@rob_farley votre solution récente de stackoverflow pour ordonner d'abord par une valeur puis un champ est génie! Je voulais vous remercier personnellement.
— Joel Sacco (@Jsac90) 11 août 2016
J'ai vu ce tweet passer…
Et cela m'a fait regarder à quoi il faisait référence, car je n'avais rien écrit "récemment" sur StackOverflow à propos de la commande de données. Il s'avère que c'était cette réponse que j'avais écrite , qui, bien que n'étant pas la réponse acceptée, a recueilli plus d'une centaine de votes.
La personne qui posait la question avait un problème très simple :vouloir faire apparaître certaines lignes en premier. Et ma solution était simple :
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Cela semble avoir été une réponse populaire, y compris pour Joel Sacco (selon ce tweet ci-dessus).
L'idée est de former une expression, et d'ordonner par là. ORDER BY ne se soucie pas de savoir s'il s'agit d'une colonne réelle ou non. Vous auriez pu faire la même chose en utilisant APPLY, si vous préférez vraiment utiliser une 'colonne' dans votre clause ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Si j'utilise des requêtes sur WideWorldImporters, je peux vous montrer pourquoi ces deux requêtes sont vraiment identiques. Je vais interroger la table Sales.Orders, en demandant que les commandes du vendeur 7 apparaissent en premier. Je vais également créer un index de couverture approprié :
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Les plans de ces deux requêtes semblent identiques. Ils fonctionnent de manière identique - mêmes lectures, mêmes expressions, il s'agit vraiment de la même requête. S'il y a une légère différence dans le processeur ou la durée réels, c'est un coup de chance en raison d'autres facteurs.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
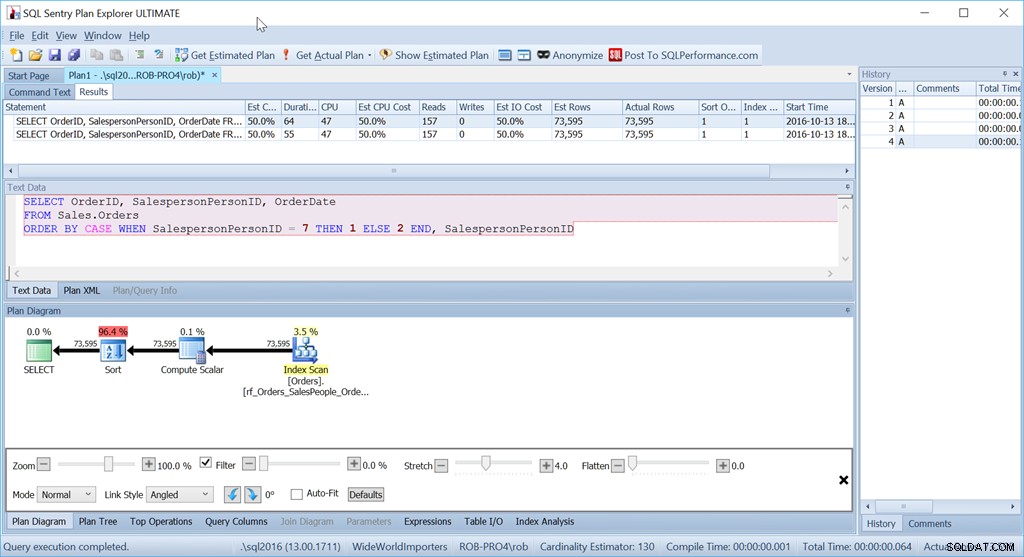
Et pourtant, ce n'est pas la requête que j'utiliserais réellement dans cette situation. Pas si la performance était importante pour moi. (C'est généralement le cas, mais cela ne vaut pas toujours la peine d'écrire une requête longue si la quantité de données est petite.)
Ce qui me dérange, c'est cet opérateur de tri. C'est 96,4% du coût!
Considérez si nous voulons simplement commander par SalespersonPersonID :
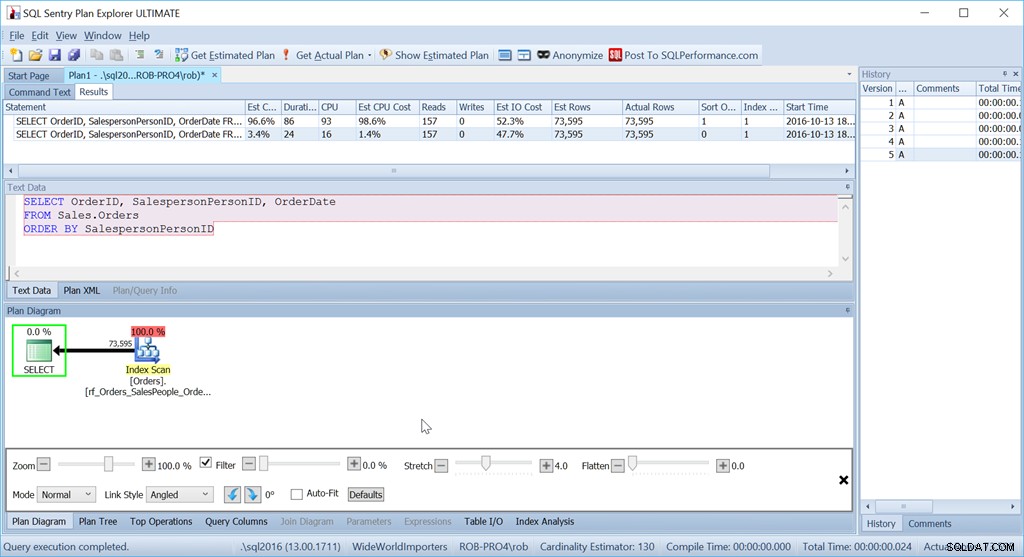
Nous constatons que le coût CPU estimé de cette requête plus simple est de 1,4 % du lot, tandis que celui de la version triée sur mesure est de 98,6 %. C'est soixante-dix fois pire. Les lectures sont les mêmes, c'est bien. La durée est bien pire, tout comme le CPU.
Je n'aime pas Sorts. Ils peuvent être méchants.
Une option que j'ai ici est d'ajouter une colonne calculée à ma table et de l'indexer, mais cela aura un impact sur tout ce qui recherche toutes les colonnes de la table, comme les ORM, Power BI ou tout ce qui fait SELECT * . Ce n'est donc pas si génial (bien que si jamais nous arrivions à ajouter des colonnes calculées cachées, cela constituerait une très bonne option ici).
Une autre option, qui est plus longue (certains pourraient suggérer que cela me conviendrait - et si vous pensiez que :Oi ! Ne soyez pas si impoli !), Et utilise plus de lectures, consiste à considérer ce que nous ferions dans la vraie vie si nous devions le faire.
Si j'avais une pile de 73 595 commandes, triées par commande de vendeur, et que je devais d'abord les renvoyer avec un vendeur particulier, je ne négligerais pas l'ordre dans lequel elles se trouvaient et je les trierais simplement toutes, je commencerais par plonger et trouver ceux pour le vendeur 7 - en les gardant dans l'ordre dans lequel ils se trouvaient. Ensuite, je trouverais ceux qui n'étaient pas ceux qui n'étaient pas le vendeur 7 - en les plaçant ensuite, et en les gardant à nouveau dans l'ordre où ils étaient déjà po.
En T-SQL, cela se fait comme ceci :
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Cela obtient deux ensembles de données et les concatène. Mais l'optimiseur de requête peut voir qu'il doit maintenir l'ordre SalespersonPersonID, une fois les deux ensembles concaténés, il effectue donc un type spécial de concaténation qui maintient cet ordre. Il s'agit d'une jointure par fusion (concaténation) et le plan ressemble à ceci :
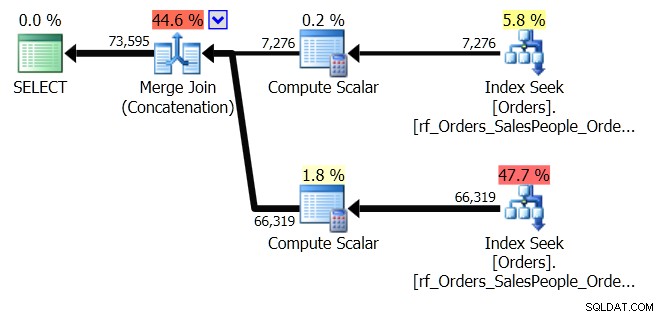
Vous voyez que c'est beaucoup plus compliqué. Mais j'espère que vous remarquerez également qu'il n'y a pas d'opérateur de tri. La jointure de fusion (concaténation) extrait les données de chaque branche et produit un ensemble de données qui est dans le bon ordre. Dans ce cas, il extrait d'abord les 7 276 lignes du vendeur 7, puis extrait les 66 319 autres, car il s'agit de l'ordre requis. Dans chaque ensemble, les données sont dans l'ordre SalespersonPersonID, qui est maintenu au fur et à mesure que les données transitent.
J'ai mentionné plus tôt qu'il utilise plus de lectures, et c'est le cas. Si j'affiche la sortie SET STATISTICS IO, en comparant les deux requêtes, je vois ceci :
Tableau 'Table de travail'. Nombre de balayages 0, lectures logiques 0, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.Tableau 'Commandes'. Nombre de balayages 1, lectures logiques 157, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
Tableau 'Commandes '. Nombre de balayages 3, lectures logiques 163, lectures physiques 0, lectures anticipées 0, lectures logiques lob 0, lectures physiques lob 0, lectures anticipées lob 0.
En utilisant la version "Custom Sort", c'est juste un scan de l'index, en utilisant 157 lectures. En utilisant la méthode "Union All", il s'agit de trois scans - un pour SalespersonPersonID =7, un pour SalespersonPersonID <7 et un pour SalespersonPersonID> 7. Nous pouvons voir ces deux derniers en regardant les propriétés du second Index Seek :
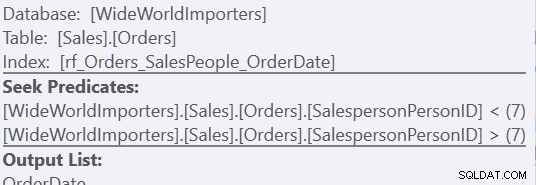
Pour moi, cependant, l'avantage se traduit par l'absence d'une table de travail.
Regardez le coût CPU estimé :

Ce n'est pas aussi petit que nos 1,4 % lorsque nous évitons complètement le tri, mais c'est quand même une grande amélioration par rapport à notre méthode de tri personnalisé.
Mais un mot d'avertissement…
Supposons que j'aie créé cet index différemment et que OrderDate soit une colonne clé plutôt qu'une colonne incluse.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Maintenant, ma méthode "Union All" ne fonctionne pas du tout comme prévu.
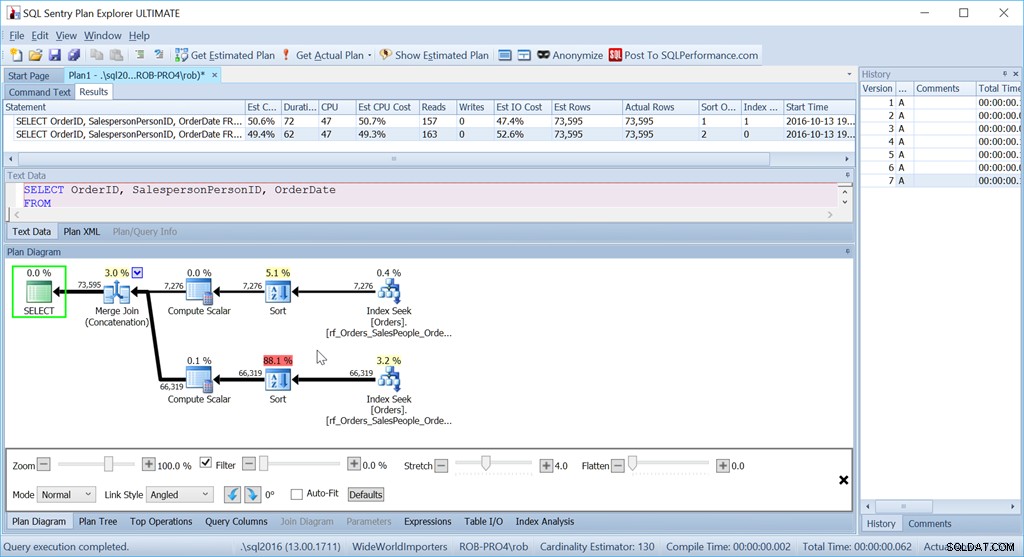
Bien qu'utilisant exactement les mêmes requêtes qu'auparavant, mon bon plan a maintenant deux opérateurs de tri, et il fonctionne presque aussi mal que ma version originale de Scan + Sort.
La raison en est une bizarrerie de l'opérateur Merge Join (Concaténation), et l'indice se trouve dans l'opérateur Sort.

Il commande par SalespersonPersonID suivi de OrderID - qui est la clé d'index cluster de la table. Il choisit cela car il est connu pour être unique et il s'agit d'un ensemble de colonnes plus petit que SalespersonPersonID suivi de OrderDate suivi de OrderID, qui est l'ordre de l'ensemble de données produit par trois balayages de plage d'index. Un de ces moments où l'optimiseur de requête ne remarque pas une meilleure option qui se trouve juste là.
Avec cet index, nous aurions également besoin de notre ensemble de données trié par OrderDate pour produire notre plan préféré.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
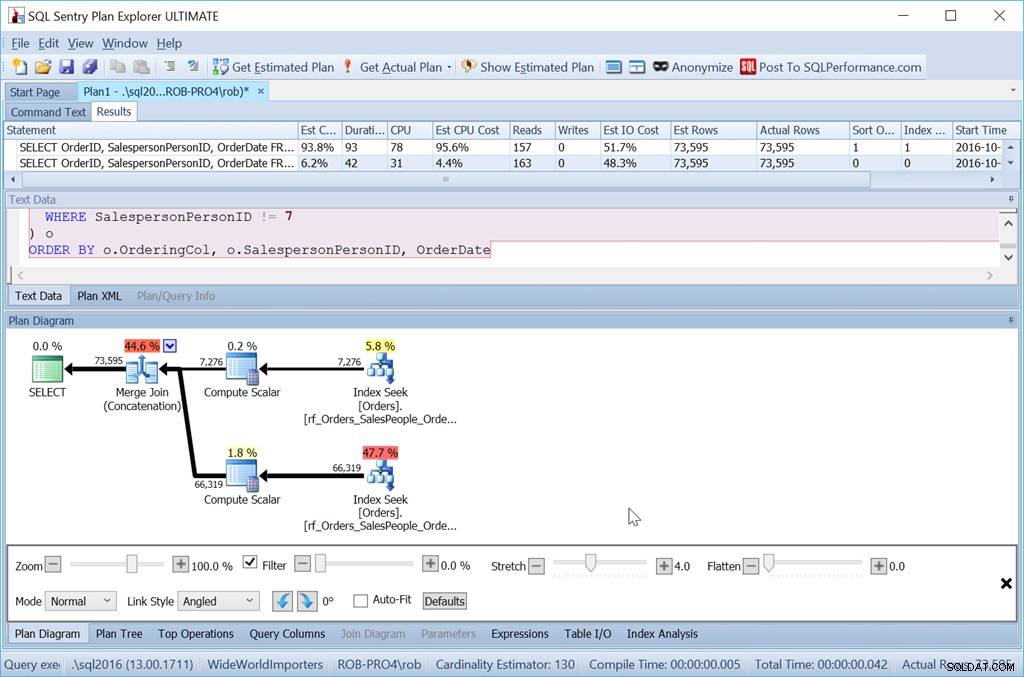
Donc, c'est certainement plus d'effort. La requête est plus longue à écrire pour moi, c'est plus de lectures et je dois avoir un index sans colonnes de clé supplémentaires. Mais c'est certainement plus rapide. Avec encore plus de lignes, l'impact est encore plus grand, et je n'ai pas non plus à risquer qu'un Sort déborde sur tempdb.
Pour les petits ensembles, ma réponse StackOverflow est toujours bonne. Mais lorsque cet opérateur de tri me coûte en performances, j'utilise la méthode Union All / Merge Join (Concaténation).