Certaines discussions intéressantes évoluent toujours autour du sujet de la séparation des chaînes. Dans deux articles de blog précédents, "Split strings the right way - or the next best way" et "Splitting Strings :A Follow-Up", j'espère avoir démontré que la poursuite de la fonction de division T-SQL "la plus performante" est infructueuse . Lorsque le fractionnement est réellement nécessaire, le CLR l'emporte toujours et la meilleure option suivante peut varier en fonction de la tâche à accomplir. Mais dans ces messages, j'ai laissé entendre que le fractionnement du côté de la base de données n'était peut-être pas nécessaire en premier lieu.
SQL Server 2008 a introduit des paramètres table, un moyen de transmettre une "table" d'une application à une procédure stockée sans avoir à créer et à analyser une chaîne, à sérialiser en XML ou à gérer l'une de ces méthodologies de fractionnement. J'ai donc pensé vérifier comment cette méthode se compare au gagnant de nos tests précédents - car cela peut être une option viable, que vous puissiez utiliser CLR ou non. (Pour la bible ultime sur les TVP, veuillez consulter l'article complet d'Erland Sommarskog, MVP de SQL Server.)
Les épreuves
Pour ce test, je vais prétendre que nous avons affaire à un ensemble de chaînes de version. Imaginez une application C # qui transmet un ensemble de ces chaînes (par exemple, qui ont été collectées auprès d'un ensemble d'utilisateurs) et nous devons faire correspondre les versions à une table (par exemple, qui indique les versions de service applicables à un ensemble spécifique de versions). De toute évidence, une application réelle aurait plus de colonnes que cela, mais juste pour créer du volume tout en gardant la table maigre (j'utilise également NVARCHAR car c'est ce que prend la fonction de fractionnement CLR et je veux éliminer toute ambiguïté due à la conversion implicite) :
CREATE TABLE dbo.VersionStrings(left_post NVARCHAR(5), right_post NVARCHAR(5)); CREATE CLUSTERED INDEX x ON dbo.VersionStrings(left_post, right_post); ;WITH x AS ( SELECT lp = CONVERT(DECIMAL(4,3), RIGHT(RTRIM(s1.[object_id]), 3)/1000.0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) INSERT dbo.VersionStrings ( left_post, right_post ) SELECT lp - CASE WHEN lp >= 0.9 THEN 0.1 ELSE 0 END, lp + (0.1 * CASE WHEN lp >= 0.9 THEN -1 ELSE 1 END) FROM x;
Maintenant que les données sont en place, la prochaine chose que nous devons faire est de créer un type de table défini par l'utilisateur qui peut contenir un ensemble de chaînes. Le type de table initial pour contenir cette chaîne est assez simple :
CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(5));
Ensuite, nous avons besoin de quelques procédures stockées pour accepter les listes de C#. Pour simplifier, encore une fois, nous allons juste faire un décompte pour être sûr d'effectuer une analyse complète, et nous ignorerons le décompte dans l'application :
CREATE PROCEDURE dbo.SplitTest_UsingCLR
@list NVARCHAR(MAX)
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN dbo.SplitStrings_CLR(@list, N',') AS s
ON s.Item BETWEEN v.left_post AND v.right_post;
END
GO
CREATE PROCEDURE dbo.SplitTest_UsingTVP
@list dbo.VersionStringsTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN @list AS l
ON l.VersionString BETWEEN v.left_post AND v.right_post;
END
GO Notez qu'un TVP passé dans une procédure stockée doit être marqué comme READONLY - il n'y a actuellement aucun moyen d'effectuer DML sur les données comme vous le feriez pour une variable de table ou une table temporaire. Cependant, Erland a soumis une demande très populaire pour que Microsoft rende ces paramètres plus flexibles (et beaucoup d'informations plus approfondies derrière son argument ici).
La beauté ici est que SQL Server n'a plus du tout à gérer le fractionnement d'une chaîne - ni dans T-SQL ni en la transmettant à CLR - car il est déjà dans une structure d'ensemble où il excelle.
Ensuite, une application console C# qui effectue les opérations suivantes :
- Accepte un nombre comme argument pour indiquer combien d'éléments de chaîne doivent être définis
- Construit une chaîne CSV de ces éléments, à l'aide de StringBuilder, à transmettre à la procédure stockée CLR
- Construit un DataTable avec les mêmes éléments à transmettre à la procédure stockée TVP
- Teste également la surcharge de conversion d'une chaîne CSV en DataTable et vice-versa avant d'appeler les procédures stockées appropriées
Le code de l'application C# se trouve à la fin de l'article. Je sais épeler C#, mais je ne suis en aucun cas un gourou; Je suis sûr qu'il y a des inefficacités que vous pouvez y repérer et qui peuvent améliorer un peu les performances du code. Mais tout changement de ce type devrait affecter l'ensemble des tests de la même manière.
J'ai exécuté l'application 10 fois en utilisant 100, 1 000, 2 500 et 5 000 éléments. Les résultats étaient les suivants (cela montre la durée moyenne, en secondes, sur les 10 tests) :
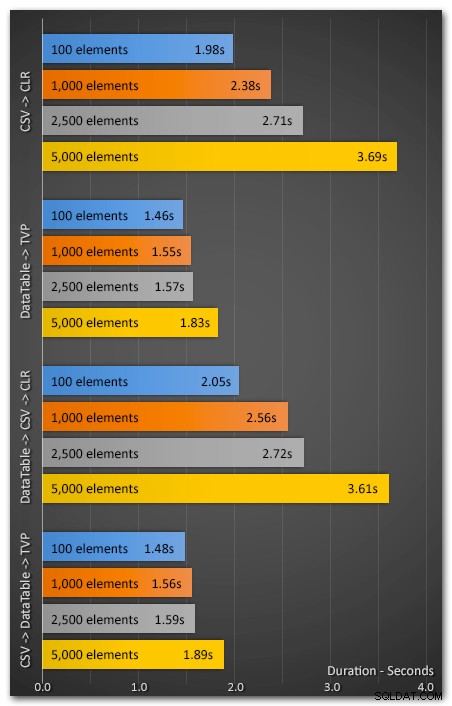
Les performances mises à part…
Outre la nette différence de performances, les TVP présentent un autre avantage :les types de table sont beaucoup plus simples à déployer que les assemblages CLR, en particulier dans les environnements où le CLR a été interdit pour d'autres raisons. J'espère que les obstacles au CLR disparaissent progressivement et que de nouveaux outils rendent le déploiement et la maintenance moins pénibles, mais je doute que la facilité de déploiement initial du CLR soit un jour plus facile que les approches natives.
D'autre part, en plus de la limitation en lecture seule, les types de table sont comme les types d'alias en ce sens qu'ils sont difficiles à modifier après coup. Si vous souhaitez modifier la taille d'une colonne ou ajouter une colonne, il n'y a pas de commande ALTER TYPE, et pour supprimer le type et le recréer, vous devez d'abord supprimer les références au type de toutes les procédures qui l'utilisent. . Ainsi, par exemple, dans le cas ci-dessus, si nous devions augmenter la colonne VersionString à NVARCHAR (32), nous devions créer un type factice et modifier la procédure stockée (et toute autre procédure qui l'utilise) :
CREATE TYPE dbo.VersionStringsTVPCopy AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVPCopy READONLY AS ... GO DROP TYPE dbo.VersionStringsTVP; GO CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVP READONLY AS ... GO DROP TYPE dbo.VersionStringsTVPCopy; GO
(Ou bien, supprimez la procédure, supprimez le type, recréez le type et recréez la procédure.)
Conclusion
La méthode TVP a constamment surpassé la méthode de fractionnement CLR, et d'un pourcentage plus élevé à mesure que le nombre d'éléments augmentait. Même l'ajout de la surcharge de conversion d'une chaîne CSV existante en DataTable a produit de bien meilleures performances de bout en bout. J'espère donc que, si je ne vous avais pas déjà convaincu d'abandonner vos techniques de fractionnement de chaînes T-SQL en faveur de CLR, je vous ai exhorté à essayer les paramètres de table. Il devrait être facile à tester même si vous n'utilisez pas actuellement un DataTable (ou un équivalent).
Le code C# utilisé pour ces tests
Comme je l'ai dit, je ne suis pas un gourou de C #, donc il y a probablement beaucoup de choses naïves que je fais ici, mais la méthodologie devrait être assez claire.
using System;
using System.IO;
using System.Data;
using System.Data.SqlClient;
using System.Text;
using System.Collections;
namespace SplitTester
{
class SplitTester
{
static void Main(string[] args)
{
DataTable dt_pure = new DataTable();
dt_pure.Columns.Add("Item", typeof(string));
StringBuilder sb_pure = new StringBuilder();
Random r = new Random();
for (int i = 1; i <= Int32.Parse(args[0]); i++)
{
String x = r.NextDouble().ToString().Substring(0,5);
sb_pure.Append(x).Append(",");
dt_pure.Rows.Add(x);
}
using
(
SqlConnection conn = new SqlConnection(@"Data Source=.;
Trusted_Connection=yes;Initial Catalog=Splitter")
)
{
conn.Open();
// four cases:
// (1) pass CSV string directly to CLR split procedure
// (2) pass DataTable directly to TVP procedure
// (3) serialize CSV string from DataTable and pass CSV to CLR procedure
// (4) populate DataTable from CSV string and pass DataTable to TCP procedure
// ********** (1) ********** //
write(Environment.NewLine + "Starting (1)");
SqlCommand c1 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c1.CommandType = CommandType.StoredProcedure;
c1.Parameters.AddWithValue("@list", sb_pure.ToString());
c1.ExecuteNonQuery();
c1.Dispose();
write("Finished (1)");
// ********** (2) ********** //
write(Environment.NewLine + "Starting (2)");
SqlCommand c2 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c2.CommandType = CommandType.StoredProcedure;
SqlParameter tvp1 = c2.Parameters.AddWithValue("@list", dt_pure);
tvp1.SqlDbType = SqlDbType.Structured;
c2.ExecuteNonQuery();
c2.Dispose();
write("Finished (2)");
// ********** (3) ********** //
write(Environment.NewLine + "Starting (3)");
StringBuilder sb_fake = new StringBuilder();
foreach (DataRow dr in dt_pure.Rows)
{
sb_fake.Append(dr.ItemArray[0].ToString()).Append(",");
}
SqlCommand c3 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c3.CommandType = CommandType.StoredProcedure;
c3.Parameters.AddWithValue("@list", sb_fake.ToString());
c3.ExecuteNonQuery();
c3.Dispose();
write("Finished (3)");
// ********** (4) ********** //
write(Environment.NewLine + "Starting (4)");
DataTable dt_fake = new DataTable();
dt_fake.Columns.Add("Item", typeof(string));
string[] list = sb_pure.ToString().Split(',');
for (int i = 0; i < list.Length; i++)
{
if (list[i].Length > 0)
{
dt_fake.Rows.Add(list[i]);
}
}
SqlCommand c4 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c4.CommandType = CommandType.StoredProcedure;
SqlParameter tvp2 = c4.Parameters.AddWithValue("@list", dt_fake);
tvp2.SqlDbType = SqlDbType.Structured;
c4.ExecuteNonQuery();
c4.Dispose();
write("Finished (4)");
}
}
static void write(string msg)
{
Console.WriteLine(msg + ": "
+ DateTime.UtcNow.ToString("HH:mm:ss.fffff"));
}
}
}