Message de Dan Holmes, qui blogue sur sql.dnhlms.com.
La documentation en ligne de SQL Server (BOL), les livres blancs et de nombreuses autres sources vous montreront comment et pourquoi vous souhaiterez peut-être mettre à jour les statistiques d'une table ou d'un index. Cependant, vous n'avez qu'une seule façon de façonner ces valeurs. Je vais vous montrer comment vous pouvez créer les statistiques exactement comme vous le souhaitez dans les limites des 200 étapes disponibles.
Avis de non-responsabilité :Cela fonctionne pour moi parce que je connais mon application, ma base de données et le flux de travail régulier de mon utilisateur et les modèles d'utilisation de l'application. Cependant, il utilise des commandes non documentées et, s'il est utilisé de manière incorrecte, il pourrait rendre votre application moins performante.Dans notre application, l'utilisateur de la planification lit et écrit régulièrement des données qui représentent les événements de demain et des deux prochains jours. Les données d'aujourd'hui et d'avant ne sont pas utilisées par le planificateur. À la première heure du matin, l'ensemble de données pour demain commence à quelques centaines de lignes et à midi peut être de 1400 et plus. Le tableau suivant illustrera le nombre de lignes. Ces données ont été collectées le matin du mercredi 18 novembre 2015. Historiquement, vous pouvez constater que le nombre de lignes normal est d'environ 1 400, sauf les jours de week-end et le lendemain.
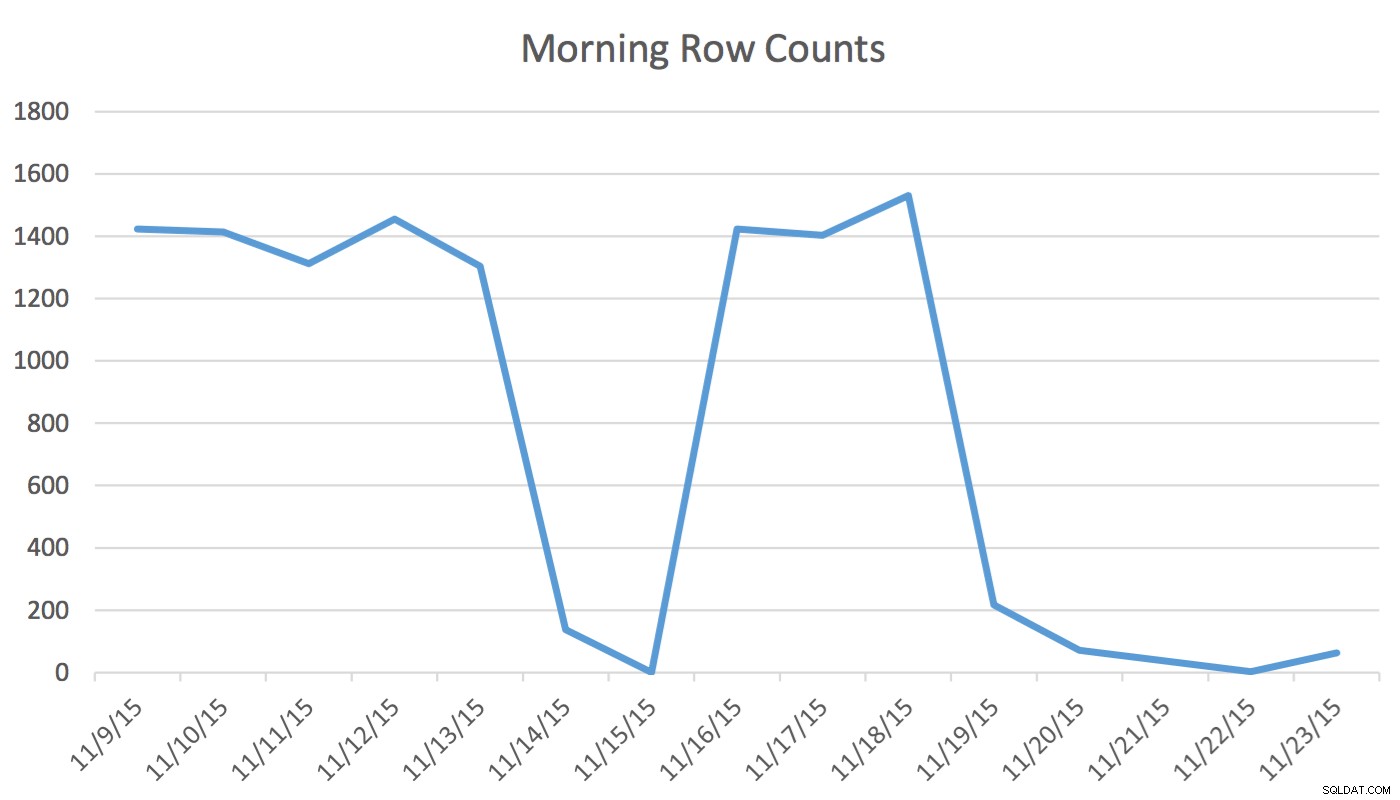
Pour le planificateur, les seules données pertinentes sont les prochains jours. Ce qui se passe aujourd'hui et ce qui s'est passé hier n'a rien à voir avec son activité. Alors, comment cela cause-t-il un problème? Cette table contient 2 259 205 lignes, ce qui signifie que la modification du nombre de lignes du matin au midi ne sera pas suffisante pour déclencher une mise à jour des statistiques initiée par SQL Server. De plus, une tâche planifiée manuellement qui génère des statistiques à l'aide de UPDATE STATISTICS remplit l'histogramme avec un échantillon de toutes les données du tableau, mais peut ne pas inclure les informations pertinentes. Ce delta du nombre de lignes est suffisant pour modifier le plan. Cependant, sans une mise à jour des statistiques et un histogramme précis, le plan ne changera pas pour le mieux à mesure que les données changent.
Une sélection pertinente de l'histogramme pour ce tableau à partir d'une sauvegarde datée du 4/11/2015 pourrait ressembler à ceci :
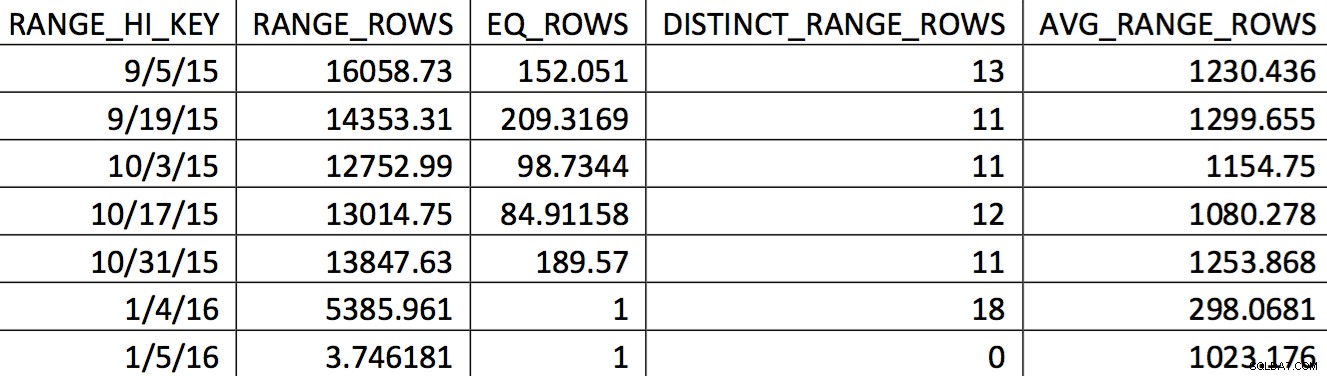
Les valeurs d'intérêt ne sont pas reflétées avec précision dans l'histogramme. Ce qui serait utilisé pour la date du 05/11/2015 serait la valeur haute 04/01/2016. D'après le graphique, cet histogramme n'est clairement pas une bonne source d'informations pour l'optimiseur pour la date d'intérêt. Forcer les valeurs d'utilisation dans l'histogramme n'est pas fiable, alors comment pouvez-vous faire cela ? Ma première tentative a été d'utiliser à plusieurs reprises le WITH SAMPLE option de UPDATE STATISTICS et interrogez l'histogramme jusqu'à ce que les valeurs dont j'avais besoin soient dans l'histogramme (un effort détaillé ici). En fin de compte, cette approche s'est avérée peu fiable.
Cet histogramme peut conduire à un plan avec ce type de comportement. La sous-estimation des lignes produit une jointure Nested Loop et une recherche d'index. Les lectures sont par la suite plus élevées qu'elles ne devraient l'être en raison de ce choix de plan. Cela aura également un effet sur la durée de la déclaration.
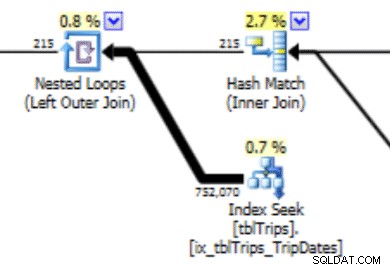
Ce qui fonctionnerait beaucoup mieux, c'est de créer les données exactement comme vous le souhaitez, et voici comment procéder.
Il existe une option non prise en charge de UPDATE STATISTICS :STATS_STREAM . Ceci est utilisé par le support client Microsoft pour exporter et importer des statistiques afin qu'ils puissent obtenir un optimiseur recréé sans avoir toutes les données dans la table. Nous pouvons utiliser cette fonctionnalité. L'idée est de créer un tableau qui imite le DDL de la statistique que nous voulons personnaliser. Les données pertinentes sont ajoutées au tableau. Les statistiques sont exportées et importées dans la table d'origine.
Dans ce cas, il s'agit d'une table avec 200 lignes de dates non NULL et 1 ligne qui inclut les valeurs NULL. De plus, il existe un index sur cette table qui correspond à l'index qui a les mauvaises valeurs d'histogramme.
Le nom de la table est tblTripsScheduled . Il a un index non clusterisé sur (id, TheTripDate) et un index clusterisé sur TheTripDate . Il existe une poignée d'autres colonnes, mais seules celles impliquées dans l'index sont importantes.
Créez une table (table temporaire si vous le souhaitez) qui imite la table et l'index. Le tableau et l'index ressemblent à ceci :
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
Ensuite, le tableau doit être rempli avec 200 lignes de données sur lesquelles les statistiques doivent être basées. Pour ma situation, c'est le jour de la prochaine soixante jours. Les 60 jours passés et au-delà sont peuplés d'une sélection "aléatoire" de tous les 10 jours. (Le cnt La valeur dans le CTE est une valeur de débogage. Il ne joue aucun rôle dans les résultats finaux.) L'ordre décroissant pour le rn garantit que les 60 jours sont inclus, puis le plus possible du passé.
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
Notre table est maintenant remplie avec chaque ligne qui est précieuse pour l'utilisateur aujourd'hui et une sélection de lignes historiques. Si la colonne TheTripdate était nullable, l'insert aurait également inclus ce qui suit :
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
Ensuite, nous mettons à jour les statistiques sur l'index de notre table temporaire.
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
Maintenant, exportez ces statistiques vers une table temporaire. Ce tableau ressemble à ceci. Il correspond à la sortie de DBCC SHOW_STATISTICS WITH HISTOGRAM .
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS a une option pour exporter les statistiques sous forme de flux. C'est ce flux que nous voulons. Ce flux est également le même flux que le UPDATE STATISTICS l'option de flux utilise. Pour ce faire :
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); La dernière étape consiste à créer le SQL qui met à jour les statistiques de notre table cible, puis à l'exécuter.
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); À ce stade, nous avons remplacé l'histogramme par notre histogramme personnalisé. Vous pouvez vérifier en vérifiant l'histogramme :
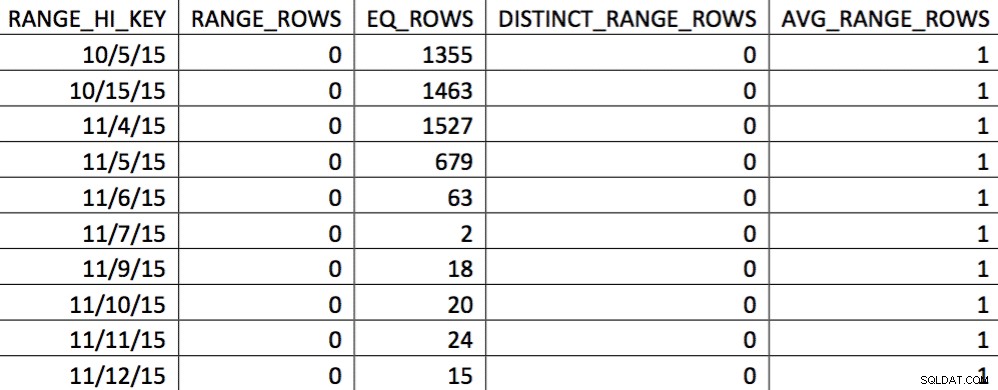
Dans cette sélection des données du 4/11, tous les jours à partir du 4/11 sont représentés, et les données historiques sont représentées et exactes. En revenant sur la partie du plan de requête présentée précédemment, vous pouvez voir que l'optimiseur a fait un meilleur choix en fonction des statistiques corrigées :
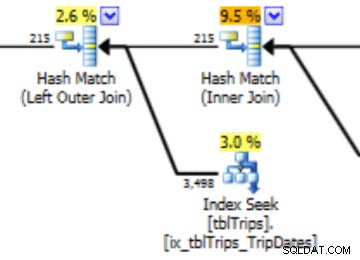
Les statistiques importées présentent un avantage en termes de performances. Le coût pour calculer les statistiques est sur une table "hors ligne". Le seul temps d'arrêt de la table de production est la durée de l'importation du flux.
Ce processus utilise des fonctionnalités non documentées et il semble que cela puisse être dangereux, mais rappelez-vous qu'il existe une annulation facile :l'instruction de mise à jour des statistiques. En cas de problème, les statistiques peuvent toujours être mises à jour à l'aide du T-SQL standard.
Planifier l'exécution régulière de ce code peut grandement aider l'optimiseur à produire de meilleurs plans étant donné un ensemble de données qui change au-delà du point de basculement, mais pas suffisamment pour déclencher une mise à jour des statistiques.
Lorsque j'ai terminé la première ébauche de cet article, le nombre de lignes sur le tableau du premier graphique est passé de 217 à 717. C'est un changement de 300 %. C'est suffisant pour modifier le comportement de l'optimiseur mais pas assez pour déclencher une mise à jour des statistiques. Ce changement de données aurait laissé un mauvais plan en place. C'est avec le processus décrit ici que ce problème est résolu.
Références :
- MISE À JOUR DES STATISTIQUES (Livres en ligne)
- Livre blanc sur les statistiques SQL 2008
- Recherche de point de basculement



