La suppression et la prévention de la fragmentation des index font depuis longtemps partie des opérations normales de maintenance des bases de données, non seulement dans SQL Server, mais sur de nombreuses plates-formes. La fragmentation d'index affecte les performances pour de nombreuses raisons, et la plupart des gens parlent des effets de petits blocs aléatoires d'E/S qui peuvent se produire physiquement sur le stockage sur disque comme quelque chose à éviter. La préoccupation générale concernant la fragmentation d'index est qu'elle affecte les performances des analyses en limitant la taille des E/S en lecture anticipée. C'est sur la base de cette compréhension limitée des problèmes causés par la fragmentation d'index que certaines personnes ont commencé à faire circuler l'idée que la fragmentation d'index n'a pas d'importance avec les périphériques de stockage à semi-conducteurs (SSD) et que vous pouvez simplement ignorer la fragmentation d'index à l'avenir.
Cependant, ce n'est pas le cas pour un certain nombre de raisons. Cet article explique et démontre l'une de ces raisons :la fragmentation de l'index peut avoir un impact négatif sur le choix du plan d'exécution des requêtes. Cela se produit parce que la fragmentation de l'index conduit généralement à un index ayant plus de pages (ces pages supplémentaires proviennent du fractionnement de page opérations, comme décrit dans cet article sur ce site), et donc l'utilisation de cet index est considérée comme ayant un coût plus élevé par l'optimiseur de requêtes de SQL Server.
Prenons un exemple.
La première chose que nous devons faire est de créer une base de données de test appropriée et un ensemble de données à utiliser pour examiner l'impact de la fragmentation d'index sur le choix du plan de requête dans SQL Server. Le script suivant créera une base de données avec deux tables avec des données identiques, une fortement fragmentée et une peu fragmentée.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Après avoir reconstruit l'index, nous pouvons regarder les niveaux de fragmentation avec la requête suivante :
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Résultats :

Ici, nous pouvons voir que notre GuidHighFragmentation la table est fragmentée à 99 % et utilise 31 % d'espace de page en plus que la GuidLowFragmentation table dans la base de données, bien qu'ils aient les mêmes 7 000 000 lignes de données. Si nous effectuons une requête d'agrégation de base sur chacune des tables et comparons les plans d'exécution sur une installation par défaut (avec les options de configuration et les valeurs par défaut) de SQL Server à l'aide de SentryOne Plan Explorer :
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


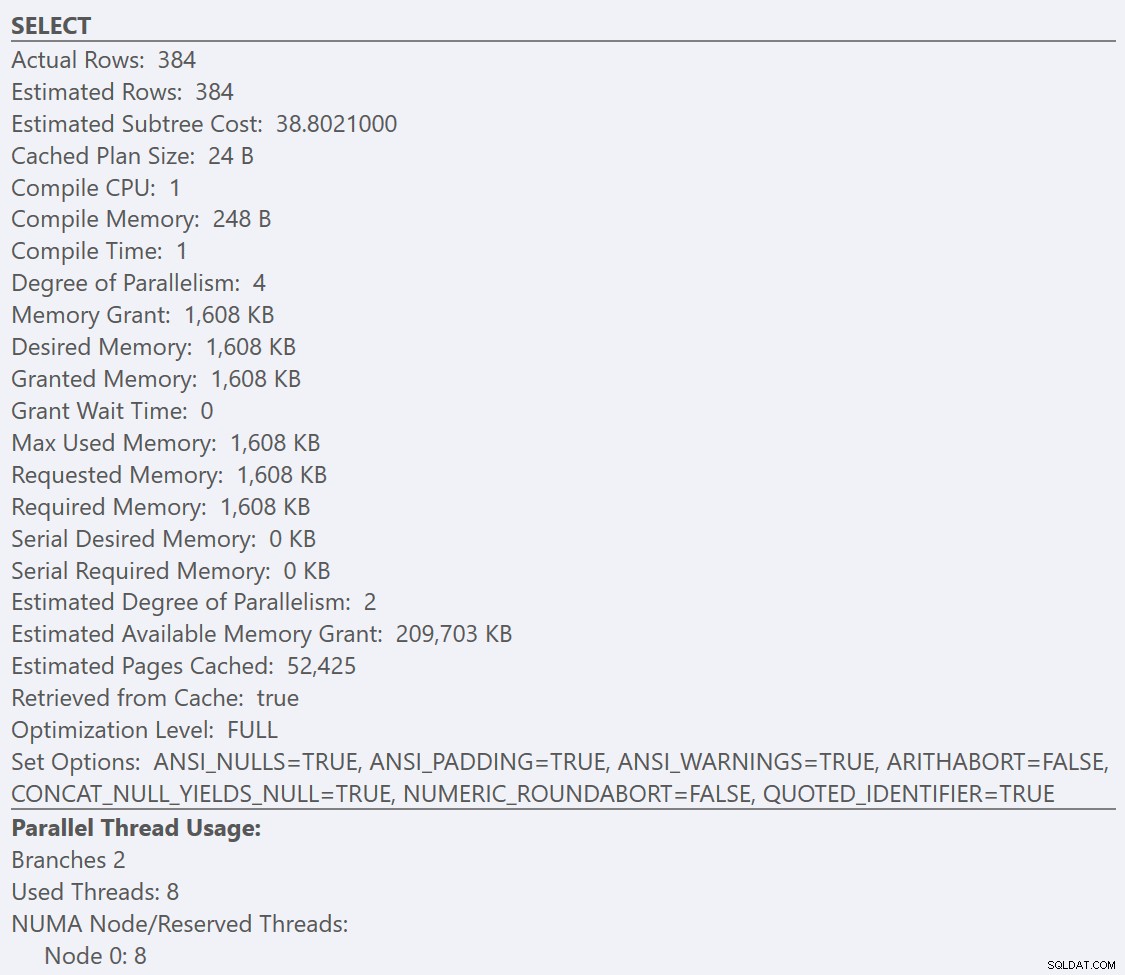

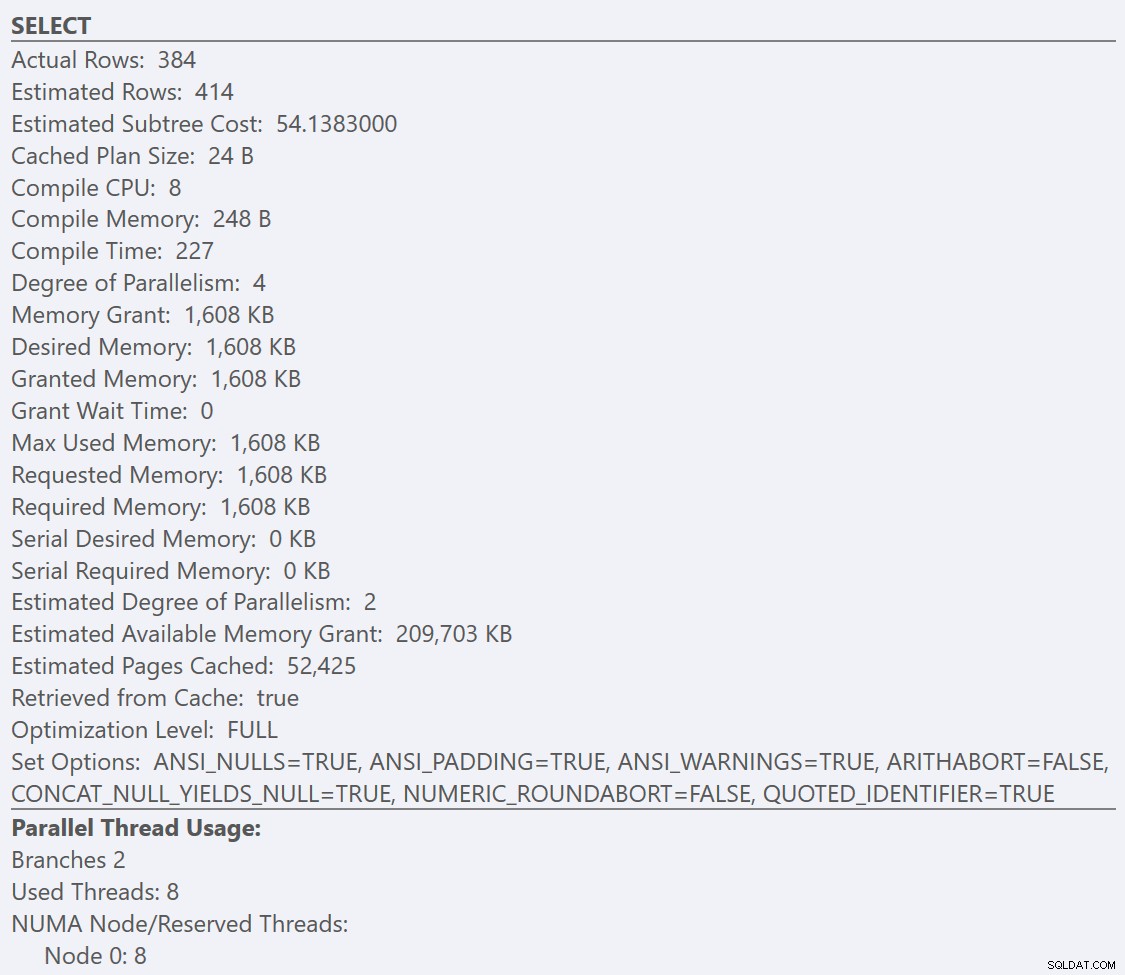
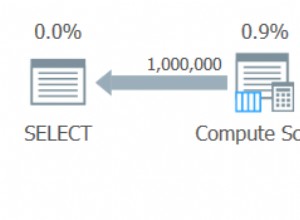
Si nous regardons les info-bulles de la SELECT opérateur pour chaque plan, le plan pour la GuidLowFragmentation table a un coût de requête de 38,80 (la troisième ligne à partir du haut de l'info-bulle) contre un coût de requête de 54,14 pour le plan du plan GuidHighFragmentation.
Dans une configuration par défaut pour SQL Server, ces deux requêtes finissent par générer un plan d'exécution parallèle puisque le coût estimé de la requête est supérieur au "seuil de coût pour le parallélisme" de l'option sp_configure par défaut de 5. Cela est dû au fait que l'optimiseur de requête produit d'abord une série plan (qui ne peut être exécuté que par un seul thread) lors de la compilation du plan d'une requête. Si le coût estimé de ce plan en série dépasse la valeur configurée du « seuil de coût pour le parallélisme », un plan parallèle est généré et mis en cache à la place.
Cependant, que se passe-t-il si l'option sp_configure 'cost threshold for parallelism' n'est pas définie sur la valeur par défaut de 5 et est définie plus haut ? C'est une bonne pratique (et une bonne pratique) d'augmenter cette option de la faible valeur par défaut de 5 à n'importe où entre 25 et 50 (ou même beaucoup plus) pour éviter que les petites requêtes n'encourent la surcharge supplémentaire d'aller en parallèle.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Après avoir suivi les bonnes pratiques et augmenté le « seuil de coût pour le parallélisme » à 50, la réexécution des requêtes aboutit au même plan d'exécution pour GuidHighFragmentation table, mais la GuidLowFragmentation le coût en série de la requête, 44,68, est maintenant inférieur à la valeur du « seuil de coût pour le parallélisme » (rappelez-vous que son coût parallèle estimé était de 38,80), nous obtenons donc un plan d'exécution en série :
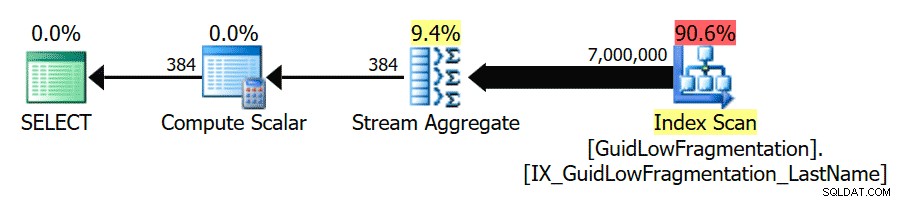
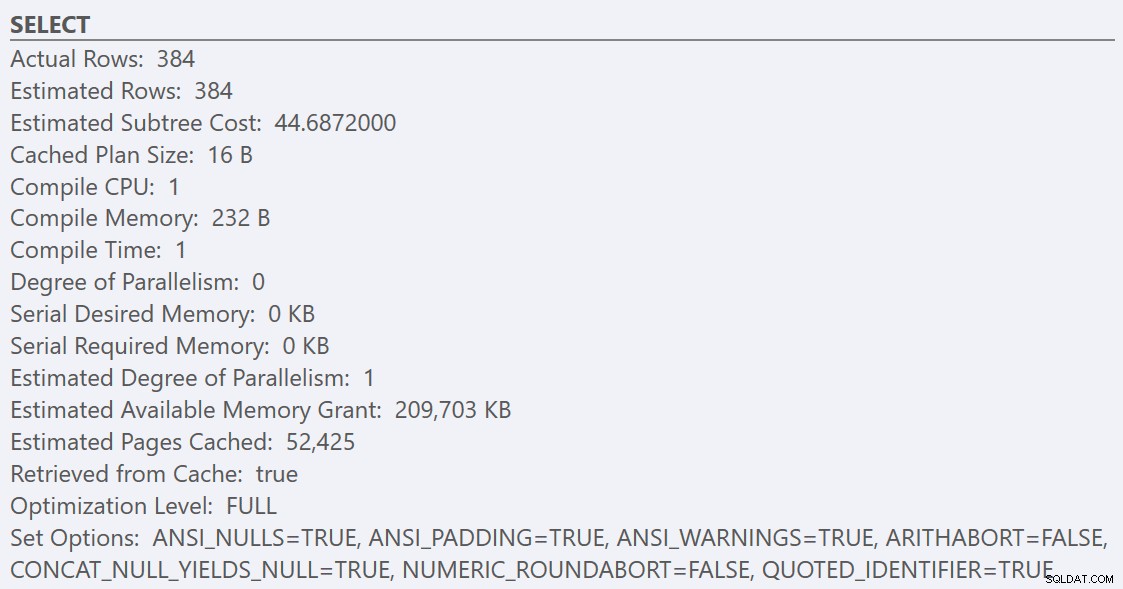
L'espace de page supplémentaire dans le GuidHighFragmentation l'index clusterisé a maintenu le coût au-dessus du paramètre de meilleure pratique pour le "seuil de coût pour le parallélisme" et a abouti à un plan parallèle.
Imaginez maintenant qu'il s'agit d'un système dans lequel vous avez suivi les conseils de bonnes pratiques et configuré initialement le « seuil de coût pour le parallélisme » à une valeur de 50. Puis, plus tard, vous avez suivi le conseil erroné d'ignorer complètement la fragmentation de l'index.
Au lieu d'être une requête de base, elle est plus complexe, mais si elle est également exécutée très fréquemment sur votre système, et en raison de la fragmentation de l'index, le nombre de pages fait pencher le coût vers un plan parallèle, il utilisera plus de CPU et impact sur les performances globales de la charge de travail.
Que fais-tu? Augmentez-vous le « seuil de coût pour le parallélisme » afin que la requête maintienne un plan d'exécution en série ? Est-ce que vous indiquez la requête avec OPTION(MAXDOP 1) et la forcez simplement à un plan d'exécution en série ?
Gardez à l'esprit que la fragmentation d'index n'affecte probablement pas qu'une seule table de votre base de données, maintenant que vous l'ignorez complètement; il est probable que de nombreux index clusterisés et non clusterisés soient fragmentés et aient un nombre de pages plus élevé que nécessaire, de sorte que les coûts de nombreuses opérations d'E/S augmentent en raison de la fragmentation généralisée de l'index, ce qui peut entraîner de nombreuses requêtes inefficaces plans.
Résumé
Vous ne pouvez pas simplement ignorer complètement la fragmentation des index comme certains pourraient vouloir vous le faire croire. Entre autres inconvénients, les coûts cumulés d'exécution des requêtes vous rattraperont, avec des changements de plan de requête car l'optimiseur de requête est un optimiseur basé sur les coûts et considère donc à juste titre ces index fragmentés comme plus coûteux à utiliser.
Les requêtes et le scénario ici sont évidemment artificiels, mais nous avons vu des changements de plan d'exécution causés par la fragmentation dans la vie réelle sur les systèmes clients.
Vous devez vous assurer que vous traitez la fragmentation des index pour les index où la fragmentation entraîne des problèmes de performances de la charge de travail, quel que soit le matériel que vous utilisez.