Dans mon article précédent, nous avons commencé à décrire les bases de la commande EXPLAIN et analysé ce qui se passe dans PostgreSQL lors de l'exécution d'une requête.
Je vais continuer à écrire sur les bases d'EXPLAIN dans PostgreSQL. L'information est une courte critique de Comprendre EXPLAIN par Guillaume Lelarge. Je recommande fortement de lire l'original car certaines informations sont manquantes.
Cache
Que se passe-t-il au niveau physique lors de l'exécution de notre requête ? Découvrons-le. J'ai déployé mon serveur sur Ubuntu 13.10 et utilisé des caches disque au niveau du système d'exploitation.
J'arrête PostgreSQL, je valide les modifications apportées au système de fichiers, j'efface le cache et j'exécute PostgreSQL :
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Lorsque le cache est vidé, lancez la requête avec l'option BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

On lit le tableau par blocs. Le cache est vide. Nous avons dû accéder à 8334 blocs pour lire toute la table à partir du disque.
Tampons :la lecture partagée correspond au nombre de blocs que PostgreSQL lit à partir du disque.
Exécuter la requête précédente
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Tampons :le hit partagé est le nombre de blocs récupérés depuis le cache PostgreSQL.
À chaque requête, PostgreSQL extrait de plus en plus de données du cache, remplissant ainsi son propre cache.
Les opérations de lecture de cache sont plus rapides que les opérations de lecture de disque. Vous pouvez voir cette tendance en suivant la valeur d'exécution totale.
La taille de stockage du cache est définie par la constante shared_buffers dans le fichier postgresql.conf.
OÙ
Ajouter la condition à la requête
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Il n'y a pas d'index sur la table. Lors de l'exécution de la requête, chaque enregistrement de la table est parcouru séquentiellement (Seq Scan) et comparé à la condition c1> 500. Si la condition est remplie, l'enregistrement est ajouté au résultat. Sinon, il est jeté. Le filtre indique ce comportement, ainsi que l'augmentation de la valeur du coût.
Le nombre estimé de lignes diminue.
L'article d'origine explique pourquoi le coût prend cette valeur et comment le nombre estimé de lignes est calculé.
Il est temps de créer des index.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Le nombre estimé de lignes a changé. Qu'en est-il de l'index ?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Seules 510 lignes sur plus d'un million sont filtrées. PostgreSQL devait lire plus de 99,9 % de la table.
On va forcer l'utilisation de l'index en désactivant Seq Scan :
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Dans Index Scan et Index Cond, l'index foo_c1_idx est utilisé à la place de Filter.
Lors de la sélection de la table entière, l'utilisation de l'index augmentera le coût et le temps d'exécution de la requête.
Activer l'analyse séquentielle :
SET enable_seqscan TO on;
Modifier la requête :
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
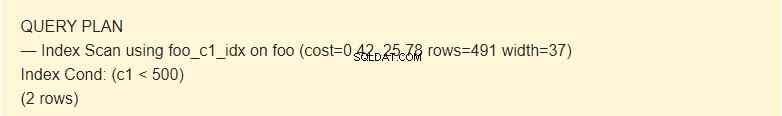
Ici, le planificateur utilise l'index.
Maintenant, compliquons la valeur en ajoutant le champ de texte.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Comme vous pouvez le voir, l'index foo_c1_idx est utilisé pour c1 <500. Pour effectuer c2 ~~ 'abcd%'::text, utilisez le filtre.
Il convient de noter que le format POSIX de l'opérateur LIKE est utilisé dans la sortie des résultats. S'il n'y a que le champ de texte dans la condition :
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan est appliqué.
Construire l'index par c2 :
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

L'index n'est pas appliqué car ma base de données pour les champs de test utilise l'encodage UTF-8.
Lors de la construction de l'index, il est nécessaire de préciser la classe de l'opérateur text_pattern_ops :
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Génial! Ça a marché !
Bitmap Index Scan utilise l'index foo_c2_idx1 pour déterminer les enregistrements dont nous avons besoin. Ensuite, PostgreSQL va à la table (Bitmap Heap Scan) pour s'assurer que ces enregistrements existent réellement. Ce comportement fait référence à la gestion des versions de PostgreSQL.
Si vous sélectionnez uniquement le champ sur lequel l'index est construit, au lieu de la ligne entière :
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan sera exécuté plus rapidement que Index Scan car il n'est pas nécessaire de lire la ligne du tableau :width=4.
Conclusion
- Seq Scan lit toute la table
- Index Scan utilise l'index pour les instructions WHERE et lit la table lors de la sélection de lignes
- Le balayage d'index bitmap utilise le balayage d'index et le contrôle de sélection dans la table. Efficace pour un grand nombre de lignes.
- Index Only Scan est le bloc le plus rapide, qui ne lit que l'index.
Pour en savoir plus :
Optimisation des requêtes dans PostgreSQL. EXPLIQUER les bases – Partie 3