Vous savez probablement comment insérer des enregistrements dans une table en utilisant une ou plusieurs clauses VALUES. Vous savez également comment effectuer des insertions en bloc à l'aide de SQL INSERT INTO SELECT. Mais vous avez quand même cliqué sur l'article. S'agit-il de gérer les doublons ?
De nombreux articles traitent de SQL INSERT INTO SELECT. Google ou Bing it et choisissez le titre que vous préférez – ça ira. Je ne couvrirai pas non plus les exemples de base de la façon dont cela est fait. Au lieu de cela, vous verrez des exemples sur la façon de l'utiliser ET de gérer les doublons en même temps . Ainsi, vous pouvez faire passer ce message familier à partir de vos efforts d'INSERTION :
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Mais avant tout.

[sendpulse-form id="12989″]
Préparer les données de test pour les exemples de code SQL INSERT INTO SELECT
Je pense plutôt aux pâtes cette fois. Donc, je vais utiliser des données sur les plats de pâtes. J'ai trouvé une bonne liste de plats de pâtes sur Wikipedia que nous pouvons utiliser et extraire dans Power BI à l'aide d'une source de données Web. J'ai entré l'URL Wikipedia. Ensuite, j'ai spécifié les données à 2 tables de la page. Nettoyé un peu et copié les données dans Excel.
Nous avons maintenant les données - vous pouvez les télécharger à partir d'ici. C'est brut car on va en faire 2 tables relationnelles. L'utilisation de INSERT INTO SELECT nous aidera à accomplir cette tâche,
Importer les données dans SQL Server
Vous pouvez soit utiliser SQL Server Management Studio ou dbForge Studio pour SQL Server pour importer 2 feuilles dans le fichier Excel.
Créez une base de données vide avant d'importer les données. J'ai nommé les tables dbo.ItalianPastaDishes et dbo.NonItalianPastaDishes .
Créer 2 tableaux supplémentaires
Définissons les deux tables de sortie avec la commande SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Remarque :Des index uniques sont créés sur deux tables. Cela nous empêchera d'insérer des enregistrements en double ultérieurement. Les restrictions rendront ce voyage un peu plus difficile mais passionnant.
Maintenant que nous sommes prêts, plongeons.
5 façons simples de gérer les doublons à l'aide de SQL INSERT INTO SELECT
Le moyen le plus simple de gérer les doublons est de supprimer les contraintes uniques, n'est-ce pas ?
Faux !
Une fois les contraintes uniques supprimées, il est facile de faire une erreur et d'insérer les données deux fois ou plus. Nous ne voulons pas cela. Et si nous avions une interface utilisateur avec une liste déroulante pour choisir l'origine du plat de pâtes ? Les doublons rendront-ils vos utilisateurs heureux ?
Par conséquent, la suppression des contraintes d'unicité n'est pas l'une des cinq manières de gérer ou de supprimer les enregistrements en double dans SQL. Nous avons de meilleures options.
1. Utiliser INSERT INTO SELECT DISTINCT
La première option pour identifier les enregistrements SQL dans SQL consiste à utiliser DISTINCT dans votre SELECT. Pour explorer le cas, nous remplirons l'Origine table. Mais d'abord, utilisons la mauvaise méthode :
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Cela déclenchera les erreurs de doublon suivantes :
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
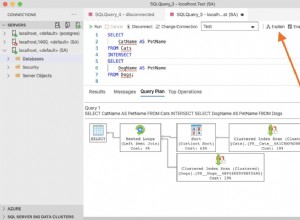
Il y a un problème lorsque vous essayez de sélectionner des lignes en double dans SQL. Pour démarrer la vérification SQL des doublons qui existaient auparavant, j'ai exécuté la partie SELECT de l'instruction INSERT INTO SELECT :
C'est la raison de la première erreur de duplication SQL. Pour l'empêcher, ajoutez le mot-clé DISTINCT pour rendre le jeu de résultats unique. Voici le bon code :
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Il insère les enregistrements avec succès. Et nous en avons fini avec l'Origine tableau.
L'utilisation de DISTINCT créera des enregistrements uniques à partir de l'instruction SELECT. Cependant, cela ne garantit pas l'absence de doublons dans la table cible. C'est bien lorsque vous êtes sûr que la table cible ne contient pas les valeurs que vous souhaitez insérer.
Donc, n'exécutez pas ces instructions plus d'une fois.
2. Utiliser WHERE NOT IN
Ensuite, nous remplissons les PastaDishes table. Pour cela, nous devons d'abord insérer des enregistrements de ItalianPastaDishes table. Voici le code :
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Depuis ItalianPastaDishes contient des données brutes, nous devons joindre l'Origine texte au lieu de OriginID . Maintenant, essayez d'exécuter le même code deux fois. La deuxième fois qu'il s'exécute, aucun enregistrement n'est inséré. Cela se produit à cause de la clause WHERE avec l'opérateur NOT IN. Il filtre les enregistrements qui existent déjà dans la table cible.
Ensuite, nous devons remplir les PastaDishes table des NonItalianPastaDishes table. Comme nous n'en sommes qu'au deuxième point de cet article, nous n'insérerons pas tout.
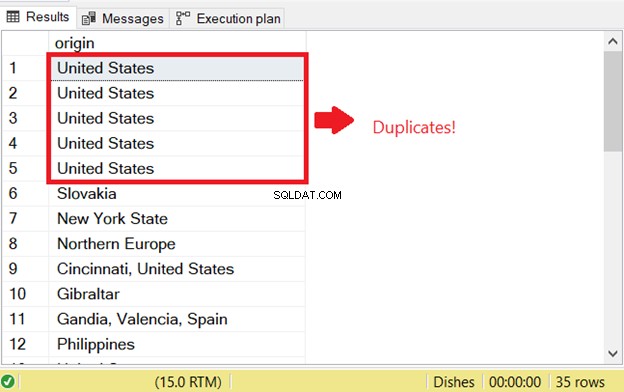
Nous avons choisi des plats de pâtes des États-Unis et des Philippines. Voici :
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Il y a 9 enregistrements insérés à partir de cette déclaration - voir la figure 2 ci-dessous :
Encore une fois, si vous exécutez le code ci-dessus deux fois, la deuxième exécution n'aura pas d'enregistrements insérés.
3. Utiliser OÙ N'EXISTE PAS
Une autre façon de trouver des doublons dans SQL consiste à utiliser NOT EXISTS dans la clause WHERE. Essayons avec les mêmes conditions de la section précédente :
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
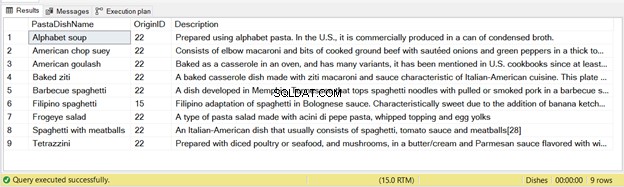
Le code ci-dessus insérera les mêmes 9 enregistrements que vous avez vus dans la figure 2. Cela évitera d'insérer les mêmes enregistrements plus d'une fois.
4. Utilisation de SI NON EXISTE
Parfois, vous devrez peut-être déployer une table dans la base de données et il est nécessaire de vérifier si une table portant le même nom existe déjà pour éviter les doublons. Dans ce cas, la commande SQL DROP TABLE IF EXISTS peut être d'une grande aide. Une autre façon de vous assurer que vous n'insérerez pas de doublons consiste à utiliser IF NOT EXISTS. Encore une fois, nous utiliserons les mêmes conditions de la section précédente :
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Le code ci-dessus vérifiera d'abord l'existence de 9 enregistrements. S'il renvoie vrai, INSERT continuera.
5. Utiliser COUNT(*) =0
Enfin, l'utilisation de COUNT(*) dans la clause WHERE peut également garantir que vous n'insérerez pas de doublons. Voici un exemple :
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Pour éviter les doublons, le COUNT ou les enregistrements renvoyés par la sous-requête ci-dessus doivent être nuls.
Remarque :Vous pouvez concevoir n'importe quelle requête visuellement dans un diagramme à l'aide de la fonction de générateur de requêtes de dbForge Studio pour SQL Server.
Comparaison de différentes manières de gérer les doublons avec SQL INSERT INTO SELECT
4 sections ont utilisé la même sortie mais des approches différentes pour insérer des enregistrements en masse avec une instruction SELECT. Vous vous demandez peut-être si la différence n'est qu'apparente. Nous pouvons vérifier leurs lectures logiques à partir de STATISTICS IO pour voir à quel point elles sont différentes.
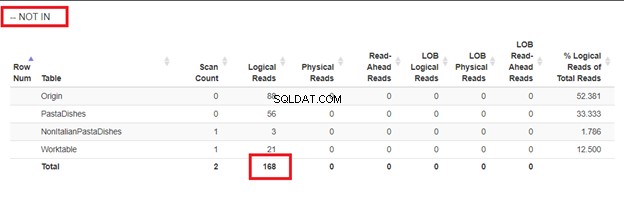
Utiliser WHERE NOT IN :
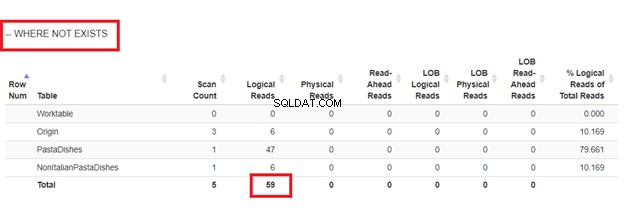
Utiliser NON EXISTE :
Utiliser SI NON EXISTE :
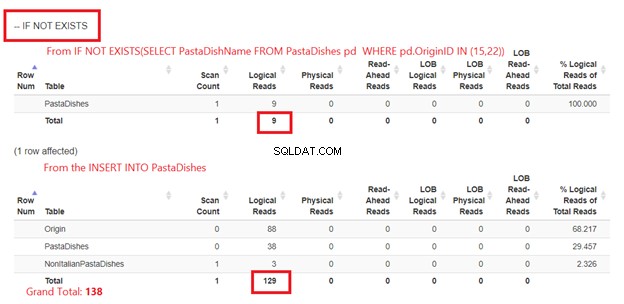
La figure 5 est un peu différente. 2 lectures logiques apparaissent pour les PastaDishes table. Le premier provient de IF NOT EXISTS(SELECT PastaDishName de Plats de pâtes OÙ Identifiant d'origine EN (15,22)). Le second provient de l'instruction INSERT.
Enfin, en utilisant COUNT(*) =0
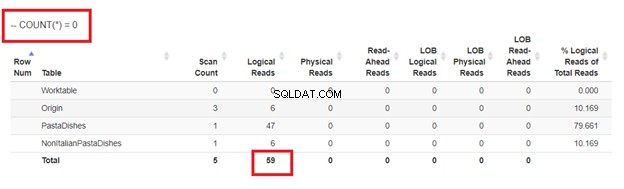
D'après les lectures logiques de 4 approches que nous avions, le meilleur choix est WHERE NOT EXISTS ou COUNT(*) =0. Lorsque nous inspectons leurs plans d'exécution, nous constatons qu'ils ont le même QueryHashPlan . Ainsi, ils ont des plans similaires. Pendant ce temps, le moins efficace utilise NOT IN.
Cela signifie-t-il que WHERE NOT EXISTS est toujours meilleur que NOT IN ? Pas du tout.
Inspectez toujours les lectures logiques et le plan d'exécution de vos requêtes !
Mais avant de conclure, nous devons terminer la tâche à accomplir. Ensuite, nous insérerons le reste des enregistrements et inspecterons les résultats.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Parcourir la liste des 179 plats de pâtes de l'Asie à l'Europe me donne faim. Découvrez une partie de la liste d'Italie, de Russie et plus ci-dessous :

Conclusion
Éviter les doublons dans SQL INSERT INTO SELECT n'est pas si difficile après tout. Vous avez des opérateurs et des fonctions à portée de main pour vous amener à ce niveau. C'est aussi une bonne habitude de vérifier le plan d'exécution et les lectures logiques pour comparer ce qui est le meilleur.
Si vous pensez que quelqu'un d'autre bénéficiera de ce message, veuillez le partager sur vos plateformes de médias sociaux préférées. Et si vous avez quelque chose à ajouter que nous avons oublié, faites-le nous savoir dans la section Commentaires ci-dessous.