Introduction
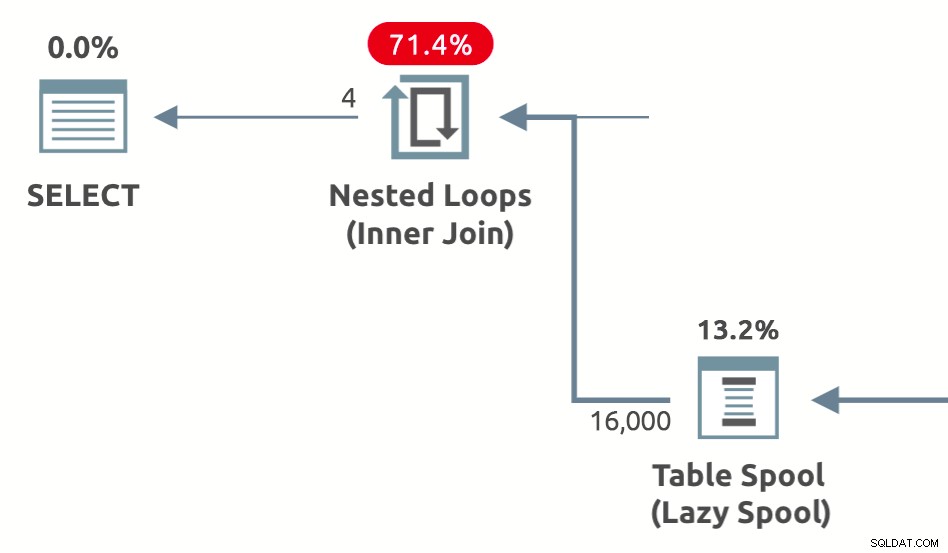
Bobines de performance sont des bobines paresseuses ajoutées par l'optimiseur pour réduire le coût estimé du côté intérieur de jointures de boucles imbriquées . Ils se déclinent en trois variétés :Lazy Table Spool , Spool d'index paresseux , et Lazy Row Count Spool . Un exemple de forme de plan montrant un spool de performances de table paresseux est ci-dessous :
Les questions auxquelles je me propose de répondre dans cet article sont pourquoi, comment et quand l'optimiseur de requête introduit chaque type de spool de performances.
Juste avant de commencer, je tiens à souligner un point important :il existe deux types distincts de jointure de boucle imbriquée dans les plans d'exécution. Je ferai référence à la variété avec des références externes en tant que candidat , et le type avec un prédicat de jointure sur l'opérateur de jointure lui-même en tant que jointure de boucles imbriquées . Pour être clair, cette différence concerne les opérateurs de plan d'exécution , pas la syntaxe de requête T-SQL. Pour plus de détails, veuillez consulter mon article lié.
Spools de performances
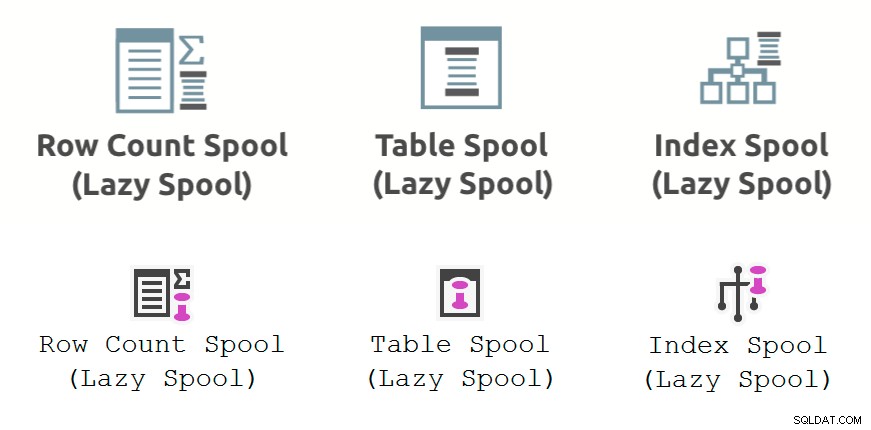
L'image ci-dessous montre la bobine de performance opérateurs de plan d'exécution tels qu'affichés dans Plan Explorer (rangée supérieure) et SSMS 18.3 (rangée inférieure) :
Remarques générales
Tous les spools de performance sont paresseux . La table de travail du spool est progressivement remplie, une ligne à la fois, au fur et à mesure que les lignes défilent dans le spool. (Les spools impatients, en revanche, consomment toutes les entrées de leur opérateur enfant avant de renvoyer des lignes à leur parent).
Les bobines de performance apparaissent toujours sur le côté intérieur (l'entrée inférieure dans les plans d'exécution graphiques) d'un opérateur de jointure ou d'application de boucles imbriquées. L'idée générale est de mettre en cache et de rejouer les résultats, en économisant autant que possible les exécutions répétées des opérateurs internes.
Lorsqu'un spool est capable de relire les résultats mis en cache, cela s'appelle un rembobinage . Lorsque le spool doit exécuter ses opérateurs enfants pour obtenir des données correctes, un rebind se produit.
Vous trouverez peut-être utile de penser à un spool rebind comme un manque de cache et un rembobinage en tant qu'accès au cache.
Spool de table paresseux
Ce type de bobine de performance peut être utilisé à la fois avec apply et les boucles imbriquées se rejoignent .
Appliquer
Une reliaison (cache miss) se produit chaque fois qu'une référence externe changements de valeur. Une bobine de table paresseuse se relie en tronquant sa table de travail et en la repeuplant entièrement à partir de ses opérateurs enfants.
Un rembobinage (cache hit) se produit lorsque le côté interne s'exécute avec le same valeurs de référence externes comme précédant immédiatement itération de la boucle. Un rembobinage rejoue les résultats mis en cache à partir de la table de travail du spool, ce qui permet d'économiser le coût de la réexécution des opérateurs de plan sous le spool.
Remarque :Un spool de table paresseux ne met en cache que les résultats d'un ensemble de apply référence externe valeurs à la fois.
Joindre des boucles imbriquées
Le spool de table paresseux est rempli une fois lors de la première itération de la boucle. Le spool rembobine son contenu pour chaque itération suivante de la jointure. Avec la jointure de boucles imbriquées, le côté interne de la jointure est un ensemble statique de lignes car le prédicat de jointure se trouve sur la jointure elle-même. L'ensemble de lignes interne statique peut donc être mis en cache et réutilisé plusieurs fois via le spool. Un spool de performances de jointure de boucles imbriquées ne se relie jamais.
Spool de comptage de lignes paresseux
Une bobine de comptage de lignes n'est guère plus qu'une table spool sans colonnes. Il met en cache l'existence d'une ligne, mais ne projette aucune donnée de colonne. En plus de noter son existence et de mentionner qu'il peut être une indication d'une erreur dans la requête source, je n'aurai pas plus à dire sur les spoules de comptage de lignes.
À partir de maintenant, chaque fois que vous voyez "table spool" dans le texte, veuillez le lire comme "table (ou row count) spool" car ils sont si similaires.
Spool d'index paresseux
Le bobine d'index paresseux l'opérateur est uniquement disponible avec apply .
Le spool d'index maintient une table de travail qui n'est pas tronquée quand référence externe les valeurs changent. Au lieu de cela, de nouvelles données sont ajoutées au cache existant, indexées par les valeurs de référence externes. Un spool d'index paresseux diffère d'un spool de table paresseux en ce qu'il peut rejouer les résultats de tout itération de boucle précédente, pas seulement la plus récente.
La prochaine étape pour comprendre quand les spools de performances apparaissent dans les plans d'exécution nécessite de comprendre un peu le fonctionnement de l'optimiseur.
Arrière-plan de l'optimiseur
Une requête source est convertie en une représentation arborescente logique par analyse, algébrisation, simplification et normalisation. Lorsque l'arbre résultant ne se qualifie pas pour un plan trivial, l'optimiseur basé sur les coûts recherche des alternatives logiques qui sont garanties de produire les mêmes résultats, mais à un coût estimé inférieur.
Une fois que l'optimiseur a généré des alternatives potentielles, il les implémente en utilisant les opérateurs physiques appropriés et calcule les coûts estimés. Le plan d'exécution final est construit à partir de l'option la moins coûteuse trouvée pour chaque groupe d'opérateurs. Vous pouvez lire plus de détails sur le processus dans ma série Query Optimizer Deep Dive.
Les conditions générales nécessaires pour qu'un spool de performance apparaisse dans le plan final de l'optimiseur sont :
- L'optimiseur doit explorer une alternative logique qui inclut un spool logique dans un substitut généré. C'est plus complexe qu'il n'y paraît, donc je déballerai les détails dans la prochaine section principale.
- Le spool logique doit être implémentable en tant que bobine physique opérateur dans le moteur d'exécution. Pour les versions modernes de SQL Server, cela signifie essentiellement que toutes les colonnes de clé d'un spool d'index doivent être d'un comparable type, pas plus de 900 octets* au total, avec 64 colonnes de clé ou moins.
- Le meilleur le plan complet après optimisation basée sur les coûts doit inclure l'une des alternatives de spool. En d'autres termes, tout choix basé sur les coûts entre les options avec ou sans bobine doit être favorable à la bobine.
* Cette valeur est codée en dur dans SQL Server et n'a pas été modifiée suite à l'augmentation à 1700 octets pour non clusterisé clés d'index à partir de SQL Server 2016. C'est parce que l'index spool est un cluster index, pas un index non clusterisé.
Règles de l'optimiseur
Nous ne pouvons pas spécifier un spool à l'aide de T-SQL, donc en obtenir un dans un plan d'exécution signifie que l'optimiseur doit choisir de l'ajouter. Dans un premier temps, cela signifie que l'optimiseur doit inclure un spool logique dans l'une des alternatives qu'il choisit d'explorer.
L'optimiseur n'applique pas de manière exhaustive toutes les règles d'équivalence logique qu'il connaît à chaque arbre de requête. Ce serait du gaspillage, compte tenu de l'objectif de l'optimiseur de produire rapidement un plan raisonnable. Il y a plusieurs aspects à cela. Tout d'abord, l'optimiseur procède par étapes, les règles les moins chères et les plus souvent applicables étant essayées en premier. Si un plan raisonnable est trouvé à un stade précoce, ou si la requête ne se qualifie pas pour les étapes ultérieures, l'effort d'optimisation peut se terminer tôt avec le plan le moins coûteux trouvé jusqu'à présent. Cette stratégie permet d'éviter de consacrer plus de temps à l'optimisation que ce qui est économisé par les améliorations des coûts supplémentaires.
Correspondance des règles
Chaque opérateur logique dans l'arborescence de requête est rapidement vérifié pour une correspondance de modèle par rapport aux règles disponibles dans l'étape d'optimisation actuelle. Par exemple, chaque règle ne correspondra qu'à un sous-ensemble d'opérateurs logiques et peut également nécessiter la mise en place de propriétés spécifiques, telles que l'entrée triée garantie. Une règle peut correspondre à une opération logique individuelle (un seul groupe) ou à plusieurs groupes contigus (une sous-section du plan).
Une fois mise en correspondance, une règle candidate est invitée à générer une valeur de promesse . Il s'agit d'un nombre représentant la probabilité que la règle actuelle produise un résultat utile, compte tenu du contexte local. Par exemple, une règle peut générer une valeur de promesse plus élevée lorsque la cible a de nombreux doublons sur son entrée, un grand nombre estimé de lignes, une entrée triée garantie ou une autre propriété souhaitable.
Une fois que les règles d'exploration prometteuses ont été identifiées, l'optimiseur les trie par ordre de valeur promise et commence à leur demander de générer de nouveaux substituts logiques. Chaque règle peut générer un ou plusieurs substituts qui seront ultérieurement implémentés à l'aide d'opérateurs physiques. Dans le cadre de ce processus, un coût estimé est calculé.
Le point de tout cela, tel qu'il s'applique aux spools de performance, est que la forme et les propriétés du plan logique doivent être propices à la correspondance des règles compatibles avec le spool, et le contexte local doit produire une valeur de promesse suffisamment élevée pour que l'optimiseur choisisse de générer des substituts à l'aide de la règle. .
Règles de spool
Il existe un certain nombre de règles qui explorent les jointures de boucles imbriquées logiques ou postuler alternatives. Certaines de ces règles peuvent produire un ou plusieurs substituts avec un type particulier de bobine de performance. Les autres règles qui correspondent aux boucles imbriquées se joignent ou s'appliquent ne génèrent jamais d'alternative spool.
Par exemple, la règle ApplyToNL implémente une application logique en tant que boucles physiques se joignent à des références externes. Cette règle peut générer plusieurs alternatives à chaque fois qu'il tourne. Outre l'opérateur de jointure physique, chaque substitut peut contenir un spool de table paresseux, un spool d'index paresseux ou aucun spool du tout. Les substituts de spool logiques sont ensuite implémentés individuellement et chiffrés en tant que spools physiques typés de manière appropriée, par une autre règle appelée BuildSpool .
Comme deuxième exemple, la règle JNtoIdxLookup implémente une jointure logique en tant que apply physique , avec une recherche d'index immédiatement sur le côté intérieur. Cette règle jamais génère une alternative avec un composant spool. JNtoIdxLookup est évalué tôt et renvoie une valeur de promesse élevée lorsqu'il correspond, de sorte que des plans simples de recherche d'index sont trouvés rapidement.
Lorsque l'optimiseur trouve une alternative peu coûteuse comme celle-ci très tôt, des alternatives plus complexes peuvent être éliminées de manière agressive ou complètement ignorées. Le raisonnement est qu'il n'est pas logique de poursuivre des options qui sont peu susceptibles d'améliorer une alternative à faible coût déjà trouvée. De même, il ne vaut pas la peine d'explorer plus avant si le meilleur plan complet actuel a déjà un coût total suffisamment bas.
Un troisième exemple de règle :la règle JNtoNL est similaire à ApplyToNL , mais il implémente uniquement la jointure de boucle imbriquée physique , soit avec une bobine de table paresseuse, soit sans bobine du tout. Cette règle jamais génère un spool d'index car ce type de spool nécessite une application.
Génération et coût du spool
Une règle capable de générer un spool logique ne le fera pas nécessairement à chaque fois qu'il sera sollicité. Ce serait du gaspillage de générer des alternatives logiques qui n'ont pratiquement aucune chance d'être choisies comme les moins chères. Il y a aussi un coût à générer de nouvelles alternatives, qui peuvent à leur tour produire encore plus d'alternatives - dont chacune peut nécessiter une mise en œuvre et un coût.
Pour gérer cela, l'optimiseur implémente une logique commune pour toutes les règles compatibles avec le spool afin de déterminer quel(s) type(s) d'alternative de spool générer en fonction des conditions du plan local.
Joindre des boucles imbriquées
Pour une jointure de boucles imbriquées , la chance d'obtenir une bobine de table paresseuse augmente en fonction de :
- Le nombre estimé de lignes sur l'entrée externe de la jointure.
- Le coût estimé des opérateurs de plans intérieurs.
Le coût de la bobine est remboursé par les économies réalisées en évitant les exécutions de l'opérateur côté intérieur. Les économies augmentent avec plus d'itérations internes et un coût interne plus élevé. Cela est particulièrement vrai parce que le modèle de coût attribue des nombres d'E/S et de coût de CPU relativement faibles aux rembobinages de table (accès au cache). N'oubliez pas qu'un spool de table sur une jointure de boucles imbriquées ne subit que des rembobinages, car l'absence de paramètres signifie que l'ensemble de données interne est statique.
Un spool peut stocker des données plus densément que les opérateurs qui l'alimentent. Par exemple, un index clusterisé de table de base peut stocker 100 lignes par page en moyenne. Supposons qu'une requête n'ait besoin que d'une seule valeur de colonne entière à partir de chaque ligne d'index cluster large. Stocker uniquement la valeur entière dans la table de travail spool signifie que plus de 800 lignes de ce type peuvent être stockées par page. Ceci est important car l'optimiseur évalue le coût du spool de table en partie à l'aide d'une estimation du nombre de pages de table de travail avait besoin. D'autres facteurs de coût incluent le coût du processeur par ligne impliqué dans l'écriture et la lecture du spool, sur le nombre estimé d'itérations de boucle.
L'optimiseur est sans doute un peu trop désireux d'ajouter des bobines de table paresseuses à l'intérieur d'une jointure de boucles imbriquées. Néanmoins, la décision de l'optimiseur a toujours un sens en termes de coût estimé. Personnellement, je considère les jointures de boucles imbriquées comme à haut risque , car ils peuvent rapidement devenir lents si l'estimation de la cardinalité d'entrée de la jointure est trop faible.
Une bobine de table peut aider à réduire le coût, mais il ne peut pas entièrement masquer les performances les plus défavorables d'une jointure de boucles imbriquées naïves. Une jointure d'application indexée est normalement préférable et plus résistante aux erreurs d'estimation. C'est également une bonne idée d'écrire des requêtes que l'optimiseur peut implémenter avec un hachage ou une jointure par fusion, le cas échéant.
Appliquer un spool de table paresseux
Pour une application , les chances d'obtenir une bobine de table paresseuse augmenter avec le nombre estimé de doublons joindre les valeurs clés sur l'entrée externe de l'application. Avec plus de doublons, il y a statistiquement plus de chances que le spool rembobine ses résultats actuellement stockés à chaque itération. Un spool de tableau paresseux d'application avec un coût estimé inférieur a de meilleures chances de figurer dans le plan d'exécution final.
Lorsque les lignes arrivant sur l'entrée externe d'application n'ont pas d'ordre particulier, l'optimiseur effectue une évaluation statistique de la probabilité que chaque itération aboutisse à un rembobinage bon marché ou à une reliure coûteuse. Cette évaluation utilise les données des étapes de l'histogramme lorsqu'elles sont disponibles, mais même ce meilleur scénario est plus une supposition éclairée. Sans garantie, l'ordre des lignes arrivant sur l'entrée externe d'application est imprévisible.
Les mêmes règles d'optimisation qui génèrent des alternatives de spool logiques peuvent aussi spécifier que l'opérateur d'application requiert lignes triées sur son entrée extérieure. Cela maximise les rembobinages de la bobine paresseuse car tous les doublons sont garantis d'être rencontrés dans un bloc. Lorsque l'ordre de tri des entrées externes est garanti, soit par un ordre préservé, soit par un Sort explicite , le coût de la bobine est très réduit. L'optimiseur tient compte de l'impact de l'ordre de tri sur le nombre de rembobinages et de reliures de la bobine.
Plans avec un Tri sur l'entrée externe d'application, et un Lazy Table Spool sur l'entrée intérieure sont assez courantes. L'optimisation du tri du côté externe peut encore finir par être contre-productive. Par exemple, cela peut se produire lorsque l'estimation de la cardinalité du côté extérieur est si faible que le tri finit par déborder sur tempdb .
Appliquer un spool d'index différé
Pour une application , obtenant un spool d'index paresseux l'alternative dépend de la forme du plan ainsi que du coût.
L'optimiseur nécessite :
- Certains doublons joindre les valeurs sur l'entrée externe.
- Une égalité joindre le prédicat (ou un équivalent logique compris par l'optimiseur, tel que
x <= y AND x >= y). - Une garantie que les références externes sont uniques sous le spool d'index paresseux proposé.
Dans les plans d'exécution, l'unicité requise est souvent fournie par un regroupement d'agrégats par les références externes, ou un agrégat scalaire (un sans groupe par). L'unicité peut également être fournie par d'autres moyens, par exemple par l'existence d'un index ou d'une contrainte unique.
Un exemple de jouet qui montre la forme du plan est ci-dessous :
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
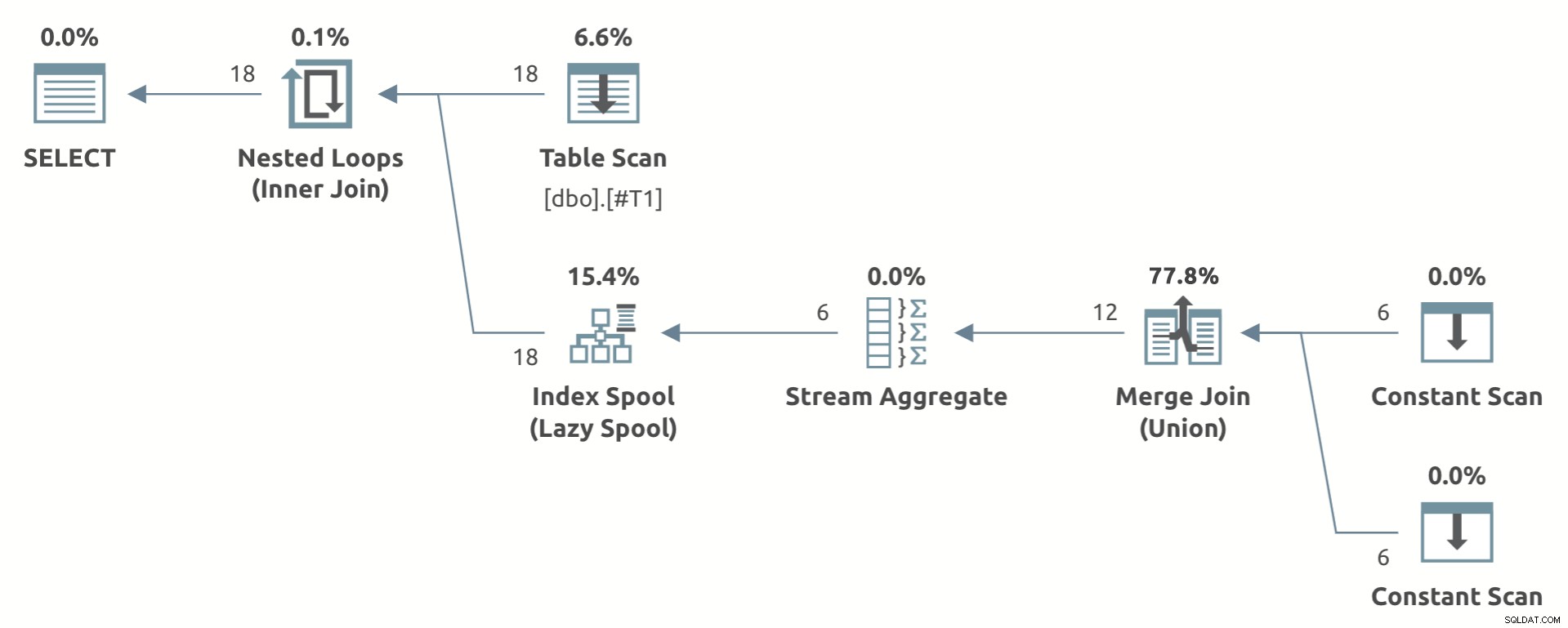
Remarquez le Stream Aggregate sous le Spool d'index paresseux .
Si les exigences de forme de plan sont remplies, l'optimiseur génère souvent une alternative d'index paresseux (sous réserve des mises en garde mentionnées précédemment). Que le plan final inclue ou non un spool d'index paresseux dépend du coût.
Index Spool contre Table Spool
Le nombre de rembobinages estimés et relie pour un spool d'index paresseux est le même comme pour une bobine de table paresseuse sans trié appliquer l'entrée externe.
Cela peut sembler une situation plutôt malheureuse. Le principal avantage d'un spool d'index est qu'il met en cache tous les résultats précédemment vus. Cela devrait faire des rembobinages de la bobine d'index plus probable que pour un spool de table (sans tri d'entrée externe) dans les mêmes circonstances. Je crois comprendre que cette bizarrerie existe parce que sans elle, l'optimiseur choisirait bien trop souvent une bobine d'index.
Quoi qu'il en soit, le modèle de coût s'ajuste dans une certaine mesure à ce qui précède en utilisant différents nombres d'E/S de ligne initiale et de ligne suivante et de coûts de CPU pour les spools d'index et de table. L'effet net est qu'un spool d'index est généralement moins cher qu'un spool de table sans entrée externe triée, mais n'oubliez pas les exigences restrictives en matière de forme de plan, qui rendent les spools d'index paresseux relativement rares.
Pourtant, le principal concurrent en termes de coût d'un index de bobine paresseux est une bobine de table avec entrée externe triée. L'intuition pour cela est assez simple :l'entrée externe triée signifie que le spool de table est assuré de voir toutes les références externes en double de manière séquentielle. Cela signifie qu'il va relier une seule fois par valeur distincte, et rembobiner pour tous les doublons. C'est le même que le comportement attendu d'un spool d'index (du moins en toute logique).
En pratique, un spool d'index est plus susceptible d'être préféré à un spool de table optimisé pour le tri pour moins de valeurs de clé d'application en double. Avoir moins de clés en double réduit le rembobinage avantage du spool de table optimisé pour le tri, par rapport aux estimations de spool d'index "malheureuses" notées précédemment.
L'option de bobine d'index bénéficie également du coût estimé d'un tri côté extérieur de la bobine de table augmente. Cela serait le plus souvent associé à des rangées plus nombreuses (ou plus larges) à ce stade du plan.
Drapeaux de suivi et conseils
-
Les spools de performance peuvent être désactivés avec indicateur de trace légèrement documenté 8690 , ou l'indicateur de requête documenté
NO_PERFORMANCE_SPOOLsur SQL Server 2016 ou version ultérieure. -
Indicateur de trace non documenté 8691 peut être utilisé (sur un système de test) pour toujours ajouter un spool de performance quand c'est possible. Le type de spool paresseux que vous obtenez (nombre de lignes, table ou index) ne peut pas être forcé ; cela dépend toujours de l'estimation des coûts.
-
Indicateur de trace non documenté 2363 peut être utilisé avec le nouveau modèle d'estimation de cardinalité pour voir la dérivation de l'estimation distincte sur l'entrée externe d'une application, et l'estimation de la cardinalité en général.
-
Indicateur de trace non documenté 9198 peut être utilisé pour désactiver les spools de performances d'index paresseux Plus précisément. Vous pouvez toujours obtenir une table paresseuse ou un spool de comptage de lignes à la place (avec ou sans optimisation du tri), en fonction du coût.
-
Indicateur de trace non documenté 2387 peut être utilisé pour réduire le coût du processeur de lire des lignes à partir d'un spool d'index paresseux . Cet indicateur affecte les estimations générales du coût du processeur pour la lecture d'une plage de lignes à partir d'un b-tree. Cet indicateur a tendance à rendre la sélection de spool d'index plus probable, pour des raisons de coût.
D'autres indicateurs de trace et méthodes pour déterminer quelles règles d'optimisation ont été activées lors de la compilation de la requête peuvent être trouvés dans ma série Query Optimizer Deep Dive.
Réflexions finales
De nombreux détails internes affectent le fait que le plan d'exécution final utilise ou non un spool de performances. J'ai essayé de couvrir les principales considérations dans cet article, sans entrer trop loin dans les détails extrêmement complexes des formules de calcul des coûts de l'opérateur de bobine. J'espère qu'il y a suffisamment de conseils généraux ici pour vous aider à déterminer les raisons possibles d'un type de spool de performances particulier dans un plan d'exécution (ou son absence).
Les bobines de performance ont souvent une mauvaise réputation, je pense qu'il est juste de dire. Une partie de cela est sans aucun doute méritée. Beaucoup d'entre vous auront vu une démo où un plan s'exécute plus rapidement sans "bobine de performance" qu'avec. Dans une certaine mesure, ce n'est pas inattendu. Il existe des cas extrêmes, le modèle d'établissement des coûts n'est pas parfait et il ne fait aucun doute que les démos présentent souvent des plans avec de mauvaises estimations de cardinalité ou d'autres problèmes limitant l'optimiseur.
Cela dit, je souhaite parfois que SQL Server fournisse une sorte d'avertissement ou d'autres commentaires lorsqu'il a recours à l'ajout d'un spool de table paresseux à une jointure de boucles imbriquées (ou une application sans index interne de prise en charge utilisé). Comme mentionné dans le corps principal, ce sont les situations qui tournent le plus souvent mal, lorsque les estimations de cardinalité s'avèrent horriblement basses.
Peut-être qu'un jour l'optimiseur de requête prendra en compte un certain concept de risque pour planifier les choix, ou fournira des capacités plus "adaptatives". En attendant, il est avantageux de prendre en charge vos jointures de boucles imbriquées avec des index utiles et d'éviter d'écrire des requêtes qui ne peuvent être implémentées qu'à l'aide de boucles imbriquées lorsque cela est possible. Je généralise bien sûr, mais l'optimiseur a tendance à faire mieux quand il a plus de choix, un schéma raisonnable, de bonnes métadonnées et des instructions T-SQL gérables avec lesquelles travailler. Comme moi, à bien y penser.
Autres articles spool
Les spools de non-performance sont utilisés à de nombreuses fins dans SQL Server, notamment :
- Protection d'Halloween
- Certaines fonctions de fenêtre en mode ligne
- Calculer plusieurs agrégats
- Optimiser les instructions qui modifient les données