L'une des nombreuses nouvelles fonctionnalités introduites dans SQL Server 2008 était la compression des données. La compression au niveau de la ligne ou de la page offre la possibilité d'économiser de l'espace disque, avec l'inconvénient de nécessiter un peu plus de CPU pour compresser et décompresser les données. On prétend souvent que la majorité des systèmes sont liés aux E/S et non au processeur, donc le compromis en vaut la peine. Le hic ? Vous deviez être sur Enterprise Edition pour utiliser la compression de données. Avec la sortie de SQL Server 2016 SP1, cela a changé ! Si vous exécutez l'édition Standard de SQL Server 2016 SP1 et versions ultérieures, vous pouvez désormais utiliser la compression des données. Il existe également une nouvelle fonction intégrée pour la compression, COMPRESS (et son équivalent DECOMPRESS). La compression des données ne fonctionne pas sur les données hors ligne, donc si vous avez une colonne comme NVARCHAR(MAX) dans votre table avec des valeurs généralement supérieures à 8000 octets, ces données ne seront pas compressées (merci Adam Machanic pour ce rappel) . La fonction COMPRESS résout ce problème et compresse les données jusqu'à 2 Go. De plus, alors que je dirais que la fonction ne devrait être utilisée que pour les données volumineuses hors ligne, j'ai pensé que la comparer directement à la compression des lignes et des pages était une expérience intéressante.
CONFIGURATION
Pour les données de test, je travaille à partir d'un script qu'Aaron Bertrand a utilisé précédemment, mais j'ai fait quelques ajustements. J'ai créé une base de données distincte pour les tests, mais vous pouvez utiliser tempdb ou un autre exemple de base de données, puis j'ai commencé avec une table Customers comportant trois colonnes NVARCHAR. J'ai envisagé de créer des colonnes plus grandes et de les remplir avec des chaînes de lettres répétées, mais l'utilisation de texte lisible donne un échantillon plus réaliste et offre donc une plus grande précision.
Remarque : Si vous êtes intéressé par la mise en œuvre de la compression et que vous voulez savoir comment cela affectera le stockage et les performances dans votre environnement, JE VOUS RECOMMANDE VIVEMENT DE LA TESTER. Je vous donne la méthodologie avec des exemples de données ; l'implémenter dans votre environnement ne devrait pas impliquer de travail supplémentaire.
Vous noterez ci-dessous qu'après avoir créé la base de données, nous activons Query Store. Pourquoi créer un tableau séparé pour essayer de suivre nos mesures de performances alors que nous pouvons simplement utiliser les fonctionnalités intégrées à SQL Server ? !
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Nous allons maintenant configurer certaines choses dans la base de données :
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Avec la table créée, nous allons ajouter des données, mais nous ajoutons 5 millions de lignes au lieu de 1 million. Cela prend environ huit minutes pour s'exécuter sur mon ordinateur portable.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Nous allons maintenant créer trois tables supplémentaires :une pour la compression des lignes, une pour la compression des pages et une pour la fonction COMPRESS. Notez qu'avec la fonction COMPRESS, vous devez créer les colonnes en tant que types de données VARBINARY. Par conséquent, il n'y a pas d'index non clusterisés sur la table (car vous ne pouvez pas créer de clé d'index sur une colonne varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Ensuite, nous allons copier les données de [dbo].[Customers] vers les trois autres tables. Il s'agit d'un simple INSERT pour nos tables de pages et de lignes et prend environ deux à trois minutes pour chaque INSERT, mais il y a un problème d'évolutivité avec la fonction COMPRESS :essayer d'insérer 5 millions de lignes d'un seul coup n'est tout simplement pas raisonnable. Le script ci-dessous insère des lignes par lots de 50 000 et n'insère que 1 million de lignes au lieu de 5 millions. Je sais, cela signifie que nous ne sommes pas vraiment des pommes avec des pommes ici à des fins de comparaison, mais je suis d'accord avec ça. Insérer 1 million de lignes prend 10 minutes sur ma machine; n'hésitez pas à modifier le script et à insérer 5 millions de lignes pour vos propres tests.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Avec toutes nos tables remplies, nous pouvons faire une vérification de la taille. À ce stade, nous n'avons pas implémenté la compression ROW ou PAGE, mais la fonction COMPRESS a été utilisée :
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
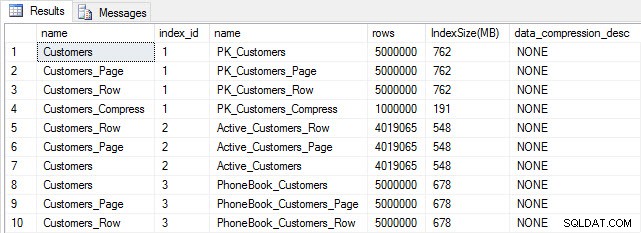 Taille du tableau et de l'index après insertion
Taille du tableau et de l'index après insertion
Comme prévu, toutes les tables sauf Customers_Compress ont à peu près la même taille. Nous allons maintenant reconstruire les index sur toutes les tables, en implémentant la compression des lignes et des pages sur Customers_Row et Customers_Page, respectivement.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Si nous vérifions la taille de la table après la compression, nous pouvons maintenant voir nos économies d'espace disque :
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
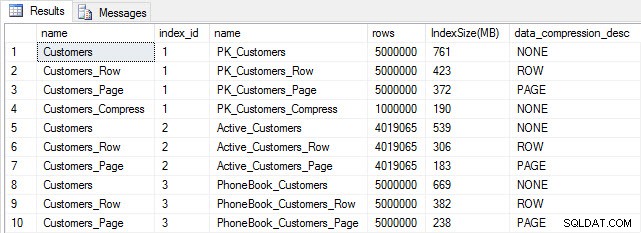
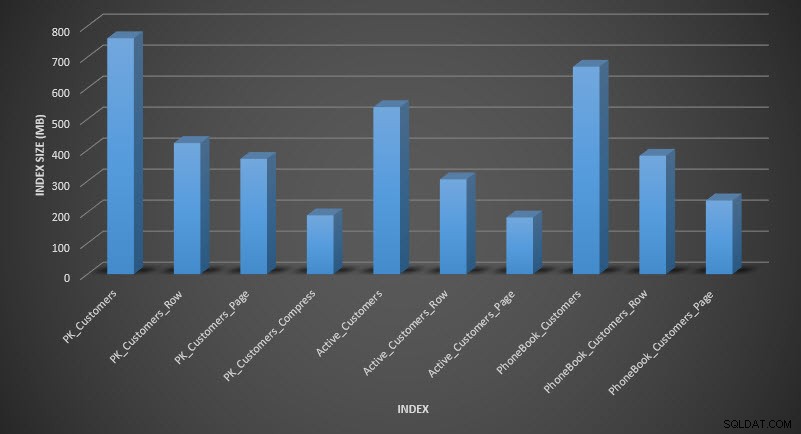 Taille de l'index après compression
Taille de l'index après compression
Comme prévu, la compression des lignes et des pages diminue considérablement la taille de la table et de ses index. La fonction COMPRESS nous a permis d'économiser le plus d'espace :l'index clusterisé représente le quart de la taille de la table d'origine.
EXAMEN DES PERFORMANCES DES REQUÊTES
Avant de tester les performances des requêtes, notez que nous pouvons utiliser le magasin de requêtes pour examiner les performances d'INSERT et de RECONSTRUIRE :
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
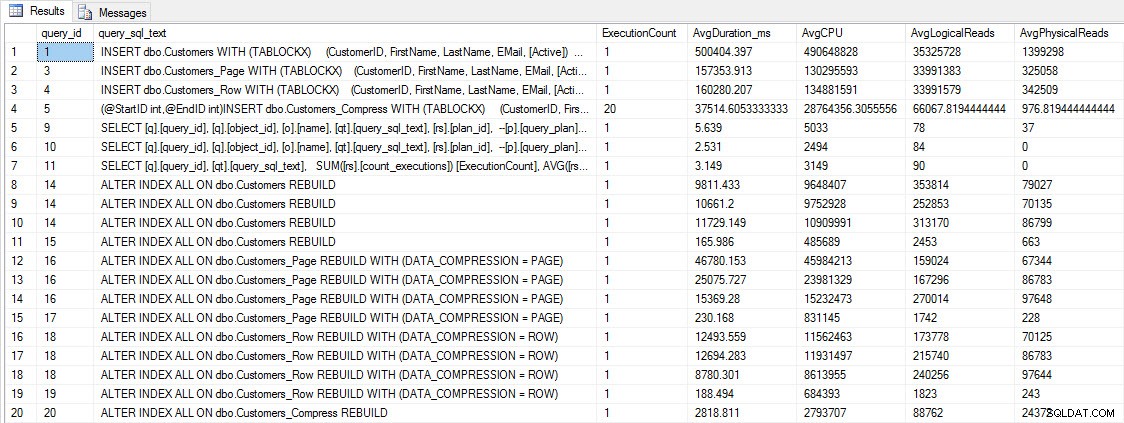 INSÉRER et RECONSTRUIRE les métriques de performance
INSÉRER et RECONSTRUIRE les métriques de performance
Bien que ces données soient intéressantes, je suis plus curieux de savoir comment la compression affecte mes requêtes SELECT quotidiennes. J'ai un ensemble de trois procédures stockées qui ont chacune une requête SELECT, de sorte que chaque index est utilisé. J'ai créé ces procédures pour chaque table, puis j'ai écrit un script pour extraire les valeurs des prénoms et des noms à utiliser pour les tests. Voici le script pour créer les procédures.
Une fois les procédures stockées créées, nous pouvons exécuter le script ci-dessous pour les appeler. Lancez-le et attendez quelques minutes…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Après quelques minutes, jetez un coup d'œil au contenu du magasin de requêtes :
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Vous verrez que la plupart des procédures stockées ne se sont exécutées que 20 fois car deux procédures contre [dbo].[Customers_Compress] sont vraiment lent. Ce n'est pas une surprise; ni [FirstName] ni [LastName] ne sont indexés, donc toute requête devra parcourir la table. Je ne veux pas que ces deux requêtes ralentissent mes tests, je vais donc modifier la charge de travail et commenter EXEC [dbo].[usp_FindActiveCustomer_CS] et EXEC [dbo].[usp_FindAnyCustomer_CS], puis redémarrez-le. Cette fois, je vais le laisser fonctionner pendant environ 10 minutes, et quand je regarde à nouveau la sortie du magasin de requêtes, j'ai maintenant de bonnes données. Les chiffres bruts sont ci-dessous, avec les graphiques préférés des managers ci-dessous.
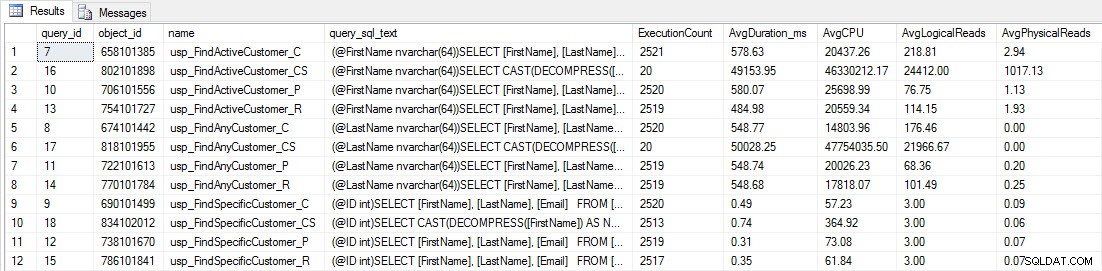 Données de performances du magasin de requêtes
Données de performances du magasin de requêtes
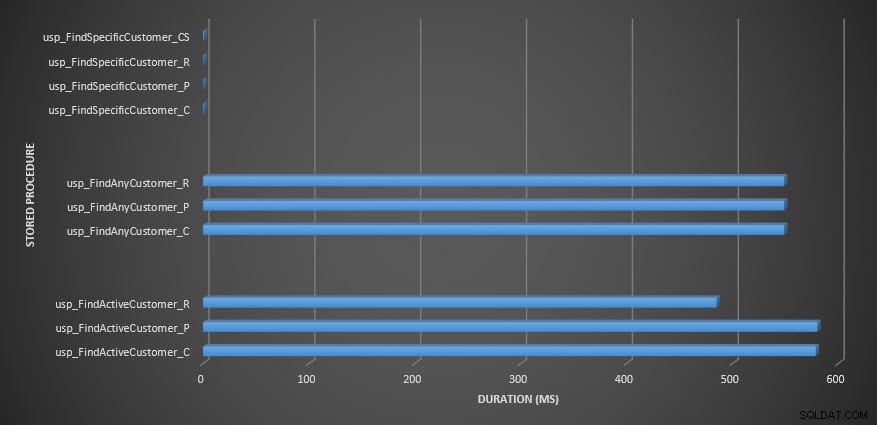 Durée de la procédure stockée
Durée de la procédure stockée
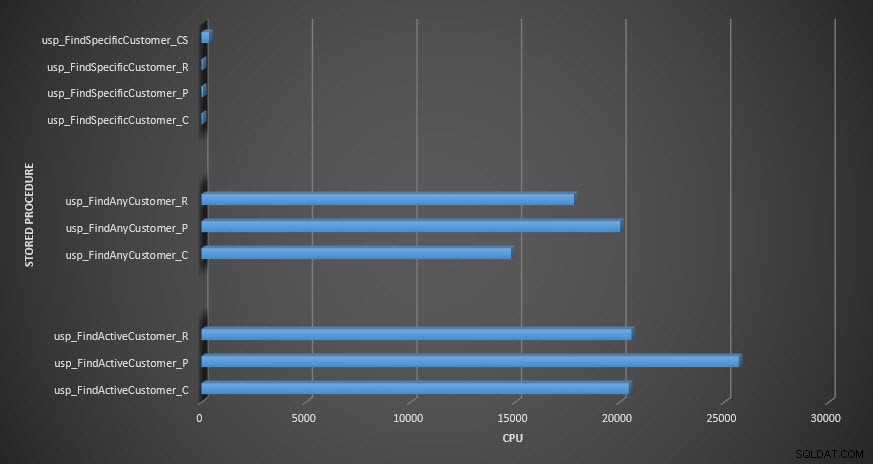 Procédure stockée CPU
Procédure stockée CPU
Rappel :Toutes les procédures stockées qui se terminent par _C proviennent de la table non compressée. Les procédures se terminant par _R sont la table compressée en ligne, celles se terminant par _P sont compressées en page, et celle avec _CS utilise la fonction COMPRESS (j'ai supprimé les résultats de ladite table pour usp_FindAnyCustomer_CS et usp_FindActiveCustomer_CS car ils ont tellement faussé le graphique que nous avons perdu le différences dans le reste des données). Les procédures usp_FindAnyCustomer_* et usp_FindActiveCustomer_* utilisaient des index non clusterisés et renvoyaient des milliers de lignes pour chaque exécution.
Je m'attendais à ce que la durée soit plus élevée pour les procédures usp_FindAnyCustomer_* et usp_FindActiveCustomer_* par rapport aux tables compressées de lignes et de pages, par rapport à la table non compressée, en raison de la surcharge de décompression des données. Les données du magasin de requêtes ne prennent pas en charge mes attentes - la durée de ces deux procédures stockées est à peu près la même (ou moins dans un cas !) Dans ces trois tables. L'E/S logique pour les requêtes était presque la même dans les tables non compressées et les tables compressées de pages et de lignes.
En termes de CPU, dans les procédures stockées usp_FindActiveCustomer et usp_FindAnyCustomer, il était toujours plus élevé pour les tables compressées. Le processeur était comparable pour la procédure usp_FindSpecificCustomer, qui était toujours une recherche singleton par rapport à l'index clusterisé. Notez le CPU élevé (mais la durée relativement faible) pour la procédure usp_FindSpecificCustomer par rapport à la table [dbo].[Customer_Compress], qui nécessitait la fonction DECOMPRESS pour afficher les données dans un format lisible.
RÉSUMÉ
Le processeur supplémentaire requis pour récupérer les données compressées existe et peut être mesuré à l'aide du magasin de requêtes ou des méthodes de référencement traditionnelles. Sur la base de ces tests initiaux, le CPU est comparable pour les recherches singleton, mais augmente avec plus de données. Je voulais forcer SQL Server à décompresser plus de 10 pages - je voulais au moins 100. J'ai exécuté des variantes de ce script, où des dizaines de milliers de lignes ont été renvoyées, et les résultats étaient cohérents avec ce que vous voyez ici. Je m'attends à ce que pour voir des différences significatives de durée en raison du temps de décompression des données, les requêtes doivent renvoyer des centaines de milliers ou des millions de lignes. Si vous êtes dans un système OLTP, vous ne voulez pas renvoyer autant de lignes, donc les tests ici devraient vous donner une idée de la façon dont la compression peut affecter les performances. Si vous êtes dans un entrepôt de données, vous verrez probablement une durée plus longue ainsi qu'un processeur plus élevé lors du retour de grands ensembles de données. Bien que la fonction COMPRESS offre des économies d'espace importantes par rapport à la compression de pages et de lignes, les performances en termes de CPU et l'impossibilité d'indexer les colonnes compressées en raison de leur type de données, la rendent viable uniquement pour les gros volumes de données qui ne seront pas cherché.