes sortes de raisons.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
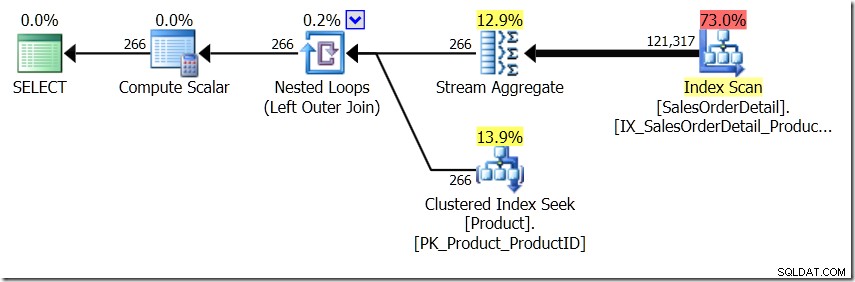
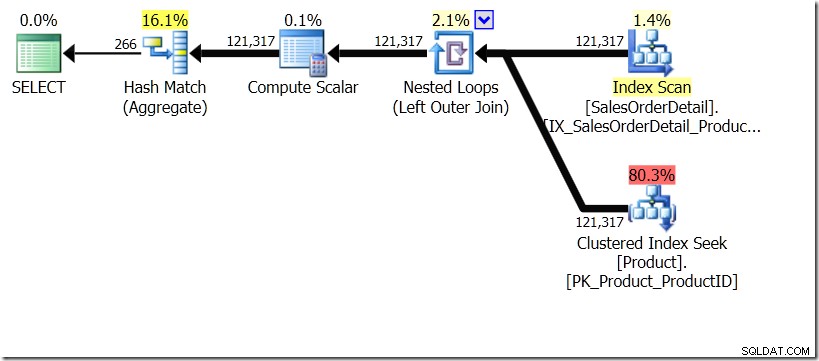
Dans cette situation, nous effectuons soit 266 recherches dans la table Product, une pour chaque ID de produit différent qui nous intéresse, soit 121 317 recherches. Donc, si nous pensons à un ProductID particulier, nous savons que nous allons récupérer un seul nom à partir du premier. Et nous supposons que nous allons récupérer un seul nom pour ce ProductID, même si nous devons le demander des centaines de fois. Nous supposons simplement que nous allons obtenir les mêmes résultats.
Et si nous ne le faisions pas ?
Cela ressemble à un problème de niveau d'isolement, alors utilisons NOLOCK lorsque nous atteignons la table Product. Et exécutons (dans une fenêtre différente) un script qui modifie le texte dans les colonnes Nom. Je vais le faire encore et encore, pour essayer d'obtenir certains des changements entre mes requêtes.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Maintenant, mes résultats sont différents. Les plans sont les mêmes (à l'exception du nombre de lignes provenant de l'agrégat de hachage dans la deuxième requête), mais mes résultats sont différents.
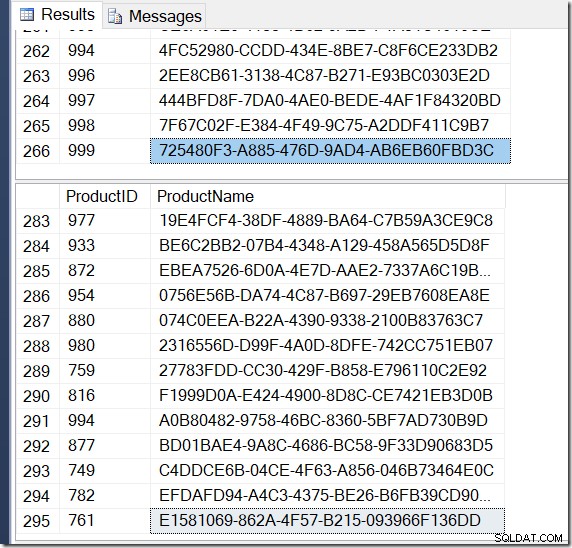
Effectivement, j'ai plus de lignes avec DISTINCT, car il trouve différentes valeurs de nom pour le même ProductID. Et je n'ai pas nécessairement 295 lignes. Un autre je l'exécute, je pourrais obtenir 273, ou 300, ou peut-être 121 317.
Il n'est pas difficile de trouver un exemple de ProductID qui affiche plusieurs valeurs de nom, confirmant ce qui se passe.

De toute évidence, pour nous assurer que nous ne voyons pas ces lignes dans les résultats, nous devrions soit NE PAS utiliser DISTINCT, soit utiliser un niveau d'isolement plus strict.
Le fait est que même si j'ai mentionné l'utilisation de NOLOCK pour cet exemple, je n'en avais pas besoin. Cette situation se produit même avec READ COMMITTED, qui est le niveau d'isolement par défaut sur de nombreux systèmes SQL Server.
Vous voyez, nous avons besoin du niveau d'isolation REPEATABLE READ pour éviter cette situation, pour maintenir les verrous sur chaque ligne une fois qu'elle a été lue. Sinon, un thread séparé pourrait modifier les données, comme nous l'avons vu.
Mais… je ne peux pas vous montrer que les résultats sont fixes, car je n'ai pas réussi à éviter un blocage sur la requête.
Modifions donc les conditions, en veillant à ce que notre autre requête pose moins de problèmes. Au lieu de mettre à jour toute la table à la fois (ce qui est de toute façon beaucoup moins probable dans le monde réel), mettons à jour une seule ligne à la fois.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Maintenant, nous pouvons toujours démontrer le problème sous un niveau d'isolement moindre, tel que READ COMMITTED ou READ UNCOMMITTED (bien que vous deviez peut-être exécuter la requête plusieurs fois si vous obtenez 266 la première fois, car la possibilité de mettre à jour une ligne pendant la requête est inférieur), et maintenant nous pouvons démontrer que REPEATABLE READ le corrige (peu importe combien de fois nous exécutons la requête).
REPEATABLE READ fait ce qu'il dit sur l'étain. Une fois que vous avez lu une ligne dans une transaction, elle est verrouillée pour vous assurer que vous pouvez répéter la lecture et obtenir les mêmes résultats. Les niveaux d'isolement inférieurs ne suppriment pas ces verrous tant que vous n'essayez pas de modifier les données. Si votre plan de requête n'a jamais besoin de répéter une lecture (comme c'est le cas avec la forme de nos plans GROUP BY), alors vous n'aurez pas besoin de REPEATABLE READ.
On peut dire que nous devrions toujours utiliser les niveaux d'isolement les plus élevés, tels que REPEATABLE READ ou SERIALIZABLE, mais tout revient à déterminer ce dont nos systèmes ont besoin. Ces niveaux peuvent introduire un verrouillage indésirable, et les niveaux d'isolation SNAPSHOT nécessitent une gestion des versions qui a également un prix. Pour moi, je pense que c'est un compromis. Si je demande une requête susceptible d'être affectée par la modification des données, je devrai peut-être augmenter le niveau d'isolement pendant un certain temps.
Idéalement, vous ne mettez simplement pas à jour les données qui viennent d'être lues et qui pourraient avoir besoin d'être lues à nouveau pendant la requête, de sorte que vous n'avez pas besoin de REPEATABLE READ. Mais cela vaut vraiment la peine de comprendre ce qui peut arriver et de reconnaître que c'est le genre de scénario où DISTINCT et GROUP BY peuvent ne pas être identiques.
@rob_farley