Ceci est la troisième partie d'une série sur les solutions au défi du générateur de séries de nombres. Dans la partie 1, j'ai couvert les solutions qui génèrent les lignes à la volée. Dans la partie 2, j'ai couvert les solutions qui interrogent une table de base physique que vous préremplissez avec des lignes. Ce mois-ci, je vais me concentrer sur une technique fascinante qui peut être utilisée pour relever notre défi, mais qui a aussi des applications intéressantes bien au-delà. Je ne connais pas de nom officiel pour la technique, mais son concept est quelque peu similaire à l'élimination de partition horizontale, donc je l'appellerai de manière informelle l'élimination d'unité horizontale technique. La technique peut avoir des avantages de performance positifs intéressants, mais il y a aussi des mises en garde dont vous devez être conscient, où, dans certaines conditions, elle peut entraîner une pénalité de performance.
Merci encore à Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea et Paul White pour avoir partagé vos idées et commentaires.
Je vais faire mes tests dans tempdb, en activant les statistiques de temps :
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Idées antérieures
La technique d'élimination d'unité horizontale peut être utilisée comme alternative à la logique d'élimination de colonne, ou élimination d'unité verticale technique, sur laquelle je me suis appuyé dans plusieurs des solutions que j'ai abordées plus tôt. Vous pouvez en savoir plus sur les principes fondamentaux de la logique d'élimination des colonnes avec des expressions de table dans Principes fondamentaux des expressions de table, Partie 3 - Tables dérivées, considérations d'optimisation sous "Projection de colonne et un mot sur SELECT *."
L'idée de base de la technique d'élimination d'unité verticale est que si vous avez une expression de table imbriquée qui renvoie les colonnes x et y, et que votre requête externe ne référence que la colonne x, le processus de compilation de la requête élimine y de l'arborescence de requête initiale, et donc le plan n'a pas besoin de l'évaluer. Cela a plusieurs implications positives liées à l'optimisation, telles que l'obtention d'une couverture d'index avec x seul, et si y est le résultat d'un calcul, il n'est pas du tout nécessaire d'évaluer l'expression sous-jacente de y. Cette idée était au cœur de la solution d'Alan Burstein. Je me suis également appuyé dessus dans plusieurs des autres solutions que j'ai couvertes, comme avec la fonction dbo.GetNumsAlanCharlieItzikBatch (de la partie 1), les fonctions dbo.GetNumsJohn2DaveObbishAlanCharlieItzik et dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 (de la partie 2), et d'autres. Par exemple, j'utiliserai dbo.GetNumsAlanCharlieItzikBatch comme solution de base avec la logique d'élimination verticale.
Pour rappel, cette solution utilise une jointure avec une table factice qui a un index columnstore pour obtenir un traitement par lots. Voici le code pour créer la table factice :
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Et voici le code avec la définition de la fonction dbo.GetNumsAlanCharlieItzikBatch :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO J'ai utilisé le code suivant pour tester les performances de la fonction avec 100M de lignes, renvoyant la colonne de résultat calculée n (manipulation du résultat de la fonction ROW_NUMBER), ordonnée par n :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Voici les statistiques de temps que j'ai obtenues pour ce test :
Temps CPU =9328 ms, temps écoulé =9330 ms.J'ai utilisé le code suivant pour tester les performances de la fonction avec 100 millions de lignes, renvoyant la colonne rn (directe, non manipulée, résultat de la fonction ROW_NUMBER), ordonnée par rn :
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Voici les statistiques de temps que j'ai obtenues pour ce test :
Temps CPU =7296 ms, temps écoulé =7291 ms.Passons en revue les idées importantes intégrées à cette solution.
S'appuyant sur la logique d'élimination des colonnes, alan a eu l'idée de renvoyer non pas une seule colonne avec la série de nombres, mais trois :
- Colonne rn représente un résultat non manipulé de la fonction ROW_NUMBER, qui commence par 1. Il est bon marché à calculer. Il s'agit de préserver l'ordre à la fois lorsque vous fournissez des constantes et lorsque vous fournissez des non-constantes (variables, colonnes) comme entrées de la fonction. Cela signifie que lorsque votre requête externe utilise ORDER BY rn, vous n'obtenez pas d'opérateur de tri dans le plan.
- Colonne n représente un calcul basé sur @low, une constante et rownum (résultat de la fonction ROW_NUMBER). C'est la préservation de l'ordre par rapport à rownum lorsque vous fournissez des constantes comme entrées à la fonction. C'est grâce à la perspicacité de Charlie concernant le pliage constant (voir la partie 1 pour plus de détails). Cependant, il ne s'agit pas de préserver l'ordre lorsque vous fournissez des nonconstantes comme entrées, car vous n'obtenez pas de pliage constant. Je le démontrerai plus tard dans la section sur les mises en garde.
- Colonne op représente n dans l'ordre inverse. C'est le résultat d'un calcul et il ne préserve pas l'ordre.
En vous appuyant sur la logique d'élimination des colonnes, si vous devez renvoyer une série de nombres commençant par 1, vous interrogez la colonne rn, ce qui est moins cher que d'interroger n. Si vous avez besoin d'une série de nombres commençant par une valeur autre que 1, vous interrogez n et payez le coût supplémentaire. Si vous avez besoin du résultat trié par la colonne numérique, avec des constantes comme entrées, vous pouvez utiliser ORDER BY rn ou ORDER BY n. Mais avec des non constantes comme entrées, vous voulez vous assurer d'utiliser ORDER BY rn. Ce serait peut-être une bonne idée de toujours s'en tenir à l'utilisation de ORDER BY rn lorsque vous avez besoin que le résultat ordonné soit du bon côté.
L'idée d'élimination d'unité horizontale est similaire à l'idée d'élimination d'unité verticale, sauf qu'elle s'applique à des ensembles de lignes au lieu d'ensembles de colonnes. En fait, Joe Obbish s'est appuyé sur cette idée dans sa fonction dbo.GetNumsObbish (de la partie 2), et nous allons aller plus loin. Dans sa solution, Joe a unifié plusieurs requêtes représentant des sous-gammes disjointes de nombres, en utilisant un filtre dans la clause WHERE de chaque requête pour définir l'applicabilité de la sous-gamme. Lorsque vous appelez la fonction et transmettez des entrées constantes représentant les délimiteurs de la plage souhaitée, SQL Server élimine les requêtes inapplicables au moment de la compilation, de sorte que le plan ne les reflète même pas.
Élimination horizontale des unités, temps de compilation versus temps d'exécution
Ce serait peut-être une bonne idée de commencer par démontrer le concept d'élimination horizontale d'unités dans un cas plus général, et de discuter également d'une distinction importante entre l'élimination à la compilation et à l'exécution. Ensuite, nous pourrons discuter de la façon d'appliquer l'idée à notre défi de séries de nombres.
J'utiliserai trois tables appelées dbo.T1, dbo.T2 et dbo.T3 dans mon exemple. Utilisez le code DDL et DML suivant pour créer et remplir ces tables :
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Supposons que vous souhaitiez implémenter un TVF en ligne appelé dbo.OneTable qui accepte l'un des trois noms de table ci-dessus en entrée et renvoie les données de la table demandée. Sur la base du concept d'élimination d'unités horizontales, vous pouvez implémenter la fonction comme suit :
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
N'oubliez pas qu'un TVF en ligne applique l'incorporation de paramètres. Cela signifie que lorsque vous passez une constante telle que N'dbo.T2' en entrée, le processus d'inlining remplace toutes les références à @WhichTable par la constante avant l'optimisation . Le processus d'élimination peut ensuite supprimer les références à T1 et T3 de l'arborescence de requête initiale, et ainsi interroger les résultats d'optimisation dans un plan qui référence uniquement T2. Testons cette idée avec la requête suivante :
SELECT * FROM dbo.OneTable(N'dbo.T2');
Le plan de cette requête est illustré à la figure 1.
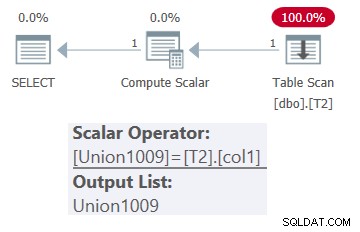 Figure 1 :Plan pour dbo.OneTable avec entrée constante
Figure 1 :Plan pour dbo.OneTable avec entrée constante
Comme vous pouvez le constater, seule la table T2 apparaît dans le plan.
Les choses sont un peu plus délicates lorsque vous passez une valeur non constante en entrée. Cela peut être le cas lors de l'utilisation d'une variable, d'un paramètre de procédure ou du passage d'une colonne via APPLY. La valeur d'entrée est soit inconnue au moment de la compilation, soit le potentiel de réutilisation du plan paramétré doit être pris en compte.
L'optimiseur ne peut éliminer aucune des tables du plan, mais il a encore une astuce. Il peut utiliser des opérateurs de filtre de démarrage au-dessus des sous-arborescences qui accèdent aux tables et exécuter uniquement la sous-arborescence pertinente en fonction de la valeur d'exécution de @WhichTable. Utilisez le code suivant pour tester cette stratégie :
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Le plan de cette exécution est illustré à la figure 2 :
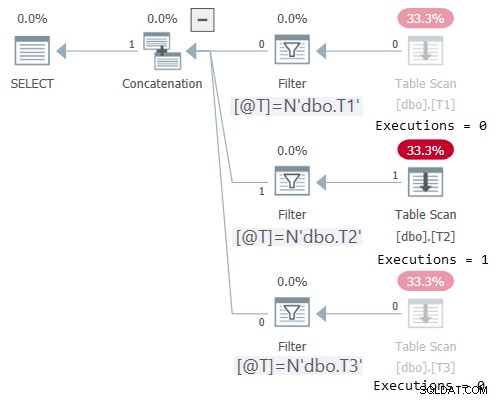 Figure 2 :Plan pour dbo.OneTable avec une entrée non constante
Figure 2 :Plan pour dbo.OneTable avec une entrée non constante
Plan Explorer rend merveilleusement évident le fait que seule la sous-arborescence applicable a été exécutée (Exécutions =1) et grise les sous-arborescences qui n'ont pas été exécutées (Exécutions =0). De plus, STATISTICS IO affiche les informations d'E/S uniquement pour la table à laquelle vous avez accédé :
Tableau 'T2'. Nombre de balayages 1, lectures logiques 1, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lectures logiques lob 0, lectures physiques lob 0, lectures du serveur de pages lob 0, lectures lob- l'avance lit 0, la lecture anticipée du serveur de pages lob lit 0.Appliquer la logique d'élimination des unités horizontales au défi des séries de nombres
Comme mentionné, vous pouvez appliquer le concept d'élimination d'unité horizontale en modifiant l'une des solutions précédentes qui utilisent actuellement la logique d'élimination verticale. Je vais utiliser la fonction dbo.GetNumsAlanCharlieItzikBatch comme point de départ pour mon exemple.
Rappelez-vous que Joe Obbish a utilisé l'élimination horizontale des unités pour extraire les sous-gammes disjointes pertinentes de la série de nombres. Nous utiliserons le concept pour séparer horizontalement le calcul le moins cher (rn) où @low =1 du calcul le plus cher (n) où @low <> 1.
Pendant que nous y sommes, nous pouvons expérimenter en ajoutant l'idée de Jeff Moden dans sa fonction fnTally, où il utilise une ligne sentinelle avec la valeur 0 pour les cas où la plage commence par @low =0.
Nous avons donc quatre unités horizontales :
- Ligne sentinelle avec 0 où @low =0, avec n =0
- TOP (@high) lignes où @low =0, avec cheap n =rownum, et op =@high – rownum
- TOP (@high) lignes où @low =1, avec cheap n =rownum, et op =@high + 1 – rownum
- TOP(@high – @low + 1) lignes où @low <> 0 AND @low <> 1, avec n plus cher =@low – 1 + rownum, et op =@high + 1 – rownum
Cette solution combine des idées d'Alan, Charlie, Joe, Jeff et moi-même, nous appellerons donc la version en mode batch de la fonction dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Tout d'abord, n'oubliez pas de vous assurer que la table factice dbo.BatchMe est toujours présente pour obtenir le traitement par lots dans notre solution, ou utilisez le code suivant si vous ne l'avez pas :
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Voici le code avec la définition de la fonction dbo.GetNumsAlanCharlieJoeJeffItzikBatch :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Important :Le concept d'élimination horizontale d'unités est sans doute plus complexe à mettre en œuvre que le concept vertical, alors pourquoi s'embêter ? Parce que cela enlève la responsabilité de choisir la bonne colonne à l'utilisateur. L'utilisateur n'a qu'à se soucier d'interroger une colonne appelée n, au lieu de se rappeler d'utiliser rn lorsque la plage commence par 1, et n sinon.
Commençons par tester la solution avec les entrées constantes 1 et 100 000 000, en demandant le résultat à ordonner :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 3.
 Figure 3 :Plan pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Figure 3 :Plan pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Observez que la seule colonne renvoyée est basée sur l'expression directe, non manipulée, ROW_NUMBER (Expr1313). Notez également qu'il n'y a pas besoin de tri dans le plan.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =7359 ms, temps écoulé =7354 ms.L'exécution reflète de manière adéquate le fait que le plan utilise le mode batch, l'expression ROW_NUMBER non manipulée et aucun tri.
Ensuite, testez la fonction avec la plage constante de 0 à 99 999 999 :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 4.
 Figure 4 :Planifier pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Figure 4 :Planifier pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Le plan utilise un opérateur Merge Join (Concaténation) pour fusionner la ligne sentinelle avec la valeur 0 et le reste. Même si la deuxième partie est aussi efficace qu'auparavant, la logique de fusion prend un lourd tribut d'environ 26 % sur le temps d'exécution, ce qui se traduit par les statistiques de temps suivantes :
Temps CPU =9265 ms, temps écoulé =9298 ms.Testons la fonction avec la plage constante de 2 à 100 000 001 :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 5.
 Figure 5 :Plan pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Figure 5 :Plan pour dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Cette fois, il n'y a pas de logique de fusion coûteuse puisque la partie ligne sentinelle n'est pas pertinente. Cependant, observez que la colonne renvoyée est l'expression manipulée @low – 1 + rownum, qui après l'incorporation/inlining des paramètres et le pliage constant est devenue 1 + rownum.
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =9000 ms, temps écoulé =9015 ms.Comme prévu, ce n'est pas aussi rapide qu'avec une plage qui commence par 1, mais curieusement, plus rapide qu'avec une plage qui commence par 0.
Suppression de la ligne sentinelle 0
Étant donné que la technique avec la ligne sentinelle avec la valeur 0 semble être plus lente que l'application de la manipulation à rownum, il est logique de l'éviter simplement. Cela nous amène à une solution simplifiée basée sur l'élimination horizontale qui mélange les idées d'Alan, Charlie, Joe et moi-même. J'appellerai la fonction avec cette solution dbo.GetNumsAlanCharlieJoeItzikBatch. Voici la définition de la fonction :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Testons-le avec la plage de 1 à 100 M :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Le plan est le même que celui présenté précédemment dans la figure 3, comme prévu.
En conséquence, j'ai obtenu les statistiques de temps suivantes :
Temps CPU =7219 ms, temps écoulé =7243 ms.Testez-le avec la plage de 0 à 99 999 999 :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Cette fois, vous obtenez le même plan que celui illustré précédemment à la figure 5, et non à la figure 4.
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =9313 ms, temps écoulé =9334 ms.Testez-le avec la plage de 2 à 100 000 001 :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Encore une fois, vous obtenez le même plan que celui présenté précédemment dans la figure 5.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =9125 ms, temps écoulé =9148 ms.Mises en garde lors de l'utilisation d'entrées non constantes
Avec les techniques d'élimination d'unité verticale et horizontale, les choses fonctionnent idéalement tant que vous transmettez des constantes comme entrées. Cependant, vous devez être conscient des mises en garde qui peuvent entraîner des baisses de performances lorsque vous transmettez des entrées non constantes. La technique d'élimination des unités verticales pose moins de problèmes, et les problèmes qui existent sont plus faciles à gérer, alors commençons par cela.
N'oubliez pas que dans cet article, nous avons utilisé la fonction dbo.GetNumsAlanCharlieItzikBatch comme exemple qui repose sur le concept d'élimination d'unité verticale. Exécutons une série de tests avec des entrées non constantes, telles que des variables.
Comme premier test, nous renverrons rn et demanderons les données ordonnées par rn :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
N'oubliez pas que rn représente l'expression ROW_NUMBER non manipulée, donc le fait que nous utilisions des entrées non constantes n'a pas de signification particulière dans ce cas. Il n'est pas nécessaire de faire un tri explicite dans le plan.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =7390 ms, temps écoulé =7386 ms.Ces chiffres représentent le cas idéal.
Dans le test suivant, triez les lignes de résultats par n :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 6.
 Figure 6 :Planifier le classement dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) par n
Figure 6 :Planifier le classement dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) par n
Vous voyez le problème ? Après l'inlining, @low a été remplacé par @mylow, et non par la valeur de @mylow, qui est 1. Par conséquent, le pliage constant n'a pas eu lieu, et donc n n'est pas préservant l'ordre par rapport à rownum. Cela a entraîné un tri explicite dans le plan.
Voici les statistiques de temps que j'ai obtenues pour cette exécution :
Temps CPU =25141 ms, temps écoulé =25628 ms.Le temps d'exécution a presque triplé par rapport à l'époque où le tri explicite n'était pas nécessaire.
Une solution de contournement simple consiste à utiliser l'idée originale d'Alan Burstein de toujours ordonner par rn lorsque vous avez besoin que le résultat soit ordonné, à la fois lors du retour de rn et lors du retour de n, comme ceci :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Cette fois, il n'y a pas de tri explicite dans le plan.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =9156 ms, temps écoulé =9184 ms.Les nombres reflètent de manière adéquate le fait que vous renvoyez l'expression manipulée, mais n'impliquez aucun tri explicite.
Avec des solutions basées sur la technique d'élimination des unités horizontales, comme notre fonction dbo.GetNumsAlanCharlieJoeItzikBatch, la situation est plus compliquée lors de l'utilisation d'entrées non constantes.
Testons d'abord la fonction avec une très petite plage de 10 nombres :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 7.
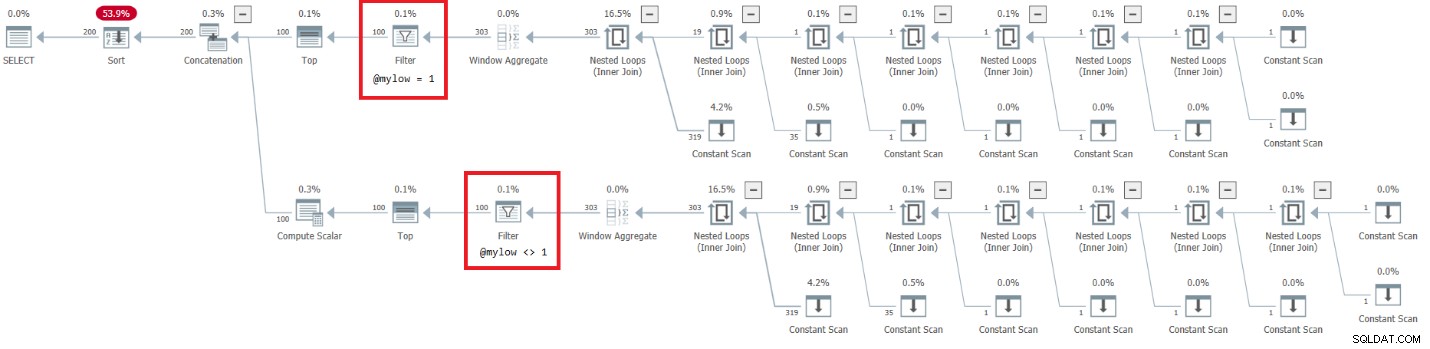 Figure 7 :Plan pour dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figure 7 :Plan pour dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Il y a un côté très alarmant à ce plan. Observez que les opérateurs de filtrage apparaissent ci-dessous les meilleurs opérateurs ! Dans tout appel donné à la fonction avec des entrées non constantes, naturellement l'une des branches sous l'opérateur de concaténation aura toujours une condition de filtre fausse. Cependant, les deux opérateurs Top demandent un nombre de lignes différent de zéro. Ainsi, l'opérateur Top au-dessus de l'opérateur avec la condition de filtre fausse demandera des lignes et ne sera jamais satisfait puisque l'opérateur de filtre continuera à supprimer toutes les lignes qu'il obtiendra de son nœud enfant. Le travail dans la sous-arborescence sous l'opérateur Filtre devra s'exécuter jusqu'à la fin. Dans notre cas, cela signifie que le sous-arbre passera par le travail de génération de lignes 4B, que l'opérateur de filtre éliminera. Vous vous demandez pourquoi l'opérateur de filtre prend la peine de demander des lignes à son nœud enfant, mais il semblerait que c'est ainsi que cela fonctionne actuellement. Il est difficile de voir cela avec un plan statique. Il est plus facile de voir cela en direct, par exemple, avec l'option d'exécution de requête en direct dans SentryOne Plan Explorer, comme illustré à la figure 8. Essayez-le.
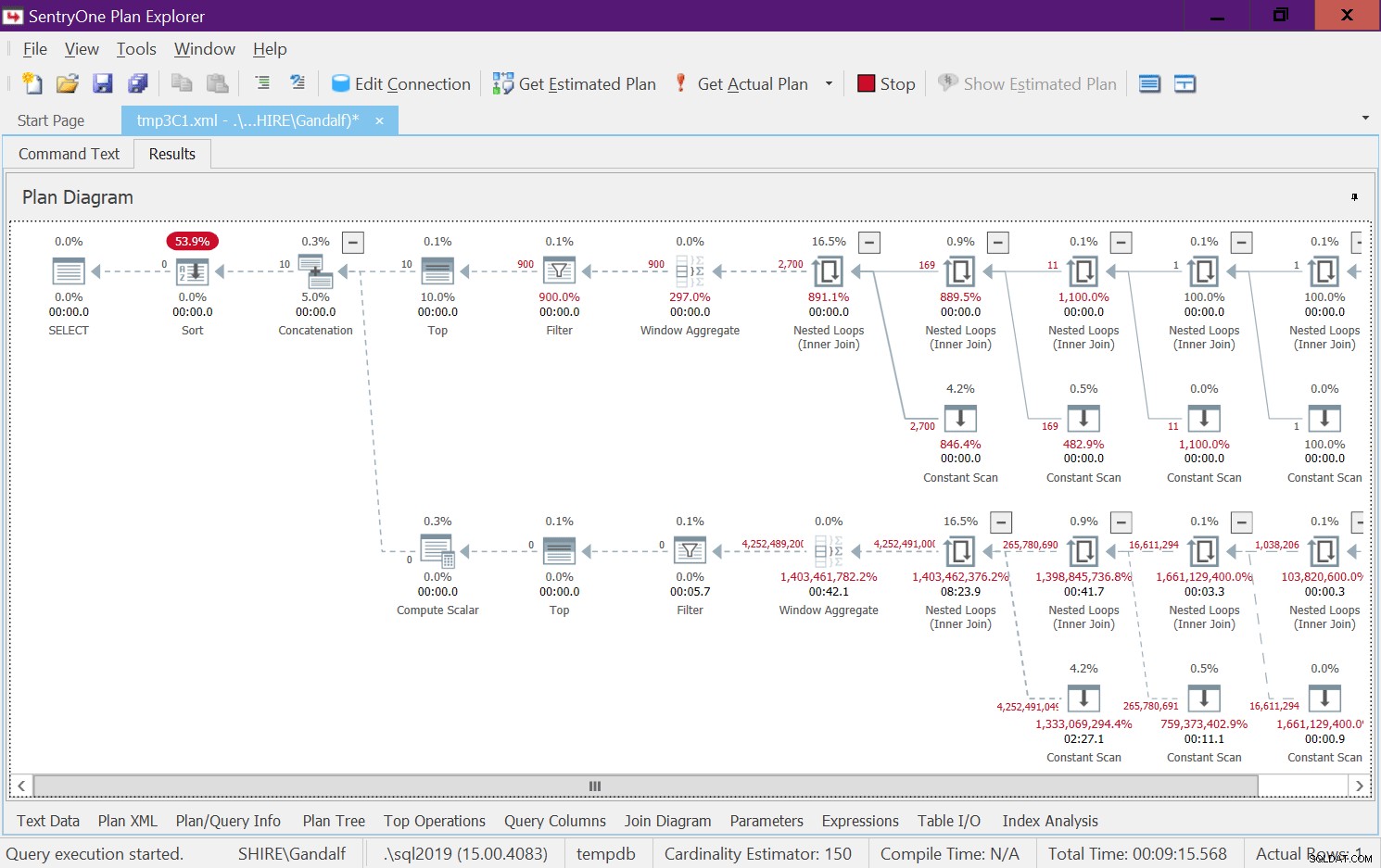 Figure 8 :Statistiques de requête en direct pour dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figure 8 :Statistiques de requête en direct pour dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Il a fallu 9 minutes 15 pour terminer ce test sur ma machine, et rappelez-vous que la demande consistait à renvoyer une plage de 10 nombres.
Réfléchissons s'il existe un moyen d'éviter d'activer le sous-arbre non pertinent dans son intégralité. Pour ce faire, vous voudriez que les opérateurs de filtre de démarrage apparaissent au-dessus les opérateurs supérieurs au lieu d'en dessous d'eux. Si vous avez lu Principes fondamentaux des expressions de table, Partie 4 - Tables dérivées, considérations d'optimisation, suite, vous savez qu'un filtre TOP empêche la désimbrication des expressions de table. Ainsi, tout ce que vous avez à faire est de placer la requête TOP dans une table dérivée et d'appliquer le filtre dans une requête externe sur la table dérivée.
Voici notre fonction modifiée implémentant cette astuce :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Comme prévu, les exécutions avec des constantes continuent de se comporter et de fonctionner de la même manière que sans l'astuce.
Quant aux entrées non constantes, maintenant avec de petites plages, c'est très rapide. Voici un test avec une plage de 10 chiffres :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Le plan de cette exécution est illustré à la figure 9.
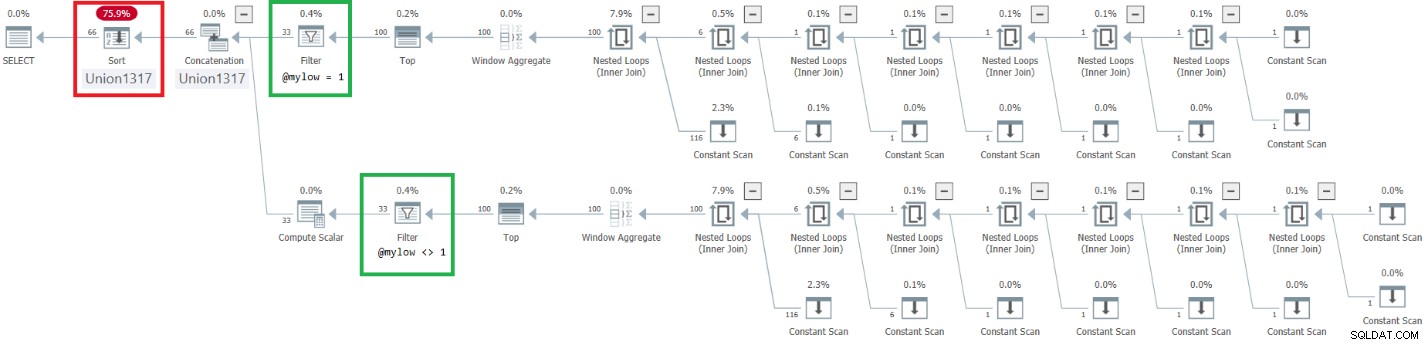 Figure 9 :Plan d'amélioration de dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figure 9 :Plan d'amélioration de dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Observez que l'effet souhaité consistant à placer les opérateurs Filtre au-dessus des opérateurs Top a été atteint. Cependant, la colonne de classement n est traitée comme le résultat d'une manipulation et n'est donc pas considérée comme une colonne de préservation de l'ordre par rapport à rownum. Par conséquent, il y a un tri explicite dans le plan.
Testez la fonction avec une large plage de nombres de 100 millions :
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
J'ai obtenu les statistiques de temps suivantes :
Temps CPU =29907 ms, temps écoulé =29909 ms.Quelle déception ; c'était presque parfait !
Résumé et informations sur les performances
La figure 10 présente un résumé des statistiques de temps pour les différentes solutions.
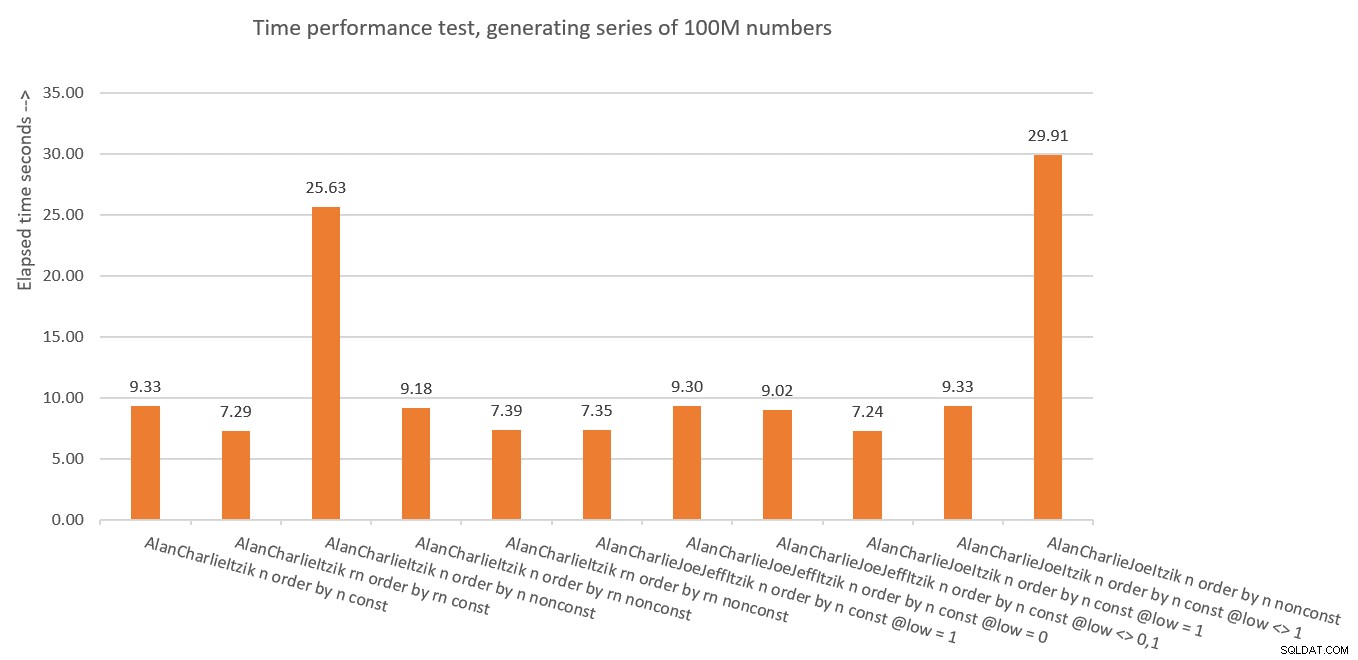 Figure 10 :Résumé des performances temporelles des solutions
Figure 10 :Résumé des performances temporelles des solutions
Alors qu'avons-nous appris de tout cela ? Je suppose qu'il ne faut plus recommencer ! Je rigole. Nous avons appris qu'il est plus sûr d'utiliser le concept d'élimination verticale comme dans dbo.GetNumsAlanCharlieItzikBatch, qui expose à la fois le résultat ROW_NUMBER non manipulé (rn) et celui manipulé (n). Assurez-vous simplement que lorsque vous devez renvoyer le résultat commandé, triez toujours par rn, que vous renvoyiez rn ou n.
Si vous êtes absolument certain que votre solution sera toujours utilisée avec des constantes comme entrées, vous pouvez utiliser le concept d'élimination d'unité horizontale. Cela se traduira par une solution plus intuitive pour l'utilisateur, car il interagira avec une colonne pour les valeurs croissantes. Je suggérerais toujours d'utiliser l'astuce avec les tables dérivées pour empêcher la désimbrication et placer les opérateurs de filtre au-dessus des opérateurs supérieurs si la fonction est utilisée avec des entrées non constantes, juste pour être sûr.
Nous n'avons pas encore fini. Le mois prochain, je continuerai à explorer d'autres solutions.