Partout dans le monde, le portail de l'emploi est une caractéristique bien connue du paysage Internet. De grands acteurs comme Indeed et Monster ont transformé la recherche d'emploi et le recrutement en une véritable industrie en ligne. Plongeons-nous dans les fonctionnalités élémentaires exploitées par les portails d'emploi et créons un modèle de données qui peut les prendre en charge.
Les gens aiment gagner du temps en utilisant les innovations technologiques; le portail d'emploi en ligne est une autre version de travailler plus intelligemment, pas plus dur. Les demandeurs d'emploi et les entreprises se rendent compte de l'intérêt d'effectuer leur recherche en ligne :ils obtiennent une meilleure portée à des vitesses plus élevées et à moindre coût.
L'industrie des portails d'emploi est maintenant assez stabilisée, du moins en ce qui concerne les volumes de trafic. Les chercheurs d'emploi utilisent ces portails pour trouver des postes dans de nombreux secteurs, allant au-delà de l'informatique vers des secteurs tels que l'ingénierie, les ventes, la fabrication et les services financiers. Cependant, ils subissent une concurrence féroce de la part des médias sociaux et des sites de réseautage professionnels comme LinkedIn. Mais il reste encore des opportunités à explorer, telles que l'expansion de leur pénétration dans les zones rurales et les petites villes.
Donc, comme nous l'avons dit, nous allons explorer ce sujet du point de vue de la conception de la base de données. Commençons par énumérer les attentes fondamentales d'un portail d'emploi.
Qu'attendent les gens d'un portail d'emploi en ligne ?
Les employeurs et les demandeurs d'emploi attendent les fonctionnalités suivantes d'un site d'emploi en ligne :
- Les personnes peuvent s'inscrire en tant que demandeurs d'emploi, créer leur profil et rechercher des emplois correspondant à leurs compétences.
- Les utilisateurs peuvent télécharger leurs CV existants. S'ils n'en ont pas, ils devraient pouvoir remplir un formulaire et se faire rédiger un CV.
- Les personnes peuvent postuler directement aux offres d'emploi publiées.
- Les entreprises peuvent s'inscrire, publier des offres d'emploi et rechercher des profils de demandeurs d'emploi.
- Plusieurs représentants d'une entreprise doivent pouvoir s'inscrire et publier des offres d'emploi.
- Les représentants de l'entreprise peuvent consulter une liste de candidats et peuvent les contacter, organiser un entretien ou effectuer d'autres actions liées à leur poste.
- Les utilisateurs enregistrés doivent pouvoir rechercher des emplois et filtrer les résultats en fonction du lieu, des compétences requises, du salaire, du niveau d'expérience, etc.
Construire le modèle de données
Après avoir examiné les exigences ci-dessus, j'ai proposé trois grandes catégories fonctionnelles :
- Gestion des utilisateurs – Comment le portail gère les utilisateurs, c'est-à-dire les demandeurs d'emploi, le personnel RH et les recruteurs indépendants ou consultants. (Aux fins de ce modèle, les représentants RH individuels et les recruteurs indépendants ou consultants sont traités comme des entreprises, du moins en termes d'utilisation du portail.)
- Créer des profils – Comment le portail permet aux demandeurs d'emploi et aux organisations de créer des profils et des CV.
- Publication et recherche d'emplois – Comment le portail facilite le processus de publication, de recherche et de candidature à des emplois.
Examinons chacun de ces domaines séparément.
1. Gestion des utilisateurs
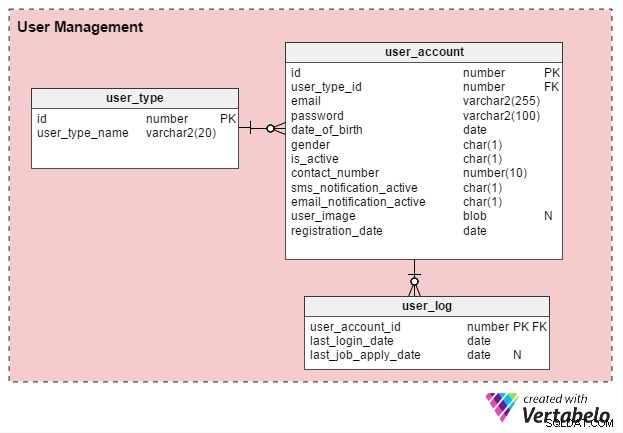
Il existe principalement deux types d'utilisateurs du portail emploi en ligne :les demandeurs d'emploi individuels et les recruteurs RH (ou consultants en recrutement indépendants). Créons une table nommée user_type pour stocker ces enregistrements. Pour commencer, il aura deux dossiers - un pour les demandeurs d'emploi et un autre pour les recruteurs. (Nous pouvons toujours créer des types d'enregistrement supplémentaires si nécessaire.)
Les utilisateurs doivent s'inscrire avant de pouvoir utiliser le portail. Le user_account table stocke les détails de base de leur compte. Auparavant, j'avais envisagé de nommer cette table "user", mais comme user est un mot-clé défini par le système dans presque toutes les bases de données, je préfère m'en tenir à "user_account".
Le user_account le tableau comporte les colonnes suivantes :
- identifiant – Il s'agit à la fois de la clé primaire de la table et d'un identifiant unique pour chaque utilisateur. Cet ID sera référencé par d'autres tables du modèle de données.
- identifiant_type_utilisateur – Cela signifie si l'utilisateur est un demandeur d'emploi ou un recruteur.
- courriel – Cette colonne contient l'adresse e-mail de l'utilisateur. Il agit comme un autre ID utilisateur pour le portail.
- mot de passe - Cela stocke un mot de passe de compte crypté (créé par les utilisateurs lors de l'inscription).
- date_of_birth et sexe – Comme leur nom l'indique, ces colonnes contiennent la date de naissance et le sexe des utilisateurs.
- is_active – Initialement, cette colonne serait "Y", mais les utilisateurs peuvent définir leur profil sur inactif, ou "N". Cette colonne stocke leur choix.
- contact_number – Il s'agit du numéro de téléphone (généralement mobile) fourni lors de l'inscription. Les utilisateurs peuvent recevoir des notifications par SMS (texte) sur ce numéro. Il peut s'agir du même numéro (ou non) que la liste des demandeurs d'emploi dans leur profil ou leur CV.
- sms_notification_active et email_notification_active – Ces colonnes stockent les préférences des utilisateurs concernant la réception de notifications par SMS et/ou e-mail.
- user_image – Il s'agit d'un attribut de type BLOB qui stocke l'image de profil de chaque utilisateur. Étant donné que ce portail n'autorise qu'une seule image de profil par utilisateur, il est logique de la stocker ici.
- date_inscription – Cette colonne conserve un enregistrement du moment où l'utilisateur s'est enregistré sur le portail.
Nous allons créer une autre table, user_log , qui stocke un enregistrement de la dernière date de connexion des utilisateurs et de leur dernière date de candidature. De nombreuses fonctionnalités peuvent être construites à partir de ces connaissances. Par exemple, nous pouvons utiliser ces informations pour répondre à la question L'utilisateur X recherche-t-il activement un emploi ? Si oui, on peut leur proposer un produit pour créer un CV efficace. Les utilisateurs qui ne recherchent pas activement un emploi ne recevront pas une telle offre.
2. Création de profils
Nous pouvons diviser cette section en deux zones :les profils d'entreprise ou d'organisation et les profils de demandeur d'emploi.
Profils d'entreprise
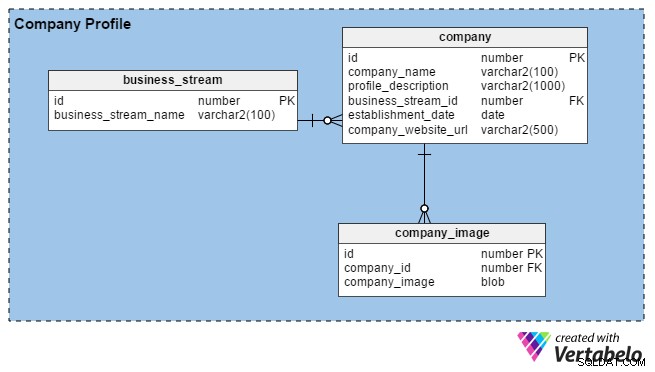
Habituellement, les équipes RH construisent des profils d'entreprise en entrant des détails sur leur organisation et des images de leurs bureaux, bâtiments, etc. Leur objectif principal est d'attirer les bons talents. Lorsque les recruteurs s'inscrivent sur le portail, ils peuvent eux aussi créer des profils de leur entreprise (ou de leur marque personnelle, s'ils sont indépendants) en fournissant quelques détails de base comme depuis combien de temps ils sont en affaires, leur emplacement et leur principal secteur d'activité ( par exemple fabrication, services informatiques, finances, etc.).
Le portail permet aux recruteurs RH et conseil de télécharger autant d'images qu'ils le souhaitent (contrairement aux demandeurs d'emploi qui ne peuvent en télécharger qu'une seule). Par conséquent, nous avons créé le company_image table pour stocker plusieurs images pour chaque compte recruteur. Le company_id colonne de ce tableau est une clé étrangère qui fait référence à l'identifiant unique utilisé dans le company tableau.
Dans l'company table, nous avons les colonnes suivantes :
- identifiant – La clé primaire de cette table est également utilisée pour identifier de manière unique les entreprises.
- nom_entreprise – Comme le nom de la colonne le suggère, cela contient le nom légal d'une entreprise.
- profil_description – Celui-ci contient une brève description de chaque entreprise.
- business_stream_id – Cette colonne indique à quel secteur d'activité appartient une entreprise. Par exemple, une société d'exploration pétrolière et gazière peut embaucher des ingénieurs en informatique , mais son principal secteur d'activité reste "Pétrole et gaz".
- date_établissement – Cette colonne vous indique l'âge d'une entreprise.
- URL_site_web_entreprise – Il s'agit d'une colonne obligatoire (non nulle). Il contient un pointeur vers le site Web officiel de l'entreprise afin que les demandeurs d'emploi puissent trouver plus d'informations.
Enfin, le business_stream table n'a que deux attributs, un identifiant qui est la clé primaire de cette table et une description du flux d'activité principal de l'entreprise (business_stream_name ).
Profils de demandeur d'emploi
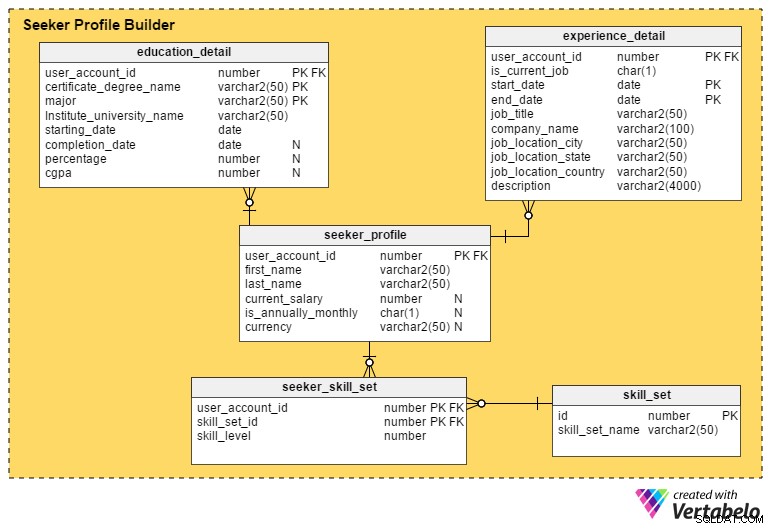
Il s'agit de la section la plus critique d'un portail d'emploi. À moins qu'un portail ne capture autant de détails que possible sur les demandeurs d'emploi, il est difficile pour les recruteurs de présélectionner les profils ou les candidats.
Le seeker_profile table contient des détails supplémentaires qui n'ont pas été saisis lors du processus d'inscription. Il contient ces champs :
- user_account_id – Cette colonne est référencée depuis le
user_accounttable, et il agit comme clé primaire pour cette table. Il garantit qu'il y aura au maximum un profil par demandeur d'emploi. - prénom et nom_de_famille – Comme les noms le suggèrent, ces colonnes contiennent le prénom et le nom du demandeur d'emploi.
- salaire_actuel – Cet attribut contient le salaire actuel du demandeur d'emploi. Il est nullable car les gens peuvent ne pas vouloir le divulguer.
- est_annuellement_mensuel – Cela définit si leur montant de salaire est annuel ou mensuel.
- devise – Cela stocke la devise du salaire.
Le education_detail table stocke les antécédents scolaires de chaque demandeur d'emploi, tels qu'ils sont fournis par eux. Il a une clé primaire composite composée de user_account_id , certificate_degree_name et majeure Colonnes. Cela garantit que les utilisateurs n'entrent qu'un un dossier pour chaque diplôme ou certificat. Le tableau contient ces attributs :
- user_account_id – Cette colonne est référencée depuis le
user_accounttable et sert de clé primaire pour cette table. - certificate_degree_name – Il s'agit du type de certificat ou de diplôme; par exemple. diplôme d'études secondaires, d'études secondaires supérieures, d'études supérieures, d'études supérieures ou professionnelles.
- majeure – Cette colonne contient le programme d'études principal pour le certificat ou le diplôme – par ex. un baccalauréat avec une majeure en informatique.
- institut_university_name – Il s'agit de l'institut, de l'école ou de l'université qui a délivré le diplôme ou le certificat.
- start_date – Cet attribut stocke la date à laquelle l'utilisateur a été accepté dans un programme éducatif.
- date_achèvement – Il s'agit de la date à laquelle le diplôme ou le certificat a été décerné. Cependant, cet attribut est nullable; les personnes peuvent encore terminer leur programme alors qu'elles sont à la recherche d'un emploi, ou elles peuvent avoir complètement abandonné le programme.
- pourcentage et cgpa – Ces colonnes stockent le pourcentage de notes ou la MPC (moyenne pondérée cumulative) obtenue par les utilisateurs dans leur cursus menant à un diplôme ou à un certificat.
Le experience_detail table enregistre l'expérience professionnelle passée et actuelle des utilisateurs. Il contient les colonnes importantes suivantes :
- user_account_id – Cette colonne est référencée depuis le
user_accounttable et est la clé primaire de cette table. - is_current_job - Il s'agit d'une colonne d'indicateur qui indique le travail actuel de l'utilisateur. Cette colonne joue également un rôle majeur dans la détermination des emplacements actuels des utilisateurs et de la durée pendant laquelle ils occupent leur poste actuel.
- start_date – Cela stocke quand un utilisateur démarre une tâche.
- end_date – Cela stocke quand un utilisateur termine un travail.
- job_title :contient des informations sur le rôle de l'utilisateur.
- nom_entreprise – Cet attribut contient le nom de l'entreprise pertinent associé à un travail.
- job_location_city – Cela signifie la ville où se trouvait le travail.
- job_location_state - Cela signifie l'état où se trouvait le travail.
- job_location_country – Cela signifie le pays où le travail était situé.
- description – Cette colonne stocke des détails sur les rôles et les responsabilités, les défis et les réalisations.
Les demandeurs d'emploi peuvent posséder plusieurs compétences. Pour conserver des enregistrements de tous ces ensembles de compétences, nous allons créer la table seeker_skill_set . Les colonnes sont :
- user_account_id – Cette colonne est référencée depuis le
user_accounttable et est la clé primaire de cette table. - skill_set_id – Cet ID signifie quel ensemble de compétences l'utilisateur possède.
- niveau_compétence – Cet attribut numérique quantifie l'expertise des demandeurs d'emploi dans une compétence particulière. Un nombre de 1 (débutant) à 10 (expert) indique leur niveau d'expérience.
Enfin, le skill_set le tableau contient les descriptions de toutes les compétences auxquelles il est fait référence dans le skill_set_id du tableau ci-dessus attribut. Il ne contient que deux colonnes, un skill_set_name et son id associé .
3. Publication et recherche d'emplois
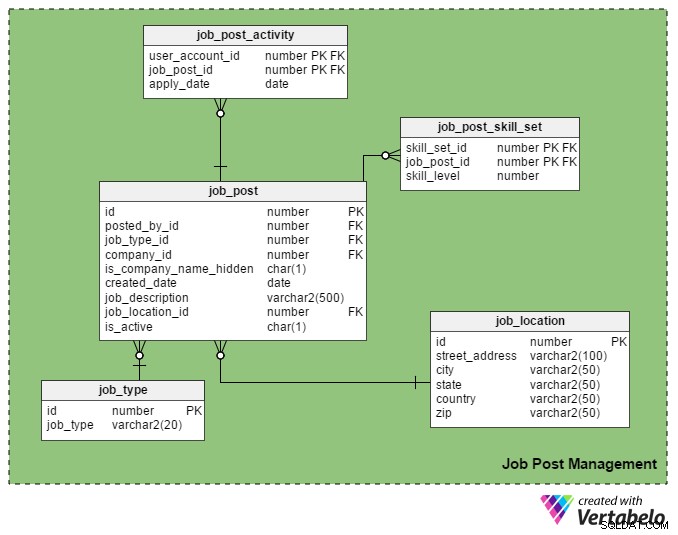
C'est le principal USP (Unique Selling Point) d'un portail d'emploi. Seuls les recruteurs inscrits sont autorisés à publier une offre d'emploi sur le portail et seuls les demandeurs d'emploi inscrits sont autorisés à y postuler.
Le job_post table est la table principale de ce domaine. Comme vous pouvez le deviner, il contient des détails sur les offres d'emploi. Tous les autres tableaux de cette section sont créés autour de lui et liés à lui.
- identifiant – Il s'agit de la clé primaire de cette table. Chaque offre d'emploi se voit attribuer un numéro unique, et ce numéro est mentionné dans d'autres tableaux.
- publié_par_id – Cette colonne contient le register_user_id du recruteur qui a publié l'offre d'emploi.
- job_type_id – Cette colonne indique si la durée de l'emploi est permanente ou temporaire (contrat).
- identifiant_entreprise – Cette colonne stocke l'ID de l'entreprise liée à l'offre d'emploi. C'est une référence à la
companytableau. - is_company_name_hidden – Il s'agit d'une colonne de drapeau qui indique si le nom de l'entreprise doit être montré aux demandeurs d'emploi. Les recruteurs peuvent préférer ne pas afficher le nom de l'entreprise sur leur publication. Au lieu de cela, ils utilisent des termes tels que "Global Automobile Company", "California-Based IT Company", etc.
- created_date - Cela stocke la date à laquelle le travail est publié.
- job_description – Cela contient une brève description du travail.
- job_location_id – Cela fait référence à un attribut dans le
job_locationtable qui stocke l'emplacement réel du travail :adresse postale, ville, état, pays et code postal. - is_active – Cela signifie si un travail est encore ouvert. Les recruteurs peuvent marquer leurs postes comme inactifs dès que les postes sont pourvus.
Le job_post_skill_set La table stocke des détails sur les ensembles de compétences requis pour un emploi. La structure du tableau est identique au seeker_skill_set table.
Et le dernier tableau de cette section, le job_post_activity tableau, contient des détails sur les demandeurs d'emploi qui postulent pour un emploi et quand.
Qu'ajouteriez-vous à ce modèle de données de portail d'emploi en ligne ?
Les portails d'emploi en ligne d'aujourd'hui font plus que fournir une plate-forme pour publier et postuler à des emplois. Ils incluent souvent d'autres services professionnels tels que :
- Un tableau de bord personnel pour suivre les candidatures
- Mises à jour en temps réel sur les applications
- Créateurs de CV vidéo
- Services d'experts en rédaction de CV
- LinkedIn ou d'autres créateurs de profils de réseaux sociaux
- Rapports sur les salaires selon les fonctions, les entreprises, les secteurs ou les zones géographiques
Si nous voulions intégrer ces fonctionnalités dans notre système, quelles modifications supplémentaires devrions-nous apporter ? Pouvez-vous penser à d'autres incontournables dans un portail d'emploi ?
Veuillez nous faire part de votre point de vue dans la section des commentaires.