Il y a quelques semaines, l'équipe SQLskills était à Tampa pour notre Performance Tuning Immersion Event (IE2) et je couvrais les lignes de base. Les lignes de base sont un sujet qui me tient à cœur, car elles sont si précieuses pour de nombreuses raisons. Deux de ces raisons, que j'évoque toujours que ce soit en enseignant ou en travaillant avec des clients, utilisent des lignes de base pour dépanner les performances, puis également les tendances d'utilisation et fournissent des estimations de planification de capacité. Mais ils sont également essentiels lorsque vous effectuez des réglages ou des tests de performances, que vous considériez ou non vos mesures de performances existantes comme des références.
Au cours du module, j'ai examiné différentes sources de données telles que Performance Monitor, les DMV et les données de trace ou XE, et une question liée aux chargements de données s'est posée. Plus précisément, la question était de savoir s'il était préférable de charger des données dans une table sans index, puis de les créer une fois terminé, plutôt que d'avoir les index en place pendant le chargement des données. Ma réponse a été :"Généralement, oui". Mon expérience personnelle a été que c'est toujours le cas, mais vous ne savez jamais à quelle mise en garde ou à quel scénario ponctuel quelqu'un pourrait être confronté lorsque le changement de performances ne correspond pas à ce qui était attendu, et comme avec toutes les questions de performance, vous ne savez pas avec certitude tant que vous ne l'avez pas testée. Jusqu'à ce que vous établissiez une ligne de base pour une méthode et que vous voyiez ensuite si l'autre méthode améliore cette ligne de base, vous ne faites que deviner. J'ai pensé que ce serait amusant de tester ce scénario, non seulement pour prouver ce que je pense être vrai, mais aussi pour montrer quelles métriques j'examinerais, pourquoi et comment les capturer. Si vous avez déjà effectué des tests de performances, c'est probablement un vieux chapeau. Mais pour ceux Si vous êtes nouveau dans la pratique, je vais suivre le processus que je suis pour vous aider à démarrer. Sachez qu'il existe de nombreuses façons d'obtenir la réponse à la question "Quelle méthode est la meilleure ?" Je m'attends à ce que vous preniez ce processus, que vous le modifiiez et que vous vous l'appropriiez au fil du temps.
Qu'essayez-vous de prouver ?
La première étape consiste à décider exactement ce que vous testez. Dans notre cas, c'est simple :est-il plus rapide de charger des données dans une table vide, puis d'ajouter les index, ou est-il plus rapide d'avoir les index sur la table pendant le chargement des données ? Mais, nous pouvons ajouter quelques variations ici si nous le voulons. Considérez le temps nécessaire pour charger les données dans un tas, puis créer les index cluster et non cluster, par rapport au temps nécessaire pour charger les données dans un index cluster, puis créer les index non cluster. Y a-t-il une différence de performances ? La clé de clustering serait-elle un facteur ? Je m'attends à ce que le chargement des données provoque la fragmentation des index non clusterisés existants. Je souhaite donc peut-être voir quel impact la reconstruction des index après le chargement a sur la durée totale. Il est important de définir cette étape autant que possible et d'être très précis sur ce que vous voulez mesurer, car cela déterminera les données que vous capturez. Pour notre exemple, nos quatre tests seront :
Test 1 : Charger les données dans un tas, créer l'index clusterisé, créer les index non clusterisés
Test 2 : Charger les données dans un index clusterisé, créer les index non clusterisés
Test 3 : Créez l'index cluster et les index non cluster, chargez les données
Test 4 : Créer l'index cluster et les index non cluster, charger les données, reconstruire les index non cluster
Que devez-vous savoir ?
Dans notre scénario, notre principale question est "quelle méthode est la plus rapide" ? Par conséquent, nous voulons mesurer la durée et pour ce faire, nous devons saisir une heure de début et une heure de fin. Nous pourrions en rester là, mais nous voudrions peut-être comprendre à quoi ressemble l'utilisation des ressources pour chaque méthode, ou peut-être voulons-nous connaître les attentes les plus élevées, ou le nombre de transactions, ou le nombre de blocages. Les données les plus intéressantes et pertinentes dépendront des processus que vous comparez. Capturer le nombre de transactions n'est pas si intéressant pour notre charge de données ; mais pour un changement de code, cela pourrait être le cas. Étant donné que nous créons des index et que nous les reconstruisons, je suis intéressé par la quantité d'E/S générée par chaque méthode. Bien que la durée globale soit probablement le facteur décisif en fin de compte, l'examen des E/S peut être utile non seulement pour comprendre quelle option génère le plus d'E/S, mais également si le stockage de la base de données fonctionne comme prévu.
Où se trouvent les données dont vous avez besoin ?
Une fois que vous avez déterminé les données dont vous avez besoin, décidez d'où elles seront capturées. Nous nous intéressons à la durée, nous voulons donc enregistrer l'heure à laquelle chaque test de chargement de données commence et quand il se termine. Nous nous intéressons également aux E/S, et nous pouvons extraire ces données de plusieurs emplacements – les compteurs de l'Analyseur de performances et le DMV sys.dm_io_virtual_file_stats nous viennent à l'esprit.
Comprenez que nous pourrions obtenir ces données manuellement. Avant d'exécuter un test, nous pouvons sélectionner sys.dm_io_virtual_file_stats et enregistrer les valeurs actuelles dans un fichier. On peut noter l'heure, puis lancer le test. Une fois terminé, nous notons à nouveau l'heure, interrogeons à nouveau sys.dm_io_virtual_file_stats et calculons les différences entre les valeurs pour mesurer les E/S.
Il y a de nombreux défauts dans cette méthodologie, à savoir qu'elle laisse une marge d'erreur importante; que se passe-t-il si vous oubliez de noter l'heure de début ou si vous oubliez de capturer les statistiques du fichier avant de commencer ? Une bien meilleure solution consiste à automatiser non seulement l'exécution du script, mais également la capture de données. Par exemple, nous pouvons créer un tableau qui contient nos informations de test - une description de ce qu'est le test, à quelle heure il a commencé et à quelle heure il s'est terminé. Nous pouvons inclure les statistiques du fichier dans le même tableau. Si nous collectons d'autres mesures, nous pouvons les ajouter au tableau. Ou, il peut être plus facile de créer un tableau séparé pour chaque ensemble de données que nous capturons. Par exemple, si nous stockons les données de statistiques de fichiers dans une table différente, nous devons attribuer à chaque test un identifiant unique, afin que nous puissions faire correspondre notre test avec les bonnes données de statistiques de fichiers. Lors de la capture des statistiques de fichiers, nous devons capturer les valeurs de notre base de données avant de commencer, puis après, et calculer la différence. Nous pouvons ensuite stocker ces informations dans sa propre table, avec l'ID de test unique.
Un exemple d'exercice
Pour ce test, j'ai créé une copie vide de la table Sales.SalesOrderHeader nommée Sales.Big_SalesOrderHeader, et j'ai utilisé une variante d'un script que j'ai utilisé dans mon post de partitionnement pour charger des données dans la table par lots d'environ 25 000 lignes. Vous pouvez télécharger le script pour le chargement des données ici. Je l'ai exécuté quatre fois pour chaque variation et j'ai également fait varier le nombre total de lignes insérées. Pour la première série de tests, j'ai inséré 20 millions de lignes et pour la deuxième série, j'ai inséré 60 millions de lignes. Les données de durée ne sont pas surprenantes :
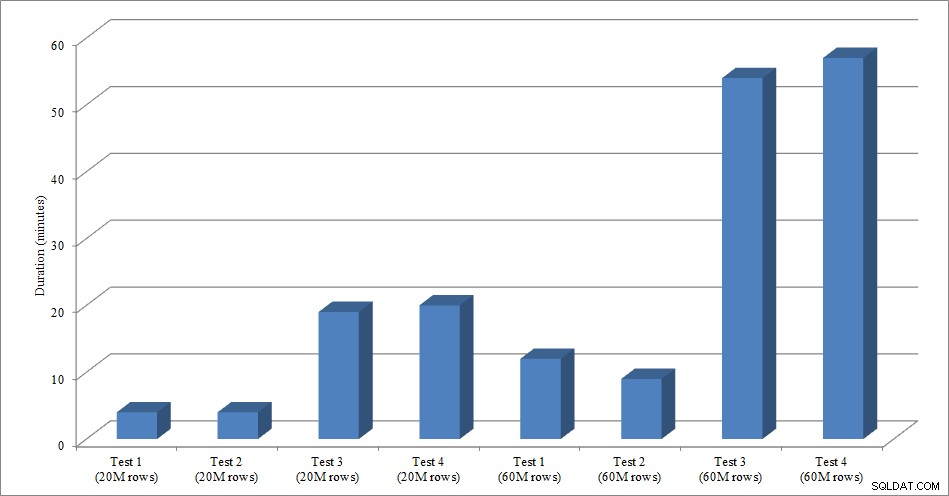
Durée de chargement des données
Le chargement des données, sans les index non clusterisés, est beaucoup plus rapide que le chargement avec les index non clusterisés déjà en place. Ce que j'ai trouvé intéressant, c'est que pour le chargement de 20 millions de lignes, la durée totale était à peu près la même entre le test 1 et le test 2, mais le test 2 était plus rapide lors du chargement de 60 millions de lignes. Dans notre test, notre clé de clustering était SalesOrderID, qui est une identité et donc une bonne clé de clustering pour notre charge puisqu'elle est ascendante. Si nous avions une clé de clustering qui était un GUID à la place, le temps de chargement pourrait être plus élevé en raison des insertions aléatoires et des fractionnements de page (une autre variante que nous pourrions tester).
Les données IO reproduisent-elles la tendance des données de durée ? Oui, avec les différences ayant les index déjà en place, ou pas, encore plus exagérées :
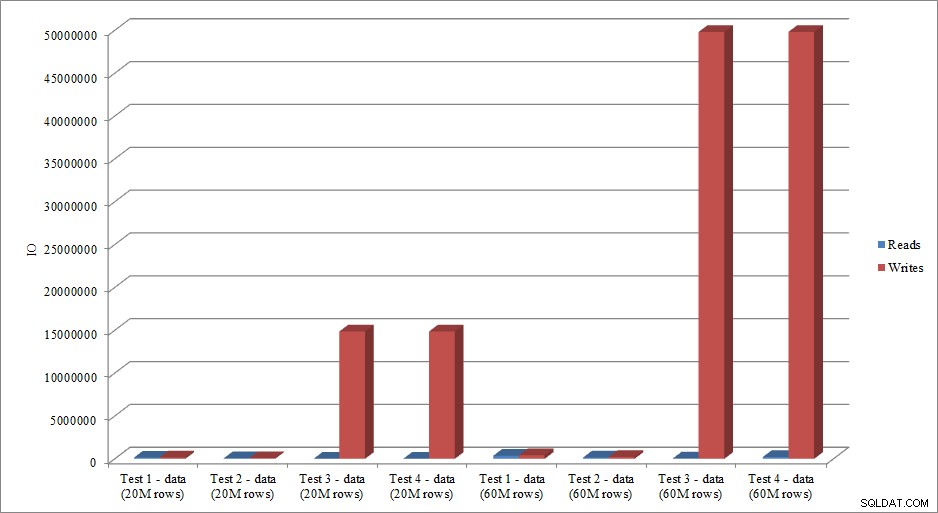
Lectures et écritures de chargement de données
La méthode que j'ai présentée ici pour tester les performances, ou mesurer les changements de performances en fonction des modifications apportées au code, à la conception, etc., n'est qu'une option pour capturer des informations de base. Dans certains scénarios, cela peut être exagéré. Si vous essayez de régler une requête, la configuration de ce processus pour capturer les données peut prendre plus de temps que pour apporter des modifications à la requête ! Si vous avez effectué des réglages de requêtes, vous avez probablement l'habitude de capturer les données STATISTICS IO et STATISTICS TIME, ainsi que le plan de requête, puis de comparer la sortie au fur et à mesure que vous apportez des modifications. Je fais cela depuis des années, mais j'ai récemment découvert une meilleure façon… SQL Sentry Plan Explorer PRO. En fait, après avoir terminé tous les tests de charge que j'ai décrits ci-dessus, j'ai parcouru et réexécuté mes tests via PE, et j'ai découvert que je pouvais capturer les informations que je voulais, sans avoir à configurer mes tables de collecte de données.
Dans Plan Explorer PRO, vous avez la possibilité d'obtenir le plan réel - PE exécutera la requête sur l'instance et la base de données sélectionnées, et renverra le plan. Et avec lui, vous obtenez toutes les autres données intéressantes fournies par PE (statistiques temporelles, lectures et écritures, E/S par table), ainsi que les statistiques d'attente, ce qui est un avantage appréciable. En utilisant notre exemple, j'ai commencé par le premier test - création du tas, chargement des données, puis ajout de l'index cluster et des index non cluster - puis j'ai exécuté l'option Get Actual Plan. Une fois terminé, j'ai modifié mon test de script 2, exécuté à nouveau l'option Get Actual Plan. J'ai répété cela pour les troisième et quatrième tests, et quand j'ai eu fini, j'ai eu ceci :
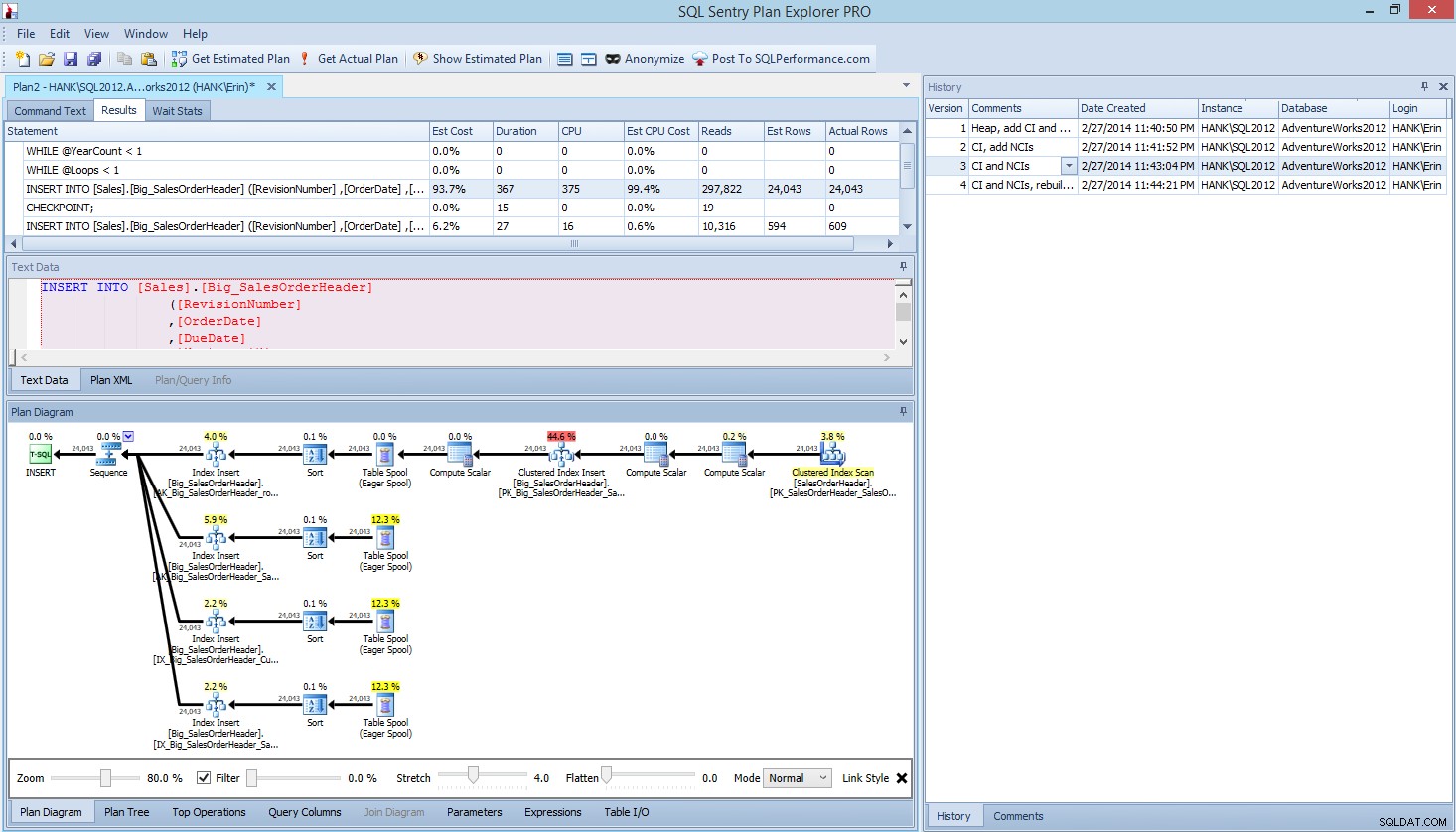
Vue Plan Explorer PRO après avoir exécuté 4 tests
Remarquez le volet d'historique sur le côté droit ? Chaque fois que je modifiais mon code et reprenais le plan réel, il enregistrait un nouvel ensemble d'informations. J'ai la possibilité d'enregistrer ces données sous forme de fichier .pesession à partager avec un autre membre de mon équipe, ou de revenir plus tard et de faire défiler les différents tests, et d'explorer différentes déclarations dans le lot si nécessaire, en examinant différentes mesures telles que comme durée, CPU et IO. Dans la capture d'écran ci-dessus, j'ai mis en surbrillance l'INSERT du test 3 et le plan de requête affiche les mises à jour des quatre index non clusterisés.
Résumé
Comme pour de nombreuses tâches dans SQL Server, il existe de nombreuses façons de capturer et d'examiner les données lorsque vous exécutez des tests de performances ou effectuez un réglage. Moins vous devez fournir d'efforts manuels, mieux c'est, car cela vous laisse plus de temps pour apporter des modifications, comprendre l'impact, puis passer à votre tâche suivante. Que vous personnalisiez un script pour capturer des données ou que vous laissiez un utilitaire tiers le faire pour vous, les étapes que j'ai décrites sont toujours valables :
- Définissez ce que vous voulez améliorer
- Étendue de vos tests
- Déterminer quelles données peuvent être utilisées pour mesurer l'amélioration
- Décidez comment capturer les données
- Configurez une méthode automatisée, dans la mesure du possible, pour les tests et la capture
- Tester, évaluer et répéter si nécessaire
Bon test !