Cet article explore certaines fonctionnalités et limitations moins connues de l'optimiseur de requêtes et explique les raisons des performances extrêmement médiocres des jointures de hachage dans un cas spécifique.
Exemple de données
L'exemple de script de création de données qui suit s'appuie sur une table de nombres existante. Si vous n'en avez pas déjà un, le script ci-dessous peut être utilisé pour en créer un efficacement. Le tableau résultant contiendra une seule colonne d'entiers avec des nombres de un à un million :
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
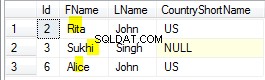
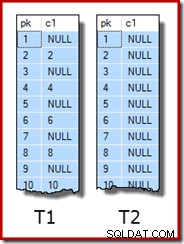
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Les données d'échantillon elles-mêmes se composent de deux tables, T1 et T2. Les deux ont une colonne de clé primaire séquentielle entière nommée pk et une deuxième colonne nullable nommée c1. La table T1 comporte 600 000 lignes où les lignes paires ont la même valeur pour c1 que la colonne pk et les lignes impaires sont nulles. Le tableau c2 contient 32 000 lignes où la colonne c1 est NULL dans chaque ligne. Le script suivant crée et remplit ces tables :
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; Les dix premières lignes d'exemples de données dans chaque tableau ressemblent à ceci :
Joindre les deux tables
Ce premier test consiste à joindre les deux tables sur la colonne c1 (pas la colonne pk) et à renvoyer la valeur pk de la table T1 pour les lignes qui se rejoignent :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
La requête ne renverra en fait aucune ligne car la colonne c1 est NULL dans toutes les lignes de la table T2, donc aucune ligne ne peut correspondre au prédicat de jointure d'égalité. Cela peut sembler une chose étrange à faire, mais je suis assuré qu'il est basé sur une vraie requête de production (grandement simplifiée pour faciliter la discussion).
Notez que ce résultat vide ne dépend pas du paramètre de ANSI_NULLS, car cela contrôle uniquement la manière dont les comparaisons avec un littéral ou une variable nul sont gérées. Pour les comparaisons de colonnes, un prédicat d'égalité rejette toujours les valeurs NULL.
Le plan d'exécution de cette requête de jointure simple présente des fonctionnalités intéressantes. Nous examinerons d'abord le plan de pré-exécution ("estimé") dans SQL Sentry Plan Explorer :
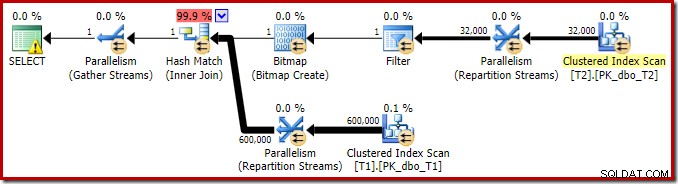
L'avertissement sur l'icône SELECT se plaint simplement d'un index manquant sur la table T1 pour la colonne c1 (avec pk comme colonne incluse). La suggestion d'index n'est pas pertinente ici.
Le premier véritable élément d'intérêt dans ce plan est le Filtre :
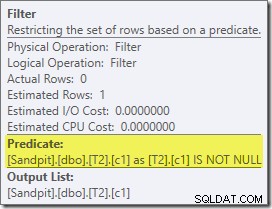
Ce prédicat N'EST PAS NULL n'apparaît pas dans la requête source, bien qu'il soit implicite dans le prédicat de jointure comme mentionné précédemment. Il est intéressant qu'il ait été décomposé en opérateur supplémentaire explicite et placé avant l'opération de jointure. Notez que même sans le filtre, la requête produirait toujours des résultats corrects ; la jointure elle-même rejetterait toujours les valeurs nulles.
Le filtre est également curieux pour d'autres raisons. Son coût est estimé exactement à zéro (même s'il est censé fonctionner sur 32 000 lignes) et il n'a pas été poussé vers le bas dans le balayage d'index clusterisé en tant que prédicat résiduel. L'optimiseur est normalement très désireux de le faire.
Ces deux choses s'expliquent par le fait que ce filtre est introduit dans une réécriture post-optimisation. Une fois que l'optimiseur de requêtes a terminé son traitement basé sur les coûts, un nombre relativement restreint de réécritures de plan fixe sont prises en compte. L'un d'eux est responsable de l'introduction du filtre.
Nous pouvons voir la sortie de la sélection de plan basée sur les coûts (avant la réécriture) en utilisant des indicateurs de trace non documentés 8607 et le familier 3604 pour diriger la sortie textuelle vers la console (onglet messages dans SSMS) :
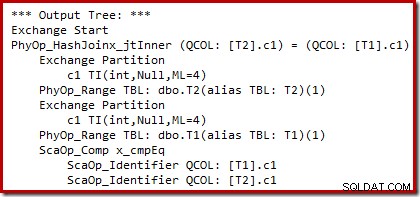
L'arborescence de sortie affiche une jointure par hachage, deux analyses et certains opérateurs de parallélisme (échange). Il n'y a pas de filtre de rejet nul sur la colonne c1 de la table T2.
La réécriture post-optimisation particulière examine exclusivement l'entrée de construction d'une jointure de hachage. En fonction de son évaluation de la situation, il peut ajouter un filtre explicite pour rejeter les lignes nulles dans la clé de jointure. L'effet du filtre sur le nombre de lignes estimé est également inscrit dans le plan d'exécution, mais comme l'optimisation basée sur les coûts est déjà terminée, un coût pour le filtre n'est pas calculé. Dans le cas où ce n'est pas évident, les coûts de calcul sont un gaspillage d'efforts si toutes les décisions basées sur les coûts ont déjà été prises.
Le filtre reste directement sur l'entrée de construction plutôt que d'être poussé vers le bas dans l'analyse de l'index clusterisé car l'activité d'optimisation principale est terminée. Les réécritures post-optimisation sont en fait des modifications de dernière minute apportées à un plan d'exécution terminé.
Une deuxième réécriture post-optimisation, assez distincte, est responsable de l'opérateur Bitmap dans le plan final (vous avez peut-être remarqué qu'il manquait également dans la sortie 8607) :
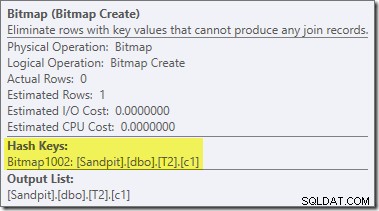
Cet opérateur a également un coût estimé nul pour les E/S et le CPU. L'autre chose qui l'identifie comme un opérateur introduit par un ajustement tardif (plutôt que lors de l'optimisation basée sur les coûts) est que son nom est Bitmap suivi d'un nombre. Il existe d'autres types de bitmaps introduits lors de l'optimisation basée sur les coûts, comme nous le verrons un peu plus tard.
Pour l'instant, la chose importante à propos de ce bitmap est qu'il enregistre les valeurs c1 vues pendant la phase de construction de la jointure par hachage. Le bitmap terminé est poussé vers le côté sonde de la jointure lorsque le hachage passe de la phase de construction à la phase de sonde. Le bitmap est utilisé pour effectuer une réduction précoce des semi-jointures, éliminant les lignes du côté de la sonde qui ne peuvent pas se joindre. si vous avez besoin de plus de détails à ce sujet, veuillez consulter mon article précédent sur le sujet.
Le deuxième effet du bitmap peut être observé sur le balayage d'index clusterisé côté sonde :
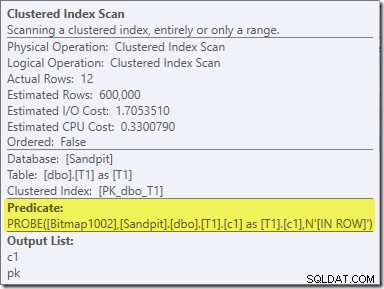
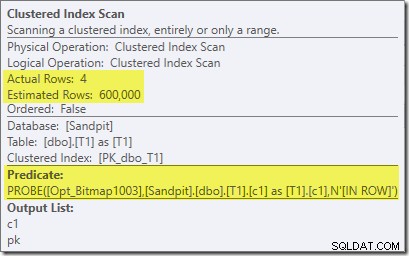
La capture d'écran ci-dessus montre le bitmap terminé en cours de vérification dans le cadre de l'analyse de l'index clusterisé sur la table T1. Étant donné que la colonne source est un entier (un bigint fonctionnerait également), la vérification du bitmap est poussée jusqu'au moteur de stockage (comme indiqué par le qualificatif 'INROW') plutôt que d'être vérifiée par le processeur de requêtes. Plus généralement, le bitmap peut être appliqué à n'importe quel opérateur côté sonde, depuis l'échange vers le bas. Jusqu'où le processeur de requêtes peut pousser le bitmap dépend du type de colonne et de la version de SQL Server.
Pour compléter l'analyse des principales caractéristiques de ce plan d'exécution, nous devons examiner le plan post-exécution ("réel") :
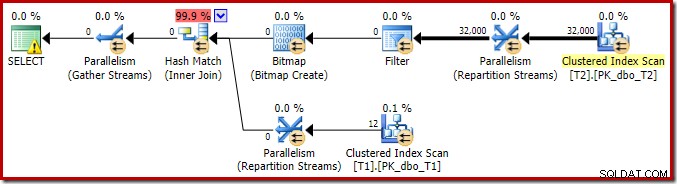
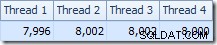
La première chose à remarquer est la répartition des lignes sur les threads entre l'analyse T2 et l'échange Repartition Streams immédiatement au-dessus. Lors d'un test, j'ai vu la distribution suivante sur un système à quatre processeurs logiques :
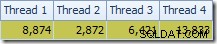
La distribution n'est pas particulièrement uniforme, comme c'est souvent le cas pour un balayage parallèle sur un nombre relativement restreint de lignes, mais au moins tous les threads ont reçu du travail. La répartition des threads entre le même échange Repartition Streams et le Filter est très différente :
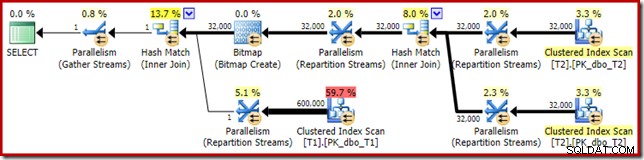
Cela montre que les 32 000 lignes de la table T2 ont été traitées par un seul thread. Pour comprendre pourquoi, nous devons examiner les propriétés de l'échange :

Cet échange, comme celui du côté sonde de la jointure par hachage, doit garantir que les lignes avec les mêmes valeurs de clé de jointure aboutissent à la même instance de la jointure par hachage. Au DOP 4, il y a quatre jointures de hachage, chacune avec sa propre table de hachage. Pour des résultats corrects, les lignes côté build et les lignes côté sonde avec les mêmes clés de jointure doivent arriver à la même jointure de hachage ; sinon, nous pourrions vérifier une ligne côté sonde par rapport à la mauvaise table de hachage.
Dans un plan parallèle en mode ligne, SQL Server y parvient en repartitionnant les deux entrées à l'aide de la même fonction de hachage sur les colonnes de jointure. Dans le cas présent, la jointure se trouve sur la colonne c1, de sorte que les entrées sont réparties sur les threads en appliquant une fonction de hachage (type de partitionnement :hachage) à la colonne de clé de jointure (c1). Le problème ici est que la colonne c1 ne contient qu'une seule valeur - null - dans la table T2, donc les 32 000 lignes reçoivent la même valeur de hachage, car elles se retrouvent toutes sur le même thread.
La bonne nouvelle est que rien de tout cela n'a vraiment d'importance pour cette requête. Le filtre de réécriture post-optimisation élimine toutes les lignes avant que beaucoup de travail ne soit effectué. Sur mon ordinateur portable, la requête ci-dessus s'exécute (ne produisant aucun résultat, comme prévu) en environ 70 ms .
Rejoindre trois tables
Pour le deuxième test, nous ajoutons une jointure supplémentaire de la table T2 à elle-même sur sa clé primaire :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Cela ne change pas les résultats logiques de la requête, mais cela change le plan d'exécution :
Comme prévu, l'auto-jointure de la table T2 sur sa clé primaire n'a aucun effet sur le nombre de lignes qualifiées de cette table :
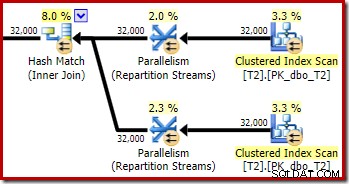
La répartition des lignes sur les threads est également bonne dans cette section du plan. Pour les scans, c'est similaire à avant car le scan parallèle distribue les lignes aux threads à la demande. La répartition des échanges basée sur un hachage de la clé de jointure, qui est la colonne pk cette fois-ci. Compte tenu de la plage de différentes valeurs de pk, la distribution de threads résultante est également très uniforme :
En ce qui concerne la section la plus intéressante du plan estimé, il existe quelques différences par rapport au test à deux tables :

Encore une fois, l'échange côté construction finit par acheminer toutes les lignes vers le même thread car c1 est la clé de jointure, et donc la colonne de partitionnement pour les échanges Repartition Streams (rappelez-vous, c1 est nul pour toutes les lignes de la table T2).
Il existe deux autres différences importantes dans cette section du plan par rapport au test précédent. Tout d'abord, il n'y a pas de filtre pour supprimer les lignes null-c1 du côté construction de la jointure par hachage. L'explication à cela est liée à la deuxième différence - le Bitmap a changé, bien que cela ne ressorte pas clairement de l'image ci-dessus :
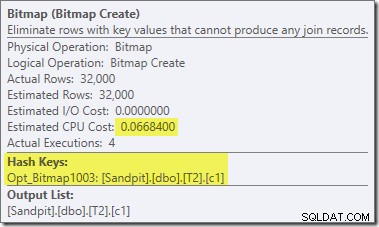
Il s'agit d'un Opt_Bitmap, pas d'un Bitmap. La différence est que ce bitmap a été introduit lors de l'optimisation basée sur les coûts, et non par une réécriture de dernière minute. Le mécanisme qui prend en compte les bitmaps optimisés est associé au traitement des requêtes de jointure en étoile. La logique de jointure en étoile nécessite au moins trois tables jointes, ce qui explique pourquoi une table optimisée le bitmap n'a pas été pris en compte dans l'exemple de jointure à deux tables.
Ce bitmap optimisé a un coût CPU estimé non nul et affecte directement le plan global choisi par l'optimiseur. Son effet sur l'estimation de cardinalité côté sonde peut être observé au niveau de l'opérateur Repartition Streams :
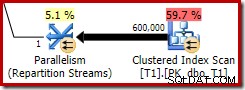
Notez que l'effet de cardinalité est visible lors de l'échange, même si le bitmap est finalement poussé jusqu'au bout dans le moteur de stockage ("INROW") comme nous l'avons vu dans le premier test (mais notez maintenant la référence Opt_Bitmap) :
Le plan post-exécution ("réel") est le suivant :
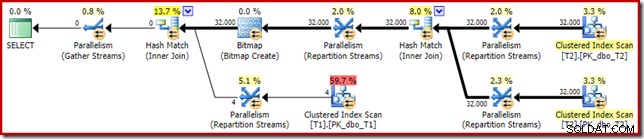
L'efficacité prévue du bitmap optimisé signifie que la réécriture post-optimisation séparée pour le filtre nul n'est pas appliquée. Personnellement, je pense que c'est malheureux car l'élimination précoce des valeurs nulles avec un filtre annulerait la nécessité de créer le bitmap, de remplir les tables de hachage et d'effectuer l'analyse bitmap améliorée de la table T1. Néanmoins, l'optimiseur en décide autrement et il n'y a tout simplement pas de discussion avec lui dans ce cas.
Malgré l'auto-jointure supplémentaire de la table T2 et le travail supplémentaire associé au filtre manquant, ce plan d'exécution produit toujours le résultat attendu (aucune ligne) en un temps record. Une exécution typique sur mon ordinateur portable prend environ 200 ms .
Modifier le type de données
Pour ce troisième test, nous allons changer le type de données de la colonne c1 dans les deux tables d'entier à décimal. Il n'y a rien de particulièrement spécial dans ce choix; le même effet peut être observé avec n'importe quel type numérique qui n'est pas entier ou bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Réutilisation de la requête de jointure à trois jointures :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
Le plan d'exécution estimé semble très familier :
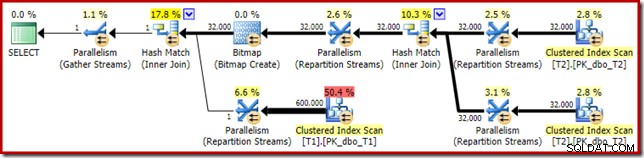
Hormis le fait que le bitmap optimisé ne peut plus être appliqué 'INROW' par le moteur de stockage en raison du changement de type de données, le plan d'exécution est essentiellement identique. La capture ci-dessous montre la modification des propriétés de numérisation :
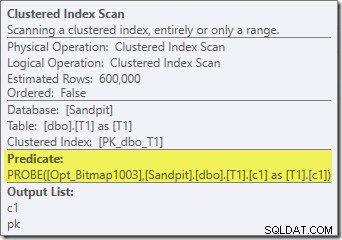
Malheureusement, les performances sont assez considérablement affectées. Cette requête ne s'exécute pas en 70 ms ou 200 ms, mais en environ 20 minutes . Dans le test qui a produit le plan de post-exécution suivant, le temps d'exécution était en fait de 22 minutes et 29 secondes :

La différence la plus évidente est que le balayage d'index clusterisé sur la table T1 renvoie 300 000 lignes même après l'application du filtre bitmap optimisé. Cela a du sens, puisque le bitmap est construit sur des lignes qui ne contiennent que des valeurs nulles dans la colonne c1. Le bitmap supprime les lignes non nulles de l'analyse T1, ne laissant que les 300 000 lignes avec des valeurs nulles pour c1. N'oubliez pas que la moitié des lignes de T1 sont nulles.
Même ainsi, il semble étrange que joindre 32 000 lignes à 300 000 lignes prenne plus de 20 minutes. Au cas où vous vous poseriez la question, un cœur de processeur a été indexé à 100 % pour toute l'exécution. L'explication de ces performances médiocres et de cette utilisation extrême des ressources s'appuie sur certaines idées que nous avons explorées précédemment :
Nous savons déjà, par exemple, que malgré les icônes d'exécution parallèles, toutes les lignes de T2 se retrouvent sur le même thread. Pour rappel, la jointure par hachage parallèle en mode ligne nécessite un repartitionnement sur les colonnes de jointure (c1). Toutes les lignes de T2 ont la même valeur - null - dans la colonne c1, donc toutes les lignes se retrouvent sur le même thread. De même, toutes les lignes de T1 qui passent le filtre bitmap ont également null dans la colonne c1, elles sont donc également réparties sur le même thread. Cela explique pourquoi un seul cœur fait tout le travail.
Il peut toujours sembler déraisonnable que le hachage joignant 32 000 lignes avec 300 000 lignes prenne 20 minutes, d'autant plus que les colonnes de jointure des deux côtés sont nulles et ne se joindront pas de toute façon. Pour comprendre cela, nous devons réfléchir au fonctionnement de cette jointure par hachage.
L'entrée de construction (les 32 000 lignes) crée une table de hachage à l'aide de la colonne de jointure, c1. Étant donné que chaque ligne côté construction contient la même valeur (null) pour la colonne de jointure c1, cela signifie que les 32 000 lignes se retrouvent dans le même compartiment de hachage. Lorsque la jointure de hachage passe à la recherche de correspondances, chaque ligne côté sonde avec une colonne c1 nulle effectue également un hachage vers le même compartiment. La jointure par hachage doit ensuite vérifier les 32 000 entrées de ce compartiment pour une correspondance.
La vérification des 300 000 rangées de sondes entraîne 32 000 comparaisons effectuées 300 000 fois. C'est le pire des cas pour une jointure par hachage :toutes les lignes latérales sont hachées dans le même compartiment, ce qui donne essentiellement un produit cartésien. Cela explique le long temps d'exécution et l'utilisation constante du processeur à 100 %, car le hachage suit la longue chaîne de compartiments de hachage.
Ces performances médiocres aident à expliquer pourquoi la réécriture post-optimisation pour éliminer les valeurs nulles sur l'entrée de construction d'une jointure de hachage existe. Il est dommage que le filtre n'ait pas été appliqué dans ce cas.
Solutions de contournement
L'optimiseur choisit cette forme de plan car il estime à tort que le bitmap optimisé filtrera toutes les lignes de la table T1. Bien que cette estimation soit affichée dans les flux de répartition au lieu de l'analyse de l'index clusterisé, c'est toujours la base de la décision. Pour rappel voici à nouveau la section pertinente du plan de pré-exécution :
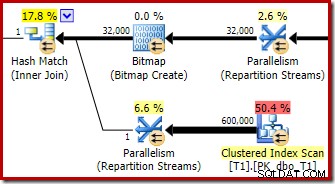
S'il s'agissait d'une estimation correcte, le traitement de la jointure par hachage ne prendrait pas beaucoup de temps. Il est regrettable que l'estimation de sélectivité pour le bitmap optimisé soit si erronée lorsque le type de données n'est pas un simple entier ou un bigint. Il semble qu'un bitmap construit sur une clé entière ou bigint soit également capable de filtrer les lignes nulles qui ne peuvent pas se joindre. Si c'est effectivement le cas, c'est une raison majeure de préférer les colonnes de jointure entières ou bigint.
Les solutions de contournement qui suivent sont largement basées sur l'idée d'éliminer les bitmaps optimisés problématiques.
Exécution en série
Une façon d'empêcher la prise en compte de bitmaps optimisés consiste à exiger un plan non parallèle. Les opérateurs Bitmap en mode ligne (optimisés ou non) ne sont visibles que dans les plans parallèles :
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Cette requête est exprimée à l'aide d'une syntaxe légèrement différente avec une indication FORCE ORDER pour générer une forme de plan plus facilement comparable aux plans parallèles précédents. La fonctionnalité essentielle est l'indice MAXDOP 1.
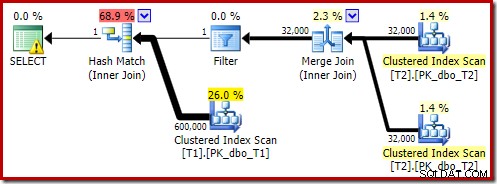
Ce plan estimé montre que le filtre de réécriture post-optimisation est rétabli :
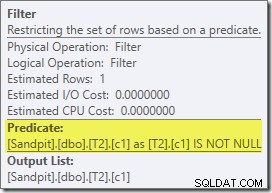
La version post-exécution du plan montre qu'il filtre toutes les lignes de l'entrée de construction, ce qui signifie que l'analyse côté sonde peut être complètement ignorée :
Comme vous vous en doutez, cette version de la requête s'exécute très rapidement - environ 20 ms en moyenne pour moi. Nous pouvons obtenir un effet similaire sans l'astuce FORCE ORDER et la réécriture de la requête :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
L'optimiseur choisit une forme de plan différente dans ce cas, avec le filtre placé directement au-dessus du scan de T2 :
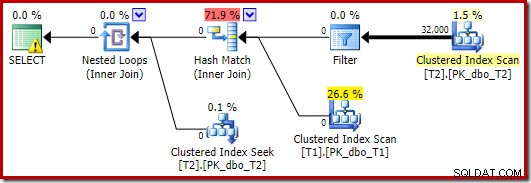
Cela s'exécute encore plus rapidement - en environ 10 ms - comme on pouvait s'y attendre. Naturellement, ce ne serait pas un bon choix si le nombre de lignes présentes (et joignables) était beaucoup plus grand.
Désactiver les bitmaps optimisés
Il n'y a pas d'indication de requête pour désactiver les bitmaps optimisés, mais nous pouvons obtenir le même effet en utilisant quelques indicateurs de trace non documentés. Comme toujours, c'est juste pour la valeur des intérêts; vous ne voudriez jamais les utiliser dans un système ou une application réels :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
Le plan d'exécution résultant est :
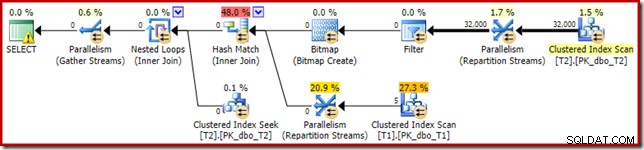
Le Bitmap est un bitmap de réécriture post-optimisation, pas un bitmap optimisé :
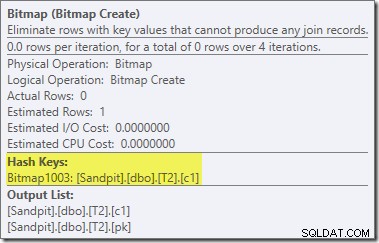
Notez les estimations de coût zéro et le nom Bitmap (plutôt que Opt_Bitmap). sans bitmap optimisé pour fausser les estimations de coût, la réécriture post-optimisation pour inclure un filtre rejetant les valeurs nulles est activée. Ce plan d'exécution s'exécute en environ 70 ms .
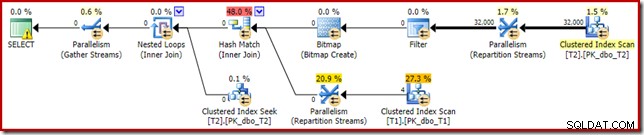
Le même plan d'exécution (avec Filtre et Bitmap non optimisé) peut également être produit en désactivant la règle d'optimisation responsable de la génération des plans de bitmap de jointure en étoile (encore une fois, strictement non documentés et non destinés à une utilisation réelle) :
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Incluant un filtre explicite
C'est l'option la plus simple, mais on ne penserait à le faire que si l'on est conscient des problèmes discutés jusqu'à présent. Maintenant que nous savons que nous devons éliminer les valeurs nulles de T2.c1, nous pouvons ajouter ceci directement à la requête :
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! Le plan d'exécution estimé qui en résulte n'est peut-être pas tout à fait ce à quoi vous vous attendiez :
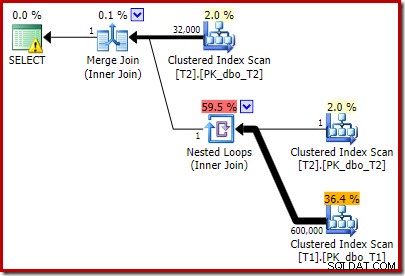
Le prédicat supplémentaire que nous avons ajouté a été poussé dans le balayage d'index clusterisé du milieu de T2 :
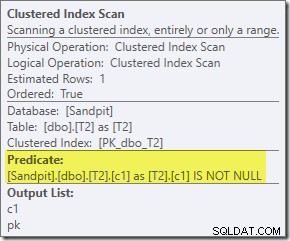
Le plan de post-exécution est :
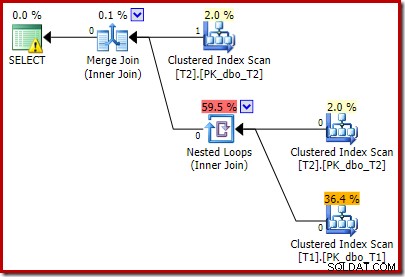
Notez que la jointure de fusion s'arrête après avoir lu une ligne à partir de son entrée supérieure, puis n'a pas trouvé de ligne sur son entrée inférieure, en raison de l'effet du prédicat que nous avons ajouté. Le balayage d'index clusterisé de la table T1 n'est jamais exécuté du tout, car la jointure Nested Loops n'obtient jamais de ligne sur son entrée pilote. Ce formulaire de requête final s'exécute en une ou deux millisecondes.
Réflexions finales
Cet article a couvert une bonne partie du terrain pour explorer certains comportements moins connus de l'optimiseur de requêtes et expliquer les raisons des performances extrêmement médiocres des jointures de hachage dans un cas spécifique.
Il pourrait être tentant de se demander pourquoi l'optimiseur n'ajoute pas systématiquement des filtres rejetant les valeurs nulles avant les jointures d'égalité. On peut seulement supposer que cela ne serait pas bénéfique dans suffisamment de cas courants. La plupart des jointures ne devraient pas rencontrer de nombreux rejets null =null, et l'ajout systématique de prédicats pourrait rapidement devenir contre-productif, en particulier si de nombreuses colonnes de jointure sont présentes. Pour la plupart des jointures, rejeter les valeurs nulles à l'intérieur de l'opérateur de jointure est probablement une meilleure option (du point de vue du modèle de coût) que d'introduire un filtre explicite.
Il semble qu'il y ait un effort pour empêcher les pires cas de se manifester par la réécriture post-optimisation conçue pour rejeter les lignes de jointure nulles avant qu'elles n'atteignent l'entrée de construction d'une jointure de hachage. Il semble qu'une fâcheuse interaction existe entre l'effet des filtres bitmap optimisés et l'application de cette réécriture. Il est également regrettable que lorsque ce problème de performances se produit, il soit très difficile de diagnostiquer à partir du seul plan d'exécution.
Pour l'instant, la meilleure option semble être consciente de ce problème de performances potentiel avec les jointures de hachage sur les colonnes nullables et ajouter des prédicats explicites de rejet nul (avec un commentaire !) Pour garantir la production d'un plan d'exécution efficace, si nécessaire. L'utilisation d'un indice MAXDOP 1 peut également révéler un plan alternatif avec le filtre révélateur présent.
En règle générale, les requêtes qui se rejoignent sur des colonnes de type entier et recherchent des données existantes ont tendance à mieux s'adapter au modèle de l'optimiseur et aux capacités du moteur d'exécution que les alternatives.
Remerciements
Je tiens à remercier SQL_Sasquatch (@sqL_handLe) pour sa permission de répondre à son article original avec une analyse technique. Les exemples de données utilisés ici sont fortement basés sur cet article.
Je tiens également à remercier Rob Farley (blog | twitter) pour nos discussions techniques au fil des ans, et en particulier une en janvier 2015 où nous avons discuté des implications des prédicats supplémentaires de rejet nul pour les équi-jointures. Rob a écrit plusieurs fois sur des sujets connexes, y compris dans Inverse Predicates - regardez des deux côtés avant de traverser.