Je pense que tout le monde connaît déjà mon opinion sur MERGE et pourquoi je m'en éloigne. Mais voici un autre (anti-) modèle que je vois partout lorsque les gens veulent effectuer un upsert (mettez à jour une ligne si elle existe et insérez-la si ce n'est pas le cas) :
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Cela ressemble à un flux assez logique qui reflète notre façon de penser à cela dans la vraie vie :
- Une ligne existe-t-elle déjà pour cette clé ?
- OUI :OK, mettez à jour cette ligne.
- NON :OK, puis ajoutez-le.
Mais c'est du gaspillage.
Localiser la ligne pour confirmer qu'elle existe, seulement pour avoir à la localiser à nouveau afin de la mettre à jour, fait deux fois le travail pour rien. Même si la clé est indexée (ce qui j'espère est toujours le cas). Si je mettais cette logique dans un organigramme et associais, à chaque étape, le type d'opération qui devrait se produire dans la base de données, j'aurais ceci :
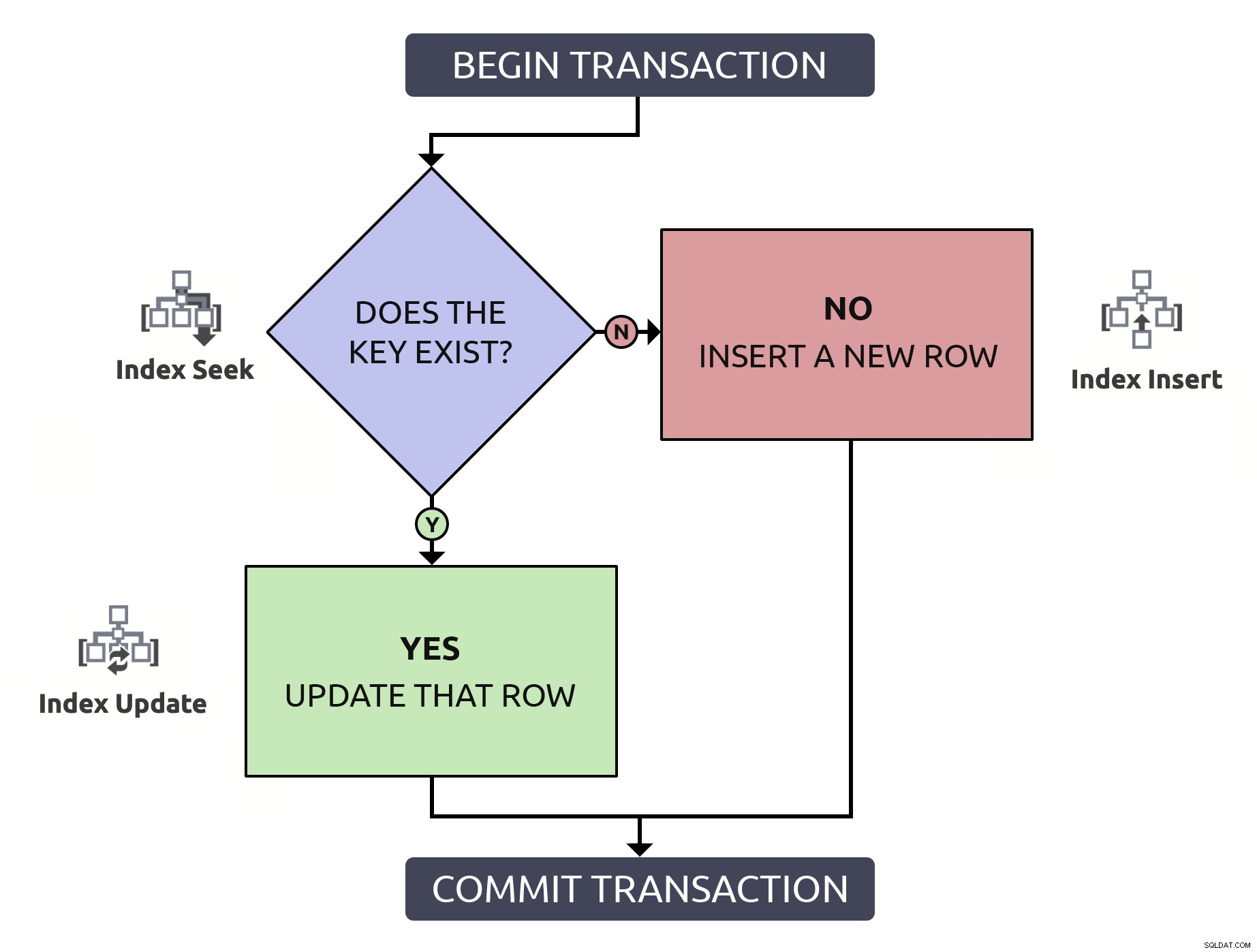 Notez que tous les chemins entraîneront deux opérations d'index.
Notez que tous les chemins entraîneront deux opérations d'index.
Plus important encore, performances mises à part, à moins que vous n'utilisiez à la fois une transaction explicite et que vous n'éleviez le niveau d'isolement, plusieurs problèmes peuvent survenir lorsque la ligne n'existe pas déjà :
- Si la clé existe et que deux sessions tentent de se mettre à jour simultanément, elles se mettront toutes les deux à jour avec succès (l'un "gagnera" ; le "perdant" suivra avec le changement qui reste, conduisant à une "mise à jour perdue"). Ce n'est pas un problème en soi, et c'est ainsi que nous devrons s'attendre à ce qu'un système avec concurrence fonctionne. Paul White parle de la mécanique interne plus en détail ici, et Martin Smith parle d'autres nuances ici.
- Si la clé n'existe pas, mais que les deux sessions réussissent la vérification d'existence de la même manière, tout peut arriver lorsqu'elles essaient toutes les deux d'insérer :
- impasse en raison de verrous incompatibles ;
- soulever des erreurs de violation de clé cela n'aurait pas dû arriver; ou,
- insérer des valeurs de clé en double si cette colonne n'est pas correctement contrainte.
Ce dernier est le pire, à mon humble avis, car c'est celui qui potentiellement corrompt les données . Les interblocages et les exceptions peuvent être gérés facilement avec des choses comme la gestion des erreurs, XACT_ABORT , et la logique de nouvelle tentative, en fonction de la fréquence à laquelle vous prévoyez des collisions. Mais si vous êtes bercé par un sentiment de sécurité que le IF EXISTS check vous protège des doublons (ou des violations de clé), c'est une surprise qui attend de se produire. Si vous vous attendez à ce qu'une colonne agisse comme une clé, rendez-la officielle et ajoutez une contrainte.
"Beaucoup de gens disent…"
Dan Guzman a parlé des conditions de course il y a plus de dix ans dans la condition de course conditionnelle INSERT/UPDATE et plus tard dans la condition de course "UPSERT" avec MERGE.
Michael Swart a également traité ce sujet à plusieurs reprises :
- Démystifier :Mise à jour simultanée/Insérer des solutions – où il a reconnu que le fait de laisser la logique initiale en place et d'élever uniquement le niveau d'isolement ne faisait que transformer les principales violations en blocages ;
- Soyez prudent avec la déclaration de fusion – où il a vérifié son enthousiasme à propos de
MERGE; et, - Ce qu'il faut éviter si vous voulez utiliser MERGE – où il a confirmé une fois de plus qu'il existe encore de nombreuses raisons valables de continuer à éviter
MERGE.
Assurez-vous également de lire tous les commentaires sur les trois messages.
La solution
J'ai résolu de nombreux blocages dans ma carrière en m'adaptant simplement au schéma suivant (abandonnez la vérification redondante, encapsulez la séquence dans une transaction et protégez le premier accès à la table avec un verrouillage approprié) :
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Pourquoi avons-nous besoin de deux indices ? N'est-ce pas UPDLOCK assez ?
UPDLOCKest utilisé pour se protéger contre les interblocages de conversion au niveau de l'instruction niveau (laisser une autre session attendre au lieu d'encourager une victime à réessayer).SERIALIZABLEest utilisé pour protéger contre les modifications des données sous-jacentes tout au long de la transaction (s'assurer qu'une ligne qui n'existe pas continue à ne pas exister).
C'est un peu plus de code, mais c'est 1000 % plus sûr, et même dans le pire cas (la ligne n'existe pas déjà), il exécute la même chose que l'anti-modèle. Dans le meilleur des cas, si vous mettez à jour une ligne qui existe déjà, il sera plus efficace de localiser cette ligne une seule fois. En combinant cette logique avec les opérations de haut niveau qui devraient se produire dans la base de données, c'est légèrement plus simple :
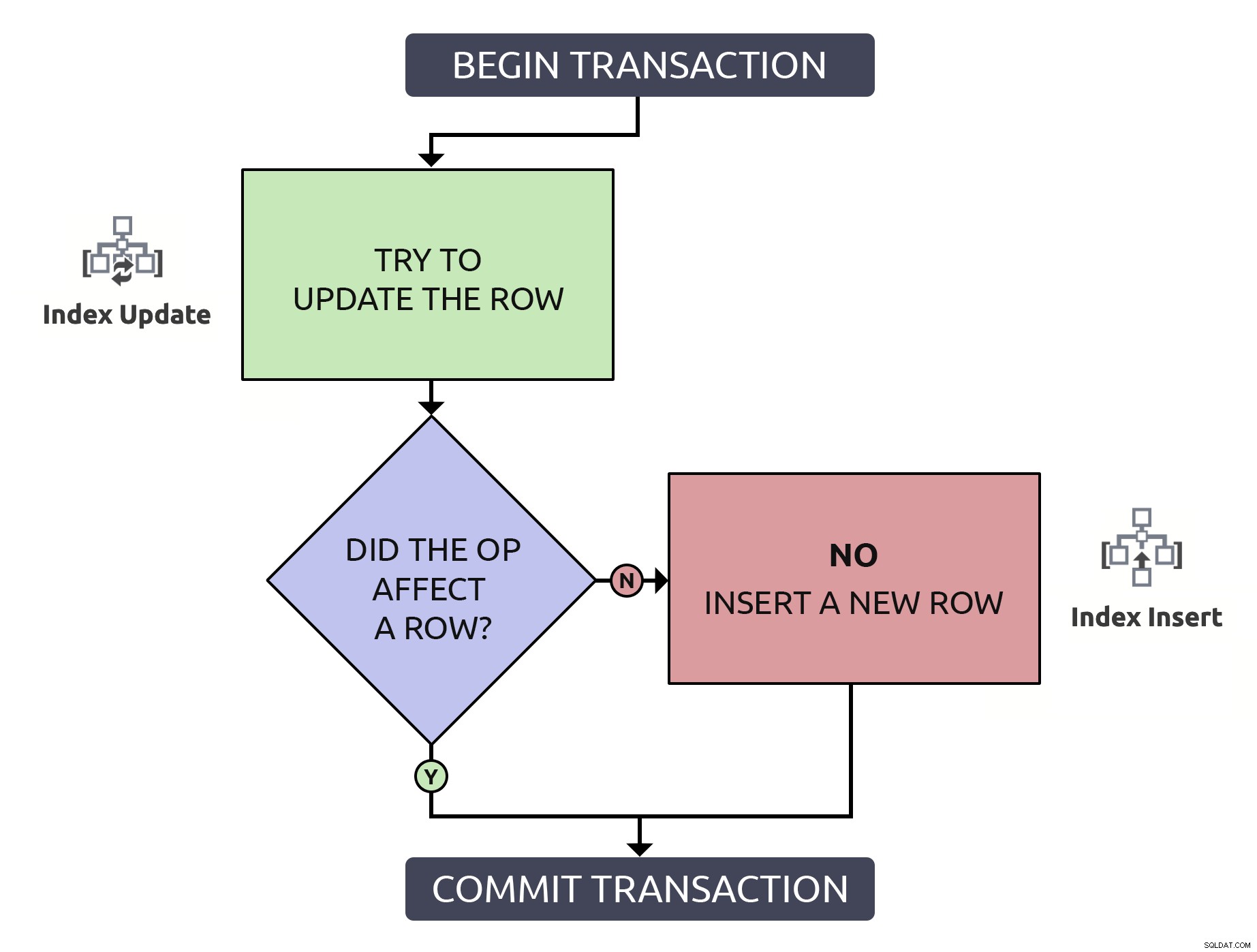 Dans ce cas, un chemin n'implique qu'une seule opération d'indexation.
Dans ce cas, un chemin n'implique qu'une seule opération d'indexation.
Mais encore une fois, performances mises à part :
- Si la clé existe et que deux sessions tentent de la mettre à jour en même temps, elles se succèdent et mettent à jour la ligne avec succès , comme avant.
- Si la clé n'existe pas, une session "gagne" et insère la ligne . L'autre devra attendre jusqu'à ce que les verrous soient libérés pour même vérifier l'existence, et être obligé de mettre à jour.
Dans les deux cas, l'écrivain qui a remporté la course perd ses données au profit de tout ce que le "perdant" a mis à jour après lui.
Notez que le débit global sur un système hautement simultané pourrait souffrir, mais c'est un compromis que vous devriez être prêt à faire. Le fait que vous ayez beaucoup de victimes de blocages ou d'erreurs de violation de clé, mais qu'elles se produisent rapidement, n'est pas une bonne mesure de performance. Certaines personnes aimeraient voir tous les blocages supprimés de tous les scénarios, mais certains d'entre eux bloquent ce que vous voulez absolument pour l'intégrité des données.
Mais que se passe-t-il si une mise à jour est moins probable ?
Il est clair que la solution ci-dessus optimise les mises à jour et suppose qu'une clé sur laquelle vous essayez d'écrire existe déjà dans la table au moins aussi souvent qu'elle n'existe pas. Si vous préférez optimiser les insertions, sachant ou devinant que les insertions seront plus probables que les mises à jour, vous pouvez inverser la logique et conserver une opération d'upsert sûre :
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Il y a aussi l'approche "just do it", où vous insérez aveuglément et laissez les collisions déclencher des exceptions pour l'appelant :
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Le coût de ces exceptions l'emportera souvent sur le coût d'une première vérification; vous devrez l'essayer avec une estimation à peu près précise du taux de réussite/échec. J'ai écrit à ce sujet ici et ici.
Qu'en est-il de la mise en place de plusieurs lignes ?
Ce qui précède traite des décisions d'insertion/mise à jour de singleton, mais Justin Pealing a demandé que faire lorsque vous traitez plusieurs lignes sans savoir lesquelles existent déjà ?
En supposant que vous envoyiez un ensemble de lignes en utilisant quelque chose comme un paramètre de table, vous mettriez à jour en utilisant une jointure, puis insérez en utilisant NOT EXISTS, mais le modèle serait toujours équivalent à la première approche ci-dessus :
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Si vous rassemblez plusieurs lignes d'une autre manière qu'un TVP (XML, liste séparée par des virgules, vaudou), placez-les d'abord dans un tableau et joignez-les à tout ce que c'est. Veillez à ne pas optimiser d'abord les insertions dans ce scénario, sinon vous risquez de mettre à jour certaines lignes deux fois.
Conclusion
Ces modèles d'upsert sont supérieurs à ceux que je vois trop souvent, et j'espère que vous commencerez à les utiliser. Je pointerai vers ce post chaque fois que je repèrerai le IF EXISTS motif à l'état sauvage. Et, hé, un autre merci à Paul White (sql.kiwi | @SQK_Kiwi), parce qu'il est si excellent pour rendre les concepts difficiles faciles à comprendre et, à leur tour, à expliquer.
Et si vous sentez que vous devez utilisez MERGE , s'il vous plaît ne me @ pas ; soit vous avez une bonne raison (peut-être avez-vous besoin d'un obscur MERGE -fonctionnalité uniquement), ou vous n'avez pas pris les liens ci-dessus au sérieux.