L'utilisation d'un environnement multi-cloud ou multi-datacenter est utile pour les topologies géo-distribuées ou même pour un plan de reprise après sinistre, et en fait, cela devient de plus en plus populaire de nos jours, d'où le concept de split-brain devient également plus important à mesure que le risque de le voir augmenter dans ce genre de scénario. Vous devez empêcher un split-brain pour éviter la perte potentielle de données ou l'incohérence des données, ce qui pourrait être un gros problème pour l'entreprise.
Dans ce blog, nous verrons ce qu'est un split-brain et comment ClusterControl peut vous aider à éviter ce problème important.
Qu'est-ce que Split-Brain ?
Dans le monde PostgreSQL, le split-brain se produit lorsque plus d'un nœud principal est disponible en même temps (sans aucun outil tiers pour avoir un environnement multi-maître) qui permet à l'application d'écrire dans les deux nœuds. Dans ce cas, vous aurez des informations différentes sur chaque nœud, ce qui génère une incohérence des données dans le cluster. La résolution de ce problème peut être difficile car vous devez fusionner des données, ce qui n'est parfois pas possible.
PostgreSQL Split-Brain dans une topologie multi-cloud
Supposons que vous ayez la topologie multi-cloud suivante pour PostgreSQL (qui est une topologie assez courante de nos jours) :
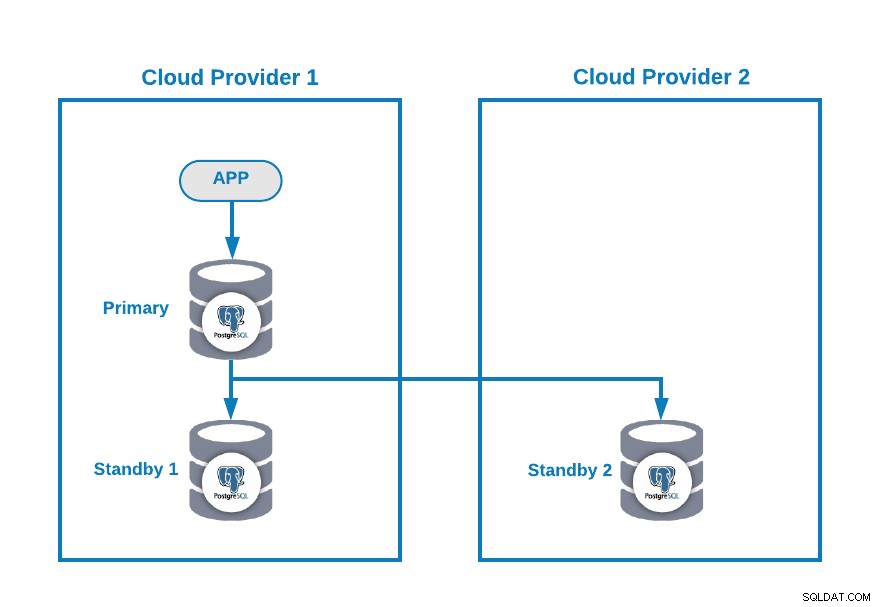
Bien entendu, vous pouvez améliorer cet environnement en ajoutant par exemple un Application Server dans le Cloud Provider 2, mais dans ce cas, utilisons cette configuration de base.
Si votre nœud principal est en panne, l'un des nœuds de secours doit être promu en tant que nouveau nœud principal et vous devez modifier l'adresse IP dans votre application pour utiliser ce nouveau nœud principal.
Il existe différentes manières de le faire de manière automatique. Par exemple, vous pouvez utiliser une adresse IP virtuelle attribuée à votre nœud principal et la surveiller. En cas d'échec, promouvez l'un des nœuds de secours et migrez l'adresse IP virtuelle vers ce nouveau nœud principal, vous n'avez donc pas besoin de modifier quoi que ce soit dans votre application, et cela peut être fait à l'aide de votre propre script ou outil.
Pour le moment, vous n'avez aucun problème, mais… si votre ancien nœud principal revient, vous devez vous assurer que vous n'aurez pas deux nœuds principaux dans le même cluster en même temps .
Les méthodes les plus courantes pour éviter cette situation sont :
- STONITH :tirez sur l'autre nœud dans la tête.
- SMITH :Je me tire une balle dans la tête.
PostgreSQL ne fournit aucun moyen d'automatiser ce processus. Vous devez le faire vous-même.
Comment éviter le Split-Brain dans PostgreSQL avec ClusterControl
Maintenant, voyons comment ClusterControl peut vous aider dans cette tâche.
Tout d'abord, vous pouvez l'utiliser pour déployer ou importer votre environnement PostgreSQL Multi-Cloud de manière simple, comme vous pouvez le voir dans cet article de blog.
Ensuite, vous pouvez améliorer votre topologie en ajoutant un équilibreur de charge (HAProxy), ce que vous pouvez également faire en utilisant ClusterControl en suivant ce blog. Ainsi, vous aurez quelque chose comme ceci :
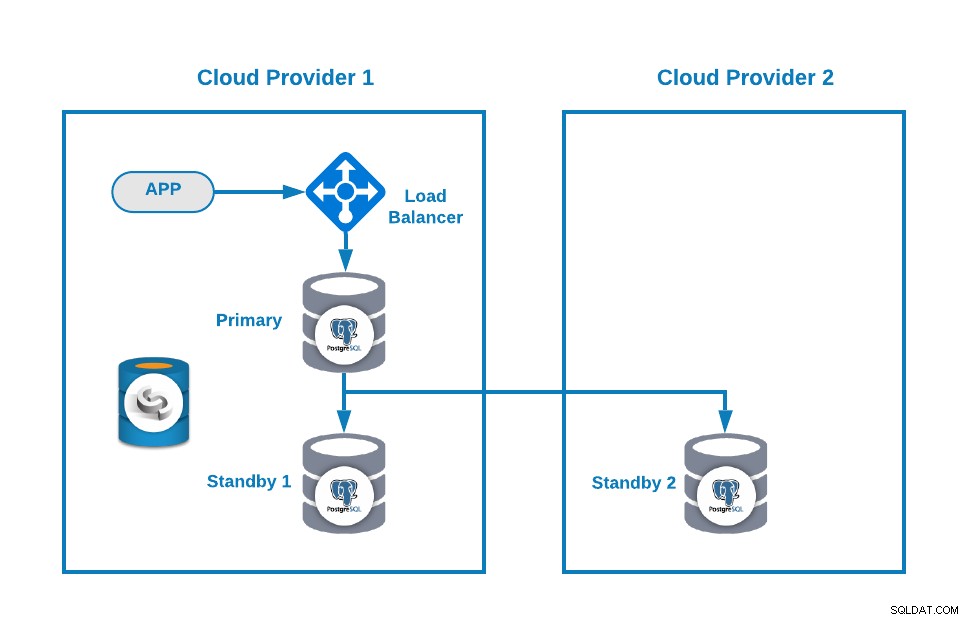
ClusterControl dispose d'une fonction de basculement automatique qui détecte les défaillances du maître et favorise une mise en veille nœud avec les données les plus récentes en tant que nouveau nœud principal. Il bascule également sur le reste des nœuds de secours pour répliquer à partir du nouveau nœud principal.
HAProxy est configuré par ClusterControl avec deux ports différents par défaut, un en lecture-écriture et un en lecture seule. Dans le port en lecture-écriture, vous avez votre nœud principal en ligne et le reste de vos nœuds hors ligne, et dans le port en lecture seule, vous avez à la fois le nœud principal et le nœud de secours en ligne. De cette façon, vous pouvez équilibrer le trafic de lecture entre vos nœuds mais vous vous assurez qu'au moment de l'écriture, le port de lecture-écriture sera utilisé, en écrivant dans le nœud principal qui est le serveur qui est en ligne.
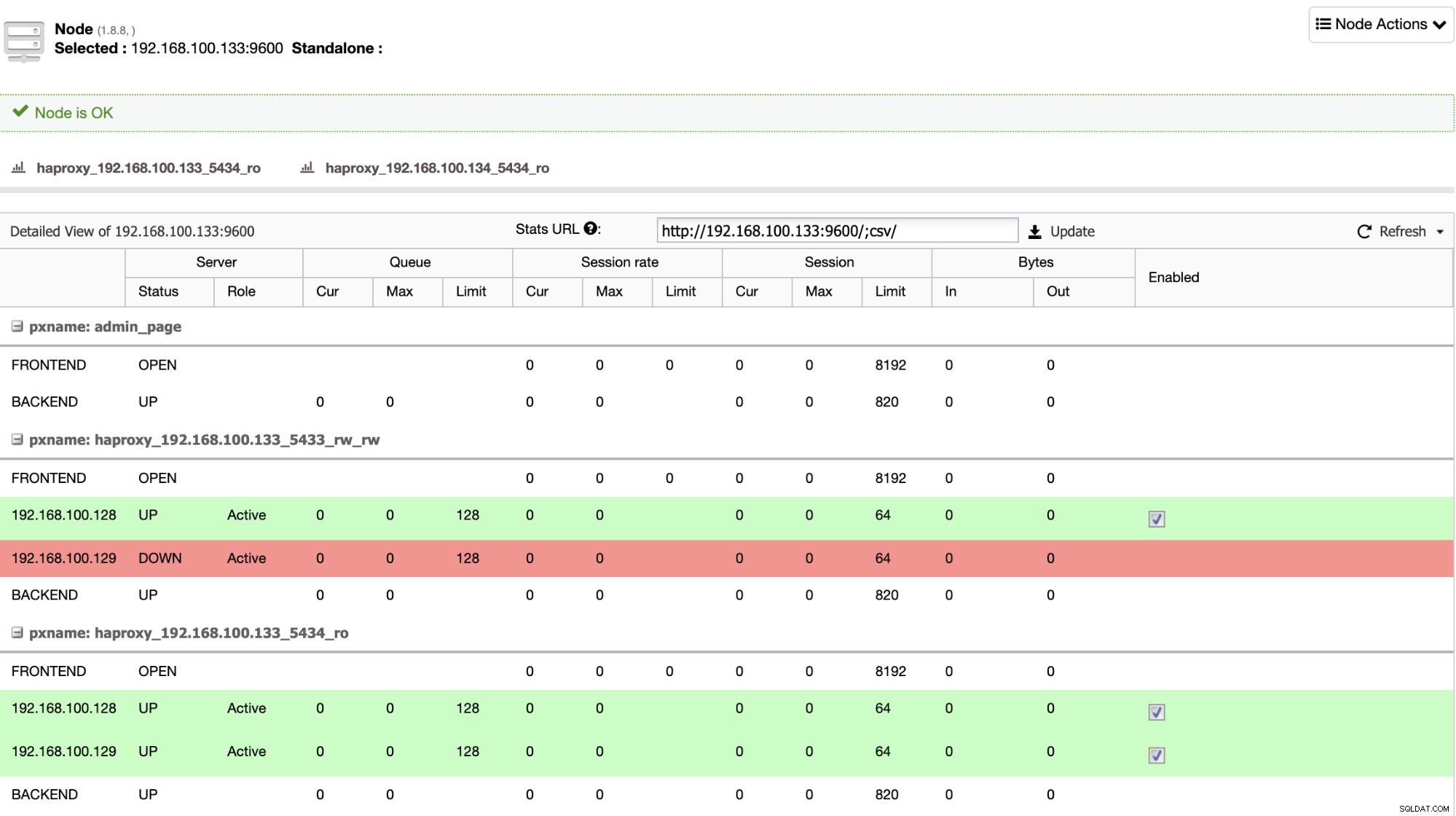
Lorsque HAProxy détecte que l'un de vos nœuds, principal ou de secours, est non accessible, il le marque automatiquement comme hors ligne et ne le prend pas en compte pour lui envoyer du trafic. Cette vérification est effectuée par des scripts de vérification de l'état configurés par ClusterControl au moment du déploiement. Ceux-ci vérifient si les instances sont actives, si elles sont en cours de récupération ou sont en lecture seule.
Si votre ancien nœud principal revient, ClusterControl évitera également de le démarrer, pour éviter un éventuel split-brain au cas où vous auriez une connexion directe qui n'utilise pas le Load Balancer, mais vous pouvez l'ajouter au cluster en tant que nœud de secours de manière automatique ou manuelle à l'aide de l'interface utilisateur ou de la CLI de ClusterControl, vous pouvez alors le promouvoir pour qu'il ait la même topologie que celle que vous aviez en cours d'exécution avant le problème.
Conclusion
Lorsque l'option "Récupération automatique" est activée, ClusterControl effectuera ce basculement automatique et vous informera du problème. De cette façon, vos systèmes peuvent récupérer en quelques secondes sans votre intervention et vous éviterez un split-brain dans un environnement PostgreSQL Multi-Cloud.
Vous pouvez également améliorer votre environnement haute disponibilité en ajoutant davantage de nœuds ClusterControl à l'aide de la fonctionnalité CMON HA décrite dans ce blog.