Un problème de performances que je rencontre souvent est lorsque les utilisateurs doivent faire correspondre une partie d'une chaîne avec une requête comme celle-ci :
... WHERE SomeColumn LIKE N'%SomePortion%';
Avec un caractère générique en tête, ce prédicat est "non-SARGable" - juste une façon élégante de dire que nous ne pouvons pas trouver les lignes pertinentes en utilisant une recherche sur un index sur SomeColumn .
Une solution qui nous fait un peu peur est la recherche en texte intégral; cependant, il s'agit d'une solution complexe qui nécessite que le modèle de recherche se compose de mots complets, n'utilise pas de mots vides, etc. Cela peut aider si nous recherchons des lignes où une description contient le mot "soft" (ou d'autres dérivés comme "softer" ou "softly"), mais cela n'aide pas lorsque nous recherchons des chaînes qui pourraient être contenues dans des mots (ou qui ne sont pas des mots du tout, comme tous les SKU de produits qui contiennent "X45-B" ou toutes les plaques d'immatriculation qui contiennent la séquence "7RA").
Et si SQL Server connaissait d'une manière ou d'une autre toutes les parties possibles d'une chaîne ? Mon processus de pensée va dans le sens du trigram / trigraph dans PostgreSQL. Le concept de base est que le moteur a la capacité d'effectuer des recherches de style point sur des sous-chaînes, ce qui signifie que vous n'avez pas à parcourir toute la table et à analyser chaque valeur complète.
L'exemple spécifique qu'ils utilisent ici est le mot cat . En plus du mot complet, il peut être décomposé en portions :c , ca , et at (ils omettent a et t par définition - aucune sous-chaîne de fin ne peut être inférieure à deux caractères). Dans SQL Server, nous n'avons pas besoin que ce soit si complexe; nous n'avons vraiment besoin que de la moitié du trigramme - si nous pensons à construire une structure de données contenant toutes les sous-chaînes de cat , nous n'avons besoin que de ces valeurs :
- chat
- à
- t
Nous n'avons pas besoin de c ou ca , car toute personne recherchant LIKE '%ca%' pourrait facilement trouver la valeur 1 en utilisant LIKE 'ca%' Au lieu. De même, toute personne recherchant LIKE '%at%' ou LIKE '%a%' pourrait utiliser un caractère générique de fin uniquement contre ces trois valeurs et trouver celle qui correspond (par exemple, LIKE 'at%' trouvera la valeur 2, et LIKE 'a%' trouvera également la valeur 2, sans avoir à trouver ces sous-chaînes à l'intérieur de la valeur 1, d'où viendrait la vraie douleur).
Donc, étant donné que SQL Server n'a rien de tel intégré, comment pouvons-nous générer un tel trigramme ?
Un tableau de fragments distinct
Je vais arrêter de faire référence à "trigramme" ici car ce n'est pas vraiment analogue à cette fonctionnalité dans PostgreSQL. Essentiellement, ce que nous allons faire est de construire une table séparée avec tous les "fragments" de la chaîne d'origine. (Donc dans le cat exemple, il y aurait une nouvelle table avec ces trois lignes, et LIKE '%pattern%' les recherches seraient dirigées vers cette nouvelle table en tant que LIKE 'pattern%' prédicats.)
Avant de commencer à montrer comment ma solution proposée fonctionnerait, permettez-moi d'être absolument clair sur le fait que cette solution ne doit pas être utilisée dans tous les cas où LIKE '%wildcard%' les recherches sont lentes. En raison de la façon dont nous allons « exploser » les données source en fragments, elles sont probablement limitées en termes pratiques à des chaînes plus petites, telles que des adresses ou des noms, par opposition à des chaînes plus longues, telles que des descriptions de produits ou des résumés de session.
Un exemple plus pratique que cat est de regarder le Sales.Customer table dans l'exemple de base de données WideWorldImporters. Il a des lignes d'adresse (à la fois nvarchar(60) ), avec les précieuses informations d'adresse dans la colonne DeliveryAddressLine2 (pour des raisons inconnues). Quelqu'un pourrait être à la recherche de quelqu'un qui habite dans une rue nommée Hudecova , ils lanceront donc une recherche comme celle-ci :
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Comme vous vous en doutez, SQL Server doit effectuer une analyse pour localiser ces deux lignes. Ce qui devrait être simple ; cependant, en raison de la complexité de la table, cette requête triviale donne un plan d'exécution très désordonné (l'analyse est mise en surbrillance et comporte un avertissement pour les E/S résiduelles) :
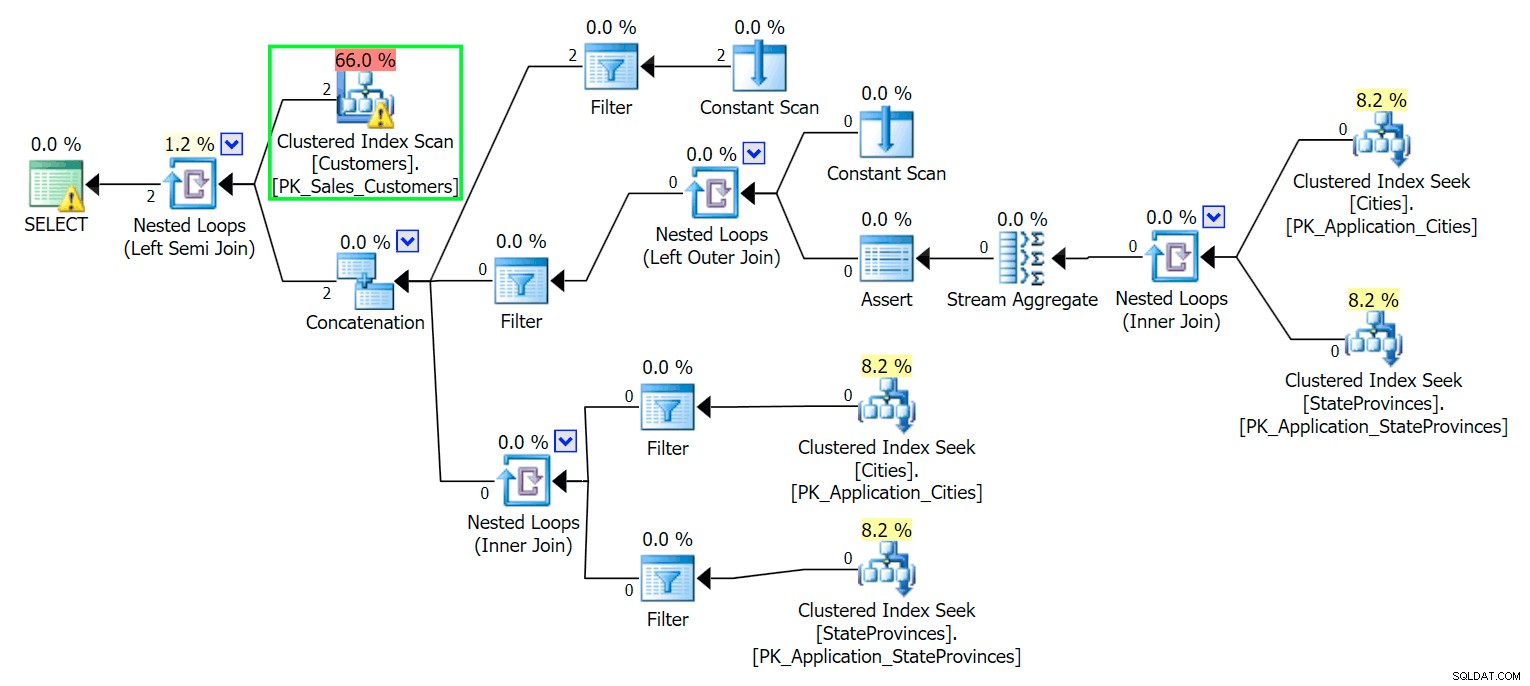
Blech. Pour garder nos vies simples et pour nous assurer de ne pas chasser un tas de faux-fuyants, créons un nouveau tableau avec un sous-ensemble de colonnes, et pour commencer, nous allons simplement insérer ces deux mêmes lignes ci-dessus :
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Maintenant, si nous exécutons la même requête que nous avons exécutée sur la table principale, nous obtenons quelque chose de beaucoup plus raisonnable à considérer comme point de départ. Cela va toujours être une analyse, peu importe ce que nous faisons - si nous ajoutons un index avec DeliveryAddressLine2 en tant que colonne de clé principale, nous obtiendrons très probablement une analyse d'index, avec une recherche de clé selon que l'index couvre les colonnes de la requête. Tel quel, nous obtenons une analyse d'index cluster :
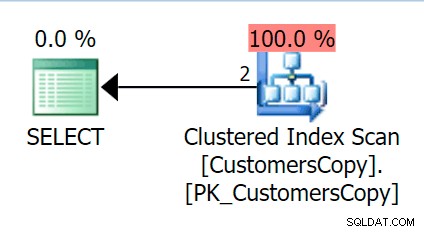
Ensuite, créons une fonction qui "explosera" ces valeurs d'adresse en fragments. Nous nous attendrions à 1846 Hudecova Crescent , par exemple, pour avoir l'ensemble de fragments suivant :
- 1846, croissant Hudecova
- 846, croissant Hudecova
- 46, croissant Hudecova
- 6 croissant Hudecova
- Croissant Hudecova
- Croissant Hudecova
- croissant udecova
- Decova Crescent
- croissant ecova
- croissant cova
- Croissant ova
- va Crescent
- un croissant
- Croissant
- Croissant
- rescent
- escent
- parfum
- centime
- ent
- nt
- t
Il est assez trivial d'écrire une fonction qui produira cette sortie - nous avons juste besoin d'un CTE récursif qui peut être utilisé pour parcourir chaque caractère sur toute la longueur de l'entrée :
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Maintenant, créons une table qui stockera tous les fragments d'adresse, et à quel client ils appartiennent :
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Ensuite, nous pouvons le remplir comme ceci :
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Pour nos deux valeurs, cela insère 42 lignes (une adresse a 20 caractères et l'autre 22). Maintenant, notre requête devient :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Voici un plan beaucoup plus agréable - deux index clusterisés *cherche* et une jointure de boucles imbriquées :
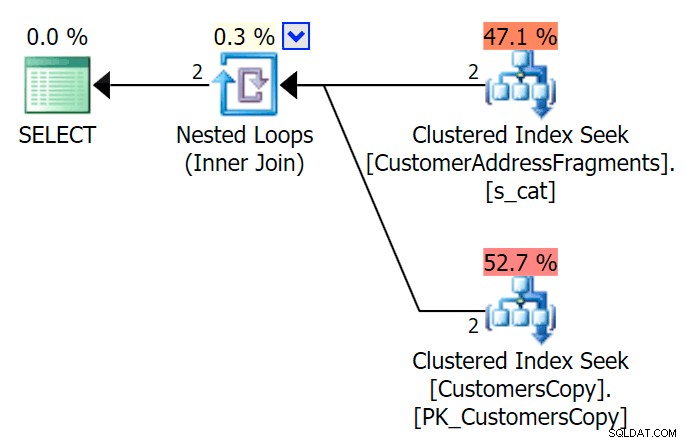
Nous pouvons également le faire d'une autre manière, en utilisant EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Voici ce plan, qui semble à première vue plus cher – il choisit de scanner la table CustomersCopy. Nous verrons bientôt pourquoi il s'agit de la meilleure approche de requête :
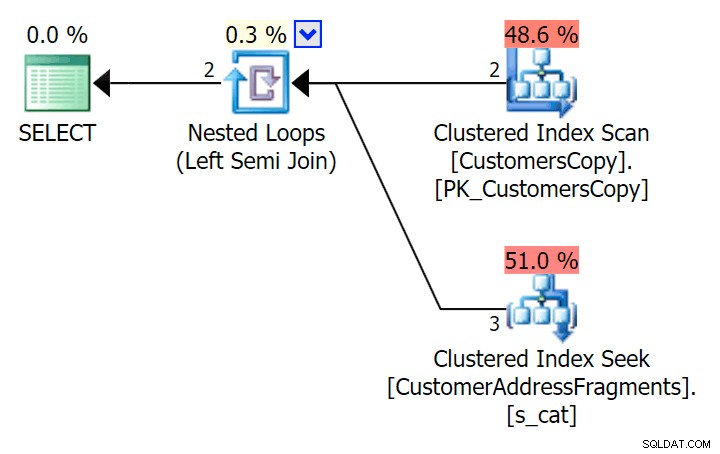
Maintenant, sur cet ensemble de données massif de 42 lignes, les différences observées dans la durée et les E/S sont si minuscules qu'elles ne sont pas pertinentes (et en fait, à cette petite taille, l'analyse par rapport à la table de base semble moins chère en termes d'E/S O que les deux autres plans qui utilisent la table des fragments) :

Et si nous remplissions ces tableaux avec beaucoup plus de données ? Ma copie de Sales.Customers a 663 lignes, donc si nous croisons cela contre lui-même, nous obtiendrions quelque part près de 440 000 lignes. Alors mélangeons 400 Ko et générons une table beaucoup plus grande :
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Maintenant, pour comparer les performances et les plans d'exécution en fonction d'une variété de paramètres de recherche possibles, j'ai testé les trois requêtes ci-dessus avec ces prédicats :
| Requête | Prédicats | ||||
|---|---|---|---|---|---|
| WHERE DeliveryLineAddress2 COMME … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| JOIGNEZ-VOUS… OÙ Fragment COMME… | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| WHERE EXISTS (… WHERE Fragment LIKE …) | |||||
Alors que nous supprimons des lettres du modèle de recherche, je m'attendrais à voir plus de lignes en sortie, et peut-être différentes stratégies choisies par l'optimiseur. Voyons comment cela s'est passé pour chaque motif :
Hudecova%
Pour ce modèle, l'analyse était toujours la même pour la condition LIKE ; cependant, avec plus de données, le coût est beaucoup plus élevé. Les recherches dans la table des fragments sont vraiment payantes à ce nombre de lignes (1 206), même avec des estimations très basses. Le plan EXISTS ajoute un tri distinct, que vous vous attendez à ajouter au coût, bien que dans ce cas, il finisse par faire moins de lectures :

 Planifier le JOIN à la table des fragments
Planifier le JOIN à la table des fragments 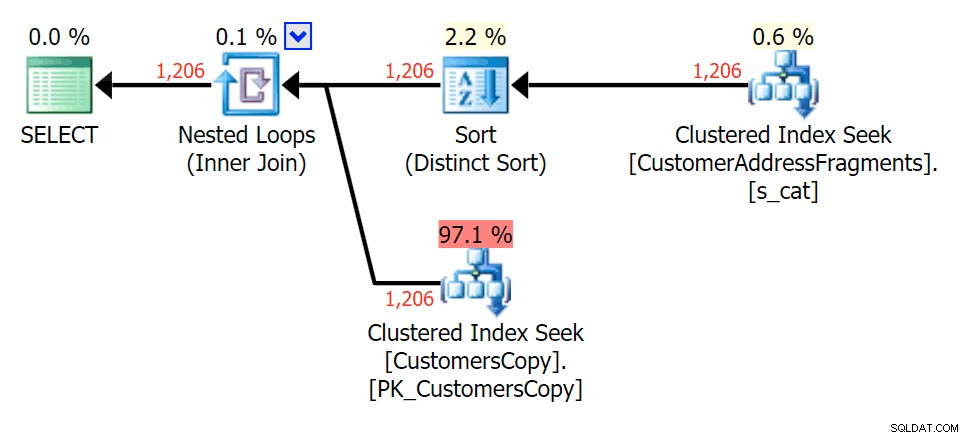 Planifiez les EXISTS par rapport à la table des fragments
Planifiez les EXISTS par rapport à la table des fragments cova%
Au fur et à mesure que nous supprimons certaines lettres de notre prédicat, nous voyons les lectures en fait un peu plus élevées qu'avec l'analyse d'index cluster d'origine, et maintenant nous sur -estimer les rangées. Même encore, notre durée reste nettement inférieure avec les deux requêtes de fragment ; la différence cette fois est plus subtile - les deux ont des sortes (seul EXISTS est distinct):

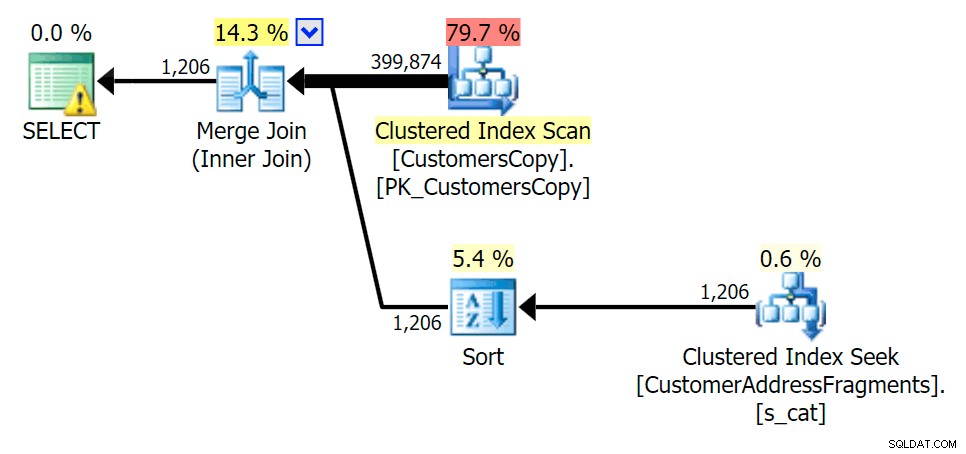 Planifier le JOIN à la table des fragments
Planifier le JOIN à la table des fragments 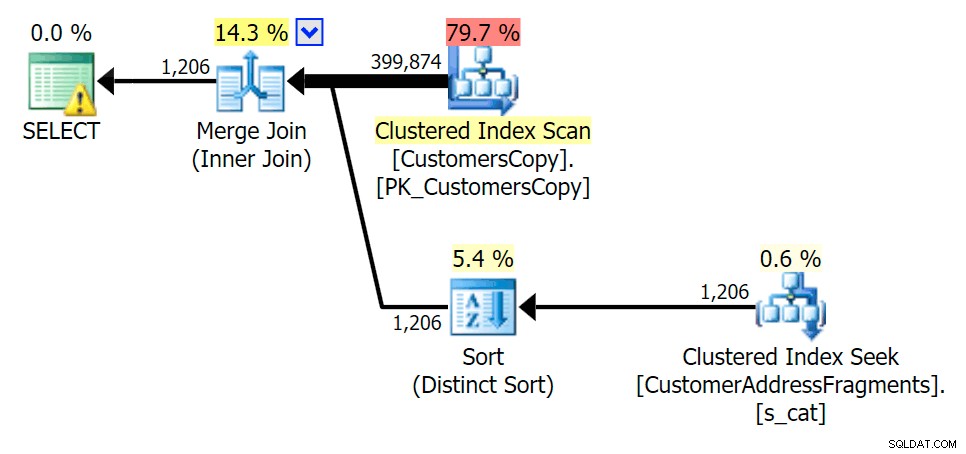 Planifier les EXISTS par rapport à la table des fragments
Planifier les EXISTS par rapport à la table des fragments ova%
Dépouiller une lettre supplémentaire n'a pas beaucoup changé; bien qu'il soit intéressant de noter à quel point les lignes estimées et réelles sautent ici - ce qui signifie qu'il peut s'agir d'un modèle de sous-chaîne commun. La requête LIKE d'origine est toujours un peu plus lente que les requêtes fragmentées.

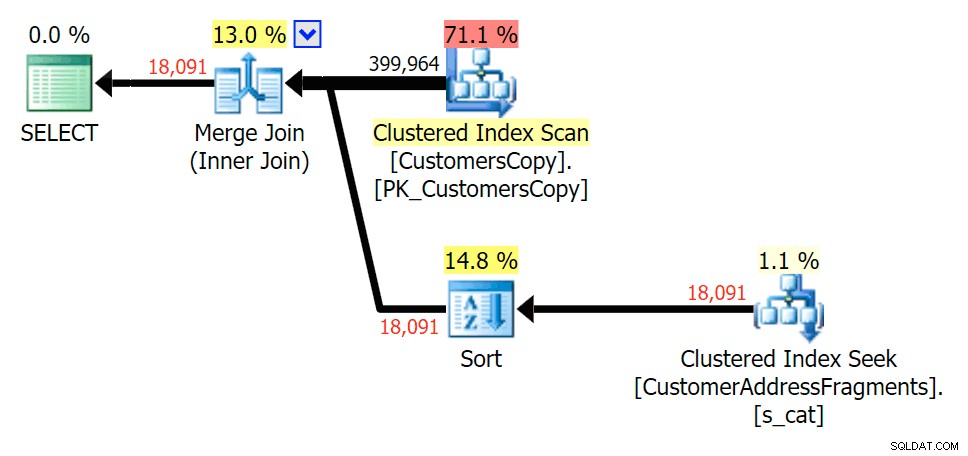 Planifier le JOIN à la table des fragments
Planifier le JOIN à la table des fragments 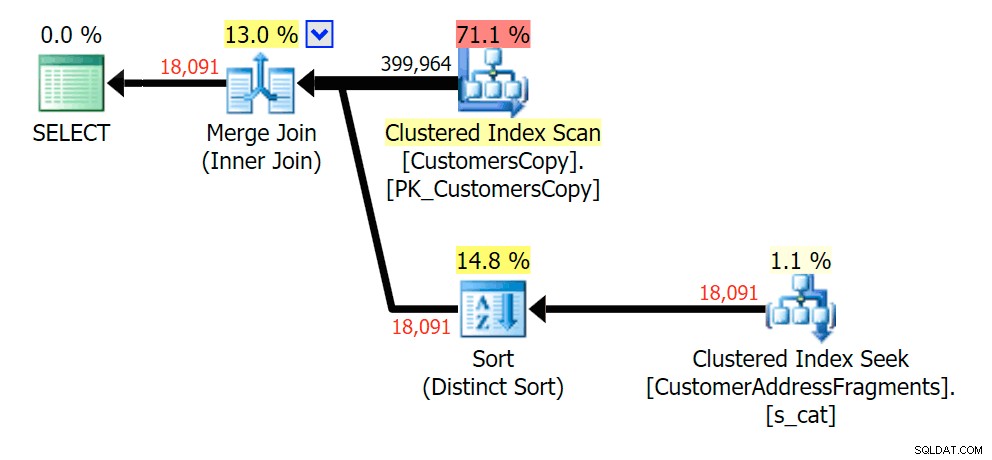 Planifiez les EXISTS par rapport à la table des fragments
Planifiez les EXISTS par rapport à la table des fragments va%
Jusqu'à deux lettres, cela introduit notre première divergence. Notez que le JOIN produit plus lignes que la requête d'origine ou EXISTS. Pourquoi serait-ce ?

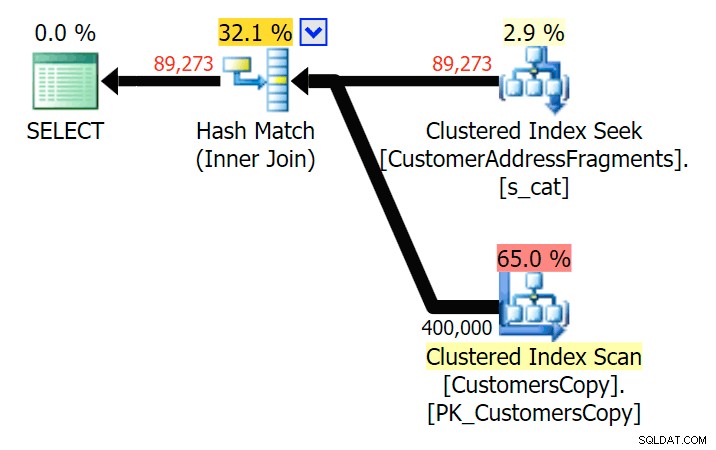 Planifier le JOIN à la table des fragments
Planifier le JOIN à la table des fragments 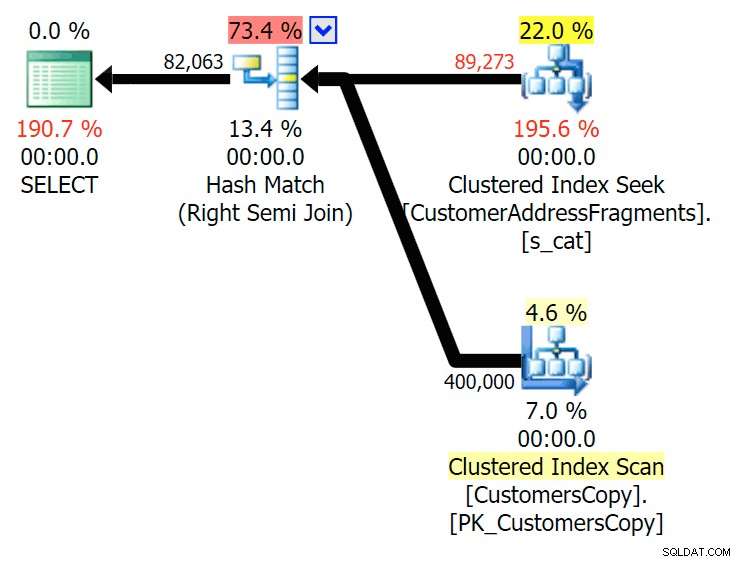 Planifiez les EXISTS par rapport à la table des fragments Nous n'avons pas à chercher bien loin. Rappelez-vous qu'il y a un fragment à partir de chaque caractère successif dans l'adresse d'origine, ce qui signifie quelque chose comme
Planifiez les EXISTS par rapport à la table des fragments Nous n'avons pas à chercher bien loin. Rappelez-vous qu'il y a un fragment à partir de chaque caractère successif dans l'adresse d'origine, ce qui signifie quelque chose comme 899 Valentova Road aura deux lignes dans la table des fragments commençant par va (sensibilité à la casse mise à part). Donc vous allez correspondre sur les deux Fragment = N'Valentova Road' et Fragment = N'va Road' . Je vais vous épargner la recherche et vous donner un seul exemple parmi tant d'autres : SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Cela explique facilement pourquoi le JOIN produit plus de lignes ; si vous souhaitez faire correspondre la sortie de la requête LIKE d'origine, vous devez utiliser EXISTS. Le fait que les résultats corrects puissent généralement aussi être obtenus d'une manière moins gourmande en ressources n'est qu'un bonus. (Je serais nerveux de voir les gens choisir le JOIN si c'était l'option la plus efficace à plusieurs reprises - vous devriez toujours privilégier les résultats corrects plutôt que de vous soucier des performances.)
Résumé
Il est clair que dans ce cas précis - avec une colonne d'adresse de nvarchar(60) et une longueur maximale de 26 caractères - la décomposition de chaque adresse en fragments peut apporter un certain soulagement aux recherches autrement coûteuses de "caractères génériques principaux". Le meilleur gain semble se produire lorsque le modèle de recherche est plus large et, par conséquent, plus unique. J'ai également démontré pourquoi EXISTS est meilleur dans les scénarios où plusieurs correspondances sont possibles - avec un JOIN, vous obtiendrez une sortie redondante à moins que vous n'ajoutiez une logique "plus grand n par groupe".
Mises en garde
Je serai le premier à admettre que cette solution est imparfaite, incomplète et mal étoffée :
- Vous devrez synchroniser la table des fragments avec la table de base à l'aide de déclencheurs :le plus simple serait pour les insertions et les mises à jour, supprimer toutes les lignes pour ces clients et les réinsérer, et pour les suppressions, supprimez évidemment les lignes des fragments table.
- Comme mentionné, cette solution fonctionnait mieux pour cette taille de données spécifique, et peut ne pas fonctionner aussi bien pour d'autres longueurs de chaîne. Cela justifierait des tests supplémentaires pour s'assurer qu'il convient à la taille de votre colonne, à la longueur de la valeur moyenne et à la longueur typique des paramètres de recherche.
- Puisque nous aurons beaucoup de copies de fragments comme "Crescent" et "Street" (peu importe les noms de rue et les numéros de maison identiques ou similaires), nous pourrions le normaliser davantage en stockant chaque fragment unique dans une table de fragments, puis encore une autre table qui agit comme une table de jonction plusieurs-à-plusieurs. Ce serait beaucoup plus lourd à mettre en place, et je ne suis pas sûr qu'il y aurait beaucoup à gagner.
- Je n'ai pas encore étudié à fond la compression de page, il semble que - du moins en théorie - cela pourrait apporter certains avantages. J'ai aussi le sentiment qu'une implémentation de columnstore peut également être bénéfique dans certains cas.
Quoi qu'il en soit, cela dit, je voulais juste le partager en tant qu'idée en développement et solliciter des commentaires sur son aspect pratique pour des cas d'utilisation spécifiques. Je peux approfondir plus de détails pour un prochain article si vous pouvez me faire savoir quels aspects de cette solution vous intéressent.