La semaine dernière, j'ai présenté ma session T-SQL :Bad Habits and Best Practices lors de la conférence GroupBy. Une rediffusion vidéo et d'autres documents sont disponibles ici :
- T-SQL :mauvaises habitudes et bonnes pratiques
L'un des éléments que je mentionne toujours dans cette session est que je préfère généralement GROUP BY à DISTINCT lors de l'élimination des doublons. Bien que DISTINCT explique mieux l'intention et que GROUP BY ne soit requis que lorsque des agrégations sont présentes, elles sont interchangeables dans de nombreux cas.
Commençons par quelque chose de simple en utilisant Wide World Importers. Ces deux requêtes produisent le même résultat :
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Et en fait dérivent leurs résultats en utilisant exactement le même plan d'exécution :

Mêmes opérateurs, même nombre de lectures, différences négligeables de CPU et de durée totale (ils "gagnent" à tour de rôle).
Alors pourquoi recommanderais-je d'utiliser la syntaxe GROUP BY plus verbeuse et moins intuitive plutôt que DISTINCT ? Eh bien, dans ce cas simple, c'est un pile ou face. Cependant, dans des cas plus complexes, DISTINCT peut finir par faire plus de travail. Essentiellement, DISTINCT collecte toutes les lignes, y compris toutes les expressions qui doivent être évaluées, puis élimine les doublons. GROUP BY peut (encore une fois, dans certains cas) filtrer les lignes en double avant effectuer l'un de ces travaux.
Parlons de l'agrégation de chaînes, par exemple. Alors que dans SQL Server v.Next, vous pourrez utiliser STRING_AGG (voir les messages ici et ici), le reste d'entre nous doit continuer avec FOR XML PATH (et avant de me dire à quel point les CTE récursifs sont incroyables pour cela, s'il vous plaît lire aussi ce post). Nous pourrions avoir une requête comme celle-ci, qui tente de renvoyer toutes les commandes de la table Sales.OrderLines, ainsi que les descriptions d'articles sous forme de liste délimitée par des barres :
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Il s'agit d'une requête typique pour résoudre ce type de problème, avec le plan d'exécution suivant (l'avertissement dans tous les plans concerne uniquement la conversion implicite sortant du filtre XPath) :
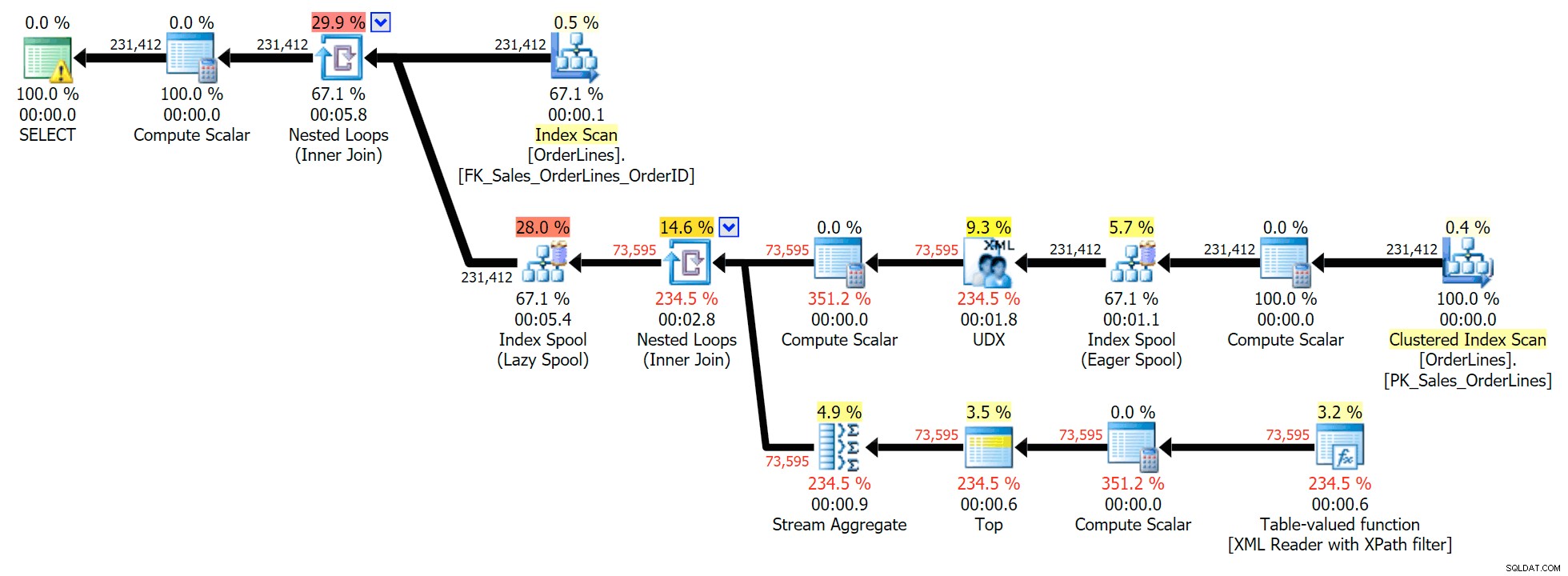
Cependant, il y a un problème que vous pourriez remarquer dans le nombre de lignes de sortie. Vous pouvez certainement le repérer en scannant la sortie avec désinvolture :

Pour chaque commande, nous voyons la liste délimitée par des tubes, mais nous voyons une ligne pour chaque article dans chaque commande. La réaction instinctive est de jeter un DISTINCT sur la liste des colonnes :
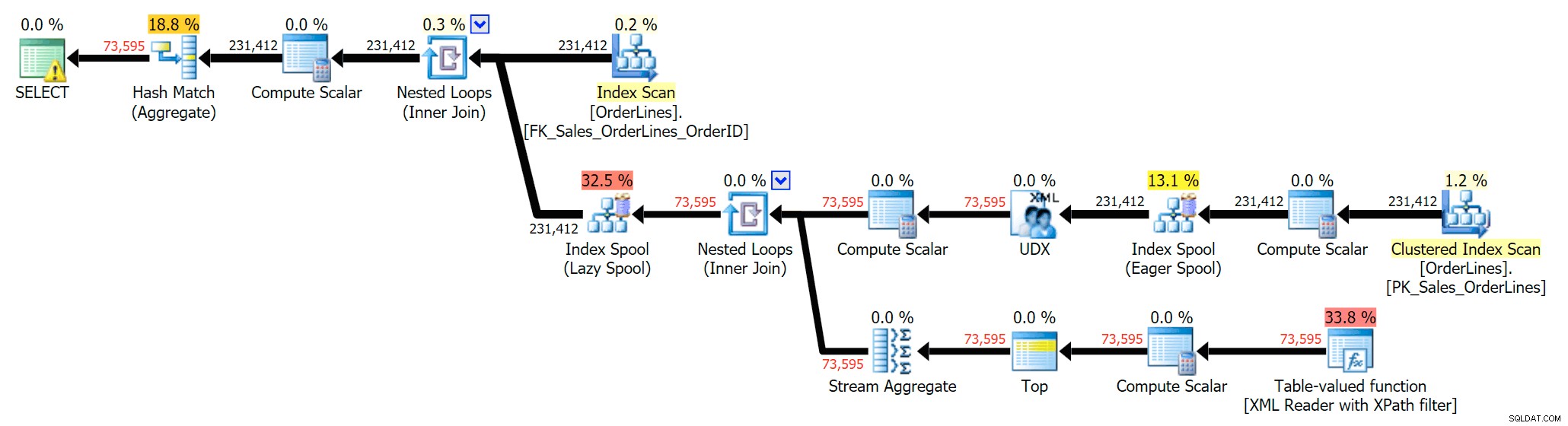
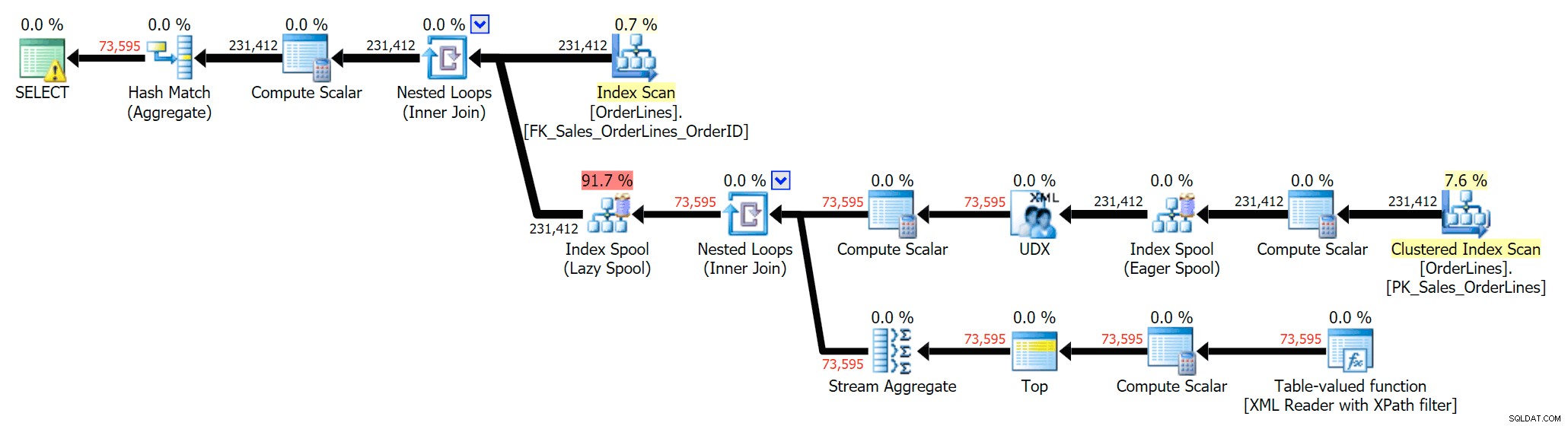
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Cela élimine les doublons (et modifie les propriétés de classement des analyses, de sorte que les résultats n'apparaissent pas nécessairement dans un ordre prévisible) et produit le plan d'exécution suivant :
Une autre façon de procéder consiste à ajouter un GROUP BY pour OrderID (puisque la sous-requête n'a pas explicitement besoin pour être à nouveau référencé dans le GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Cela produit les mêmes résultats (bien que la commande soit revenue), et un plan légèrement différent :
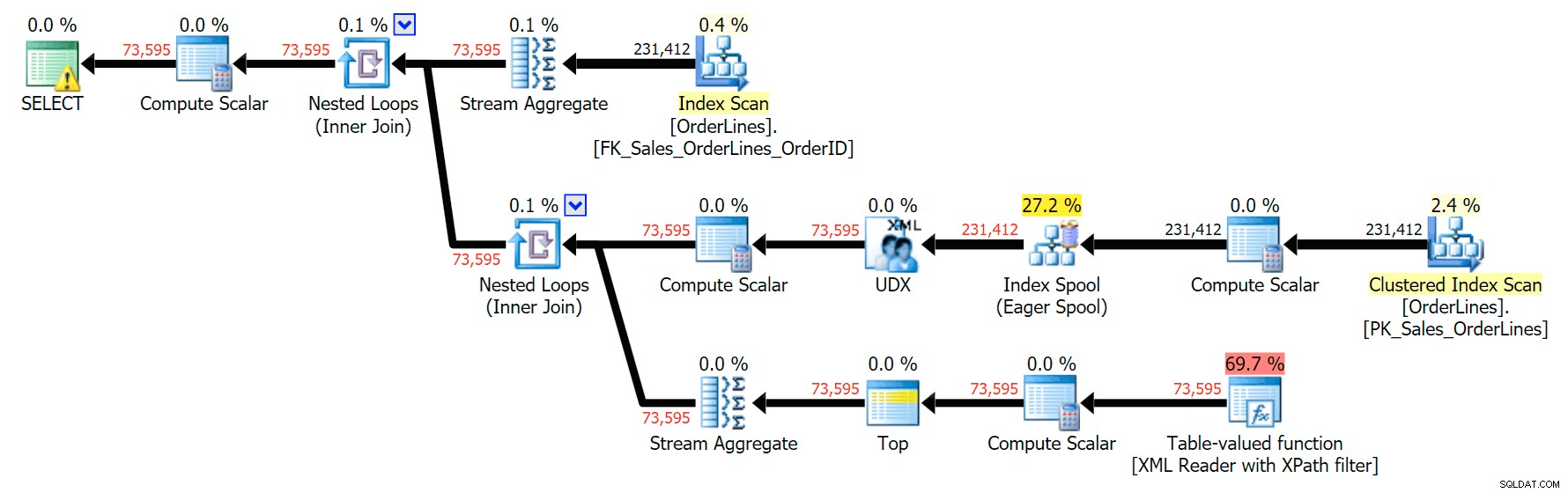
Les mesures de performance, cependant, sont intéressantes à comparer.

La variante DISTINCT a pris 4 fois plus de temps, utilisé 4 fois le processeur et presque 6 fois les lectures par rapport à la variante GROUP BY. (N'oubliez pas que ces requêtes renvoient exactement les mêmes résultats.)
Nous pouvons également comparer les plans d'exécution lorsque nous modifions les coûts de CPU + E/S combinés à E/S uniquement, une fonctionnalité exclusive à Plan Explorer. Nous affichons également les valeurs actualisées (qui sont basées sur le réel coûts observés lors de l'exécution de la requête, une fonctionnalité également disponible uniquement dans Plan Explorer). Voici le forfait DISTINCT :
Et voici le plan GROUP BY :
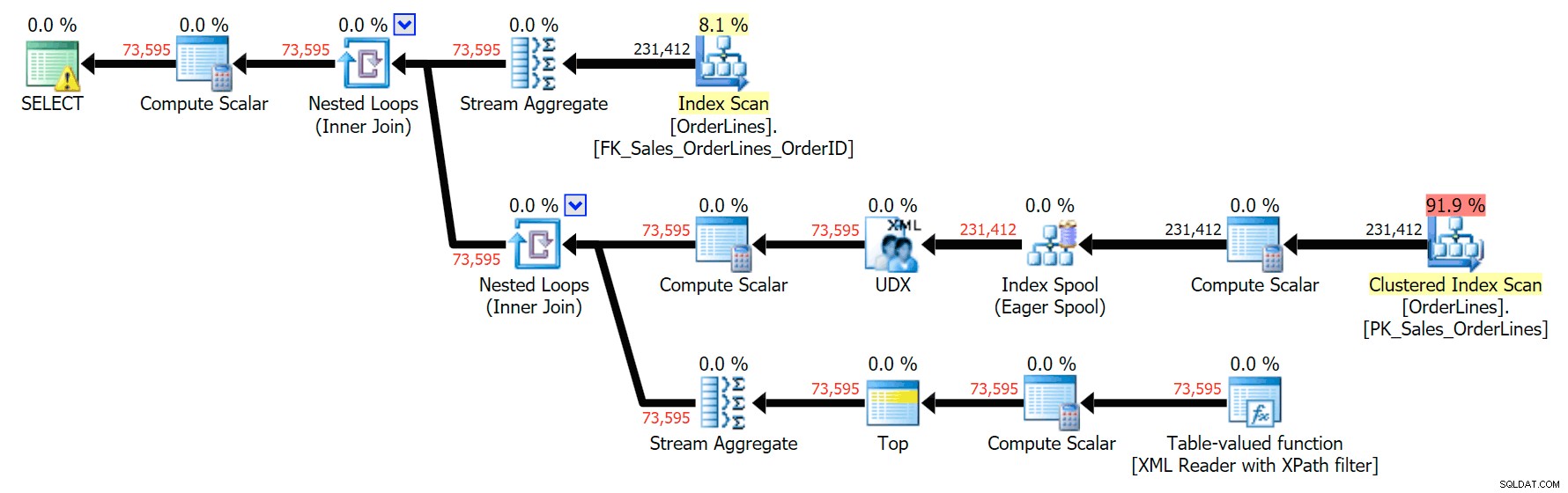
Vous pouvez voir que, dans le plan GROUP BY, presque tout le coût d'E/S est dans les analyses (voici l'info-bulle pour l'analyse CI, montrant un coût d'E/S d'environ 3,4 "bucks de requête"). Pourtant, dans le plan DISTINCT, la majeure partie du coût des E/S se trouve dans le spool d'index (et voici cette info-bulle ; le coût des E/S ici est d'environ 41,4 "dollars de requête"). Notez que le processeur est également beaucoup plus élevé avec la bobine d'index. Nous parlerons de "requête d'argent" une autre fois, mais le fait est que la bobine d'index est plus de 10 fois plus chère que l'analyse - pourtant l'analyse est toujours la même 3,4 dans les deux plans. C'est l'une des raisons pour lesquelles cela me dérange toujours lorsque les gens disent qu'ils doivent "réparer" l'opérateur dans le plan avec le coût le plus élevé. Certains opérateurs du plan seront toujours être le plus cher ; cela ne signifie pas qu'il doit être réparé.
@AaronBertrand ces requêtes ne sont pas vraiment logiquement équivalentes - DISTINCT est sur les deux colonnes, alors que votre GROUP BY n'est que sur une
— Adam Machanic (@AdamMachanic) 20 janvier 2017
Bien qu'Adam Machanic ait raison lorsqu'il dit que ces requêtes sont sémantiquement différentes, le résultat est le même :nous obtenons le même nombre de lignes, contenant exactement les mêmes résultats, et nous l'avons fait avec beaucoup moins de lectures et de CPU.
Ainsi, alors que DISTINCT et GROUP BY sont identiques dans de nombreux scénarios, voici un cas où l'approche GROUP BY conduit définitivement à de meilleures performances (au prix d'une intention déclarative moins claire dans la requête elle-même). Je serais intéressé de savoir si vous pensez qu'il existe des scénarios où DISTINCT est meilleur que GROUP BY, au moins en termes de performances, ce qui est beaucoup moins subjectif que le style ou si une déclaration doit être auto-documentée.
Cet article s'inscrit dans ma série "surprises et hypothèses", car de nombreuses choses que nous considérons comme des vérités basées sur des observations limitées ou des cas d'utilisation particuliers peuvent être testées lorsqu'elles sont utilisées dans d'autres scénarios. Il faut juste penser à prendre le temps de le faire dans le cadre de l'optimisation des requêtes SQL…
Références
- Concaténation groupée dans SQL Server
- Concaténation groupée :trier et supprimer les doublons
- Quatre cas d'utilisation pratiques pour la concaténation groupée
- SQL Server v.Next :performances de STRING_AGG()
- SQL Server v.Next :performances de STRING_AGG, partie 2