Un index de prise en charge peut potentiellement aider à éviter le besoin d'un tri explicite dans le plan de requête lors de l'optimisation des requêtes T-SQL impliquant des fonctions de fenêtre. Par un index de support, Je veux dire une avec les éléments de partitionnement et d'ordonnancement de la fenêtre comme clé d'index, et le reste des colonnes qui apparaissent dans la requête en tant que colonnes incluses d'index. J'appelle souvent un tel modèle d'indexation un POC index comme acronyme pour partitionnement , commande, et couvrant . Naturellement, si un élément de partitionnement ou de classement n'apparaît pas dans la fonction de fenêtre, vous omettez cette partie de la définition de l'index.
Mais qu'en est-il des requêtes impliquant plusieurs fonctions de fenêtre avec des besoins de classement différents ? De même, que se passe-t-il si d'autres éléments de la requête, en plus des fonctions de fenêtre, nécessitent également d'organiser les données d'entrée selon l'ordre dans le plan, comme une clause de présentation ORDER BY ? Il peut en résulter que différentes parties du plan doivent traiter les données d'entrée dans des ordres différents.
Dans de telles circonstances, vous accepterez généralement que le tri explicite soit inévitable dans le plan. Vous pouvez constater que l'arrangement syntaxique des expressions dans la requête peut affecter combien opérateurs de tri explicites que vous obtenez dans le plan. En suivant quelques conseils de base, vous pouvez parfois réduire le nombre d'opérateurs de tri explicites, ce qui peut, bien sûr, avoir un impact majeur sur les performances de la requête.
Environnement pour les démos
Dans mes exemples, j'utiliserai l'exemple de base de données PerformanceV5. Vous pouvez télécharger le code source pour créer et alimenter cette base de données ici.
J'ai exécuté tous les exemples sur SQL Server 2019 Developer, où le mode batch sur rowstore est disponible.
Dans cet article, je souhaite me concentrer sur les conseils liés au potentiel du calcul de la fonction de fenêtre dans le plan pour s'appuyer sur des données d'entrée ordonnées sans nécessiter une activité de tri explicite supplémentaire dans le plan. Ceci est pertinent lorsque l'optimiseur utilise un traitement série ou parallèle en mode ligne des fonctions de fenêtre, et lors de l'utilisation d'un opérateur d'agrégation de fenêtre en mode batch série.
SQL Server ne prend actuellement pas en charge une combinaison efficace d'une entrée de préservation de l'ordre parallèle avant un opérateur Window Aggregate en mode batch parallèle. Ainsi, pour utiliser un opérateur d'agrégation de fenêtres en mode batch parallèle, l'optimiseur doit injecter un opérateur de tri intermédiaire en mode batch parallèle, même lorsque l'entrée est déjà préordonnée.
Par souci de simplicité, vous pouvez empêcher le parallélisme dans tous les exemples présentés dans cet article. Pour y parvenir sans avoir besoin d'ajouter un indice à toutes les requêtes et sans définir d'option de configuration à l'échelle du serveur, vous pouvez définir l'option de configuration étendue à la base de données MAXDOP à 1 , comme ceci :
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
N'oubliez pas de le remettre à 0 après avoir testé les exemples de cet article. Je vous rappellerai à la fin.
Alternativement, vous pouvez empêcher le parallélisme au niveau de la session avec le non documenté DBCC OPTIMIZER_WHATIF commande, comme ceci :
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Pour réinitialiser l'option lorsque vous avez terminé, appelez-la à nouveau avec la valeur 0 comme nombre de processeurs.
Lorsque vous avez fini d'essayer tous les exemples de cet article avec le parallélisme désactivé, je vous recommande d'activer le parallélisme et de réessayer tous les exemples pour voir ce qui change.
Conseils 1 et 2
Avant de commencer avec les conseils, examinons d'abord un exemple simple avec une fonction de fenêtre conçue pour bénéficier d'un supp class="border indent shadow orting index.
Considérez la requête suivante, que j'appellerai la requête 1 :
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Ne vous inquiétez pas du fait que l'exemple est artificiel. Il n'y a aucune bonne raison commerciale de calculer un total cumulé d'ID de commande - cette table est correctement dimensionnée avec des lignes de 1 MM, et je voulais montrer un exemple simple avec une fonction de fenêtre courante telle que celle qui applique un calcul de total cumulé.
En suivant le schéma d'indexation POC, vous créez l'index suivant pour prendre en charge la requête :
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Le plan de cette requête est illustré à la figure 1.
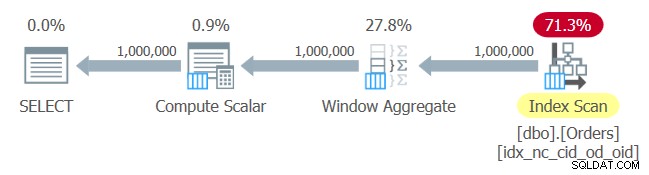 Figure 1 :Plan pour la requête 1
Figure 1 :Plan pour la requête 1
Pas de surprise ici. Le plan applique une analyse de l'ordre d'index de l'index que vous venez de créer, fournissant les données commandées à l'opérateur Window Aggregate, sans avoir besoin d'un tri explicite.
Considérons ensuite la requête suivante, qui implique plusieurs fonctions de fenêtre avec différents besoins de classement, ainsi qu'une clause ORDER BY de présentation :
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Je ferai référence à cette requête sous le nom de requête 2. Le plan de cette requête est illustré à la figure 2.
 Figure 2 :Plan pour la requête 2
Figure 2 :Plan pour la requête 2
Notez qu'il y a quatre opérateurs de tri dans le plan.
Si vous analysez les différentes fonctions de la fenêtre et les besoins de commande de présentation, vous constaterez qu'il existe trois besoins de commande distincts :
- custid, orderdate, orderid
- ID de commande
- custid, orderid
Étant donné que l'un d'entre eux (le premier de la liste ci-dessus) peut être pris en charge par l'index que vous avez créé précédemment, vous vous attendez à ne voir que deux tris dans le plan. Alors, pourquoi le plan a-t-il quatre sortes ? Il semble que SQL Server n'essaie pas d'être trop sophistiqué en réorganisant l'ordre de traitement des fonctions dans le plan pour minimiser les tris. Il traite les fonctions du plan dans l'ordre dans lequel elles apparaissent dans la requête. C'est au moins le cas pour la première occurrence de chaque besoin de commande distinct, mais je vais développer cela sous peu.
Vous pouvez supprimer le besoin de certains tris dans le plan en appliquant les deux pratiques simples suivantes :
Astuce 1 :Si vous disposez d'un index pour prendre en charge certaines fonctions de fenêtre dans la requête, spécifiez-les d'abord.
Astuce 2 :Si la requête implique des fonctions de fenêtre avec le même besoin d'ordre que l'ordre de présentation dans la requête, spécifiez ces fonctions en dernier.
En suivant ces conseils, vous réorganisez l'ordre d'apparition des fonctions de la fenêtre dans la requête comme suit :
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Je ferai référence à cette requête sous le nom de requête 3. Le plan de cette requête est illustré à la figure 3.
 Figure 3 :Plan pour la requête 3
Figure 3 :Plan pour la requête 3
Comme vous pouvez le voir, le plan n'a plus que deux sortes.
Astuce 3
SQL Server n'essaie pas d'être trop sophistiqué dans la réorganisation de l'ordre de traitement des fonctions de fenêtre dans le but de minimiser les tris dans le plan. Cependant, il est capable d'un certain réarrangement simple. Il analyse les fonctions de fenêtre en fonction de l'ordre d'apparition dans la requête et chaque fois qu'il détecte un nouveau besoin de commande distinct, il recherche des fonctions de fenêtre supplémentaires avec le même besoin de commande et s'il les trouve, il les regroupe avec la première occurrence. Dans certains cas, il peut même utiliser le même opérateur pour calculer plusieurs fonctions de fenêtre.
Considérez la requête suivante comme exemple :
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Je ferai référence à cette requête en tant que requête 4. Le plan de cette requête est illustré à la figure 4.
 Figure 4 :Plan pour la requête 4
Figure 4 :Plan pour la requête 4
Les fonctions de fenêtre avec les mêmes besoins de commande ne sont pas regroupées dans la requête. Cependant, il n'y a encore que deux sortes dans le plan. En effet, ce qui compte en termes de traitement de la commande dans le plan, c'est la première occurrence de chaque besoin de commande distinct. Cela m'amène au troisième conseil.
Astuce 3 :assurez-vous de suivre les conseils 1 et 2 pour la première occurrence de chaque besoin de commande distinct. Les occurrences suivantes du même besoin de commande, même si elles ne sont pas adjacentes, sont identifiées et regroupées avec la première.
Conseils 4 et 5
Supposons que vous souhaitiez renvoyer des colonnes résultant de calculs fenêtrés dans un certain ordre de gauche à droite dans la sortie. Mais que se passe-t-il si la commande n'est pas la même que celle qui minimise les tris dans le plan ?
Par exemple, supposons que vous vouliez le même résultat que celui produit par la requête 2 en termes d'ordre des colonnes de gauche à droite dans la sortie (ordre des colonnes :autres colonnes, somme2, somme1, somme3), mais vous préféreriez avoir le même plan que celui que vous avez obtenu pour la requête 3 (ordre des colonnes :autres colonnes, somme1, somme3, somme2), qui a obtenu deux tris au lieu de quatre.
C'est parfaitement faisable si vous connaissez le quatrième conseil.
Astuce 4 :Les recommandations susmentionnées s'appliquent à l'ordre d'apparition des fonctions de fenêtre dans le code, même si elles se trouvent dans une expression de table nommée telle qu'un CTE ou une vue, et même si la requête externe renvoie les colonnes dans un ordre différent de celui de la expression de table nommée. Par conséquent, si vous devez renvoyer des colonnes dans un certain ordre dans la sortie, et qu'il est différent de l'ordre optimal en termes de minimisation des tris dans le plan, suivez les conseils en termes d'ordre d'apparition dans une expression de table nommée et renvoyez les colonnes dans la requête externe dans l'ordre de sortie souhaité.
La requête suivante, que j'appellerai la requête 5, illustre cette technique :
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Le plan de cette requête est illustré à la figure 5.
 Figure 5 :Plan pour la requête 5
Figure 5 :Plan pour la requête 5
Vous n'obtenez toujours que deux tris dans le plan malgré le fait que l'ordre des colonnes dans la sortie est :other cols, sum2, sum1, sum3, comme dans la requête 2.
Une mise en garde à cette astuce avec l'expression de table nommée est que si vos colonnes dans l'expression de table ne sont pas référencées par la requête externe, elles sont exclues du plan et ne comptent donc pas.
Considérez la requête suivante, que j'appellerai la requête 6 :
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Ici, toutes les colonnes d'expression de table sont référencées par la requête externe, de sorte que l'optimisation se produit en fonction de la première occurrence distincte de chaque besoin de tri dans l'expression de table :
- max1 :custid, orderdate, orderid
- max3 :ID de commande
- max2 :custid, orderid
Cela se traduit par un plan avec seulement deux tris, comme illustré à la figure 6.
 Figure 6 :Plan pour la requête 6
Figure 6 :Plan pour la requête 6
Maintenant, modifiez uniquement la requête externe en supprimant les références à max2, max1, max3, avg2, avg1 et avg3, comme ceci :
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Je ferai référence à cette requête en tant que requête 7. Les calculs de max1, max3, max2, avg1, avg3 et avg2 dans l'expression de table ne sont pas pertinents pour la requête externe, ils sont donc exclus. Les calculs restants impliquant des fonctions de fenêtre dans l'expression de table, qui sont pertinentes pour la requête externe, sont ceux de sum2, sum1 et sum3. Malheureusement, ils n'apparaissent pas dans l'expression de table dans l'ordre optimal en termes de minimisation des tris. Comme vous pouvez le voir dans le plan de cette requête illustrée à la figure 7, il existe quatre tris.
 Figure 7 :Plan pour la requête 7
Figure 7 :Plan pour la requête 7
Si vous pensez qu'il est peu probable que vous ayez des colonnes dans la requête interne auxquelles vous ne ferez pas référence dans la requête externe, pensez aux vues. Chaque fois que vous interrogez une vue, vous pouvez être intéressé par un sous-ensemble différent des colonnes. Dans cet esprit, le cinquième conseil pourrait aider à réduire les tris dans le plan.
Astuce 5 :dans la requête interne d'une expression de table nommée telle qu'un CTE ou une vue, regroupez toutes les fonctions de fenêtre avec les mêmes besoins d'ordre, et suivez les conseils 1 et 2 dans l'ordre des groupes de fonctions.
Le code suivant implémente une vue basée sur cette recommandation :
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Interrogez maintenant la vue en demandant uniquement les colonnes de résultats fenêtrées sum2, sum1 et sum3, dans cet ordre :
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Je ferai référence à cette requête sous le nom de requête 8. Vous obtenez le plan illustré à la figure 8 avec seulement deux tris.
 Figure 8 :Plan pour la requête 8
Figure 8 :Plan pour la requête 8
Astuce 6
Lorsque vous avez une requête avec plusieurs fonctions de fenêtre avec plusieurs besoins de commande distincts, la sagesse commune est que vous ne pouvez prendre en charge qu'une seule d'entre elles avec des données préordonnées via un index. C'est le cas même lorsque toutes les fonctions de fenêtre ont des index de support respectifs.
Permettez-moi de le démontrer. Rappelez-vous plus tôt lorsque vous avez créé l'index idx_nc_cid_od_oid, qui peut prendre en charge les fonctions de fenêtre nécessitant les données triées par custid, orderdate, orderid, comme l'expression suivante :
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Supposons qu'en plus de cette fonction de fenêtre, vous ayez également besoin de la fonction de fenêtre suivante dans la même requête :
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Cette fonction de fenêtre bénéficierait de l'index suivant :
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
La requête suivante, que j'appellerai la requête 9, appelle les deux fonctions de fenêtre :
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Le plan de cette requête est illustré à la figure 9.
 Figure 9 :Plan pour la requête 9
Figure 9 :Plan pour la requête 9
J'obtiens les statistiques temporelles suivantes pour cette requête sur ma machine, les résultats étant ignorés dans SSMS :
CPU time = 3234 ms, elapsed time = 3354 ms.
Comme expliqué précédemment, SQL Server analyse les expressions fenêtrées par ordre d'apparition dans la requête et détermine qu'il peut prendre en charge la première avec une analyse ordonnée de l'index idx_nc_cid_od_oid. Mais ensuite, il ajoute un opérateur de tri au plan pour ordonner les données comme les besoins de la deuxième fonction de fenêtre. Cela signifie que le plan a une mise à l'échelle N log N. Il n'envisage pas d'utiliser l'index idx_nc_cid_oid pour prendre en charge la deuxième fonction de fenêtre. Vous pensez probablement que ce n'est pas possible, mais essayez de sortir un peu des sentiers battus. Ne pourriez-vous pas calculer chacune des fonctions de fenêtre en fonction de son ordre d'index respectif, puis joindre les résultats ? Théoriquement, vous pouvez, et en fonction de la taille des données, de la disponibilité de l'indexation et des autres ressources disponibles, la version jointure peut parfois faire mieux. SQL Server n'envisage pas cette approche, mais vous pouvez certainement l'implémenter en écrivant la jointure vous-même, comme ceci :
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Je ferai référence à cette requête sous le nom de requête 10. Le plan de cette requête est illustré à la figure 10.
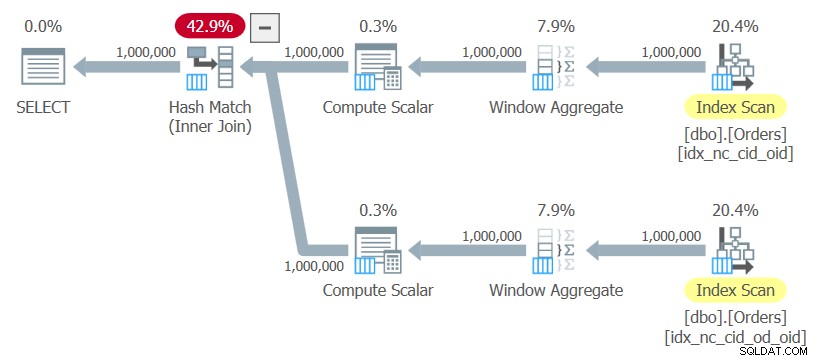 Figure 10 :Plan pour la requête 10
Figure 10 :Plan pour la requête 10
Le plan utilise des analyses ordonnées des deux index sans aucun tri explicite, calcule les fonctions de fenêtre et utilise une jointure par hachage pour joindre les résultats. Ce plan évolue de manière linéaire par rapport au précédent qui a une mise à l'échelle N log N.
J'obtiens les statistiques de temps suivantes pour cette requête sur ma machine (encore une fois avec les résultats ignorés dans SSMS) :
CPU time = 1000 ms, elapsed time = 1100 ms.
Pour récapituler, voici notre sixième conseil.
Astuce 6 :Lorsque vous avez plusieurs fonctions de fenêtre avec plusieurs besoins de classement distincts et que vous pouvez toutes les prendre en charge avec des index, essayez une version jointe et comparez ses performances à la requête sans jointure.
Nettoyage
Si vous avez désactivé le parallélisme en définissant l'option de configuration étendue à la base de données MAXDOP sur 1, réactivez le parallélisme en le définissant sur 0 :
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Si vous avez utilisé l'option de session non documentée DBCC OPTIMIZER_WHATIF avec l'option CPUs définie sur 1, réactivez le parallélisme en le définissant sur 0 :
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Vous pouvez réessayer tous les exemples avec le parallélisme activé si vous le souhaitez.
Utilisez le code suivant pour nettoyer les nouveaux index que vous avez créés :
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Et le code suivant pour supprimer la vue :
DROP VIEW IF EXISTS dbo.MyView;
Suivez les conseils pour minimiser le nombre de tris
Les fonctions de fenêtre doivent traiter les données d'entrée commandées. L'indexation peut aider à éliminer le tri dans le plan, mais normalement uniquement pour un besoin de commande distinct. Les requêtes avec plusieurs besoins de commande impliquent généralement certaines sortes dans leurs plans. Cependant, en suivant certains conseils, vous pouvez minimiser le nombre de tris nécessaires. Voici un résumé des conseils que j'ai mentionnés dans cet article :
- Conseil 1 : Si vous avez un index pour prendre en charge certaines des fonctions de fenêtre dans la requête, spécifiez-les d'abord.
- Astuce 2 : Si la requête implique des fonctions de fenêtre avec le même besoin d'ordre que l'ordre de présentation dans la requête, spécifiez ces fonctions en dernier.
- Astuce 3 : Assurez-vous de suivre les conseils 1 et 2 pour la première occurrence de chaque besoin de commande distinct. Les occurrences ultérieures du même besoin de commande, même si elles ne sont pas adjacentes, sont identifiées et regroupées avec la première.
- Conseil 4 : Les recommandations susmentionnées s'appliquent à l'ordre d'apparition des fonctions de fenêtre dans le code, même dans une expression de table nommée telle qu'un CTE ou une vue, et même si la requête externe renvoie les colonnes dans un ordre différent de celui de l'expression de table nommée. Par conséquent, si vous devez renvoyer des colonnes dans un certain ordre dans la sortie, et qu'il est différent de l'ordre optimal en termes de minimisation des tris dans le plan, suivez les conseils en termes d'ordre d'apparition dans une expression de table nommée et renvoyez les colonnes dans la requête externe dans l'ordre de sortie souhaité.
- Conseil 5 : Dans la requête interne d'une expression de table nommée comme un CTE ou une vue, regroupez toutes les fonctions de fenêtre avec les mêmes besoins de classement et suivez les conseils 1 et 2 dans l'ordre des groupes de fonctions.
- Conseil 6 : Lorsque vous avez plusieurs fonctions de fenêtre avec plusieurs besoins de classement distincts et que vous êtes en mesure de toutes les prendre en charge avec des index, essayez une version de jointure et comparez ses performances à la requête sans jointure.