De temps en temps, vous remarquerez peut-être qu'une ou plusieurs jointures dans un plan d'exécution sont annotées avec un StarJoinInfo structure. Le schéma officiel de showplan a ce qui suit à dire sur cet élément de plan (cliquez pour agrandir) :
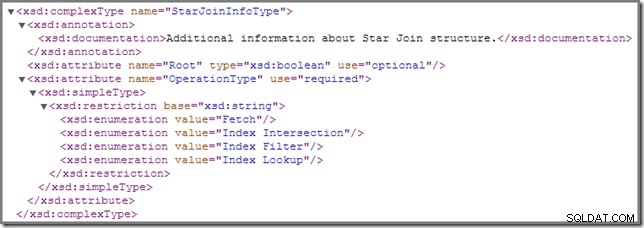
La documentation en ligne qui y est affichée ("informations supplémentaires sur la structure Star Join ") n'est pas très instructif, même si les autres détails sont assez intrigants - nous les examinerons en détail.
Si vous consultez votre moteur de recherche préféré pour plus d'informations en utilisant des termes tels que "Optimisation de jointure en étoile SQL Server", vous verrez probablement des résultats décrivant des filtres bitmap optimisés. Il s'agit d'une fonctionnalité distincte réservée aux entreprises introduite dans SQL Server 2008 et non liée à StarJoinInfo structurer du tout.
Optimisations pour les requêtes d'étoiles sélectives
La présence de StarJoinInfo indique que SQL Server a appliqué l'une des optimisations ciblées sur les requêtes de schéma en étoile sélectives. Ces optimisations sont disponibles à partir de SQL Server 2005, dans toutes les éditions (pas seulement Enterprise). Notez que sélectif ici fait référence au nombre de lignes extraites de la table de faits. La combinaison de prédicats dimensionnels dans une requête peut toujours être sélective même lorsque ses prédicats individuels qualifient un grand nombre de lignes.
Intersection d'index ordinaire
L'optimiseur de requête peut envisager de combiner plusieurs index non clusterisés lorsqu'il n'existe pas d'index unique approprié, comme le montre la requête AdventureWorks suivante :
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
L'optimiseur détermine que la combinaison de deux index non clusterisés (un sur SalesPersonID et l'autre sur CustomerID ) est le moyen le moins cher de satisfaire cette requête (il n'y a pas d'index sur les deux colonnes) :
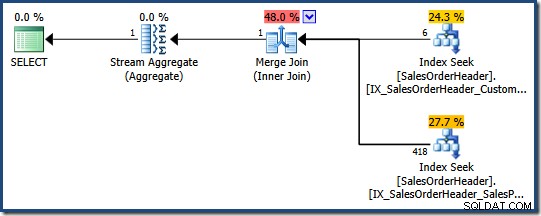
Chaque recherche d'index renvoie la clé d'index clusterisé pour les lignes qui passent le prédicat. La jointure correspond aux clés renvoyées pour garantir que seules les lignes qui correspondent les deux les prédicats sont transmis.
Si la table était un tas, chaque recherche renverrait des identificateurs de ligne de tas (RID) au lieu de clés d'index groupées, mais la stratégie globale est la même :recherchez des identificateurs de ligne pour chaque prédicat, puis faites-les correspondre.
Intersection manuelle de l'index de jointure en étoile
La même idée peut être étendue aux requêtes qui sélectionnent des lignes dans une table de faits à l'aide de prédicats appliqués aux tables de dimension. Pour voir comment cela fonctionne, considérez la requête suivante (à l'aide de l'exemple de base de données Contoso BI) pour trouver le montant total des ventes de lecteurs MP3 vendus dans les magasins Contoso comptant exactement 50 employés :
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; À des fins de comparaison avec les efforts ultérieurs, cette requête (très sélective) produit un plan de requête comme le suivant (cliquez pour développer) :
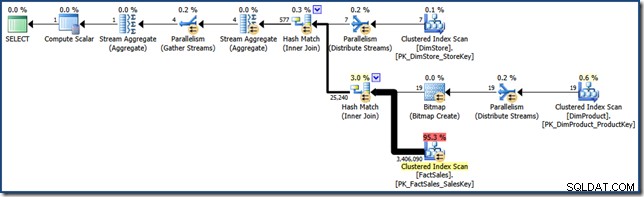
Ce plan d'exécution a un coût estimé à un peu plus de 15,6 unités . Il propose une exécution parallèle avec une analyse complète de la table de faits (bien qu'avec un filtre bitmap appliqué).
Les tables de faits de cet exemple de base de données n'incluent pas d'index non clusterisés sur les clés étrangères de la table de faits par défaut, nous devons donc en ajouter quelques-unes :
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Avec ces index en place, nous pouvons commencer à voir comment l'intersection d'index peut être utilisée pour améliorer l'efficacité. La première étape consiste à rechercher des identifiants de ligne de table de faits pour chaque prédicat distinct. Les requêtes suivantes appliquent un prédicat de dimension unique, puis rejoignent la table de faits pour rechercher des identifiants de ligne (clés d'index groupées de la table de faits) :
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Les plans de requête affichent une analyse de la petite table de dimension, suivie de recherches à l'aide de l'index non clusterisé de la table de faits pour trouver les identifiants de ligne (rappelez-vous que les index non clusterisés incluent toujours la clé de clustering de la table de base ou le RID de tas) :
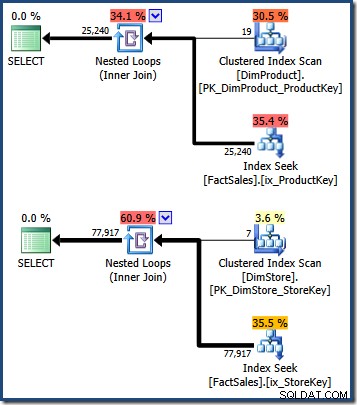
L'intersection de ces deux ensembles de clés d'index clusterisées de table de faits identifie les lignes qui doivent être renvoyées par la requête d'origine. Une fois que nous avons ces identifiants de lignes, il nous suffit de rechercher le montant des ventes dans chaque ligne de la table de faits et de calculer la somme.
Requête manuelle d'intersection d'index
Rassembler tout cela dans une requête donne ceci :
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
Le FORCESEEK indice est là pour s'assurer que nous obtenons des recherches de points dans la table de faits. Sans cela, l'optimiseur choisit d'analyser la table de faits, ce qui est exactement ce que nous cherchons à éviter. Le MAXDOP 1 l'indice aide simplement à garder le plan final à une taille assez raisonnable à des fins d'affichage (cliquez pour le voir en taille réelle) :
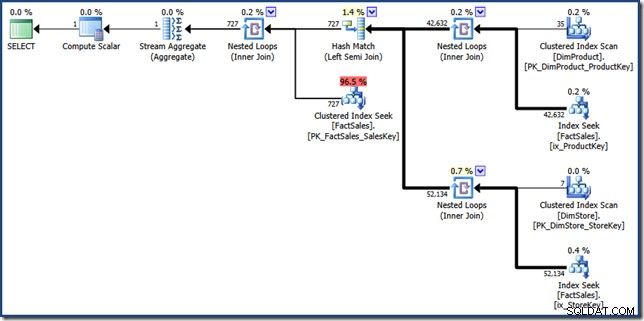
Les éléments constitutifs du plan d'intersection de l'index manuel sont assez faciles à identifier. Les deux recherches d'index non clusterisées de table de faits sur le côté droit produisent les deux ensembles d'identificateurs de ligne de table de faits. La jointure par hachage trouve l'intersection de ces deux ensembles. La recherche d'index clusterisé dans la table de faits trouve les montants des ventes pour ces identificateurs de ligne. Enfin, le Stream Aggregate calcule le montant total.
Ce plan de requête effectue relativement peu de recherches dans les index clusterisés et non clusterisés de la table de faits. Si la requête est suffisamment sélective, cela pourrait bien être une stratégie d'exécution moins coûteuse que l'analyse complète de la table de faits. L'exemple de base de données Contoso BI est relativement petit, avec seulement 3,4 millions de lignes dans la table de faits des ventes. Pour les tables de faits plus volumineuses, la différence entre une analyse complète et quelques centaines de recherches peut être très importante. Malheureusement, la réécriture manuelle introduit de graves erreurs de cardinalité, ce qui donne un plan dont le coût est estimé à 46,5 unités .
Intersection automatique Star Join Index avec recherches
Heureusement, nous n'avons pas à décider si la requête que nous écrivons est suffisamment sélective pour justifier cette réécriture manuelle. Les optimisations de jointure en étoile pour les requêtes sélectives signifient que l'optimiseur de requête peut explorer cette option pour nous, en utilisant la syntaxe de requête d'origine plus conviviale :
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; L'optimiseur produit le plan d'exécution suivant avec un coût estimé de 1,64 unités (cliquez pour agrandir) :
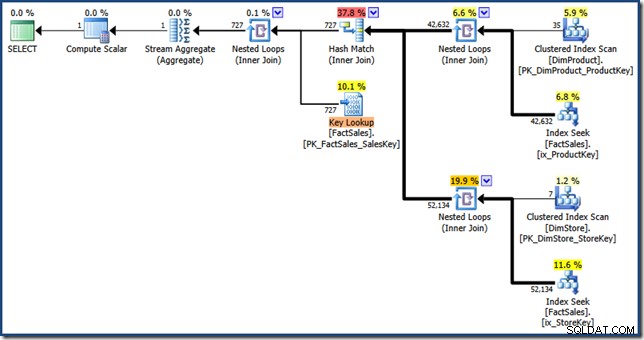
Les différences entre ce plan et la version manuelle sont les suivantes :l'intersection de l'index est une jointure interne au lieu d'une semi-jointure ; et la recherche d'index clusterisé est affichée comme une recherche de clé au lieu d'une recherche d'index clusterisé. Au risque d'insister, si la table de faits était un tas, la recherche de clé serait une recherche RID.
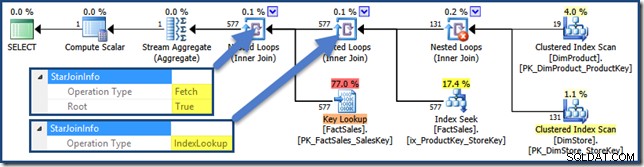
Les propriétés StarJoinInfo
Les jointures de ce plan ont toutes un StarJoinInfo structure. Pour le voir, cliquez sur un itérateur de jointure et regardez dans la fenêtre SSMS Properties. Cliquez sur la flèche à gauche de StarJoinInfo élément pour développer le nœud.
Les jointures de table de faits non clusterisées à droite du plan sont des recherches d'index créées par l'optimiseur :
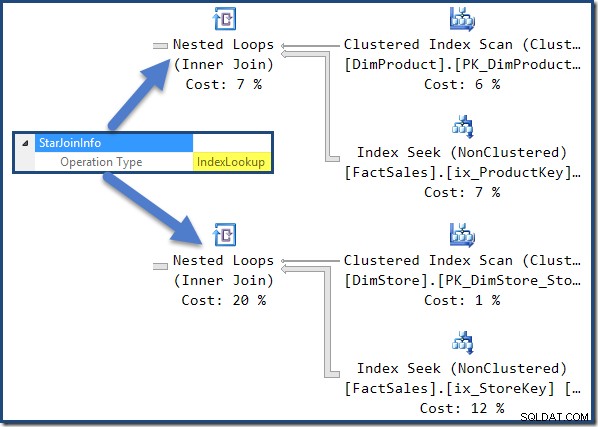
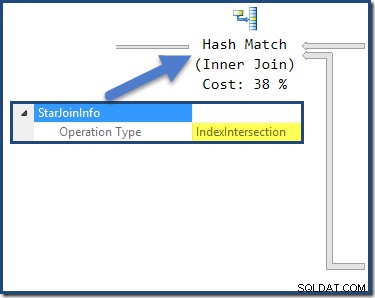
La jointure de hachage a un StarJoinInfo structure montrant qu'elle effectue une intersection d'index (encore une fois, fabriquée par l'optimiseur) :
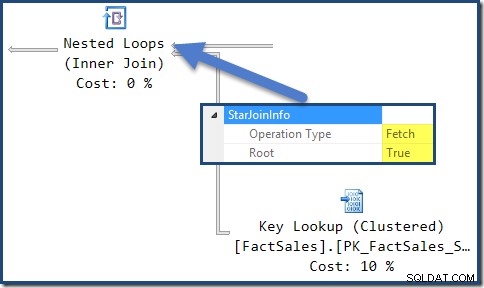
Le StarJoinInfo pour la jointure de boucles imbriquées la plus à gauche indique qu'elle a été générée pour extraire les lignes de la table de faits par identifiant de ligne. Il se trouve à la racine de la sous-arborescence de jointure en étoile générée par l'optimiseur :
Produits cartésiens et recherche d'index multi-colonnes
Les plans d'intersection d'index pris en compte dans le cadre des optimisations de jointure en étoile sont utiles pour les requêtes sélectives de table de faits où des index non clusterisés à colonne unique existent sur des clés étrangères de table de faits (une pratique de conception courante).
Il est parfois aussi judicieux de créer des index multi-colonnes sur les clés étrangères des tables de faits, pour les combinaisons fréquemment interrogées. Les optimisations de requête en étoile sélectives intégrées contiennent également une réécriture pour ce scénario. Pour voir comment cela fonctionne, ajoutez l'index multi-colonnes suivant à la table de faits :
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Compilez à nouveau la requête de test :
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Le plan de requête ne comporte plus d'intersection d'index (cliquez pour agrandir) :
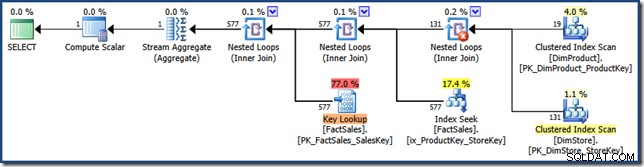
La stratégie choisie ici est d'appliquer chaque prédicat aux tables de dimension, de prendre le produit cartésien des résultats et de l'utiliser pour rechercher dans les deux clés de l'index multi-colonnes. Le plan de requête effectue ensuite une recherche de clé dans la table de faits en utilisant des identifiants de ligne exactement comme vu précédemment.
Le plan de requête est particulièrement intéressant car il combine trois fonctionnalités souvent considérées comme de mauvaises choses (analyses complètes, produits cartésiens et recherches de clés) dans une optimisation des performances. . Il s'agit d'une stratégie valable lorsque le produit des deux dimensions devrait être très petit.
Il n'y a pas de StarJoinInfo pour le produit cartésien, mais les autres jointures contiennent des informations (cliquez pour agrandir) :
Filtre d'index
En se référant au schéma showplan, il y a un autre StarJoinInfo opération que nous devons couvrir :
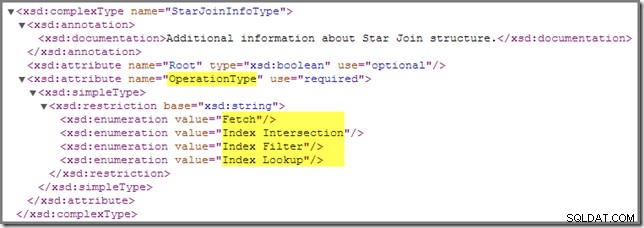
Le Index Filter La valeur est vue avec des jointures qui sont considérées comme suffisamment sélectives pour valoir la peine d'être exécutées avant l'extraction de la table de faits. Les jointures qui ne sont pas assez sélectives seront effectuées après la récupération et n'auront pas de StarJoinInfo structure.
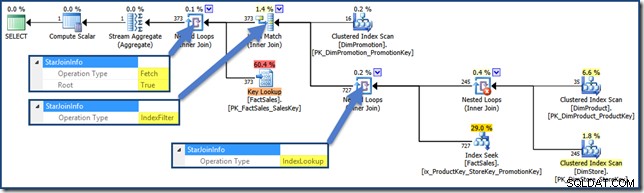
Pour voir un filtre d'index utilisant notre requête de test, nous devons ajouter une troisième table de jointure au mélange, supprimer les index de table de faits non cluster créés jusqu'à présent et en ajouter un nouveau :
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Le plan de requête est maintenant (cliquez pour agrandir) :
Un plan de requête d'intersection d'index de tas
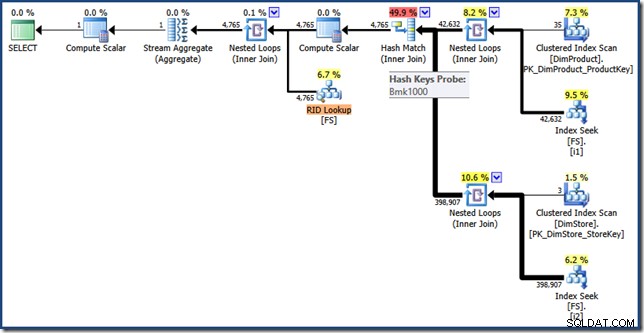
Pour être complet, voici un script pour créer une copie de tas de la table de faits avec les deux index non clusterisés nécessaires pour activer la réécriture de l'optimiseur d'intersection d'index :
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Le plan d'exécution de cette requête a les mêmes fonctionnalités qu'auparavant, mais l'intersection d'index est effectuée à l'aide de RID au lieu de clés d'index groupées de tables de faits, et la récupération finale est une recherche RID (cliquez pour développer) :
Réflexions finales
Les réécritures de l'optimiseur présentées ici ciblent les requêtes qui renvoient un nombre relativement faible de lignes d'un grand table de faits. Ces réécritures sont disponibles dans toutes les éditions de SQL Server depuis 2005.
Bien qu'elles soient destinées à accélérer les requêtes de schéma en étoile (et en flocon) sélectives dans l'entreposage de données, l'optimiseur peut appliquer ces techniques chaque fois qu'il détecte un ensemble approprié de tables et de jointures. Les heuristiques utilisées pour détecter les requêtes en étoile sont assez larges, vous pouvez donc rencontrer des formes de plan avec StarJoinInfo structures dans à peu près n'importe quel type de base de données. Tout tableau d'une taille raisonnable (disons 100 pages ou plus) avec des références à des tableaux plus petits (de type dimension) est un candidat potentiel pour ces optimisations (notez que les clés étrangères explicites ne sont pas obligatoire).
Pour ceux d'entre vous qui aiment ce genre de choses, la règle d'optimisation responsable de la génération de modèles de jointure en étoile sélectifs à partir d'une jointure logique à n tables s'appelle StarJoinToIdxStrategy (stratégie de jointure étoile à index).